
作业3
作业1
1.气象网页爬取实验
实验要求
指定一个网站,爬取这个网站中的所有的所有图片,中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
输出信息:将下载的图片保存在images子文件夹中
导入库:
requests:发送请求获取数据
BeautifulSoup:解析数据,获取url
urljoin:拼接图片url,把相对 URL 转换成完整 URL
time:设置爬取时间间隔,避免被网站注意
re:使用正则表达式搜索/匹配字符串
hashlib:用于计算图片哈希值,实现对图片去重
threading:多线程爬取(控制并发)
实验思路:
单双线程共通:
(1)通过F12查看页面代码,可知网页中图片一般包含“img”字符或在<img...>元素下,可采用正则表达式来匹配。
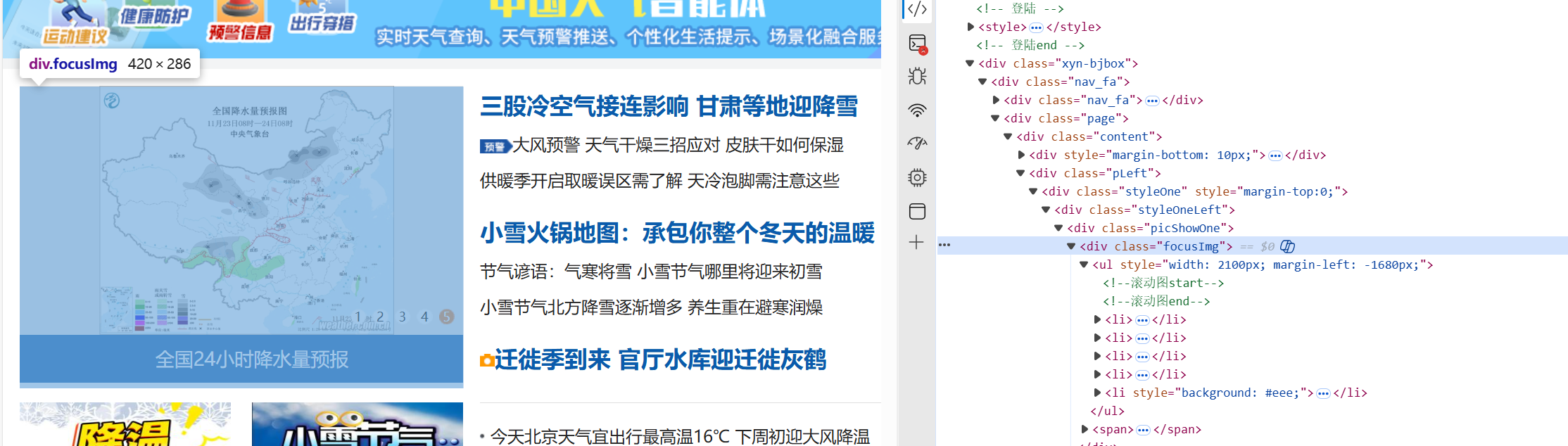

(2)注意到主持人中的图片位于外部页面中,我们要先找到link rel="stylesheet"的元素,取出它们的 href,通过urljoin将其外部css路径转换为完整url进行爬取


核心代码:
点击查看代码
# --- 单线程爬取主函数 (匹配所有图片URL并去重) ---
def single_threaded_all_images_crawler_deduplicated(url):
print(f"\n--- 正在使用单线程爬取所有图片 (HTML和CSS中的URL,并去重): {url} ---")
# 创建保存图片的目录
base_dir = "images_single_threaded_deduplicated" # 更新目录名称以便区分
if not os.path.exists(base_dir):
os.makedirs(base_dir)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36',
'Referer': url
}
all_potential_image_urls = set() # 使用set存储唯一的图片URL
all_css_content = [] # 存储所有收集到的CSS内容
seen_hashes = set() # 存储已下载图片内容的MD5哈希值,用于去重
try:
# 1. 获取主页内容
print(f"正在获取主页: {url}")
response = requests.get(url, timeout=10, headers=headers)
response.raise_for_status()
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
# 2. 提取<img>标签的src (使用BeautifulSoup)
img_tags = soup.find_all('img')
for img in img_tags:
src = img.get('src')
if src:
abs_img_url = urljoin(url, src)
all_potential_image_urls.add((abs_img_url, url + " (via <img> tag)"))
# 3. 收集所有CSS内容 (页面内嵌和外部)
print("正在收集页面内嵌和外部CSS内容...")
style_blocks = soup.find_all('style')
for style_tag in style_blocks:
if style_tag.string:
all_css_content.append(style_tag.string)
link_tags = soup.find_all('link', rel='stylesheet')
for link_tag in link_tags:
css_href = link_tag.get('href')
if css_href:
abs_css_url = urljoin(url, css_href)
print(f"尝试获取外部CSS文件: {abs_css_url}")
try:
css_response = requests.get(abs_css_url, timeout=5, headers=headers)
css_response.raise_for_status()
all_css_content.append(css_response.text)
except requests.exceptions.RequestException as e:
print(f"获取外部CSS文件失败 {abs_css_url}: {e}")
time.sleep(0.5) # 稍微暂停
# 4. 使用正则表达式从所有文本中匹配图片URL
print("正在使用正则表达式从HTML和所有CSS内容中查找所有图片URL...")
