加载文本数据、跨服务器导数据、hive分隔符、hive倾斜案列(优化)
将CSV文件的数据导入到表里
第一步:创建表。并指定分隔符
CREATE TABLE `xyy_temp_data.temp_ec_tb_order_promo_detail`( `order_no` string, `type` tinyint, `sku_id` bigint, `barcode` string, `original_price` double, `product_count` int, `promo_type` tinyint, `promo_id` bigint, `coupon_id` bigint, `coupon_template_id` bigint, `promo_rule_id` bigint, `promo_amount` double, `discount_amount` double) row format delimited fields terminated by',' ----指定分隔符 csv默认的分隔符就是逗号 ;
第二步:将文件上传到服务器上,文件名不要用中文
第三步:导入到表里
load data local inpath'/home/dev/del/liu/chaifen_bu.csv' into table xyy_temp_data.temp_ec_tb_order_promo_detail;
截图如下:

加载文本数据
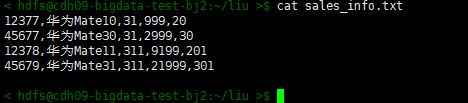
1、linux 目录里的文本数据如下:
12377,华为Mate10,31,999,20 45677,华为Mate30,31,2999,30 12378,华为Mate11,311,9199,201 45679,华为Mate31,311,21999,301
截图如下:
2、把sales_info.txt文件上传到hdfs目录里
hadoop fs -put sales_info.txt /data/hive/test ---上传文件
hadoop fs -ls /data/hive/test ----查看hdfs目录里的文件
截图如下:

3、在hive里创建表
CREATE TABLE `xyy_temp_data.sales_info`( `sku_id` string COMMENT '商品id', `sku_name` string COMMENT '商品名称', `category_id3` string COMMENT '三级分类id', `price` double COMMENT '销售价格', `sales_count` bigint COMMENT '销售数量' ) COMMENT '商品销售信息表' PARTITIONED BY( `dt` string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' NULL DEFINED AS '' STORED AS TEXTFILE
4、加载数据到指定分区
load data inpath 'hdfs://nameservice1/data/hive/test/sales_info.txt' overwrite into table xyy_temp_data.sales_info partition(dt = '2019-04-26')
截图如下:

跨服务器导数据
方法一
1、查看存储地址
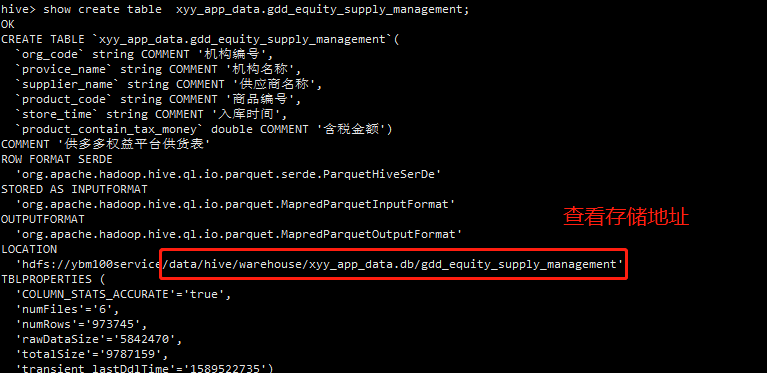
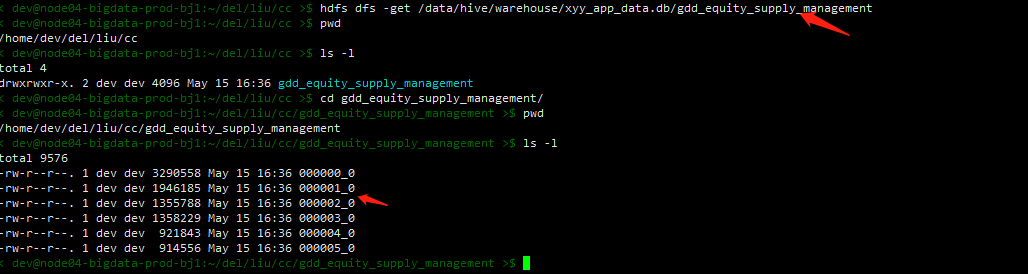
2、通过get命令下载到指定路径里
hdfs dfs -get /data/hive/warehouse/xyy_app_data.db/gdd_equity_supply_management
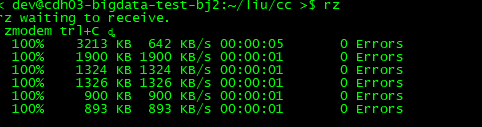
3、通过rz上传到服务器
4、 上传到hdfs上 hdfs dfs -put 00000* /data/hive/warehouse/xyy_app_data.db/gdd6_equity_supply_management

