Python 之 解码汉字乱码(如果gbk、utf8都试过不行,可以试试这个)
起因:
使用 requests.get(url) 获取页面内容,并打印出来后显示如下:
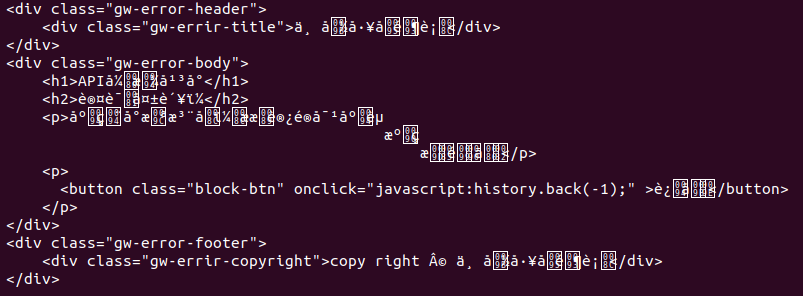
使用 type() 查看类型也是 <type 'unicode'>
print [content] 显示的也是像utf-8的样子:[u'<div class="gw-error-body">\n\t\t<h1>API\xe5\xbc\x80\xe6\x94\xbe\xe5\xb9\xb3\xe5\x8f\xb0</h1>\n\t\t<h2>\xe8\xae\xa4\xe8\xaf\x81\xe5\xa4\xb1\xe8\xb4\xa5\xef\xbc\x9a</h2>\n\t\t<p>\xe5\xba\x94\xe7\x94\xa8\xe5\xb0\x9a\xe6\x9c\xaa\xe6\xb3\xa8\xe5\x86\x8c\xef\xbc\x8c\xe6\x88\x96\xe6\x98\xaf\xe6\xb2\xa1\xe6\x9c\x89\xe8\xae\xbf\xe9\x97\xae\xe5\xaf\xb9\xe5\xba\x94\xe8\xb5\x84\xe6\xba\x90\xe7\x9a\x84\xe6\x9d\x83\xe9\x99\x90\xe3\x80\x82</p>\n\t\t<p>\n\t\t\t<button class="block-btn" onclick="javascript:history.back(-1);" >\xe8\xbf\x94\xe5\x9b\x9e</button>\n\t\t</p>\n\t</div>'],要注意开头的u,正常的utf-8是没有这个的。
也没有BOM头,utf-8,utf-16, utf8-sig,gbk试了个遍也没打印出中文,后来终于找到个解决办法。
解决办法I :----是个办法,但不是正规办法
原文:https://www.v2ex.com/t/304608
取到的网页文字内容在编码上存在一定的 trick ,简单来说就是 unicode 形式的 gbk 编码内容,形如: u'\xd6\xb0\xce\xbb\xc3\xe8\xca\xf6'
而事实上,这个字符串实际所要表达的 gbk 编码内容为
'\xd6\xb0\xce\xbb\xc3\xe8\xca\xf6',对应的汉字字符为“职位描述”
解这个问题可参见
http://stackoverflow.com/questions/14539807/convert-unicode-with-utf-8-string-as-content-to-str
可以看到,关键之处在于利用了以下这一特性:
Unicode codepoints U+0000 to U+00FF all map one-on-one with the latin-1 encoding
先将 unicode 字符串编码为 latin1 字符串,编码后保留了等价的字节流数据。
而此时在这个问题中,这一字节流数据又恰恰对应了 gbk 编码,因此对其进行解码即可还原最初的 unicode 字符。
不过值得注意的是,需要确定的是形如\xd6\xb0 究竟是 utf8 编码还是类似 gbk 类型的其他编码,
这一点对于最终正确还原 unicode 字符同样重要。
综上所述,对拿到的 content 执行以下操作即可:
content.encode("latin1").decode("gbk")
解决办法II :----正规办法
1 resp = requests.get('http://www.******')
2 print resp.encoding # ISO-8859-1
3 print resp.apparent_encoding # GB2312
4 resp.encoding = resp.apparent_encoding
5 content = resp.text
6 print content
原文:http://xiaorui.cc/2016/02/19/%E4%BB%A3%E7%A0%81%E5%88%86%E6%9E%90python-requests%E5%BA%93%E4%B8%AD%E6%96%87%E7%BC%96%E7%A0%81%E9%97%AE%E9%A2%98/requests会从服务器返回的响应头的 Content-Type 去获取字符集编码,如果content-type有charset字段那么requests才能正确识别编码,否则就使用默认的 ISO-8859-1. 一般那些不规范的页面往往有这样的问题。
所以,通过 resp.apparent_encoding 来查看本页面使用的编码(上例子中为GB2312),在明确了网页的字符集编码后可以使用 resp.encoding = 'GB2312' 获取正确结果。
完整代码:
1 # coding=utf-8
2 import requests
3
4 resp = requests.get('http://www.******')
5 resp.encoding = resp.apparent_encoding
6 print resp.text
7
8
9 # print resp.text.encode("latin1").decode("utf-8") # 这里的utf-8改成gbk就会报错,但有时候又情况相反,所以觉得这不是个正规办法
运行:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号