combined_text_for_regex = html_content + "\n" + "\n".join(all_css_content)
# 匹配以.png, .jpg, .jpeg, .gif, .webp, .svg 结尾的URL
image_url_pattern = re.compile(
r'(?:'
r'src=["\']?(?P<src_url>[^"\'>\s]+?\.(?:png|jpe?g|gif|webp|svg))'
r'|href=["\']?(?P<href_url>[^"\'>\s]+?\.(?:png|jpe?g|gif|webp|svg))'
r'|url\((?:[\'"]?)(?P<css_url>[^)\'"]+?\.(?:png|jpe?g|gif|webp|svg))[\'"]?\)'
r'|(?P<plain_url>https?://[^"\')\s]+?\.(?:png|jpe?g|gif|webp|svg))'
r')',
re.IGNORECASE
)
for match in image_url_pattern.finditer(combined_text_for_regex):
img_src = match.group('src_url') or \
match.group('href_url') or \
match.group('css_url') or \
match.group('plain_url')
if img_src and not img_src.startswith('data:'):
abs_img_url = urljoin(url, img_src)
all_potential_image_urls.add((abs_img_url, url + " (via regex)"))
print(f"通过正则表达式找到 {len(all_potential_image_urls)} 个潜在图片URL.")
except requests.exceptions.RequestException as e:
print(f"获取主页或处理图片链接失败: {e}")
return
print(f"\n总共收集到 {len(all_potential_image_urls)} 个潜在图片URL (包括<img>标签和正则表达式匹配).")
# 5. 下载所有收集到的图片 (单线程)
if not all_potential_image_urls:
print("没有找到任何图片可供下载。")
return
print("开始下载所有图片 (单线程)...")
downloaded_count = 0 # 统计实际下载的图片数量
for i, img_url_tuple in enumerate(list(all_potential_image_urls)): # 转换为list以便索引
if download_image(img_url_tuple[0], base_dir, i, img_url_tuple[1], headers, seen_hashes):
downloaded_count += 1
print(f"实际下载了 {downloaded_count} 张不重复的图片。")
print(f"--- 单线程爬取完成: {url} ---")
对于多线程:
用threading 设置互斥锁避免冲突,再采用ThreadPoolExecutor 线程池把每一个下载任务丢进线程池并发执行
点击查看代码
seen_hashes = set()
hash_lock = threading.Lock()
# === 初始化 ThreadPoolExecutor ===
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# 提交下载任务到线程池
futures = []
for i, img_url_tuple in enumerate(list(all_potential_image_urls)): # 转换为list以便索引
# 每个下载任务都需要seen_hashes和hash_lock
futures.append(
executor.submit(download_image, img_url_tuple[0], base_dir, i, img_url_tuple[1], headers, seen_hashes,
hash_lock))
downloaded_count = 0
# 等待所有任务完成并收集结果
for future in as_completed(futures):
if future.result(): # 如果下载成功(且内容不重复)
downloaded_count += 1
print(f"实际下载了 {downloaded_count} 张不重复的图片。")
