


SQLServer学习笔记系列1
一.前言
一直自己没有学习做笔记的习惯,所以为了加强自己对知识的深入理解,决定将学习笔记写下来,希望向各位大牛们学习交流!
不当之处请斧正!在此感谢!这边就先从学习Sqlserver写起,自己本身对数据库方面不擅长,所以决定对此从基础开始学习,
大牛们对此文可以忽略!首先以《Sqlserver2008技术内幕》这本书作为学习的指导,大家如果觉得这本书不错的话,
可以去网上买一本,作为菜鸟的我,觉得这本书对于入门介绍的还是非常不错的。
请戳我:http://item.jd.com/10067484.html#none。
二.Sqlserver基础知识
(1)创建数据库
创建数据库有两种方式,手动创建和编写sql脚本创建,在这里我采用脚本的方式创建一个名称为TSQLFundamentals2008的数据库。
脚本如下:


1 --------------------------------------------------------------------- 2 -- Microsoft SQL Server 2008 T-SQL Fundamentals 3 -- 4 -- Script that creates the sample database TSQLFundamentals2008 5 -- 6 -- Supported versions of SQL Server: 2005, 2008 7 -- 8 -- Based originally on the Northwind sample database 9 -- with changes in both schema and data to fit the book's needs 10 -- 11 -- Last updated: 20081202 12 --------------------------------------------------------------------- 13 14 --------------------------------------------------------------------- 15 -- Create Database 16 --------------------------------------------------------------------- 17 18 USE master; 19 20 -- Drop database 21 IF DB_ID('TSQLFundamentals2008') IS NOT NULL DROP DATABASE TSQLFundamentals2008; 22 23 -- If database could not be created due to open connections, abort 24 IF @@ERROR = 3702 25 RAISERROR('Database cannot be dropped because there are still open connections.', 127, 127) WITH NOWAIT, LOG; 26 27 -- Create database 28 CREATE DATABASE TSQLFundamentals2008; 29 GO 30 31 USE TSQLFundamentals2008; 32 GO 33 34 --------------------------------------------------------------------- 35 -- Create Schemas 36 --------------------------------------------------------------------- 37 38 CREATE SCHEMA HR AUTHORIZATION dbo; 39 GO 40 CREATE SCHEMA Production AUTHORIZATION dbo; 41 GO 42 CREATE SCHEMA Sales AUTHORIZATION dbo; 43 GO 44 45 --------------------------------------------------------------------- 46 -- Create Tables 47 --------------------------------------------------------------------- 48 49 -- Create table HR.Employees 50 CREATE TABLE HR.Employees 51 ( 52 empid INT NOT NULL IDENTITY, 53 lastname NVARCHAR(20) NOT NULL, 54 firstname NVARCHAR(10) NOT NULL, 55 title NVARCHAR(30) NOT NULL, 56 titleofcourtesy NVARCHAR(25) NOT NULL, 57 birthdate DATETIME NOT NULL, 58 hiredate DATETIME NOT NULL, 59 