
作业1
作业①
1.大学排名动态网页爬取实验
实验要求
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
(1)查看网页,发现为静态网页,且没有其他反爬机制,可直接采用requests和soup。
(2)用F12查看网页,发现表内行标签为'tr',行内对应块均在'td'内,同时学校名称内有不必要的其他信息(英文名称等),中文名称在class='tooltip'属性内。依此编写正则表达式,最终得到清晰的排名信息。
核心代码:
点击查看代码
# 查找表格中的每一行(每行信息都在<tr>内)
rows = soup.find_all('tr')
for row in rows[1:]: # 跳过表头
#行内信息都在节点<td>内
cols = row.find_all('td')
if len(cols) >= 5:
rank = cols[0].get_text(strip=True)
# 获取学校名称
name_tag =cols[1].find('div', class_='tooltip')
name = name_tag.get_text(strip=True) if name_tag else cols[1].get_text(strip=True)
province = cols[2].get_text(strip=True)
category = cols[3].get_text(strip=True)
score = cols[4].get_text(strip=True)
print(f"{rank}\t{name}\t{province}\t{category}\t{score}")
实验结果:
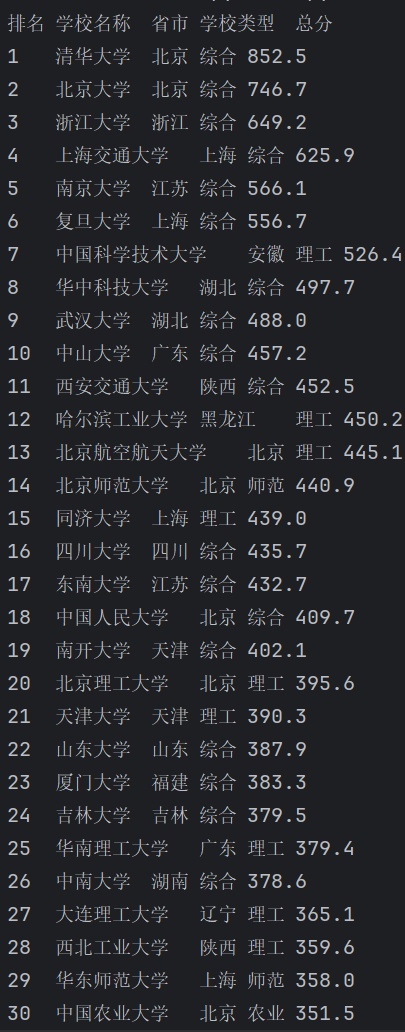
实验心得:
1.初次爬取学校名称时还有大量头衔(985,211)不够简洁,最后也是对正则表达式进行两层优化,在含学校名称的节点内在筛选出有tooltip的节点,也说明了正则表达式的重要性,写不好会匹配太多无关内容。
作业②
1.商城商品比价定向爬虫实验
实验要求
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
思路:
1.由于淘宝等大平台反爬做的太好了,这里选取百联网(https://search.bl.com)进行爬取
2.该网站内容是通过 JavaScript 动态加载的,如果只用requests,要找到其数据接口(JSON地址),然后用正则在接口返回的数据里提取想要的内容。用F12查看该网页真实的数据接口(https://search.bl.com/js/mainGoodList.html),查看商品名称和价格所属节点以编写正则表达式,最后用requests库模拟 POST 请求进行爬取。商品名称和价格节点如下图:

3.由于该网站翻页url时改变,可以通过改变url的方法对多页数据进行采集。通过查看负载得到表单数据如下:
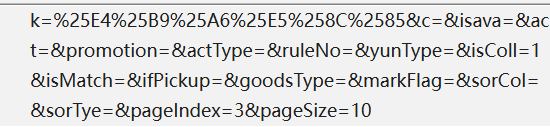
后续代码可通过改变POST请求参数来改变爬取的页面(pageindex)和每页爬取数量(pagesize)
核心代码:
点击查看代码
def parse_html_content(raw_content):
html = raw_content
names = re.findall(r'class="pro-name[^"]*".*?title="([^"]+)"', html, re.DOTALL)
prices = re.findall(r'class="money-fl">\s*¥\s*([\d.]+)', html)
return names, prices
点击查看代码
# --- 配置参数 ---
BASE_URL = "https://search.bl.com/js/mainGoodList.html"
SEARCH_KEYWORD = "书包"
PAGE_SIZE = 10 # 每次请求抓取的商品数量
MAX_ITEMS = 60 # 限定抓取的最大商品数量
# 存储所有抓取到的数据
all_products = []
current_page = 1 # 从第 1 页开始抓取
# --- 配置参数---
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/121.0.0.0 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Origin": "https://search.bl.com",
"Referer": "https://search.bl.com/k-%E4%B9%A6%E5%8C%85.html",
"X-Requested-With": "XMLHttpRequest",
"Cookie": "HWWAFSESID=a4491760474a07c89b; HWWAFSESTIME=1761122765955; __bl_test_id_=AECC49679A349A36126E89157AC51247; sensorsdata_is_new_user=true; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2219a0b18d44bd7d-063fd18953fc8a-4c657b58-1638720-19a0b18d44ce35%22%2C%22props%22%3A%7B%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22platform%22%3A%22PC%22%7D%7D; Qs_lvt_73105=1761122768; _jzqckmp_v2=1/; smidV2=20251022164608e186645d8628bee486a4d95039662d74007e71e5e6bf82200; i_h_s=%25E4%25B9%25A6%25