print(f"--- 多线程爬取完成: {url} ---")
实验结果:
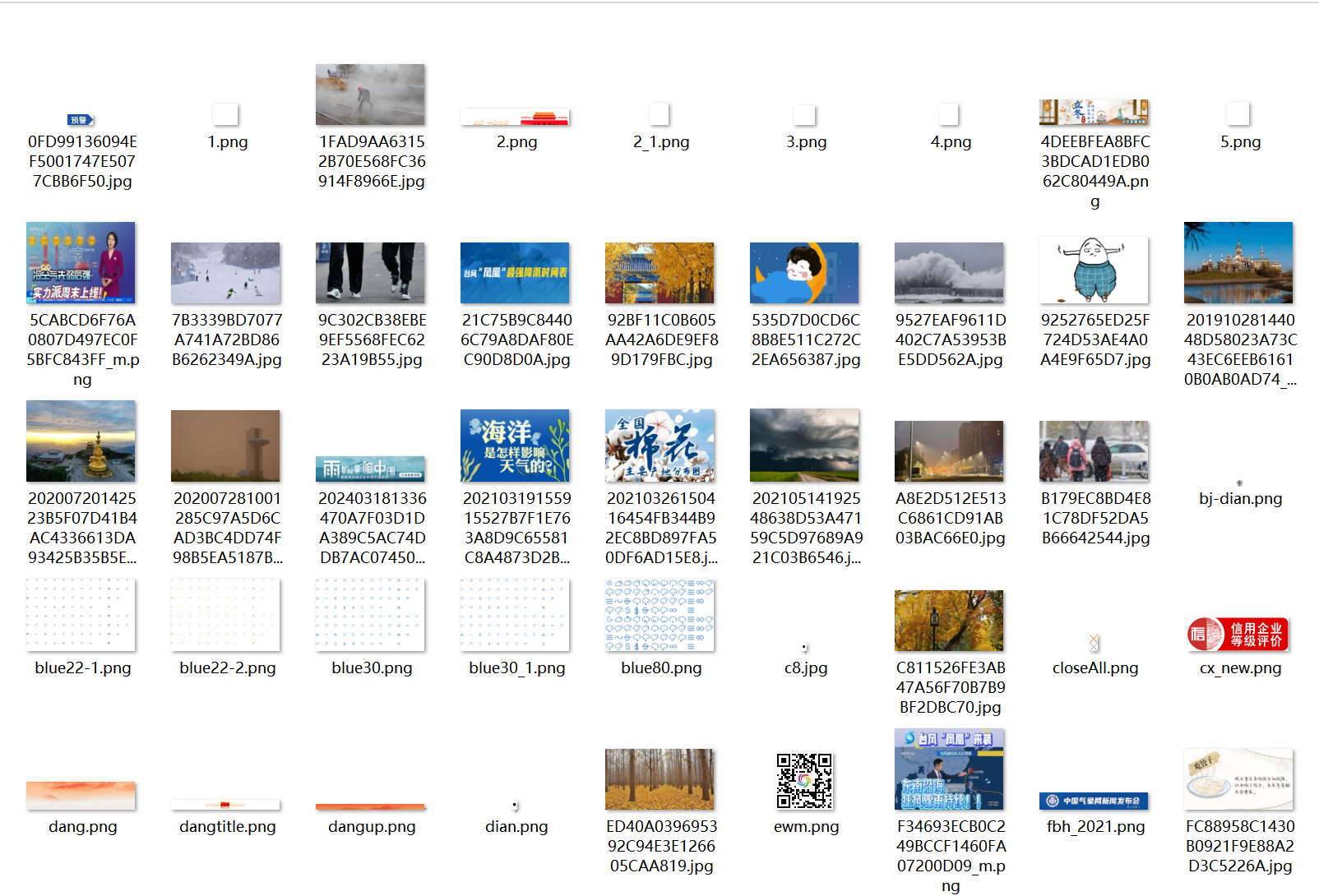

实验心得:
(1)初次爬取时发现有重复图片,最后是采用为每个图片计算哈希值,去除相同哈希值图片的方法进行解决,可能是正则表达式的原因导致重复,需要再考虑。
(2)理解相对路径与绝对路径区别,避免路径错误导致爬取失败。
作业2
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
导入库:
scrapy:调度、下载网页、解析数据、管理 item 和 pipeline
pymysql:把 Scrapy 生成的数据写入 MySQL 数据库
项目结构:
点击查看代码
stock/
├── stock/ # Scrapy 项目主包
│ ├── __init__.py
│ ├── items.py # Item 定义(数据字段)
│ ├── middlewares.py # Spider 中间件 & 下载器中间件
│ ├── pipelines.py # 数据处理管道(通常用于存储到 DB)
│ ├── settings.py # Scrapy 配置文件
│ └── spiders/ # 爬虫目录
│ ├── __init__.py
│ └── spider.py # 主爬虫 Spider 文件
│
├── main.py # 手动运行 Scrapy 的入口脚本(可选)
└── scrapy.cfg # Scrapy 项目的全局配置文件
核心代码:
item.py(定义数据结构)
点击查看代码
import scrapy
class StockItem(scrapy.Item):
# 定义item的字段,全部使用中文
股票代码 = scrapy.Field()
股票名称 = scrapy.Field()
最新价 = scrapy.Field()
涨跌幅 = scrapy.Field()
涨跌额 = scrapy.Field()
成交量 = scrapy.Field()
成交额 = scrapy.Field()
振幅 = scrapy.Field()
最高 = scrapy.Field()
最低 = scrapy.Field()
今开 = scrapy.Field()
昨收 = scrapy.Field()
spider.py(实际爬虫的逻辑定义 Spider 类)
找到网页中的数据接口url,将json格式内容转换为html,再用xpath解析
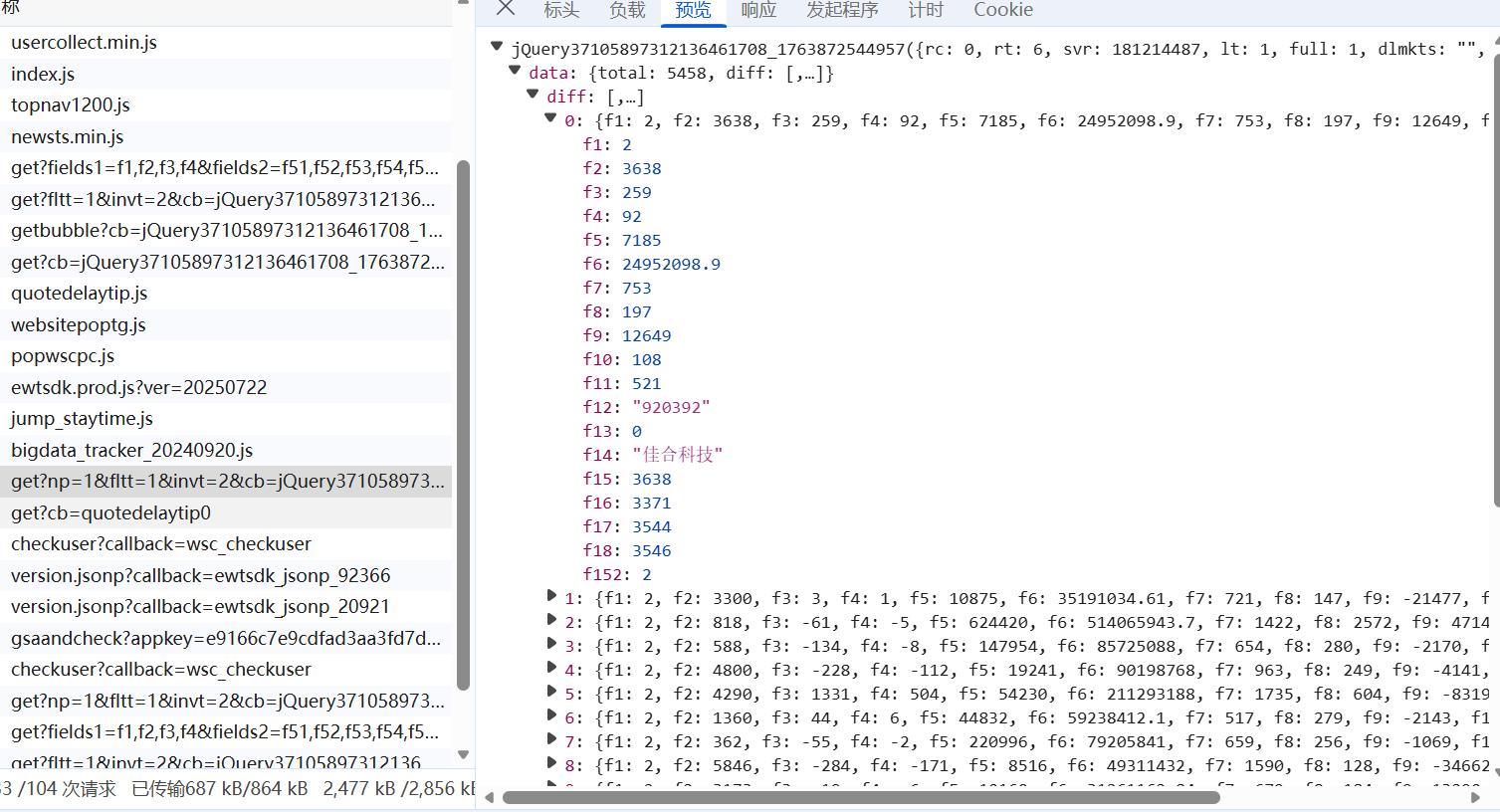
点击查看代码
# stock/spiders/spider.py
import scrapy
from stock.items import StockItem
from scrapy.selector import Selector
import json
from scrapy.exceptions import CloseSpider
class StockSpiderSpider(scrapy.Spider):
name = 'stock_api_xpath'
api_url_template = (
"http://push2.eastmoney.com/api/qt/clist/get?"
"pn={page_num}&pz=50&po=1&np=1&ut=bd1d9ddb040897001ac39a275de594d0&"
"fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23&"
"fields=f12,f14,f2,f3,f4,f5,f6,f7,f15,f16,f17,f18"
)
start_page = 1
CRAWL_LIMIT = 120
crawled_items_count = 0
def start_requests(self):
self.log(f"开始爬取股票数据,上限为 {self.CRAWL_LIMIT} 条。")
url = self.api_url_template.format(page_num=self.start_page)
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response, **kwargs):
try:
data = response.json()
except json.JSONDecodeError:
self.log(f"无法解析JSON响应: {response.text}")
return
if not (data and data.get('data') and data['data'].get('diff')):
self.log("API未返回有效数据,爬取结束。")
return