5、通过查看命令会发现已经上传到hdfs里

6、通过查看表里数据已经加载进去
hive> select count(1) from xyy_app_data.gdd6_equity_supply_management;

跨服务器导出分区数据
--查看下面的文件 hdfs dfs -ls /data/hive/warehouse/xyy_app_data.db/gdd_entrance_flow_platform --创建文件夹 hdfs dfs -mkdir /data/hive/warehouse/xyy_app_data.db/gdd_entrance_flow_platform/dt=20200526 ---数据传入到指定分区 hdfs dfs -put 00000* /data/hive/warehouse/xyy_app_data.db/gdd_entrance_flow_platform/dt=20200526 ---将表里的数据加载到分区里 alter table xyy_app_data.gdd_entrance_flow_platform add partition (dt = '20200526');
方法二、
步骤1:找到表在hdfs上面的位置 show create table xyy_bigdata_ods.saas_dictionary; /data/hive/warehouse/xyy_bigdata_ods.db/saas_dictionary' 步骤2:下载数据到本地 http://cdh-hdfs.prod.ybm100.com/explorer.html#/data/hive/warehouse/xyy_bigdata_ods.db/saas_dictionary 步骤3:在测试集群上面建表 CREATE TABLE `xyy_bigdata_ods.saas_dictionary`( `id` int, `dictionary_name` string, `mnemonic_code` string, `key_words` string, `dictionary_type` int, `create_user` string, `create_time` string, `update_user` string, `update_time` string, `yn` tinyint); 步骤4:上传下载的数据的测试服务器 步骤5:加载数据到表中 load data local inpath '/home/hdfs/saas_dictionary' into table xyy_bigdata_ods.saas_dictionary;
案列:
第一步:查看生产服务器表的hdfs存储路径截图如下:
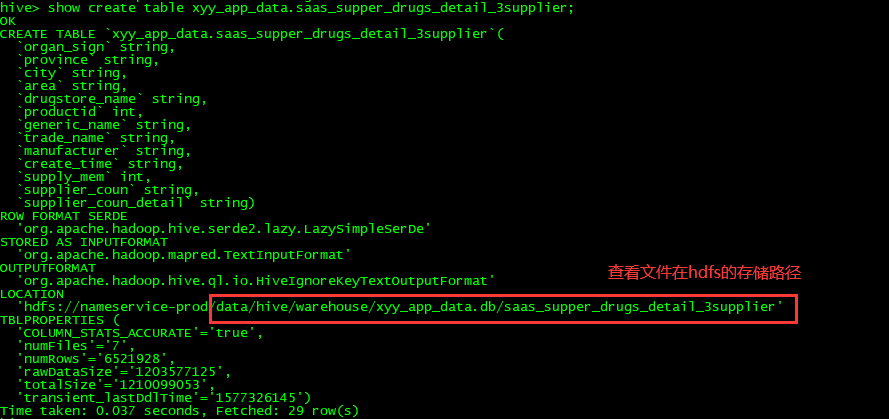
第二步:把生产表的建表语句复制下来:
CREATE TABLE `xyy_app_data.saas_supper_drugs_detail_3supplier`( `organ_sign` string, `province` string, `city` string, `area` string, `drugstore_name` string, `productid` int, `generic_name` string, `trade_name` string, `manufacturer` string, `create_time` string, `supply_mem` int, `supplier_coun` string, `supplier_coun_detail` string)
第三步、查看文件大小
< hdfs@cdh06-bigdata-prod-bj1:/home/hdfs/liu >$ hadoop fs -ls /data/hive/warehouse/xyy_app_data.db/saas_supper_drugs_detail_3supplier ---查看所有文件
---加上 -du -h 查看这个表的整个大小
< hdfs@cdh06-bigdata-prod-bj1:/home/hdfs/liu >$ hadoop fs -du -h /data/hive/warehouse/xyy_app_data.db |grep saas_supper_drugs_detail_3supplier
截图如下:

