爬虫
方法一:采用 WebClient ,代码如下
using System.Net;
{
string strurl="网址";
WebClient aWebClient = new WebClient();
aWebClient.Encoding = System.Text.Encoding.UTF8;
string htmlcode = aWebClient.DownloadString(strurl);
txtbox.Text=htmlcode;//txtbox为一个文本框
}
方法二:采用 HttpWebRequest HttpWebResponse ,代码如下
using System.Net;
{
string strurl = "http://www.weather.com.cn/weather/101310101.shtml?from=cn";
HttpWebRequest myReq = (HttpWebRequest)WebRequest.Create(strurl);
myReq.Accept = "Accept-Languat:zh-cn";
myReq.AllowAutoRedirect = true;
myReq.MaximumAutomaticRedirections = 1;
myReq.Referer = "weather";
HttpWebResponse myResponse =
(HttpWebResponse)myReq.GetResponse();
Stream myStream = myResponse.GetResponseStream();
StreamReader myReader = new StreamReader(myStream,
System.Text.Encoding.UTF8);
txtbox.Text = myReader.ReadToEnd();//txtbox为一个文本框
}
2.添加引用
Winista.HtmlParser.dll
static void Main(string[] args)
{
string strurl = "http://hq.cnpc/cwb/news/bnxx/Pages/20171228_C1852.aspx ";
WebClient aWebClient = new WebClient();
aWebClient.Encoding = System.Text.Encoding.UTF8;
string htmlcode = aWebClient.DownloadString(strurl);
//Console.WriteLine(htmlcode);
Parser parser = Parser.CreateParser(htmlcode, "utf-8");//GBK
HtmlPage page = new HtmlPage(parser);
HasAttributeFilter filter = new HasAttributeFilter("id", "contentText");
NodeList result = parser.Parse(filter);
TagNode tag = (TagNode)result[0];
Console.WriteLine(result.ToHtml().ToString());
Console.WriteLine(tag.GetAttribute("id"));
Console.ReadKey();
}
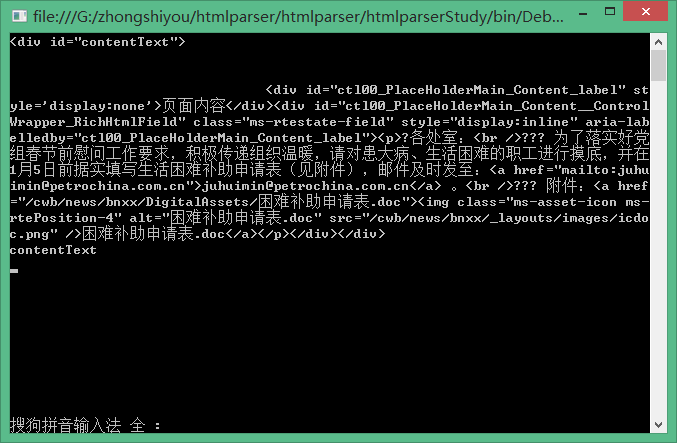
3.输出:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号