stock_list = data['data']['diff']
total_stocks = data['data']['total']
html_body = "<tbody>"
for stock in stock_list:
html_body += f"""
<tr>
<code>{stock.get('f12', '')}</code>
<name>{stock.get('f14', '')}</name>
<price>{stock.get('f2', '-')}</price>
<percent>{stock.get('f3', '-')}</percent>
<amount>{stock.get('f4', '-')}</amount>
<volume>{stock.get('f5', '-')}</volume>
<turnover>{stock.get('f6', '-')}</turnover>
<amplitude>{stock.get('f7', '-')}</amplitude>
<high>{stock.get('f15', '-')}</high>
<low>{stock.get('f16', '-')}</low>
<open>{stock.get('f17', '-')}</open>
<prev_close>{stock.get('f18', '-')}</prev_close>
</tr>
"""
html_body += "</tbody>"
selector = Selector(text=html_body)
rows = selector.xpath("//tr")
self.log(f"成功将JSON转换为HTML,并用XPath解析出 {len(rows)} 行数据。")
for row in rows:
if self.crawled_items_count >= self.CRAWL_LIMIT:
self.log(f"已达到爬取上限 {self.CRAWL_LIMIT} 条,正在关闭爬虫...")
raise CloseSpider(f'已达到爬取上限: {self.CRAWL_LIMIT} 条')
item = StockItem()
#将数据赋值给中文命名的item字段
item['股票代码'] = row.xpath('./code/text()').get()
item['股票名称'] = row.xpath('./name/text()').get()
item['最新价'] = row.xpath('./price/text()').get()
item['涨跌幅'] = row.xpath('./percent/text()').get()
item['涨跌额'] = row.xpath('./amount/text()').get()
item['成交量'] = row.xpath('./volume/text()').get()
item['成交额'] = row.xpath('./turnover/text()').get()
item['振幅'] = row.xpath('./amplitude/text()').get()
item['最高'] = row.xpath('./high/text()').get()
item['最低'] = row.xpath('./low/text()').get()
item['今开'] = row.xpath('./open/text()').get()
item['昨收'] = row.xpath('./prev_close/text()').get()
self.crawled_items_count += 1
yield item
current_page = response.meta.get('crawled_page', self.start_page)
crawled_pages_count = current_page * 50
if crawled_pages_count < total_stocks and self.crawled_items_count < self.CRAWL_LIMIT:
next_page = current_page + 1
self.log(f"准备请求第 {next_page} 页...")
next_url = self.api_url_template.format(page_num=next_page)
yield scrapy.Request(
url=next_url,
callback=self.parse,
meta={'crawled_page': next_page}
)
else:
if self.crawled_items_count < self.CRAWL_LIMIT:
self.log("所有数据已爬取完毕!")
