
作业2
作业①
实验要求
在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
思路:爬取数据方面如之前作业,查看网页源代码,发现天气数据在"li class"属性下,采用requesets和bs4进行爬取,之后采用sqlite3将数据存入 SQLite 数据库中
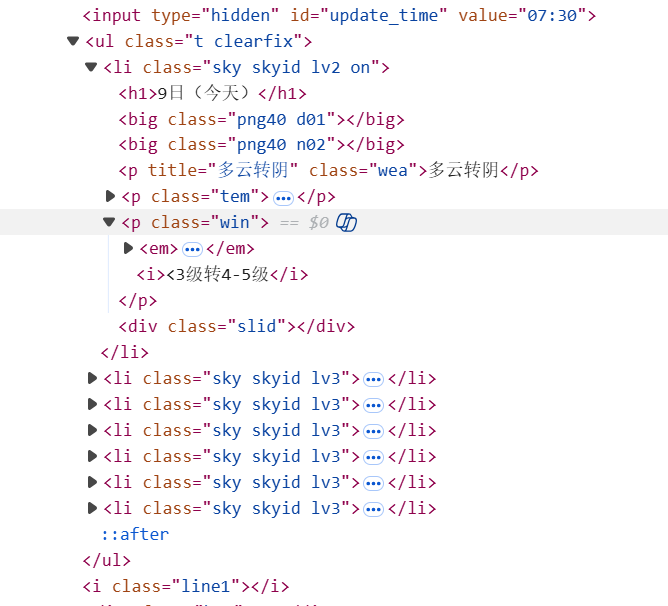
核心代码:
点击查看代码
# ========== 1. 请求网页 ==========
city_name = "福州"
url = "https://www.weather.com.cn/weather/101230101.shtml"
headers = {"User-Agent": "Mozilla/5.0"}
resp = requests.get(url, headers=headers)
resp.encoding = "utf-8"
soup = BeautifulSoup(resp.text, "html.parser")
# ========== 2. 解析天气(取前7天) ==========
ul = soup.find("div", id="7d").find("ul")
data_list = []
for li in ul.find_all("li")[:7]:
date = li.find("h1").text.strip()
wea = li.find("p", class_="wea").text.strip()
temp = li.find("p", class_="tem").text.strip()
data_list.append([city_name, date, wea, temp])
点击查看代码
# ========== 3. 存入 SQLite 数据库 ==========
conn = sqlite3.connect("weather.db")
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS weather (
id INTEGER PRIMARY KEY AUTOINCREMENT,
city TEXT,
date TEXT,
weather TEXT,
temperature TEXT
)
""")
cursor.executemany(
"INSERT INTO weather (city, date, weather, temperature) VALUES (?,?,?,?)",
data_list
)
conn.commit()
结果:
数据文件weather.db:
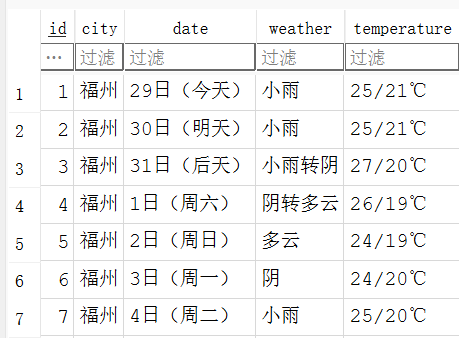
终端打印:
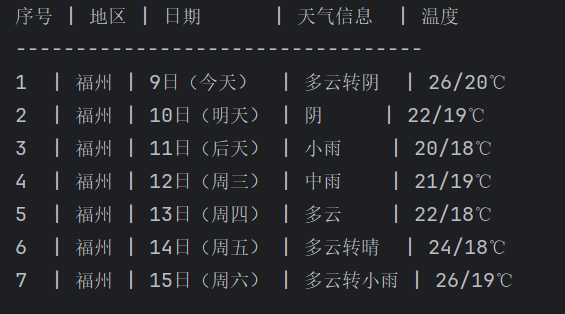
实验心得:
(1)掌握了将数据存为.db文件的操作
(2)要加入headers部分防止反爬
作业②
实验要求
用requests和json解析方法定向爬取股票相关信息,并存储在数据库中
思路:(1)F12查看网页存信息的js文件,查看其请求url及负载
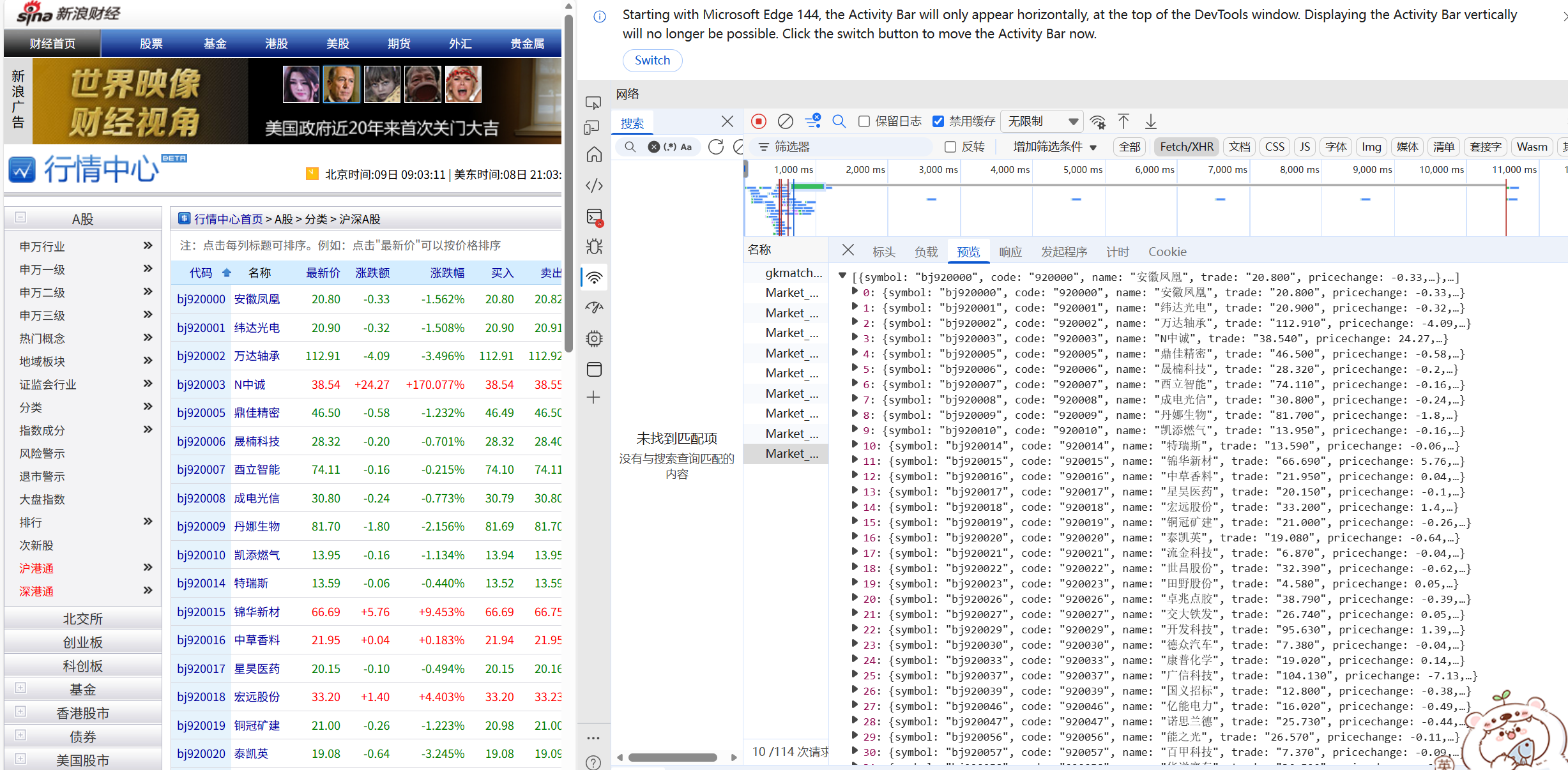

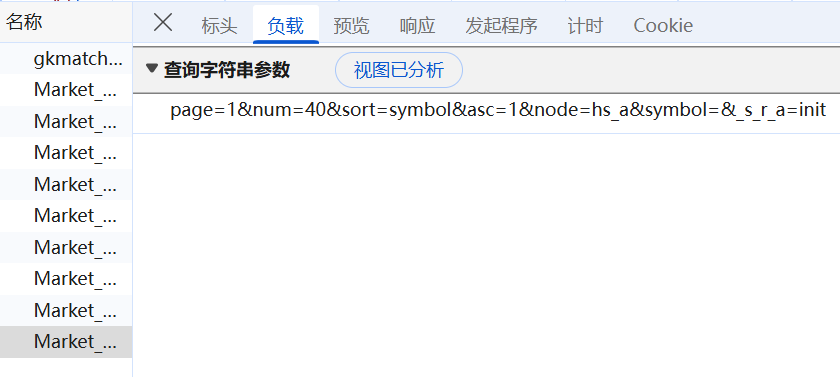
(2)使用requests库请求这个API的URL,用字典的方式从响应该网页字符串参数部分
点击查看代码
# 配置
# =========================================================
url = "https://vip.stock.finance.sina.com.cn/quotes_service/api/json_v2.php/Market_Center.getHQNodeData"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
# 翻页配置
MAX_ITEMS = 60 # 最大读取数目
PAGE_SIZE = 30 # 每页条目数
all_data = []
current_page = 1
print(f"开始爬取数据,目标最大条目数: {MAX_ITEMS}")
# =========================================================
# 翻页读取数据
# =========================================================
while len(all_data) < MAX_ITEMS:
params = {
"page": str(current_page),
"num": str(PAGE_SIZE),
"sort": "changepercent",
"asc": "0",
"node": "hs_a",
"symbol": "",
"_s_r_a": "init"
}
# 1. 发送请求
resp = requests.get(url, params=params, headers=headers, timeout=10)
resp.raise_for_status() # 检查HTTP错误
resp.encoding = "utf-8"
点击查看代码
# 2. 提取纯文本
soup = BeautifulSoup(resp.text, "html.parser")