第四步、把hdfs上的文件下载到 linux 上
< hdfs@cdh06-bigdata-prod-bj1:/home/hdfs/liu >$ hadoop fs -get /data/hive/warehouse/xyy_app_data.db/saas_supper_drugs_detail_3supplier/000000_0

第五步、把文件进行压缩
用 tar -zcvf 把 多个文件进行压缩成 000.tar.gz
< hdfs@cdh06-bigdata-prod-bj1:/home/hdfs/liu >$ tar -zcvf 000.tar.gz 000000_0 000001_0 000002_0
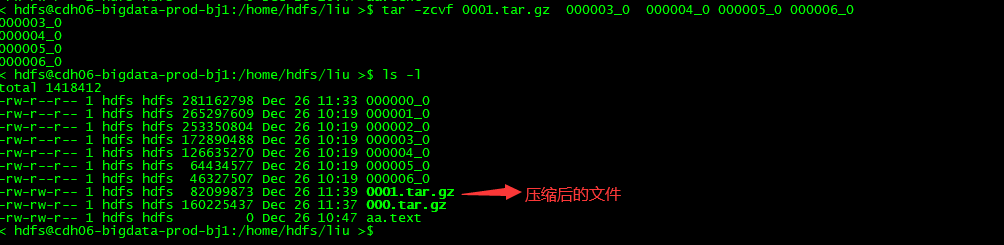
第六步、把压缩文件下载到本地 ,因为网络不通,只能先下载到本地,再上传到新的服务器上

第七步:上传到新的服务器上
rz 上传脚本命令
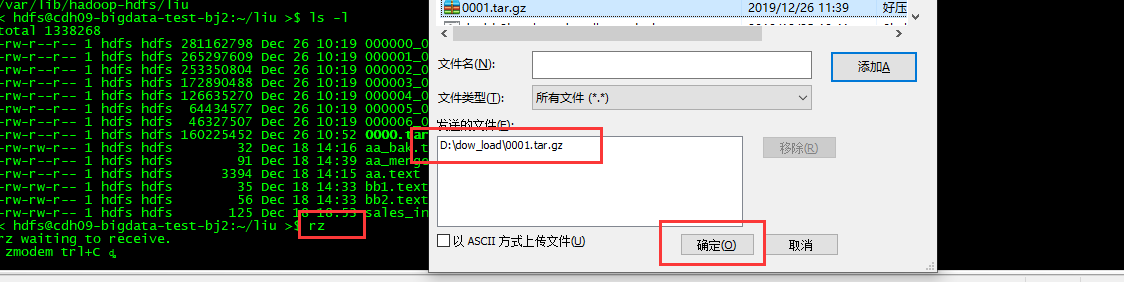
第八步:把上传的文件进行压缩:
使用 tar -zxvf 0000.tar.gz 命令

