模块的循环导入问题、包、json与pickle模块、time与datetime模块、random模块
一:模块的循环导入问题
模块的循环/嵌套导入抛出异常的根本原因是由于在python中模块被导入一次之后,就不会重新导入,只会在第一次导入模块时执行模块内代码。在项目中,如果出现多个模块都需要共享的数据,可以将共享的数据集中存放到某一个地方。


#m1.py print('正在导入m1') from m2 import y #在m1中导入m2中的y x='m1' #m2.py print('正在导入m2') from m1 import x #在m2中导入m1中的x y='m2' #run.py import m1 #导入m1,打印正在导入m1,执行导入m2,打印正在导入m2,此时需要导入m1,而m1中的x还没有执行到,程序就会抛出异常ImportError: cannot import name 'x'
此列方法可以采用两种方式解决:一种是将变量名放在导入模块代码的前面,另一种是将导入语句放到函数里面,在定义阶段是不会执行函数体代码的。
如下:
方法一:导入语句放到最后 #m1.py print('正在导入m1') x='m1' from m2 import y #m2.py print('正在导入m2') y='m2' from m1 import x 方法二:导入语句放到函数中 #m1.py print('正在导入m1') def f1(): from m2 import y print(x,y) x = 'm1' # f1() #m2.py print('正在导入m2') def f2(): from m1 import x print(x,y) y = 'm2' #run.py import m1 m1.f1()
二:包
1.包就是一个含有__init__.py文件的文件夹,创建包的目的就是为了用文件夹将文件/模块组织起来。
注意:
1.在python3中,即便包下面没有__init__.py文件,import包仍然不会报错,而在python2中,包下面一定要有该文件夹,否则import包报错。
2.创建包不是为了运行,而是为了被导入使用,包只是模块的一种形式而已,包的本质就是一种模块。
3.包以及包所包含的模块都是用来被导入的,而不是直接被执行。环境变量都是以执行文件为准的。
三:json&pickle模块
1.什么是序列化?
序列化就是将内存中的数据类型转换成另外一种格式。
即:字典——序列化———>其他格式————>存到硬盘
硬盘——读取———>其他格式——反序列化———>字典
2.为什么要序列化?
1:持久保存状态:在断电或重启数据之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便下次执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
2:跨平台数据交互:序列化之后,不仅可以将序列化之后的内容写入磁盘,还可以通过网络传输到别的机器上,如果双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
json和python内置的数据类型对应如下:
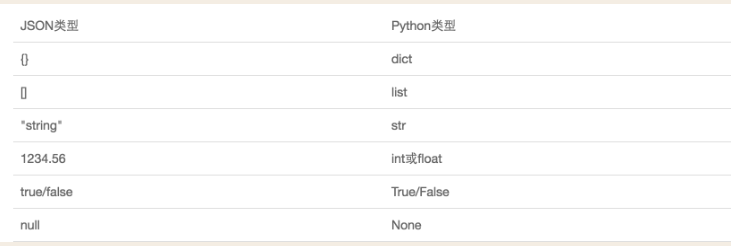
内存中结构化数据<———>格式JSON<———>字符串<———>保存到文件中或基于网络传输
import json # dic={'k1':True,'k2':10,'k3':'egon','k4':'你好啊'} # # # 序列化:将字典转换成json格式 dic_json=json.dumps(dic) print(dic_json,type(dic_json)) # # # 持久化:将转换好的json格式存到硬盘 with open('a.json',mode='wt',encoding='utf-8') as f: f.write(dic_json) 下面可以将序列化和持久化通过dump写到一起: import json dic={'k1':'zdsb'} with open('a.json','wt',encoding='utf8') as f: json.dump(dic,f) #将字典dump成json格式,然后通过f(f是文件格式)将内容存到硬盘
import json # 从文件中读取json格式化的字符 with open('a.json',mode='rt',encoding='utf-8') as f: dic_json=f.read() # 反序列化(通过loads) dic=json.loads(dic_json) print(dic,dic['k1']) # 反序列化(通过load) with open('a.json','rt',encoding='utf8') as f: d=json.load(f) print(d)
# pickle序列化 import pickle dic={'k1':'zdsb'} with open('b.pickle','wb') as f: pickle.dump(dic,f) # 反序列化 with open('b.pickle','rb') as f: pkl=pickle.load(f) print(pkl)
3.json&pickle
json:
优点:这种格式是一种通用的格式,所有编程语言都能识别
缺点:不能识别所有python语言
强调:json格式不能识别单引号
pickle:
优点:能识别所有python类型
缺点:只能被python这门编程语言识别
四:time和datetime模块
在python中通常有这几种方式来表示时间:
- 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串(Format String)
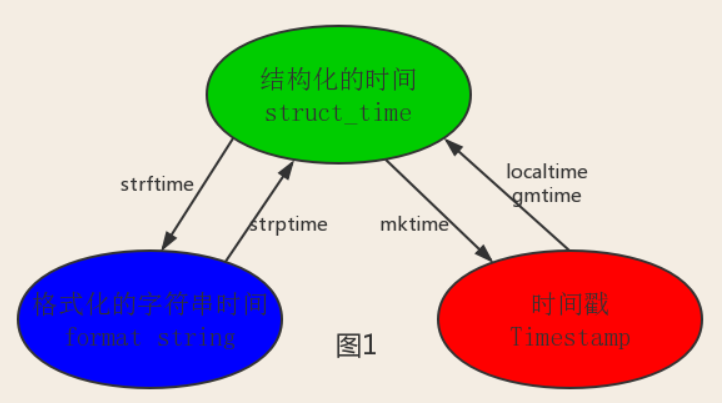
- 结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
import time print(time.time()) # 时间戳:1487130156.419527 print(time.strftime('%Y-%m-%d %H:%M:%S %p'))#格式化的时间字符串:'2018-12-05 16:07:13 PM' print(time.localtime()) #本地时区的struct_time print(time.gmtime()) #UTC时区(格林尼治时间)的struct_time
#--------------------------按图1转换时间 # localtime([secs]) # 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。 time.localtime() time.localtime(1473525444.037215) # gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。 # mktime(t) : 将一个struct_time转化为时间戳。 print(time.mktime(time.localtime()))#1473525749.0 # strftime(format[, t]) : 把一个代表时间的元组或者struct_time(如由time.localtime()和 # time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。如果元组中任何一个 # 元素越界,ValueError的错误将会被抛出。 print(time.strftime("%Y-%m-%d %X", time.localtime()))#2016-09-11 00:49:56 # time.strptime(string[, format]) # 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。 print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X')) #time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6, # tm_wday=3, tm_yday=125, tm_isdst=-1) #在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。
#时间加减 import datetime # print(datetime.datetime.now()) #返回 2018-12-05 16:13:06.306700 #print(datetime.datetime.fromtimestamp(time.time())) # 时间戳直接转成日期格式 2018-12-05 16:13:55.377545 # print(datetime.datetime.now() ) # print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天 # print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天 # print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时 # print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 # # c_time = datetime.datetime.now() # print(c_time.replace(minute=3,hour=2)) #时间替换
五:random模块
import random print(random.random()) #(0,1)----float 大于0且小于1之间的小数 print(random.randint(1,3)) #[1,3] 大于等于1且小于等于3之间的整数 print(random.randrange(1,3)) #[1,3) 大于等于1且小于3之间的整数 print(random.choice([1,'23',[4,5]])) #1或者23或者[4,5] print(random.sample([1,'23',[4,5]],2)) #列表元素任意2个组合 print(random.uniform(1,3)) #大于1小于3的小数,如1.927109612082716 item=[1,3,5,7,9] random.shuffle(item) #打乱item的顺序,相当于"洗牌" print(item)
import random def make_code(max_size=5): #默认它取五个随机值 res='' for i in range(max_size): num=str(random.randint(0,9)) #表示数字0~9 alp=chr(random.randint(65,90)) #表示大小写字母 res+=random.choice([num,alp]) return res print(make_code(4)) #自定义取四个值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号