text_only = soup.text.strip()
# 3. 解析 JSON
data = json.loads(text_only)
if not data:
print(f"第 {current_page} 页未获取到数据或数据为空,停止翻页。")
break
# 4. 限制添加的数据量,确保不超过 MAX_ITEMS
items_needed = MAX_ITEMS - len(all_data)
items_to_add = data[:items_needed]
all_data.extend(items_to_add)
print(f"成功获取第 {current_page} 页 ({len(items_to_add)} 条),当前总数: {len(all_data)} / {MAX_ITEMS}")
if len(all_data) >= MAX_ITEMS:
break
current_page += 1
点击查看代码
# =========================================================
# 将数据写入 SQLite 数据库
# =========================================================
DB_NAME = "stock_data.db"
conn = None
try:
# 连接数据库(自动创建)
conn = sqlite3.connect(DB_NAME)
cursor = conn.cursor()
# 建表(不存在则创建)
cursor.execute("""
CREATE TABLE IF NOT EXISTS stock_info (
id INTEGER PRIMARY KEY AUTOINCREMENT,
symbol TEXT,
name TEXT,
trade REAL,
changepercent REAL,
pricechange REAL,
volume INTEGER,
amount REAL,
high REAL,
low REAL,
open REAL,
settlement REAL
)
""")
# 准备插入数据
data_to_insert = []
for item in all_data:
data_to_insert.append((
item.get("symbol", ""),
item.get("name", ""),
item.get("trade", ""),
item.get("changepercent", ""),
item.get("pricechange", ""),
item.get("volume", ""),