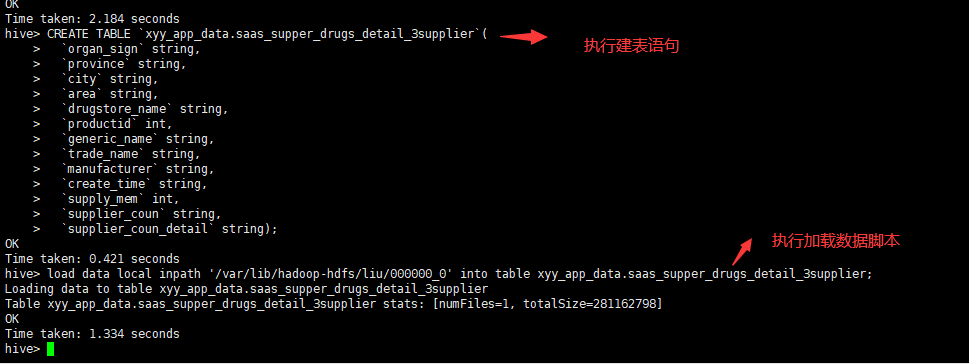
第九步:把数据加载到新服务器上
1、把第二步复制下来的sql 在新服务器上执行
2、load data local inpath '/var/lib/hadoop-hdfs/liu/000000_0' into table xyy_app_data.saas_supper_drugs_detail_3supplier; ---加载数据脚本
、
HIVE-默认分隔符的(linux系统的特殊字符)查看,输入和修改
这段时间做hive的时候,用到了系统默认分隔符。通常下面2中情况我们需要需要用到分隔符
1,制作table的输入文件,有时候我们需要输入一些特殊的分隔符
2,把hive表格导出到本地时,系统默认的分隔符是^A,这个是特殊字符,直接cat或者vim是看不到的
分隔符在HIVE中的用途
|
分隔符 |
描述 |
|
\n |
对于文本文件来说,每行都是一条记录,因此换行符可以分隔记录 |
|
^A(Ctrl+A) |
用于分隔字段(列)。在CREATE TABLE语句中可以使用八进制编码\001表示 |
|
^B(Ctrl+B) |
用于分隔ARRAY或者STRUCT中的元素,或用于MAP中键-值对之间的分隔。在CREATE TABLE语句中可以使用八进制编码\002表示 |
|
^C(Ctrl+C) |
用于MAP中键和值之间的分隔。在CREATE TABLE语句中可以使用八进制编码\003表示 |
Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、”\t”、”\x001″)、行分隔符(”\n”)以及读取文件数据的方法。由于在加载数据的过程中,不需要从用户数据格式到 Hive 定义的数据格式的转换,因此,Hive 在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中。
我们可以在create表格的时候,选择如下,表格加载input的文件的时候就会按照下面格式匹配
row format delimited fields terminated by '\001' collection items terminated by '\002' map keys terminated by '\003' lines terminated by '\n' stored as textfile;
如何查看和修改分割符,特殊符号
1、查看隐藏字符的方法
1.1,cat -A filename

1.2,vim filename后 命令模式下输入
set list显示特殊符号
set nolist 取消显示特殊符号
2、修改隐藏字符的方法
首先按照1.2打开显示特殊符号。进入INSERT模式
ctrl + V 可以输入 ^符号 ctrl + a 可以输入A---'\001' ctrl + b 可以输入A---'\002' ctrl + c 可以输入A---'\003'
注意:虽然键盘上你能找到^和A但直接输入时不行的,必须按照上面的方法输入。
第一行是特殊符号颜色蓝色,第二行直接输入不是特殊符号。