address NVARCHAR(60) NOT NULL, 60 city NVARCHAR(15) NOT NULL, 61 region NVARCHAR(15) NULL, 62 postalcode NVARCHAR(10) NULL, 63 country NVARCHAR(15) NOT NULL, 64 phone NVARCHAR(24) NOT NULL, 65 mgrid INT NULL, 66 CONSTRAINT PK_Employees PRIMARY KEY(empid), 67 CONSTRAINT FK_Employees_Employees FOREIGN KEY(mgrid) 68 REFERENCES HR.Employees(empid), 69 CONSTRAINT CHK_birthdate CHECK(birthdate <= CURRENT_TIMESTAMP) 70 ); 71 72 CREATE NONCLUSTERED INDEX idx_nc_lastname ON HR.Employees(lastname); 73 CREATE NONCLUSTERED INDEX idx_nc_postalcode ON HR.Employees(postalcode); 74 75 -- Create table Production.Suppliers 76 CREATE TABLE Production.Suppliers 77 ( 78 supplierid INT NOT NULL IDENTITY, 79 companyname NVARCHAR(40) NOT NULL, 80 contactname NVARCHAR(30) NOT NULL, 81 contacttitle NVARCHAR(30) NOT NULL, 82 address NVARCHAR(60) NOT NULL, 83 city NVARCHAR(15) NOT NULL, 84 region NVARCHAR(15) NULL, 85 postalcode NVARCHAR(10) NULL, 86 country NVARCHAR(15) NOT NULL, 87 phone NVARCHAR(24) NOT NULL, 88 fax NVARCHAR(24) NULL, 89 CONSTRAINT PK_Suppliers PRIMARY KEY(supplierid) 90 ); 91 92 CREATE NONCLUSTERED INDEX idx_nc_companyname ON Production.Suppliers(companyname); 93 CREATE NONCLUSTERED INDEX idx_nc_postalcode ON Production.Suppliers(postalcode); 94 95 -- Create table Production.Categories 96 CREATE TABLE Production.Categories 97 ( 98 categoryid INT NOT NULL IDENTITY, 99 categoryname NVARCHAR(15) NOT NULL, 100 description NVARCHAR(200) NOT NULL, 101 CONSTRAINT PK_Categories PRIMARY KEY(categoryid) 102 ); 103 104 CREATE INDEX categoryname ON Production.Categories(categoryname); 105 106 -- Create table Production.Products 107 CREATE TABLE Production.Products 108 ( 109 productid INT NOT NULL IDENTITY, 110 productname NVARCHAR(40) NOT NULL, 111 supplierid INT NOT NULL, 112 categoryid INT NOT NULL, 113 unitprice MONEY NOT NULL 114 CONSTRAINT DFT_Products_unitprice DEFAULT(0), 115 discontinued BIT NOT NULL 116 CONSTRAINT DFT_Products_discontinued DEFAULT(0), 117 CONSTRAINT PK_Products PRIMARY KEY(productid), 118 CONSTRAINT FK_Products_Categories FOREIGN KEY(categoryid) 119 REFERENCES Production.Categories(categoryid), 120 CONSTRAINT FK_Products_Suppliers FOREIGN KEY(supplierid) 121 REFERENCES Production.Suppliers(supplierid), 122 CONSTRAINT CHK_Products_unitprice