
案例二:实时读取本地文件到HDFS

同时启动的agent不能相同:a1、a2、...
1.创建flume-hdfs.conf文件
|
# 1 agent a2.sources = r2 a2.sinks = k2 a2.channels = c2
# 2 source a2.sources.r2.type = exec #要监控的文件 a2.sources.r2.command = tail -F /opt/plus a2.sources.r2.shell = /bin/bash -c
# 3 sink a2.sinks.k2.type = hdfs # 如果是Hadoop,写有namenode节点的一个主机名,如果是HA,哪个是native就写哪个 #也就是说,当active点换的时候,这个主机名也需要修改 a2.sinks.k2.hdfs.path = hdfs://bigdata111:9000/flume/%Y%m%d/%H #上传文件的前缀 a2.sinks.k2.hdfs.filePrefix = logs- #是否按照时间滚动文件夹 a2.sinks.k2.hdfs.round = true #多少时间单位创建一个新的文件夹 a2.sinks.k2.hdfs.roundValue = 1 #重新定义时间单位 a2.sinks.k2.hdfs.roundUnit = hour #是否使用本地时间戳 a2.sinks.k2.hdfs.useLocalTimeStamp = true #积攒多少个Event才flush到HDFS一次 a2.sinks.k2.hdfs.batchSize = 1000 #设置文件类型,可支持压缩 a2.sinks.k2.hdfs.fileType = DataStream #多久生成一个新的文件 