pipelines.py(数据处理管道)
点击查看代码
# stock/pipelines.py
from itemadapter import ItemAdapter
import pymysql
class EastmoneyStocksPipeline:
def process_item(self, item, spider):
adapter = ItemAdapter(item)
for field_name in adapter.field_names():
value = adapter.get(field_name)
if value is None or str(value).strip() in ['-', '']:
adapter[field_name] = 0.0 if field_name not in ['股票代码', '股票名称'] else ''
continue
value_str = str(value)
if field_name in ['成交量', '成交额']:
try:
adapter[field_name] = int(float(value_str))
except (ValueError, TypeError):
adapter[field_name] = 0
elif field_name not in ['股票代码', '股票名称']:
try:
cleaned_value = value_str.replace('%', '')
adapter[field_name] = float(cleaned_value)
except (ValueError, TypeError):
adapter[field_name] = 0.0
return item
class MysqlPipeline:
def __init__(self, host, database, user, password, port):
self.host, self.database, self.user, self.password, self.port = host, database, user, password, port
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
database=crawler.settings.get('MYSQL_DATABASE'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
port=crawler.settings.get('MYSQL_PORT'),
)
def open_spider(self, spider):
self.db = pymysql.connect(host=self.host, user=self.user, password=self.password, database=self.database,
port=self.port, charset='utf8mb4')
self.cursor = self.db.cursor()
def close_spider(self, spider):
self.db.close()
def process_item(self, item, spider):
adapter = ItemAdapter(item)
#构建动态的SQL插入语句,以适应中文键
keys = adapter.keys()
# 用反引号包裹每个中文键
wrapped_keys = [f"`{k}`" for k in keys]
# VALUES部分用 %s 占位符
placeholders = ['%s'] * len(keys)
# ON DUPLICATE KEY UPDATE 部分
update_str = ", ".join([f"{k}=VALUES({k})" for k in wrapped_keys])
sql = "INSERT INTO a_share_stocks ({}) VALUES ({}) ON DUPLICATE KEY UPDATE {}".format(
", ".join(wrapped_keys),
", ".join(placeholders),
update_str
)
try:
# 值按顺序传入
self.cursor.execute(sql, tuple(adapter.values()))
self.db.commit()
except Exception as e:
spider.log(f"数据插入失败: {e}\nSQL: {sql}")
self.db.rollback()
return item
main.py(启动 Scrapy 入口)
点击查看代码
# main.py
import pymysql
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from stock.spiders.spider import StockSpiderSpider
# --- 数据库配置 ---
MYSQL_HOST = 'localhost'
MYSQL_PORT = 3306
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123iop12'
MYSQL_DATABASE = 'stock_data'
# --------------------
def init_database():
"""初始化数据库和数据表,使用中文列名。"""
connection = None
try:
connection = pymysql.connect(
host=MYSQL_HOST, user=MYSQL_USER, password=MYSQL_PASSWORD,
port=MYSQL_PORT, charset='utf8mb4'
)
with connection.cursor() as cursor:
cursor.execute(f"CREATE DATABASE IF NOT EXISTS `{MYSQL_DATABASE}` DEFAULT CHARACTER SET utf8mb4;")
connection.select_db(MYSQL_DATABASE)
with connection.cursor() as cursor:
# CREATE TABLE 语句中的列名全部改为中文,并用反引号包裹
create_table_sql = """
CREATE TABLE IF NOT EXISTS a_share_stocks (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '自增序号',
`股票代码` VARCHAR(10) NOT NULL UNIQUE,
`股票名称` VARCHAR(50),
`最新价` DECIMAL(10, 2),
`涨跌幅` DECIMAL(10, 2),
`涨跌额` DECIMAL(10, 2),
`成交量` BIGINT,
`成交额` BIGINT,
`振幅` DECIMAL(10, 2),
`最高` DECIMAL(10, 2),
`最低` DECIMAL(10, 2),
`今开` DECIMAL(10, 2),
`昨收` DECIMAL(10, 2),
`更新时间` TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) COMMENT='A股实时行情表';
"""
cursor.execute(create_table_sql)
print("数据库初始化完成!(使用中文列名)")
return True
except pymysql.MySQLError as e:
print(f"数据库操作失败: {e}")
return False
finally:
if connection:
connection.close()
def run_spider():
"""启动Scrapy爬虫。"""
print("\n--- 准备启动爬虫 (API + XPath 版本) ---")
settings = get_project_settings()
process = CrawlerProcess(settings)
process.crawl(StockSpiderSpider)
print("爬虫开始运行...")