CHECK(unitprice >= 0) 123 ); 124 125 CREATE NONCLUSTERED INDEX idx_nc_categoryid ON Production.Products(categoryid); 126 CREATE NONCLUSTERED INDEX idx_nc_productname ON Production.Products(productname); 127 CREATE NONCLUSTERED INDEX idx_nc_supplierid ON Production.Products(supplierid); 128 129 -- Create table Sales.Customers 130 CREATE TABLE Sales.Customers 131 ( 132 custid INT NOT NULL IDENTITY, 133 companyname NVARCHAR(40) NOT NULL, 134 contactname NVARCHAR(30) NOT NULL, 135 contacttitle NVARCHAR(30) NOT NULL, 136 address NVARCHAR(60) NOT NULL, 137 city NVARCHAR(15) NOT NULL, 138 region NVARCHAR(15) NULL, 139 postalcode NVARCHAR(10) NULL, 140 country NVARCHAR(15) NOT NULL, 141 phone NVARCHAR(24) NOT NULL, 142 fax NVARCHAR(24) NULL, 143 CONSTRAINT PK_Customers PRIMARY KEY(custid) 144 ); 145 146 CREATE NONCLUSTERED INDEX idx_nc_city ON Sales.Customers(city); 147 CREATE NONCLUSTERED INDEX idx_nc_companyname ON Sales.Customers(companyname); 148 CREATE NONCLUSTERED INDEX idx_nc_postalcode ON Sales.Customers(postalcode); 149 CREATE NONCLUSTERED INDEX idx_nc_region ON Sales.Customers(region); 150 151 -- Create table Sales.Shippers 152 CREATE TABLE Sales.Shippers 153 ( 154 shipperid INT NOT NULL IDENTITY, 155 companyname NVARCHAR(40) NOT NULL, 156 phone NVARCHAR(24) NOT NULL, 157 CONSTRAINT PK_Shippers PRIMARY KEY(shipperid) 158 ); 159 160 -- Create table Sales.Orders 161 CREATE TABLE Sales.Orders 162 ( 163 orderid INT NOT NULL IDENTITY, 164 custid INT NULL, 165 empid INT NOT NULL, 166 orderdate DATETIME NOT NULL, 167 requireddate DATETIME NOT NULL, 168 shippeddate DATETIME NULL, 169 shipperid INT NOT NULL, 170 freight MONEY NOT NULL 171 CONSTRAINT DFT_Orders_freight DEFAULT(0), 172 shipname NVARCHAR(40) NOT NULL, 173 shipaddress NVARCHAR(60) NOT NULL, 174 shipcity NVARCHAR(15) NOT NULL, 175 shipregion NVARCHAR(15) NULL, 176 shippostalcode NVARCHAR(10) NULL, 177 shipcountry NVARCHAR(15) NOT NULL, 178 CONSTRAINT PK_Orders PRIMARY KEY(orderid), 179 CONSTRAINT FK_Orders_Customers FOREIGN KEY(custid) 180 REFERENCES Sales.Customers(custid), 181 CONSTRAINT FK_Orders_Employees FOREIGN KEY(empid) 182 REFERENCES HR.Employees(empid), 183 CONSTRAINT FK_Orders_Shippers FOREIGN KEY(shipperid) 184 REFERENCES Sales.Shippers(shipperid) 185 ); 186 187 CREATE NONCLUSTERED