E5%258C%2585; Hm_lvt_d4bb30b3ba58b04cd3d04be8ebb57263=1761122769; HMACCOUNT=6ADDF01C2801D70F; _qzja=1.1160944136.1761122768543.1761122768543.1761122768543.1761123550005.1761123894891.0.0.0.4.1; _qzjb=1.1761122768543.4.0.0.0; _qzjc=1; _qzjto=4.1.0; Qs_pv_73105=9999446217126684%2C398392608469106700%2C3751520961269061600%2C148286681435495460; Hm_lpvt_d4bb30b3ba58b04cd3d04be8ebb57263=1761123896; .thumbcache_c6ed5383e076d23f8144e9f7663f043c=kETL0l65GWpzqphaO01IIUphFz5OxXqTyQNI0bVi86ODUWiW/e90BbaUaYBkmw3OXe1dpv/Fw1OaMxd+ycd1Lg%3D%3D"
}
点击查看代码
def get_page_data(page_index):
"""根据页码发起请求,并返回原始响应字符串"""
data = {
"k": SEARCH_KEYWORD,
"c": "",
"isava": "",
"act": "",
"promotion": "",
"actType": "",
"ruleNo": "",
"yunType": "",
"isColl": "1",
"isMatch": "",
"ifPickup": "",
"goodsType": "",
"markFlag": "",
"sorCol": "",
"sorTye": "",
"pageIndex": str(page_index), # 动态页码
"pageSize": str(PAGE_SIZE)
}
try:
resp = requests.post(BASE_URL, headers=headers, data=data, timeout=10)
resp.raise_for_status() # 检查状态码是否 200
return resp.text
except requests.exceptions.RequestException as e:
print(f"请求第 {page_index} 页失败: {e}")
return None
点击查看代码
while len(all_products) < MAX_ITEMS:
# 1. 发起请求
raw_response = get_page_data(current_page)
if raw_response is None:
print("请求失败或超时,停止爬取。")
break