a2.sinks.k2.hdfs.rollInterval = 600 #设置每个文件的滚动大小-超过这个数据大小(一个块的大小128MB)就滚动 a2.sinks.k2.hdfs.rollSize = 134217700 #文件的滚动与Event数量无关 a2.sinks.k2.hdfs.rollCount = 0 #最小副本数 a2.sinks.k2.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel a2.sources.r2.channels = c2 a2.sinks.k2.channel = c2 |
复制之后,注意修改主机名(active的那个),然后根据这句配置:a2.sources.r2.command = tail -F /opt/plus
记得创建文件plus:[root@bigdata111 myconf]# vi /opt/plus,然后添加一些数据。
2.执行监控配置
|
/opt/module/flume1.8.0/bin/flume-ng agent \ --conf /opt/module/flume1.8.0/conf/ \ --name a2 \ --conf-file /opt/module/flume1.8.0/jobconf/flume-hdfs.conf |
接下来查看Web页面,bigdata111的50070端口,监控plus文件,可以echo往里追加一些内容,查看变化。
对文件的内容进行追加:
[root@bigdata111 ~]# date Tue Mar 24 22:40:03 CST 2020
[root@bigdata111 ~]# echo a >> /opt/plus
3.实践结果分析
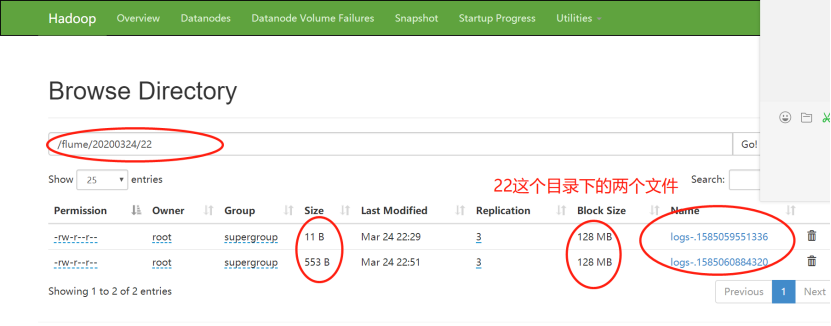