INDEX idx_nc_custid ON Sales.Orders(custid); 188 CREATE NONCLUSTERED INDEX idx_nc_empid ON Sales.Orders(empid); 189 CREATE NONCLUSTERED INDEX idx_nc_shipperid ON Sales.Orders(shipperid); 190 CREATE NONCLUSTERED INDEX idx_nc_orderdate ON Sales.Orders(orderdate); 191 CREATE NONCLUSTERED INDEX idx_nc_shippeddate ON Sales.Orders(shippeddate); 192 CREATE NONCLUSTERED INDEX idx_nc_shippostalcode ON Sales.Orders(shippostalcode); 193 194 -- Create table Sales.OrderDetails 195 CREATE TABLE Sales.OrderDetails 196 ( 197 orderid INT NOT NULL, 198 productid INT NOT NULL, 199 unitprice MONEY NOT NULL 200 CONSTRAINT DFT_OrderDetails_unitprice DEFAULT(0), 201 qty SMALLINT NOT NULL 202 CONSTRAINT DFT_OrderDetails_qty DEFAULT(1), 203 discount NUMERIC(4, 3) NOT NULL 204 CONSTRAINT DFT_OrderDetails_discount DEFAULT(0), 205 CONSTRAINT PK_OrderDetails PRIMARY KEY(orderid, productid), 206 CONSTRAINT FK_OrderDetails_Orders FOREIGN KEY(orderid) 207 REFERENCES Sales.Orders(orderid), 208 CONSTRAINT FK_OrderDetails_Products FOREIGN KEY(productid) 209 REFERENCES Production.Products(productid), 210 CONSTRAINT CHK_discount CHECK (discount BETWEEN 0 AND 1), 211 CONSTRAINT CHK_qty CHECK (qty > 0), 212 CONSTRAINT CHK_unitprice CHECK (unitprice >= 0) 213 ) 214 215 CREATE NONCLUSTERED INDEX idx_nc_orderid ON Sales.OrderDetails(orderid); 216 CREATE NONCLUSTERED INDEX idx_nc_productid ON Sales.OrderDetails(productid); 217 GO
同时往数据库表插入一些数据,用户后续对数据库的sql的练习。在这里有需要的可以下载相应的脚本进行数据库的初始化。
我放到百度云上面,请戳我:http://yun.baidu.com/share/link?shareid=3635107613&uk=2971209779,
提供了《Sqlserver2008技术内幕》这本书的电子版和脚本。
(2)在这里对TSQLFundamentals2008数据各个表进行表说明一下:
数据库表界面如下:
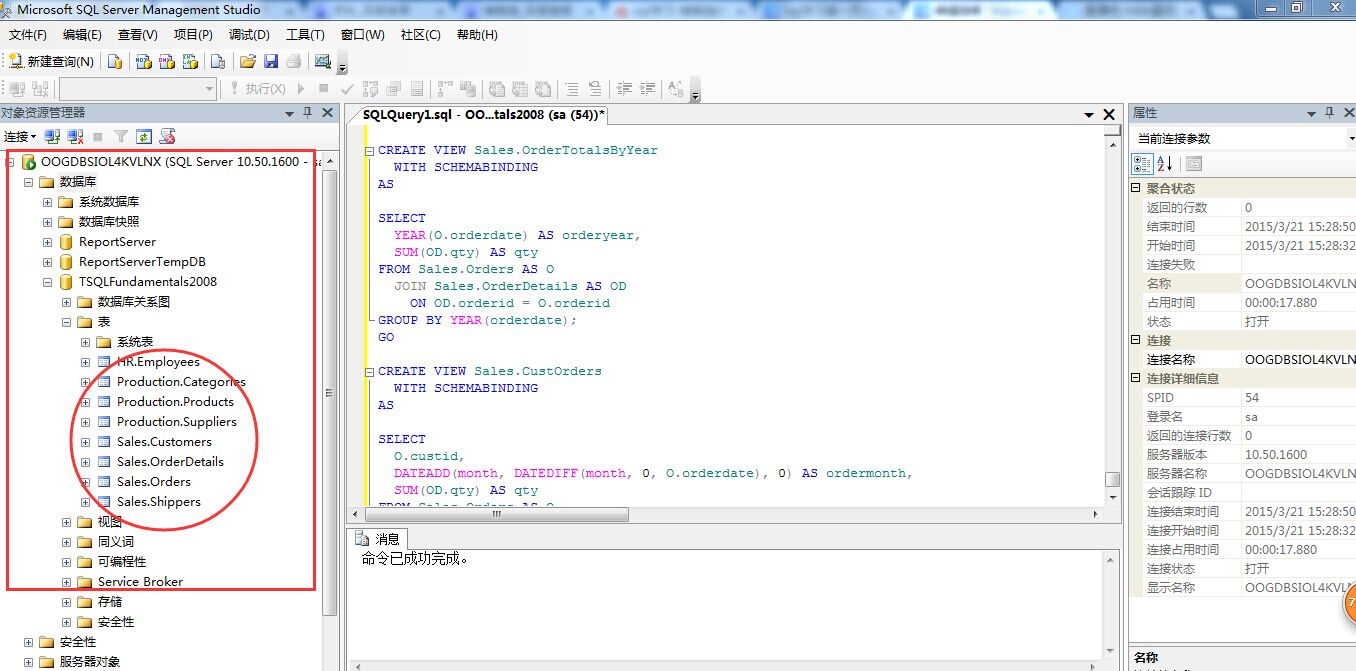
|
HR.Employees |
雇员表,存放员工的一些基本信息。 |
|
Production.Products |
产品信息表 |
|
Production.Suppliers |
供应商表 |
|
Production.Customers |
顾客信息表 |
|
Production.Categories |
产品类别表 |
|
Sales.OrderDetails |
订单详情表 |
|
Sales.Orders |
订单表 |
|
Sales.Shippers |
货运公司表 |
三.Sqlserver一些基本命令:
查询数据库是否存在:
if DB_ID("testDB")is not null;
检查表是否存在:
if OBJECT_ID(“textDB”,“U”) is not null ;其中U代表用户表
创建数据库:
create database+数据名
删除数据库:
四.单表查询
1 select country,count(*) as N'人数' 2 from hr.Employees 3 group by country
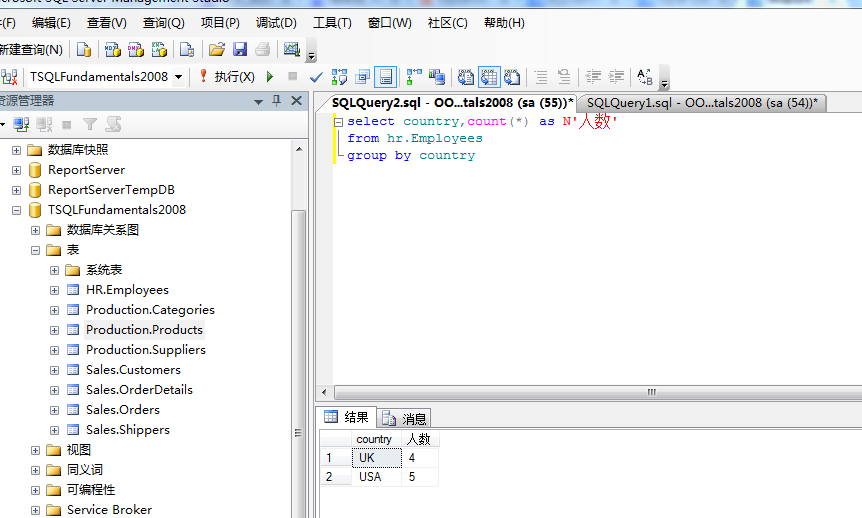
当要查询的字段不包含在group by子句中,则会报相应的错误,所以此时要注意出现在select 后面的查询字段进行分组后,也同时需要出现在group by后面。