item.get("amount", ""),
item.get("high", ""),
item.get("low", ""),
item.get("open", ""),
item.get("settlement", ""),
))
# 批量插入数据
cursor.executemany("""
INSERT INTO stock_info (symbol, name, trade, changepercent, pricechange,
volume, amount, high, low, open, settlement)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
""", data_to_insert)
conn.commit()
print(f"\n数据已成功写入 SQLite 数据库:{DB_NAME}")
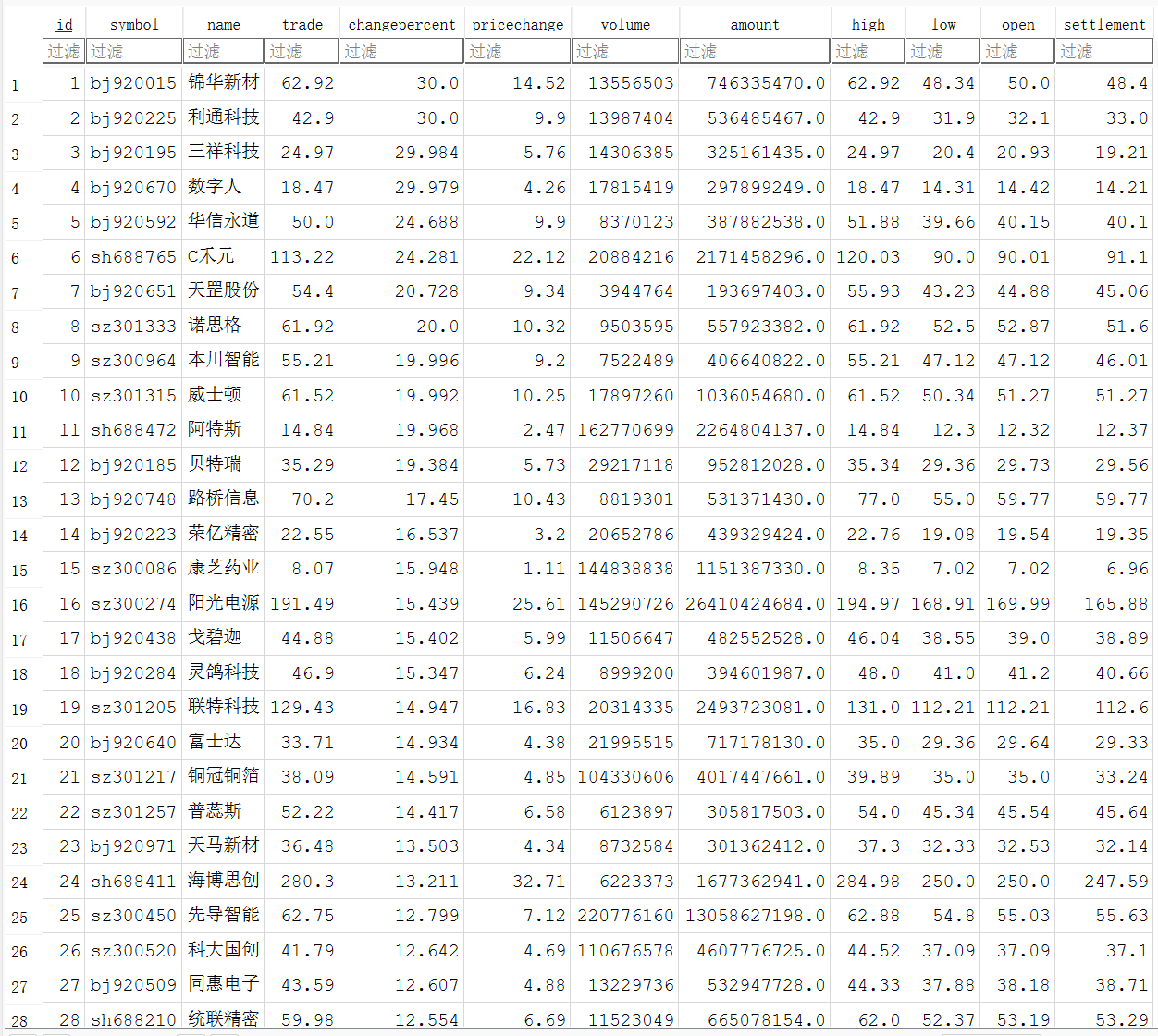
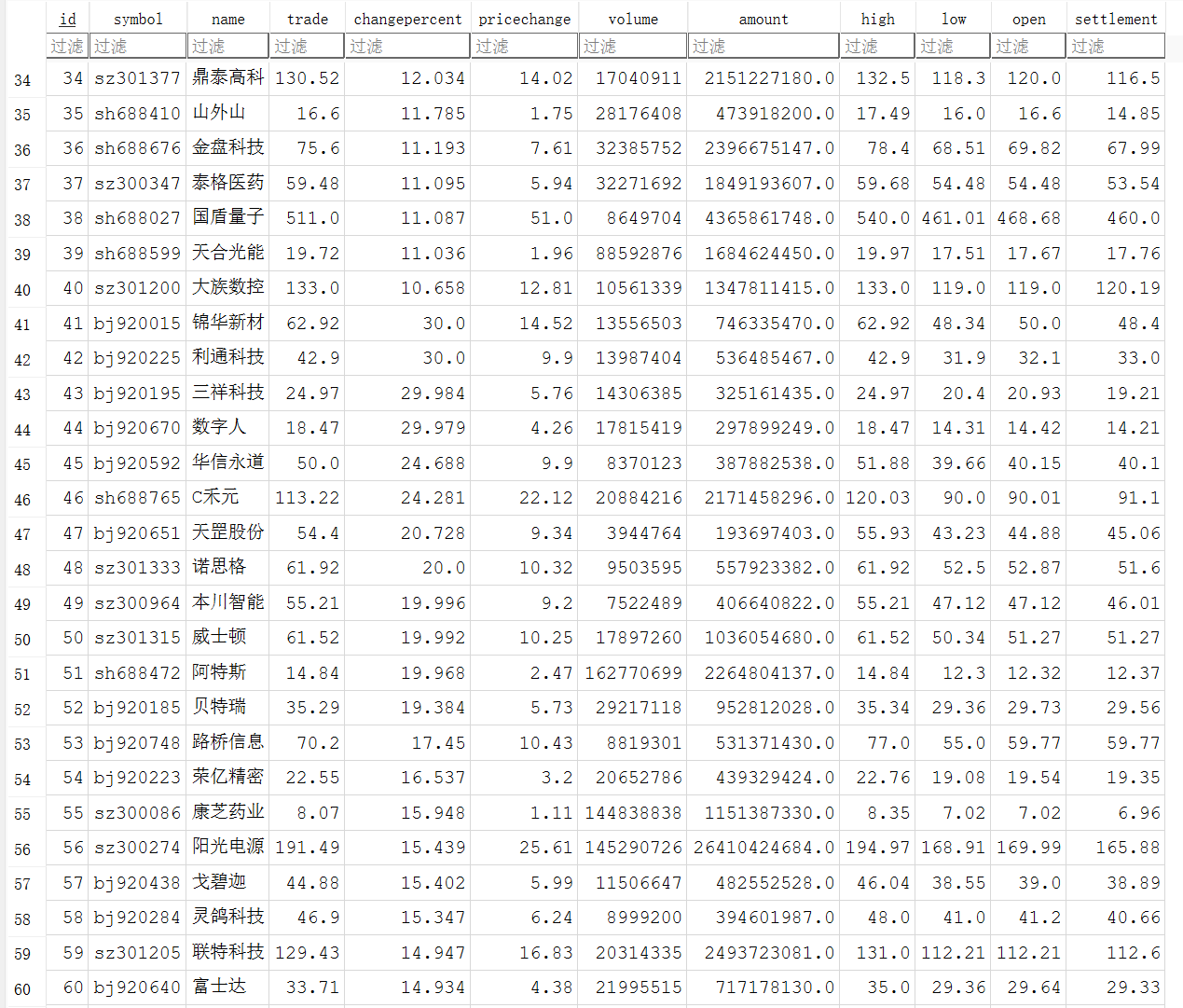
实验心得:
(1)爬取网页中js文件数据比爬取html文件要高效得多(没有正则表达式太快了),其最重要的是找到API和其js数据文件,然后对其相应参数进行更换。
作业③
实验要求
爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中
思路:(1)找到相应api对应的js数据接口https://www.shanghairanking.cn/_nuxt/static/1762223212/rankings/bcur/202111/payload.js
(2)爬取后发现该数据下有许多是变量代号(eq、dj等)的字段(因为有__NUXT_JSONP__参数调用),对此采用字典的形式将每个参数名的值进行一一对应(该部分为形参,需要先对齐),(如i:双一流,j:211),生成mapping.csv,相应数据如下:
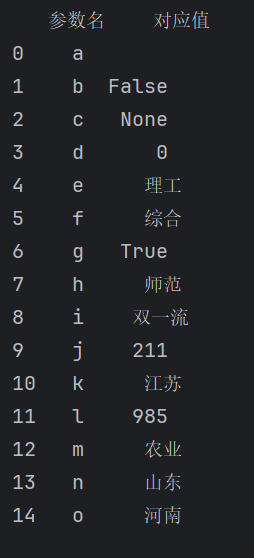
(3)查找univData数组(发现该数组下有大学相应的排名,得分等信息),使用正则表达式找到univNameCn,province,univCategory,score四个键,将其放进表当中。同时将部分大学的score通过mapping.csv进行转换(因为该部分为形参,要把对象里这些代号替换回真实值)
核心代码:
点击查看代码
# ===================== 主程序 =====================
def run_ranking_process():