process.start()
print("爬虫运行结束。")
if __name__ == '__main__':
print("--- 股票数据爬取程序开始 ---")
if init_database():
run_spider()
else:
print("\n程序因数据库初始化失败而终止。")
print("\n--- 所有任务已完成 ---")
实验结果:
用navicat查看mysql的数据
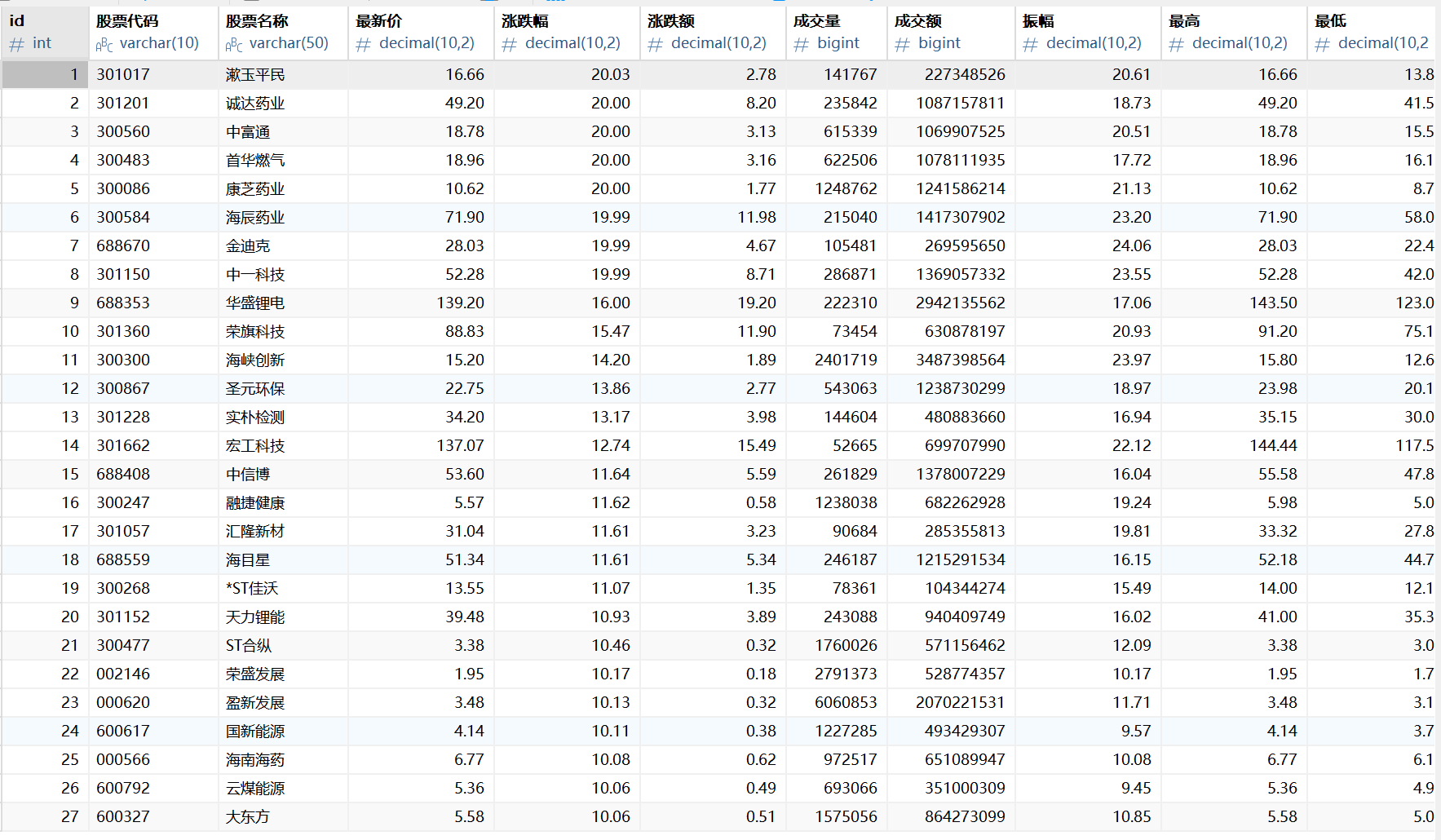
实验心得:
(1)本次实验让我对 Scrapy 项目的结构和运行流程有了更清晰的认识。从爬虫编写、数据解析到 pipeline 的数据处理,每个模块之间的协作更加直观。
作业3
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
导入库:
scrapy:调度、下载网页、解析数据、管理 item 和 pipeline
pymysql:把 Scrapy 生成的数据写入 MySQL 数据库
项目结构:
点击查看代码
boc_scraper/
├── boc_scraper/ # Scrapy 项目主包
│ ├── __init__.py
│ ├── items.py # 定义 Item 数据结构
│ ├── middlewares.py # 爬虫中间件 & 下载中间件
│ ├── pipelines.py # 数据处理管道
│ ├── settings.py # Scrapy 配置文件
│ ├── spiders/ # 爬虫目录
│ │ ├── __init__.py
│ │ ├── boc_spider.py # 主爬虫(Spider)
│ └── __init__.py
│
├── main.py # 自定义启动文件(手动运行 Scrapy)
├── scrapy.cfg # Scrapy 项目配置(入口)
核心代码:
item.py(定义数据结构)
点击查看代码
import scrapy
class ForexScraperItem(scrapy.Item):
# 定义需要抓取的字段,统一使用这个类名
currency_name = scrapy.Field() # 货币名称
tbp = scrapy.Field() # 现汇买入价
cbp = scrapy.Field() # 现钞买入价
tsp = scrapy.Field() # 现汇卖出价
csp = scrapy.Field() # 现钞卖出价
publish_time = scrapy.Field() # 发布时间
boc_spider(实际爬虫的逻辑定义 Spider 类)
用F12查看数据位置,使用xpath匹配

点击查看代码
import scrapy
from boc_scraper.items import ForexScraperItem
class BocSpider(scrapy.Spider):
name = 'boc_forex'
allowed_domains = ['boc.cn']
# 基础URL,用于拼接
base_url = 'https://www.boc.cn/sourcedb/whpj/'
# start_urls只包含第一页
start_urls = [base_url]
# 设置一个上限,避免无限爬取
TOTA_PAGES = 10
def parse(self, response, **kwargs):
"""
解析中国银行外汇牌价静态页面,并使用手动构造URL的方式进行翻页。
"""
# 从meta中获取当前页码,如果没有则默认为1
current_page_num = response.meta.get('page_num', 1)
self.log(f"正在解析第 {current_page_num} 页: {response.url}")
rows = response.xpath('//div[@class="publish"]//table[@align="left"]/tr[position()>1]')
#万一某一页是空的,可以提前终止
if not rows:
self.log(f"在页面 {response.url} 未找到数据行,爬取终止。")
return
self.log(f"在页面 {response.url} 找到 {len(rows)} 行货币数据。")
for row in rows:
item = ForexScraperItem()
item['currency_name'] = row.xpath('./td[1]/text()').get()
item['tbp'] = row.xpath('./td[2]/text()').get()
item['cbp'] = row.xpath('./td[3]/text()').get()
item['tsp'] = row.xpath('./td[4]/text()').get()
item['csp'] = row.xpath('./td[5]/text()').get()
item['publish_time'] = row.xpath('./td[7]/text()').get()
yield item
#手动构造URL进行翻页 ---
# 如果当前页码小于总页数,就构造下一页的请求
if current_page_num < self.TOTAL_PAGES:
next_page_num = current_page_num + 1
# 构造下一页的URL,格式为 index_1.html, index_2.html, ...
next_page_url = f"{self.base_url}index_{next_page_num - 1}.html"
self.log(f"准备请求下一页 (第 {next_page_num} 页): {next_page_url}")
# 发起对下一页的请求,并通过meta传递新的页码
yield scrapy.Request(
url=next_page_url,
callback=self.parse,
meta={'page_num': next_page_num}
)
else:
self.log(f"已达到总页数 {self.TOTAL_PAGES},爬取结束。")
pipelines.py(数据处理管道)
点击查看代码
from itemadapter import ItemAdapter
import pymysql
# 导入与items.py中定义的类名一致的Item
from boc_scraper.items import ForexScraperItem
class DataCleaningPipeline:
"""负责数据清洗和类型转换的管道。"""
def process_item(self, item, spider):
adapter = ItemAdapter(item)
for field_name in adapter.field_names():
value = adapter.get(field_name)
if isinstance(value, str):
cleaned_value = value.strip()
adapter[field_name] = cleaned_value if cleaned_value else None
return item
class MysqlPipeline:
"""负责将数据存入MySQL数据库的管道。"""
def __init__(self, host, database, user, password, port):
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port
self.db = None
self.cursor = None
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
database=crawler.settings.get('MYSQL_DATABASE'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
port=crawler.settings.get('MYSQL_PORT'),
)
def open_spider(self, spider):
self.db = pymysql.connect(
host=self.host, user=self.user, password=self.password,
database=self.database, port=self.port, charset='utf8mb4'
)
self.cursor = self.db.cursor()
spider.log("MySQL数据库连接成功。")
def close_spider(self, spider):
if self.db:
self.db.close()
spider.log("MySQL数据库连接已关闭。")
def process_item(self, item, spider):
# 判断Item类型,确保只处理ForexScraperItem
if isinstance(item, ForexScraperItem):
self.insert_forex(item, spider)
return item
def insert_forex(self, item, spider):
sql = """
INSERT INTO boc_exchange_rates (
currency_name, tbp, cbp, tsp, csp, publish_time
) VALUES (%s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
tbp=VALUES(tbp), cbp=VALUES(cbp), tsp=VALUES(tsp),
csp=VALUES(csp), publish_time=VALUES(publish_time);
"""
try:
self.cursor.execute(sql, (
item.get('currency_name'),
item.get('tbp'),
item.get('cbp'),
item.get('tsp'),
item.get('csp'),
item.get('publish_time'),
))
self.db.commit()
except Exception as e:
spider.log(f"数据插入失败: {e}\nItem: {item}")
self.db.rollback()
main.py(启动 Scrapy 入口)
点击查看代码
import pymysql
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
# 因为main.py和spiders是同级目录,所以使用相对导入
from boc_scraper.spiders.boc_spider import BocSpider
# --- 数据库配置 ---
MYSQL_HOST = 'localhost'
MYSQL_PORT = 3306
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123iop12'
MYSQL_DATABASE = 'box_data'
TABLE_NAME = 'boc_exchange_rates'
# --------------------
def init_database():
connection = None
try:
connection = pymysql.connect(
host=MYSQL_HOST, user=MYSQL_USER, password=MYSQL_PASSWORD,
port=MYSQL_PORT, charset='utf8mb4'
)
print("成功连接到MySQL服务器。")
with connection.cursor() as cursor:
cursor.execute(f"CREATE DATABASE IF NOT EXISTS `{MYSQL_DATABASE}` DEFAULT CHARACTER SET utf8mb4;")
print(f"数据库 '{MYSQL_DATABASE}' 已准备就绪。")
connection.select_db(MYSQL_DATABASE)
with connection.cursor() as cursor:
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS `{TABLE_NAME}` (
id INT AUTO_INCREMENT PRIMARY KEY,
currency_name VARCHAR(50) NOT NULL,
tbp DECIMAL(10, 4),
cbp DECIMAL(10, 4),
tsp DECIMAL(10, 4),
csp DECIMAL(10, 4),
publish_time DATETIME,
UNIQUE KEY `unique_currency_time` (`currency_name`, `publish_time`)
);"""
cursor.execute(create_table_sql)
print(f"数据表 '{TABLE_NAME}' 已准备就绪。")
return True
except pymysql.MySQLError as e:
print(f"数据库操作失败: {e}")
return False
finally:
if connection:
connection.close()
print("数据库连接已关闭。")
def run_spider():
print("\n--- 准备启动爬虫 (boc_forex) ---")
settings = get_project_settings()
process = CrawlerProcess(settings)
process.crawl(BocSpider)
print("爬虫开始运行...")