(2)在这里提示一下:查询条件不要使用计算列,下面谈谈具体原因:
例如:查询雇员表里面雇员出生为1973年的所有雇员信息,可以这样编写sql语句:
1 select YEAR(birthdate),firstname,lastname from HR.Employees 2 where YEAR(birthdate)='1973'

可以看到查询结果将1973年的雇员信息查出来了,但是大家可以思考一下,上面的sql语句在查询的时候,首先是要讲birthdate进行取出年度的计算,
Year(birthdate),其中Year为sql的内置函数,可以用于对字符串日期进行取出年份的计算。同时我们还可以采用下面的sql语句进行查询:

通过sql执行计划可以看出来,查询条件带计算列走的是索引扫描,而where子句后面采用查找范围限制,则走的是索查找。对比两个查询显然绝大部分情况下
走索引查找的查询性能要高于走索引扫描,特别是查询的数据库不是非常大的情况下,索引查找的消耗时间要远远少于索引扫描的时间。所以在查询条件中尽
量避免计算条件。
(3)说说sqlserver中的null,null在数据库中表示不存在,与C#中的null不同,不表示空引用,没有对象,NULL的运算规则:有null的任何运算都是null。
is [not] null: 只能用做条件判断表达式,是否是null?是 条件为true,不是 条件为false。
isnull():函数,如果第一个参数是null,则用第二个参数的值替换第一个参数的值作为函数的返回值。记住:第二个参数的类型必须和第一个兼容。
nullif():函数,如果两个参数值相等、有一个参数是null、或两个参数是null,函数返回值是null;否则返回第一个参数的值。
(4)top用法:意在取出表中满足条件的前多少位。top 10---前10位
说到top,突然想到了面试题中经常出现的查询某表中的前30—40条记录,注意id可能不连续。利用top可以这样写:
1 select top 10 * from A where ID 2 not in(select top 30 ID from A order by ID asc) 3 order by ID asc
同时也可以采用如下写法,只不过可读性比较差:
1 select top 10 * fron A where ID> 2 (select Max(ID) from (select top 30 ID from A order by ID)as t) 3 order by ID asc
当然既然有范围in存在,就可以用exist实现:
1 select top 10 * from A a1 2 WHERE NOT EXISTS 3 (SELECT * from 4 (SELECT TOP 30 * FROM A ORDER BY id asc) a2 5 WHERE a2.id =a1.id 6 )
但是目前需要考虑到----相关子查询:主查询每遍历一条记录时,都要针对主查询的值执行子查询,所以效率比较低。
下面介绍一下top与percent联合使用,percent表示所占的百分比:例如查询雇员表里面,前面百分之二十的雇员的信息,可以写sql,查询结果为两人。
1 select top(20) percent * from hr.employees

我们在查询一下hr.employees(雇员表),同时查询一下雇员表里面总共有多少人,查出结果显示有9人。
1 select count(*) as N'总人数' from hr.employees
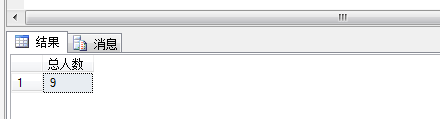
可以看出,9个人按百分之二十取整数了,所以查出来的显示有两个人。
(5)with ties附加属性:
当我们查询订单表时,查询sql:
1 select orderid,orderdate 2 from sales.orders order by orderdate desc
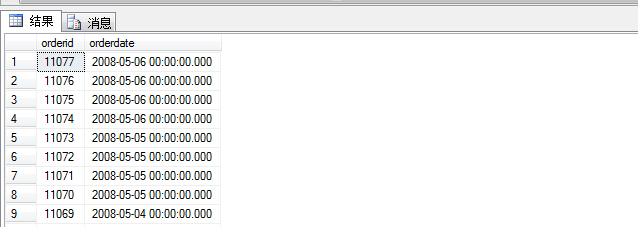
加入我们查询前五个订单信息时候,加入top 5
1 select top 5 orderid,orderdate 2 from sales.orders order by orderdate desc
查询结果如图:
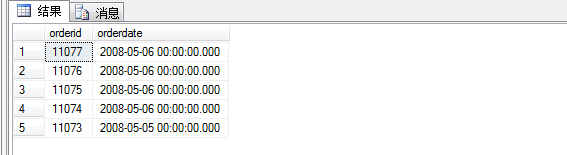
对比没有加top 5,查询结果截取了前五条订单信息,但是有时候我们需要将与最后一条订单日期相同的一起取出来,此时就需要采用附加属性with ties。