source_js_url = "https://www.shanghairanking.cn/_nuxt/static/1762223212/rankings/bcur/202111/payload.js"
local_js_file = "payload.js"
main_db_file = "university_paiming.db"
# 原代码中main函数没有调用 download_payload_js,此处保持一致。
# fetch_js_file(source_js_url, local_js_file)
# 加载得分映射表
score_lookup_map = load_score_config("mapping.csv")
# 解析数据
final_rankings_data = process_university_data(local_js_file, score_lookup_map)
# 写入数据库
main_db_conn = establish_database_connection(main_db_file)
if main_db_conn:
create_university_table(main_db_conn)
populate_university_data(main_db_conn, final_rankings_data)
# ------- 打印前20条结果 -------
print("\n数据预览(前20条):")
display_headers = ["排名", "学校", "省份", "类型", "总分"]
column_widths = [6, 20, 10, 10, 8]
# 打印表头
for header_text, width_val in zip(display_headers, column_widths):
print(format_padded_string(header_text, width_val), end="")
print()
print("-" * sum(column_widths))
# 打印数据
for rank_entry in final_rankings_data[:20]:
formatted_row = [
format_padded_string(rank_entry["rank"], column_widths[0]),
format_padded_string(rank_entry["name_cn"], column_widths[1]),
format_padded_string(rank_entry["province"], column_widths[2]),
format_padded_string(rank_entry["category"], column_widths[3]),