process.start()
print("爬虫运行结束。")
if __name__ == '__main__':
print("--- 中国银行外汇牌价爬取程序开始 ---")
if init_database():
run_spider()
else:
print("\n程序因数据库初始化失败而终止。")
print("\n--- 所有任务已完成 ---")
setting.py(Scrapy 运行配置)
点击查看代码
# forex_scraper/boc_scraper/settings.py
BOT_NAME = "boc_scraper" # 确认项目名
SPIDER_MODULES = ["boc_scraper.spiders"]
NEWSPIDER_MODULE = "boc_scraper.spiders"
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
}
# 修正 ITEM_PIPELINES 的路径,使用正确的项目名 `boc_scraper`
ITEM_PIPELINES = {
'boc_scraper.pipelines.DataCleaningPipeline': 200,
'boc_scraper.pipelines.MysqlPipeline': 300,
}
# --- 数据库连接配置 ---
MYSQL_HOST = 'localhost'
MYSQL_PORT = 3306
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123iop12'
MYSQL_DATABASE = 'box_data'
import pymysql
pymysql.install_as_MySQLdb()
实验结果:
用navicat查看mysql数据库中数据
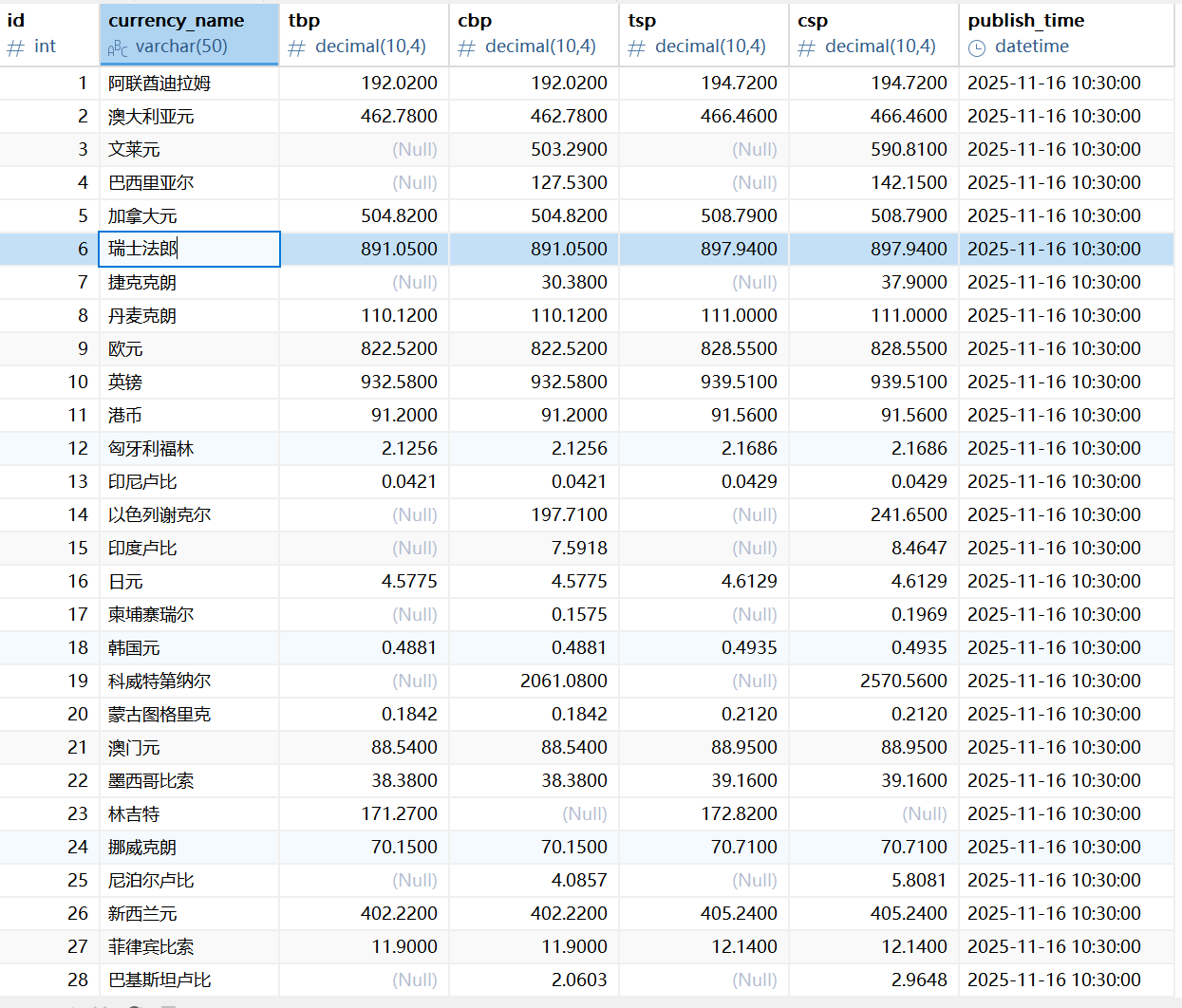
实验心得:
通过本次实验,我更加熟悉了Scrapy 的基本工作流程,包括项目结构、爬虫编写、数据提取和存储等环节。实践中也体会到框架的高效与灵活性,能够快速实现网页数据采集任务。
代码链接:
https://gitee.com/liu-yi-huang/data_project/tree/master/作业3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号