(6)over开窗函数:
上面讲到要用count聚合函数,在需要分组求和。但采用over 则可以同样实现基于什么的求和。省去group by。
1 select firstname,lastname ,count(*) over() as N'总人数' 2 from hr.employees
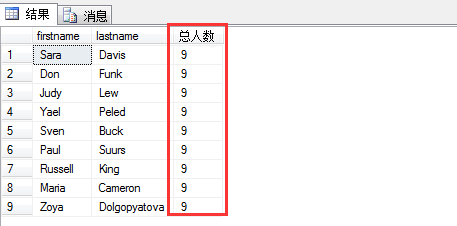
其中over(),括号里面可以附加条件,基于什么进行汇总。不添加,则表示对所有的记录进行汇总。例如求每位顾客所消费的订单总额,可以这样写:
1 select orderid,custid,sum(val) over (partition by custid) as N'顾客消费总额', 2 sum(val) over() as N'订单总额' from sales.ordervalues

五.排名函数
(1)row_number,行号,一般与over联合使用。over基于什么排名。
1 select row_number() over(order by lastname) as N'行号', lastname,firstname 2 from hr.employees
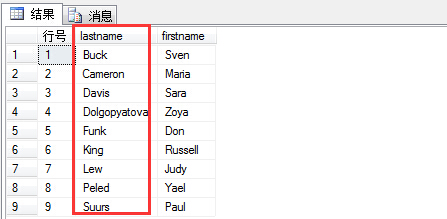
(2)rank ,排名,真正意义上的排名,例如:
1 select country,row_number() over(order by country) as N'rank排名', lastname,firstname 2 from hr.employees
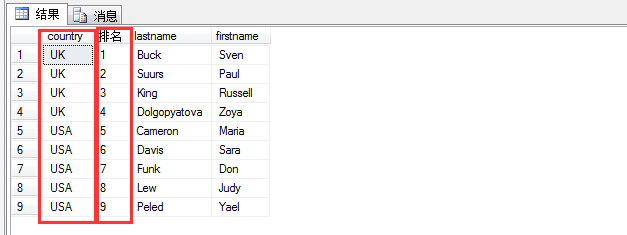
可以看出,根据country排名,确实排出来啦,但是发现前四位同为UK,按理来说使部分先后顺序的,所以在此可以用rank来操作。
1 select country,rank() over(order by country) as N'rank排名', lastname,firstname 2 from hr.employees

可以看出来,使用rank以后,country同为UK的并列第一,类似于学生考试成绩排名并列第一的情况。
(3)dense_rank,密集排名
通过上面rank排名以后,存在并列第一的情况,但是country为USA的应该为第二,所以就出现了使用密集排名dense_rank进行排名。
1 select country,dense_rank() over(order by country) as N'dense_rank排名', lastname,firstname 2 from hr.employees
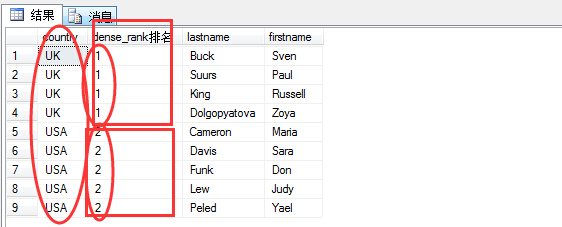
可以看出采用dense_rank以后,就满足了某一条件下,同属一个名次的需求。
(4)分组ntile。按某一条件进行分组。
1 select country,ntile(3) over (order by country) as N'ntile分组',dense_rank() over(order by country) as N'dense_rank排名', lastname,firstname 2 from hr.employees 3 order by country

有时候为了在某一个范围内进行排序,比如:
1 select lastname,firstname,country,row_number() over( order by country) as N'排名' 2 from hr.employees

为了实现根据在country范围内排序,即country为Uk的为一组进行排序,country为USA的为一组进行排序。可以这样写:
1 select lastname,firstname,country,row_number() over( partition by country order by country) as N'排名' 2 from hr.employees
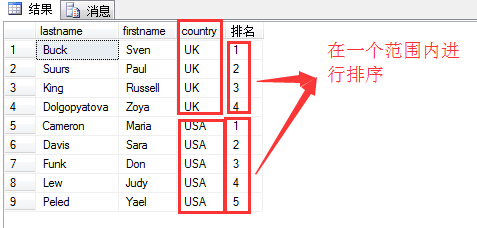
希望各位大牛给出指导,不当之处虚心接受学习!谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号