特殊号直接cat是不可以看见的,但是第二行是可见的,所以不是特殊符号。

数据倾斜
hive或者MR处理数据,不怕数据量大,就怕倾斜。hive里大表join的时候,数据倾斜就是个很头疼的问题。本博主就遇到了一个真实案例,特意记录下来,有需要的同学可以参考
1.查了5个小时还没结束的sql语句
set mapred.reduce.tasks = 30; insert overwrite directory 'xxx' select cus.idA,cus.name,addr.bb from tableA as cus join tableB as addr on cus.idA = addr.idB
很简单的一个hql语句,优化的空间也不是很大(例子中的addr数据量比cus小,应该讲addr放在前面驱动join)。tableA的量级为亿级,tableB的量级为几百万级别。就这么一个简单的sql,尼玛从上午十点半开始跑,跑到下午三点半还没有跑完。实在受不了了,kill掉了。
2.初步分析
首先上个查询过程中的图
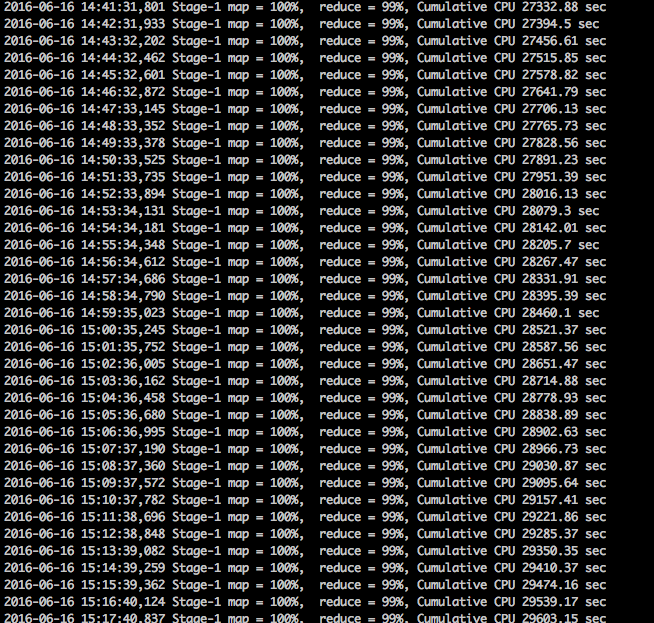
看到这种情况,稍微有点经验的同学第一反应肯定就是:卧槽,这尼玛肯定是数据倾斜了。没错,map早就完工了,reduce阶段一直卡在99%,而且cumulative cpu的时间还一直在增长,说明整个job还在后台跑着。这种情况下,99%的可能性就是数据发生了倾斜,整个查询任务都在等某个节点完成。。。
3.分析那部分数据产生了倾斜
问题既然已经定位了,那接下来就是需要解决问题了。正好不巧的是,集群这几天还出了一些状况。so,首先为了确认到底是集群本身的问题,还是代码的问题,先找了另外两个表,都是亿级数据。这两个表不存在数据倾斜的情况,join一把试了试,两分钟之内结果就出来了。万幸,说明这会集群已经没有问题了,还是查查数据跟代码吧。
代码本身很简单,那就沿着数据倾斜的方向查查吧。因为上面的两个表是根据id关联的,那如果倾斜的话,肯定就是id倾斜了哇。
set mapred.reduce.tasks = 5; select idA,count(*) as num from tableA group by idA distribute by idA sort by num desc limit 10
结果为:
192928 5828529
2000000000496592833 2406289
18000 1706031
4000288 1386324
2000000003624295444 1201178
2000000001720892923 1029475
2000000002292880478 991299
2000000000736661289 881954
2000000000740899183 873487
2000000000575115116 803250对于有上亿数据的一个表来说,这数据也算不上倾斜多厉害嘛。最多的一个key也就五百多万不到六百万。好吧,先不管了,再查一把另外一个表
set mapred.reduce.tasks = 5; select idB,count(*) as num from tableB group by idB distribute by idB sort by num desc limit 10
结果也很快出来
192928 383412
18000 60318
617279581 23028
51010262 4643
4000286 3528
2000000000575115116 3218
1366173280 3012
4212339 2972
2000000002025620390 2704
2000000001312577574 2622这数据倾斜,也不是特别严重嘛。
不过再把这两个结果一对比,尼玛恍然大悟。两个表里最多的一个key都是192928,一个出现了将近600万次,一个出现了将近40万次。这两个表再一join,尼玛这一个key就是600万*40万的计算量。最要命的是,这计算量都分配给了一个节点。我数学不太好,600万*40万是多少,跪求数学好的同学帮忙计算一下。不过根据经验来看的话,别说5个小时,再添个0也未必能算得完。。。
4.如何解决
既然找到了数据倾斜的位置,那解决起来也就好办了。因为本博主的真正需求并不是真正要算两个表的笛卡尔积(估计实际中也极少有真正的需求算600万*40万数据的笛卡尔积。如果有,那画面太美我不敢看),所以最easy的解决方案,就是将这些key给过滤掉完事:
set mapred.reduce.tasks = 30; insert overwrite directory 'xxx' select cus.idA,cus.name,addr.bb from tableA as cus join tableB as addr on cus.idA = addr.idB where cus.idA not in (192928,2000000000496592833,18000,4000288,2000000003624295444,2000000001720892923,2000000002292880478,2000000000736661289,2000000000740899183,2000000000575115116,617279581,51010262,4000286,1366173280,2000000002025620390,2000000001312577574)
将此代码重新提交,5min时间,job跑完收工!
hive中的distribute by
1.背景
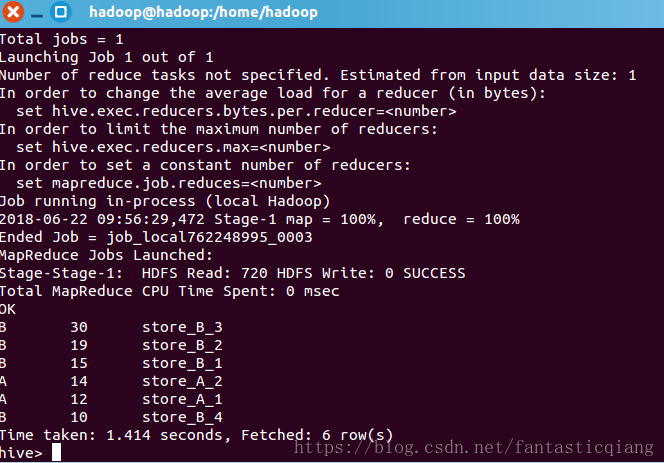
hive中有一个store表,字段分别是"商店所属人标识"(merid),“商户余额(money)”,“商店名称(name)”。求每个法人下属的商店的余额按照降序排序。
//merid,money,name B 10 store_B_4 A 12 store_A_1 A 14 store_A_2 B 15 store_B_1 B 19 store_B_2 B 30 store_B_3
2.distribute by、sort by
hive中(distribute by + “表中字段”)关键字控制map输出结果的分发,相同字段的map输出会发到一个reduce节点去处理。sort by为每一个reducer产生一个排序文件,他俩一般情况下会结合使用。
hive> select * from store distribute by merid sort by money desc;
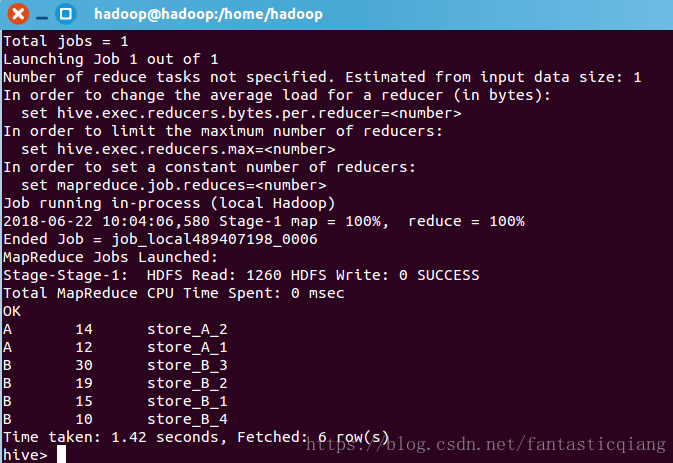
3.cluster by
cluster by 相当于 distribute by 和sort by 的结合,默认只能是升序,以下两种写法查询结果相同
//cluster by hive>select * from store cluster by merid; //distribute by,sort by hive>select * from store distribute by merid sort by merid asc;
[Hive]Hive数据倾斜(大表join大表)
业务背景
用户轨迹工程的性能瓶颈一直是etract_track_info,其中耗时大户主要在于trackinfo与pm_info进行左关联的环节,trackinfo与pm_info两张表均为GB级别,左关联代码块如下:
from trackinfo a left outer join pm_info b on (a.ext_field7 = b.id)
使用以上代码块需要耗时1.5小时。
优化流程
第一次优化
考虑到pm_info表的id是bigint类型,trackinfo表的ext_field7是string类型,其关联时数据类型不一致,默认的hash操作会按bigint型的id进行分配,这样会导致所有string类型的ext_field7集中到一个reduce里面,因此,改为如下
from trackinfo a left outer join pm_info b on (cast(a.ext_field7 as bigint) = b.id)
改动为上面代码后,效果仍然不理想,耗时为1.5小时。
第二次优化
考虑到trackinfo表的ext_field7字段缺失率很高(为空、字段长度为零、字段填充了非整数)情况,做进行左关联时空字段的关联操作实际上没有意义,因此,如果左表关联字段ext_field7为无效字段,则不需要关联,因此,改为如下:
from trackinfo a left outer join pm_info b on (a.ext_field7 is not null and length(a.ext_field7) > 0 and a.ext_field7 rlike '^[0-9]+$' and a.ext_field7 = b.id)
上面代码块的作用是,如果左表关联字段ext_field7为无效字段时(为空、字段长度为零、字段填充了非整数),不去关联右表,由于空字段左关联以后取到的右表字段仍然为null,所以不会影响结果。