format_padded_string(rank_entry["score"], column_widths[4])
]
print("".join(formatted_row))
print(f"\n共解析 {len(final_rankings_data)} 所大学数据,已保存至数据库。")
main_db_conn.close()
点击查看代码
# ===================== 映射文件加载 =====================
def load_score_config(config_filepath="mapping.csv"):
score_mappings = {}
if not os.path.exists(config_filepath):
print(f"未找到映射文件,将跳过映射替换。")
return score_mappings
with open(config_filepath, "r", encoding="utf-8") as f:
for line_content in f:
line_content = line_content.strip()
if not line_content or line_content.startswith("#"):
continue
# 自动识别分隔符(制表符、空格、逗号)
parts = re.split(r'[\t, ]+', line_content)
if len(parts) >= 2:
key, val = parts[0], parts[1]
score_mappings[key.strip()] = val.strip()
print(f"成功加载 {len(score_mappings)} 条得分映射。")
return score_mappings
# ===================== 辅助解析函数 =====================
def _extract_item_field(university_item_str, field_regex, fallback_value=""):
"""
从单个大学的字符串数据中提取字段的原始值。
:param university_item_str: 单个大学的字符串数据。
:param field_regex: 用于匹配字段值的正则表达式。
:param fallback_value: 提取失败时的默认值。
:return: 提取到的原始字符串值,或默认值。
"""
match_result = re.search(field_regex, university_item_str)
if match_result:
# Group 1 is usually the captured value, strip quotes and whitespace.
return match_result.group(1).strip('"').strip()
return fallback_value
# ===================== 数据解析 =====================
def process_university_data(js_data_filepath="payload.js", score_conversion_map=None):
"""解析本地文件,只提取:学校、省份、类型、总分(支持映射替换)"""
with open(js_data_filepath, "r", encoding="utf-8") as f:
js_content = f.read()
data_block_match = re.search(r'univData:\s*\[(.*?)\],\s*indList:', js_content, re.S)
if not data_block_match:
print("未找到大学数据块。")
return []
university_records = re.findall(r'\{[^}]*univNameCn:"[^"]+"[^}]*\}', data_block_match.group(1), re.S)
parsed_university_rankings = []
for record_index, record_string in enumerate(university_records, 1):
chinese_name = _extract_item_field(record_string, r'univNameCn:"(.*?)"', f"未知大学_{record_index}")
# 排名处理
raw_rank_value = _extract_item_field(record_string, r'ranking:([^,]+)', str(record_index))
ranking_position = int(raw_rank_value) if raw_rank_value.isdigit() else record_index
# 省份处理
prov_code = _extract_item_field(record_string, r'province:([^,]+)', "")
province_name = PROVINCE_CODE_TO_NAME.get(prov_code, "未知省份")
# 类型处理
cat_code = _extract_item_field(record_string, r'univCategory:([^,]+)', "")
category_type = CATEGORY_CODE_TO_TYPE.get(cat_code, "未知类型")
# 总分处理
raw_score_value = _extract_item_field(record_string, r'score:([^,}]+)', None) # 使用 None 作为默认值,以区分未找到和空字符串
final_score = None
if raw_score_value is not None:
# 映射替换
if score_conversion_map and raw_score_value in score_conversion_map:
raw_score_value = score_conversion_map[raw_score_value]
# 尝试转浮点
try:
final_score = float(raw_score_value)
except (ValueError, TypeError): # 增加对 TypeError 的捕获,更健壮
final_score = None
parsed_university_rankings.append({
"rank": ranking_position,
"name_cn": chinese_name,
"province": province_name,
"category": category_type,
"score": final_score
})
print(f"成功解析 {len(parsed_university_rankings)} 条排名数据")
return parsed_university_rankings