1)22:19分,开始监控plus文件的内容
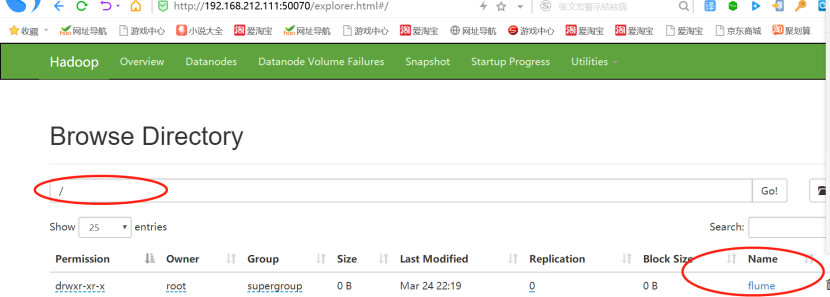
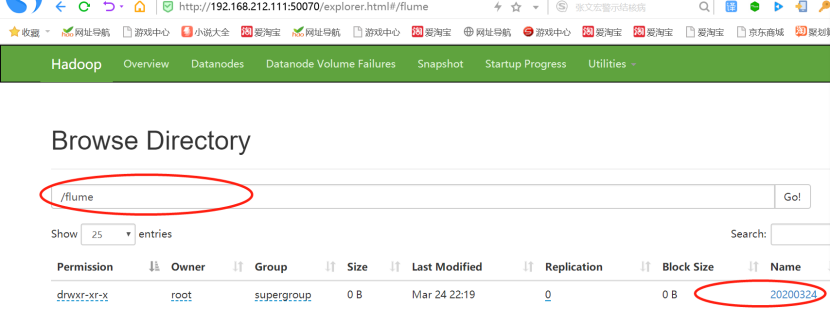

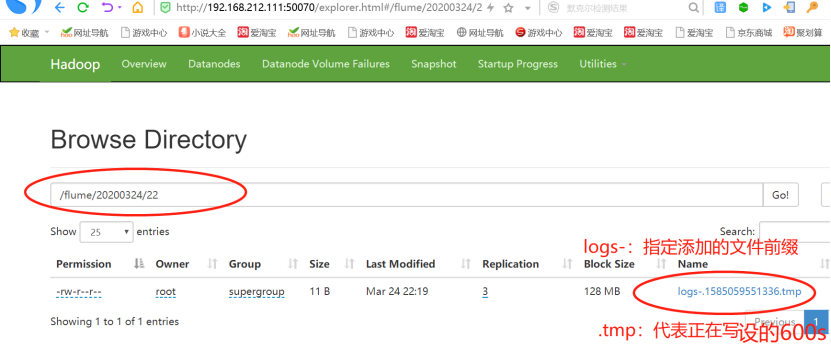
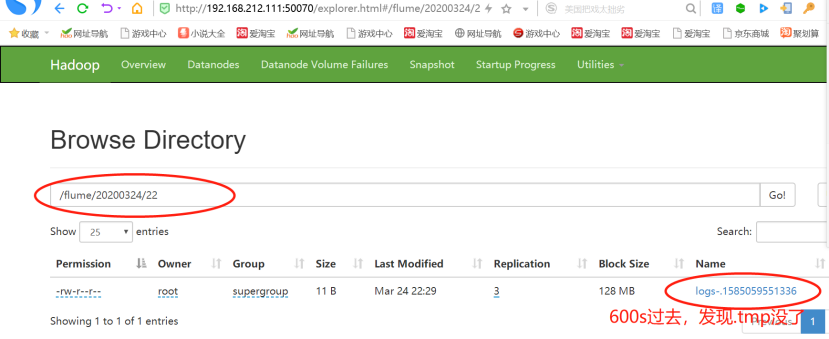
2)22:29分,正是600秒-十分钟之后,文件停止更新,生成成功
3)一段时间后,22:41分,接着对plus文件输入数据
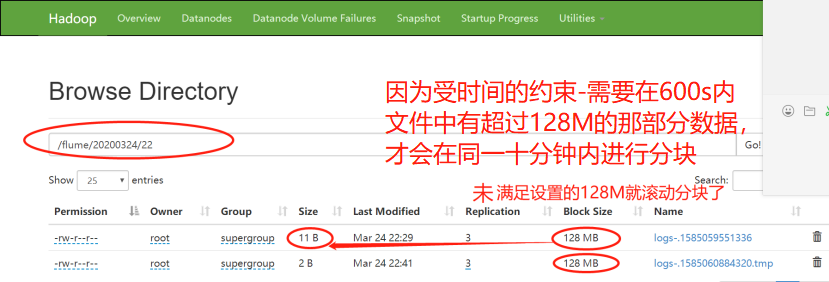
4)22:51分,正是600秒-十分钟之后,文件停止更新,生成成功
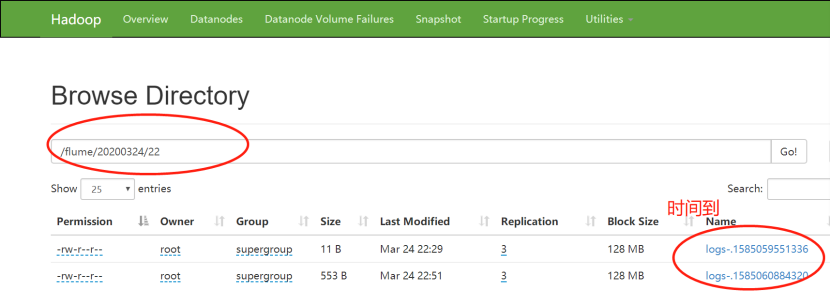
5)过了一段时间,23:44分,进行第三波的数据输入
此时较上两波数据的输入,不在同一小时内,也就是说不在同一时间戳里,因此又生成了23目录。
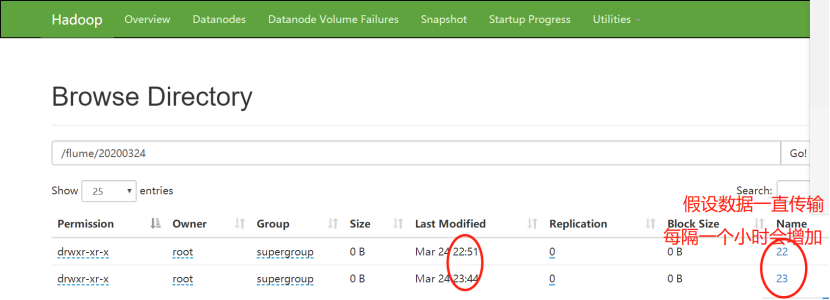
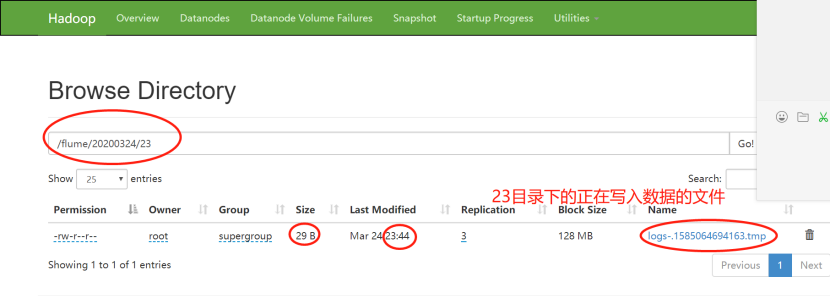
6)23:54分,正是600秒-十分钟之后,文件停止更新,生成成功
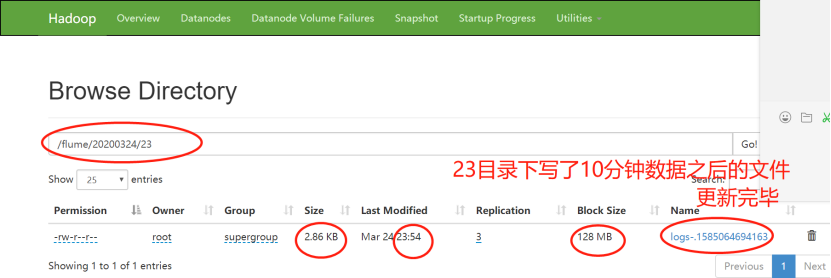
此时22目录下面的两个文件的大小依然未改变,表明:生成后的文件不会再被写进数据,即使它大小不足128MB-134217700byte
7)也可以向文件追加执行脚本
#!/bin/bash
while true
do
date >> /opt/plus;
sleep 0.5; #(这样可以使追加变得缓慢一些)
done

 浙公网安备 33010602011771号
浙公网安备 33010602011771号