改动为上面代码后,效果仍然不理想,耗时为50分钟。
第三次优化
想了很久,第二次优化效果效果不理想的原因,其实是在左关联中,虽然设置了左表关联字段为空不去关联右表,但是这样做,左表中未关联的记录(ext_field7为空)将会全部聚集在一个reduce中进行处理,体现为reduce进度长时间处在99%。
换一种思路,解决办法的突破点就在于如何把左表的未关联记录的key尽可能打散,因此可以这么做:若左表关联字段无效(为空、字段长度为零、字段填充了非整数),则在关联前将左表关联字段设置为一个随机数,再去关联右表,这么做的目的是即使是左表的未关联记录,它的key也分布得十分均匀
from trackinfo a left outer join pm_info b on ( case when (a.ext_field7 is not null and length(a.ext_field7) > 0 and a.ext_field7 rlike '^[0-9]+$') then cast(a.ext_field7 as bigint) else cast(ceiling(rand() * -65535) as bigint) end = b.id )
第三次改动后,耗时从50分钟降为了1分钟32秒,效果显著!
数据倾斜案列四
https://www.cnblogs.com/ggjucheng/archive/2013/01/03/2842860.html 原始博客
在做Shuffle阶段的优化过程中,遇到了数据倾斜的问题,造成了对一些情况下优化效果不明显。主要是因为在Job完成后的所得到的Counters是整个Job的总和,优化是基于这些Counters得出的平均值,而由于数据倾斜的原因造成map处理数据量的差异过大,使得这些平均值能代表的价值降低。Hive的执行是分阶段的,map处理数据量的差异取决于上一个stage的reduce输出,所以如何将数据均匀的分配到各个reduce中,就是解决数据倾斜的根本所在。规避错误来更好的运行比解决错误更高效。在查看了一些资料后,总结如下。
1数据倾斜的原因
1.1操作:
|
关键词 |
情形 |
后果 |
|
Join |
其中一个表较小, 但是key集中 |
分发到某一个或几个Reduce上的数据远高于平均值 |
|
大表与大表,但是分桶的判断字段0值或空值过多 |
这些空值都由一个reduce处理,灰常慢 |
|
|
group by |
group by 维度过小, 某值的数量过多 |
处理某值的reduce灰常耗时 |
|
Count Distinct |
某特殊值过多 |
处理此特殊值的reduce耗时 |
1.2原因:
1)、key分布不均匀
2)、业务数据本身的特性
3)、建表时考虑不周
4)、某些SQL语句本身就有数据倾斜
1.3表现:
任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
2数据倾斜的解决方案
2.1参数调节:
hive.map.aggr=true
Map 端部分聚合,相当于Combiner
hive.groupby.skewindata=true
有数据倾斜的时候进行负载均衡,当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
2.2 SQL语句调节:
如何Join:
关于驱动表的选取,选用join key分布最均匀的表作为驱动表
做好列裁剪和filter操作,以达到两表做join的时候,数据量相对变小的效果。
大小表Join:
使用map join让小的维度表(1000条以下的记录条数) 先进内存。在map端完成reduce.
大表Join大表:
把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终结果。
count distinct大量相同特殊值
count distinct时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
group by维度过小:
采用sum() group by的方式来替换count(distinct)完成计算。
特殊情况特殊处理:
在业务逻辑优化效果的不大情况下,有些时候是可以将倾斜的数据单独拿出来处理。最后union回去。
3典型的业务场景
3.1空值产生的数据倾斜
场景:如日志中,常会有信息丢失的问题,比如日志中的 user_id,如果取其中的 user_id 和 用户表中的user_id 关联,会碰到数据倾斜的问题。
解决方法1: user_id为空的不参与关联(红色字体为修改后)