# ===================== 用sqlite进行数据库操作 =====================
def establish_database_connection(database_filepath):
"""创建数据库连接"""
try:
db_connection = sqlite3.connect(database_filepath)
return db_connection
except Error as e:
print(f"数据库连接失败: {e}")
return None
def create_university_table(db_connection):
"""创建仅包含4字段的表"""
try:
db_cursor = db_connection.cursor()
db_cursor.execute("""
CREATE TABLE IF NOT EXISTS university_rankings (
id INTEGER PRIMARY KEY AUTOINCREMENT,
rank INTEGER,
name_cn TEXT,
province TEXT,
category TEXT,
score REAL
)
""")
db_connection.commit()
print("大学排名表创建成功")
except Error as e:
print(f"创建表失败: {e}")
def populate_university_data(db_connection, university_rank_list):
"""插入排名数据"""
if not university_rank_list:
print("没有数据可插入")
return
try:
db_cursor = db_connection.cursor()
db_cursor.execute("DELETE FROM university_rankings") # 清空旧数据
insert_sql_query = "INSERT INTO university_rankings (rank, name_cn, province, category, score) VALUES (?, ?, ?, ?, ?)"
data_to_insert = [(r["rank"], r["name_cn"], r["province"], r["category"], r["score"]) for r in university_rank_list]
db_cursor.executemany(insert_sql_query, data_to_insert)
db_connection.commit()
print(f"成功插入 {db_cursor.rowcount} 条数据")
except Error as e:
print(f"插入数据失败: {e}")
db_connection.rollback()
def calculate_char_display_width(input_string):
display_width = 0
for char_unit in str(input_string):
if unicodedata.east_asian_width(char_unit) in ('F', 'W'):
display_width += 2
else:
display_width += 1
return display_width
def format_padded_string(input_string, desired_width):
input_string = str(input_string)
padding_spaces = desired_width - calculate_char_display_width(input_string)
return input_string + " " * max(padding_spaces, 0)
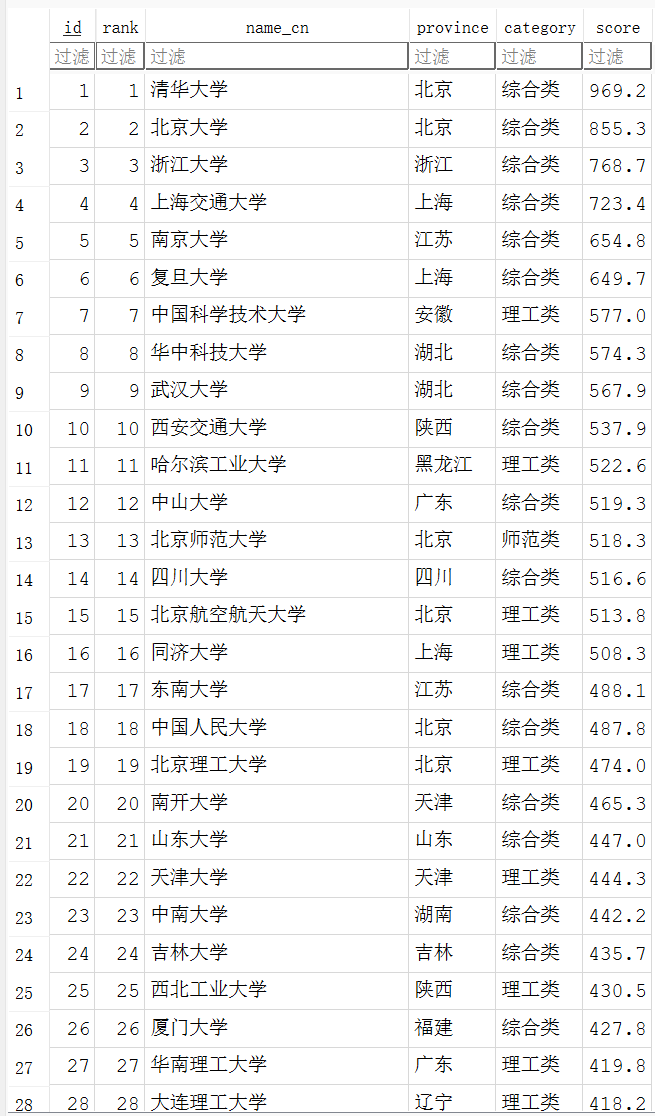
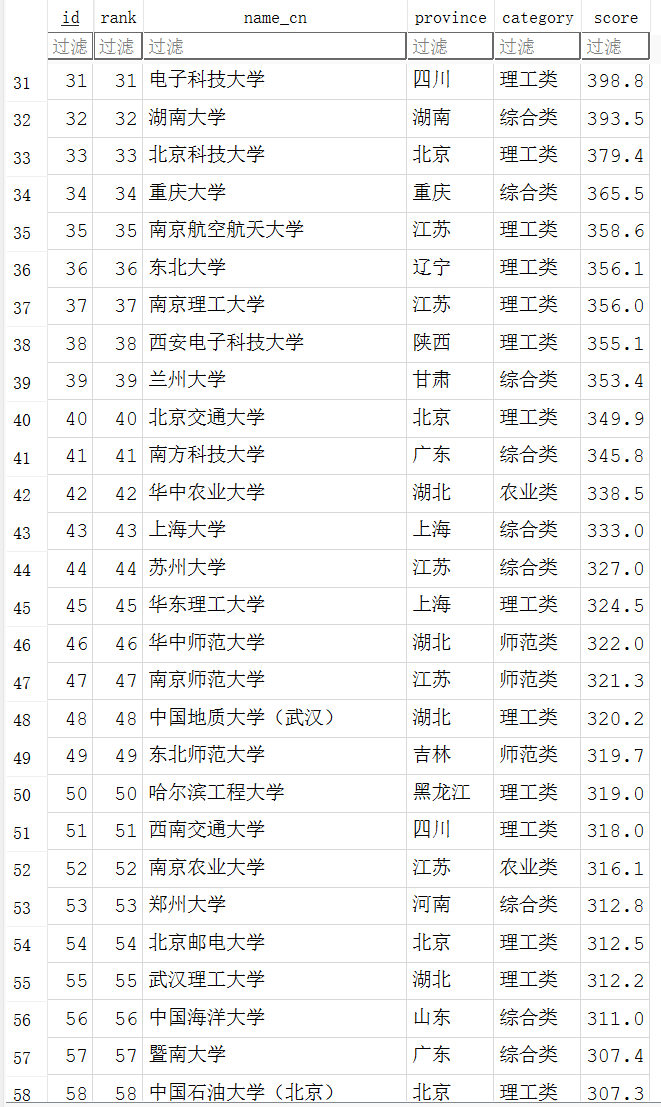
实验心得:
(1)该页面json数据解析十分复杂,部分形参数据信息无法用肉眼识别(很多乱码),最后选择性调用需要的数据(形参,data列表中的univ等)。
(2)该网页js数据的url似乎还是在变换的,与同学对照后发现自己的url和他们不同,这方面也是花了不少时间
gitee链接:https://gitee.com/liu-yi-huang/data_project/tree/master/作业2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号