select * from log a join users b on a.user_id is not null and a.user_id = b.user_id union all select * from log a where a.user_id is null;
解决方法2 :赋与空值分新的key值
select * from log a left outer join users b on case when a.user_id is null then concat(‘hive’,rand() ) else a.user_id end = b.user_id;
结论:方法2比方法1效率更好,不但io少了,而且作业数也少了。解决方法1中 log读取两次,jobs是2。解决方法2 job数是1 。这个优化适合无效 id (比如 -99 , ’’, null 等) 产生的倾斜问题。把空值的 key 变成一个字符串加上随机数,就能把倾斜的数据分到不同的reduce上 ,解决数据倾斜问题。
3.2不同数据类型关联产生数据倾斜
场景:用户表中user_id字段为int,log表中user_id字段既有string类型也有int类型。当按照user_id进行两个表的Join操作时,默认的Hash操作会按int型的id来进行分配,这样会导致所有string类型id的记录都分配到一个Reducer中。
解决方法:把数字类型转换成字符串类型
select * from users a left outer join logs b on a.usr_id = cast(b.user_id as string)
3.3小表不小不大,怎么用 map join 解决倾斜问题
使用 map join 解决小表(记录数少)关联大表的数据倾斜问题,这个方法使用的频率非常高,但如果小表很大,大到map join会出现bug或异常,这时就需要特别的处理。 以下例子:
select * from log a left outer join users b on a.user_id = b.user_id;
users 表有 600w+ 的记录,把 users 分发到所有的 map 上也是个不小的开销,而且 map join 不支持这么大的小表。如果用普通的 join,又会碰到数据倾斜的问题。
解决方法:
select /*+mapjoin(x)*/* from log a
left outer join (
select /*+mapjoin(c)*/d.*
from ( select distinct user_id from log ) c
join users d
on c.user_id = d.user_id
) x
on a.user_id = b.user_id;
假如,log里user_id有上百万个,这就又回到原来map join问题。所幸,每日的会员uv不会太多,有交易的会员不会太多,有点击的会员不会太多,有佣金的会员不会太多等等。所以这个方法能解决很多场景下的数据倾斜问题。
4总结
使map的输出数据更均匀的分布到reduce中去,是我们的最终目标。由于Hash算法的局限性,按key Hash会或多或少的造成数据倾斜。大量经验表明数据倾斜的原因是人为的建表疏忽或业务逻辑可以规避的。在此给出较为通用的步骤:
1、采样log表,哪些user_id比较倾斜,得到一个结果表tmp1。由于对计算框架来说,所有的数据过来,他都是不知道数据分布情况的,所以采样是并不可少的。
2、数据的分布符合社会学统计规则,贫富不均。倾斜的key不会太多,就像一个社会的富人不多,奇特的人不多一样。所以tmp1记录数会很少。把tmp1和users做map join生成tmp2,把tmp2读到distribute file cache。这是一个map过程。
3、map读入users和log,假如记录来自log,则检查user_id是否在tmp2里,如果是,输出到本地文件a,否则生成<user_id,value>的key,value对,假如记录来自member,生成<user_id,value>的key,value对,进入reduce阶段。
4、最终把a文件,把Stage3 reduce阶段输出的文件合并起写到hdfs。
如果确认业务需要这样倾斜的逻辑,考虑以下的优化方案:
1、对于join,在判断小表不大于1G的情况下,使用map join
2、对于group by或distinct,设定 hive.groupby.skewindata=true
3、尽量使用上述的SQL语句调节进行优化


 浙公网安备 33010602011771号
浙公网安备 33010602011771号