# 2. 解析数据
names, prices = parse_html_content(raw_response)
# 检查是否还有商品
if not names:
print("未检测到更多商品,提前结束。")
break
# 3. 存储数据
new_products = []
for name, price in zip(names, prices):
if len(all_products) < MAX_ITEMS:
all_products.append({
"name": name.strip(),
"price": price.strip()
})
new_products.append(name.strip())
else:
break
print(f"抓取到 {len(new_products)} 项商品。")
print(f"当前累计商品数量: {len(all_products)} / {MAX_ITEMS}")
# 4. 准备下一页
current_page += 1
运行结果:
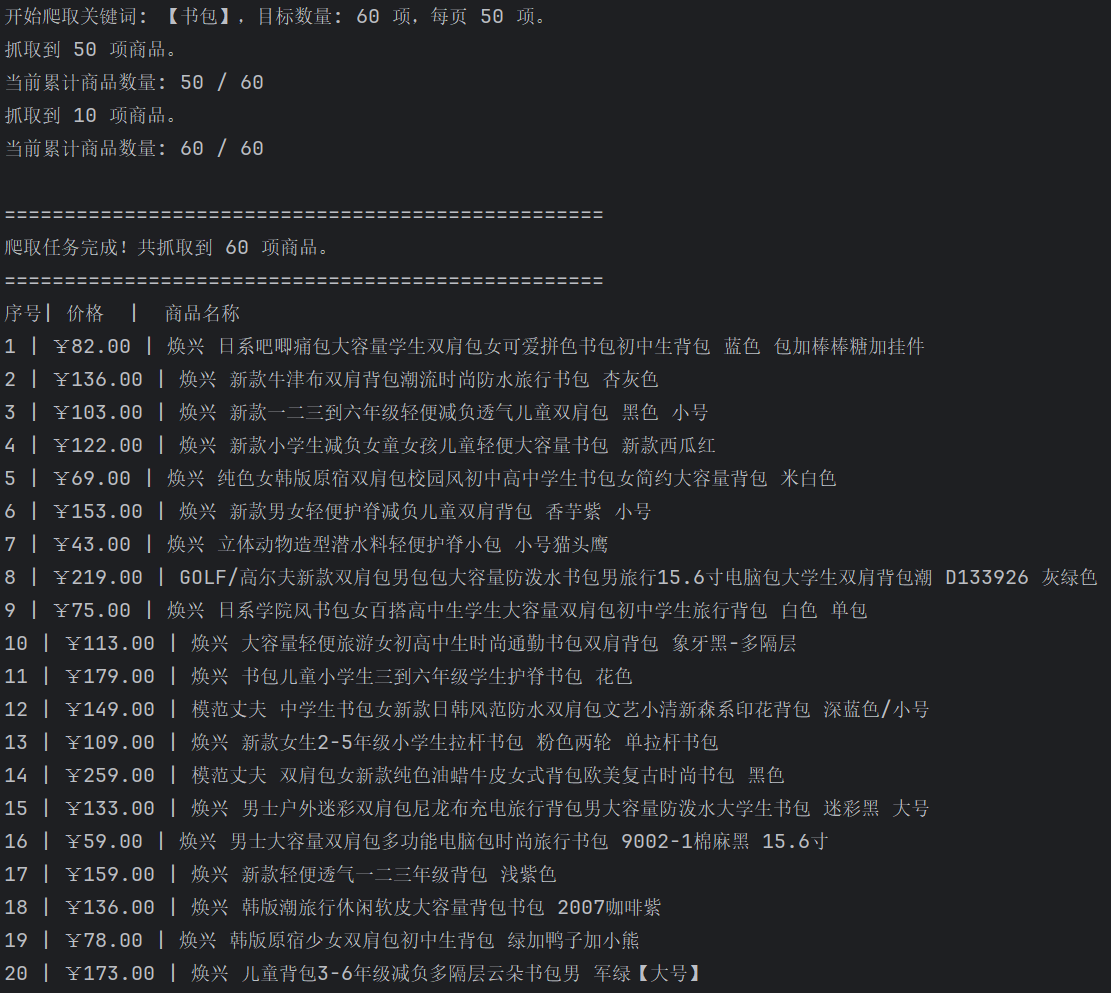
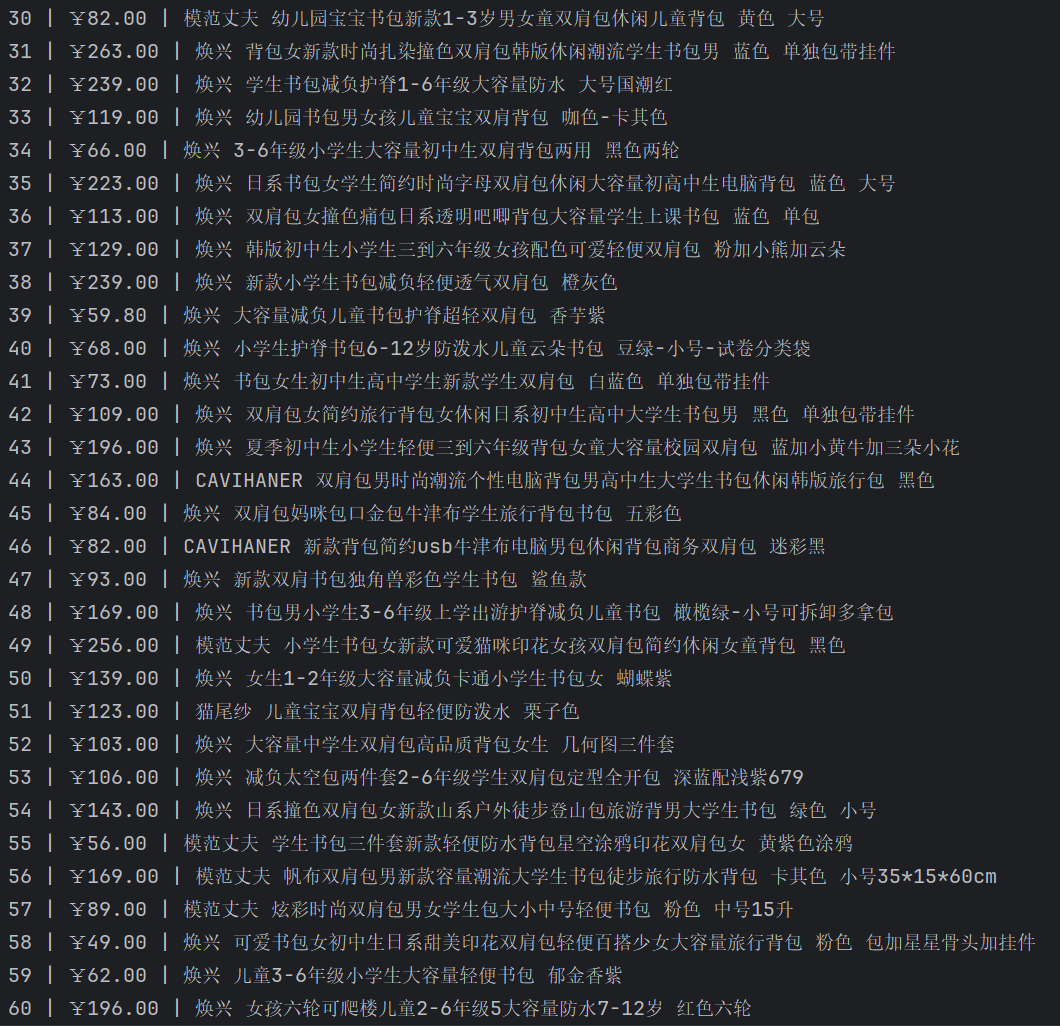
实验心得:
(1)找商品数据接口找了很久(网页内容是通过 JavaScript 动态加载的,真实的商品信息是浏览器加载后由 JS 异步请求接口(API) 获取的,若要静态获取数据要找真实的数据请求接口),然后还要配自己的cookie(小网站还是做了点反爬的,令人感慨)。
(2)初次爬取时发现有漏爬内容,后续发现商品名称可能有两行,于是修改正则表达式加入[^"]*,表示匹配任意数量(包括零个)的非双引号字符。
作业③
网页图片批量下载实验
实验要求
爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)的所有JPEG、JPG或PNG格式图片文件
输出信息:将自选网页内的所有JPEG、JPG或PNG格式文件保存在一个文件夹中
思路:
1.查看网页中图片位置,发现它们都在"div class=img slow"中,可以用re库的find_all来匹配它们
2.注意到每张图的后缀可能不同,写正则化表达式时要添加.(?:jpg|jpeg|png)。
以下为网页的内容:

核心代码:
点击查看代码
# 3. 从 <div class="img slow"> 中提取所有 <img src="...">
# 支持 jpg/jpeg/png 格式
pattern_img = r'<div[^>]*class="img\s+slow"[^>]*>.*?<img[^>]+src="([^"]+\.(?:jpg|jpeg|png))"'
img_urls = re.findall(pattern_img, html, re.IGNORECASE | re.S)
if not img_urls:
print("未找到任何图片")
exit()
结果:
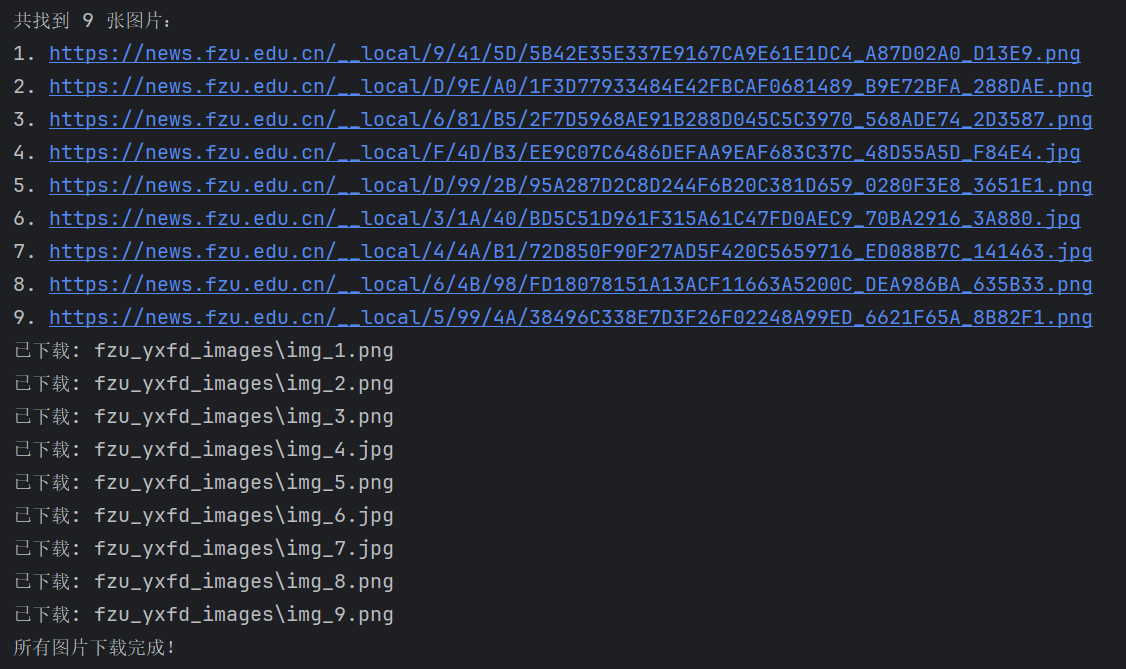
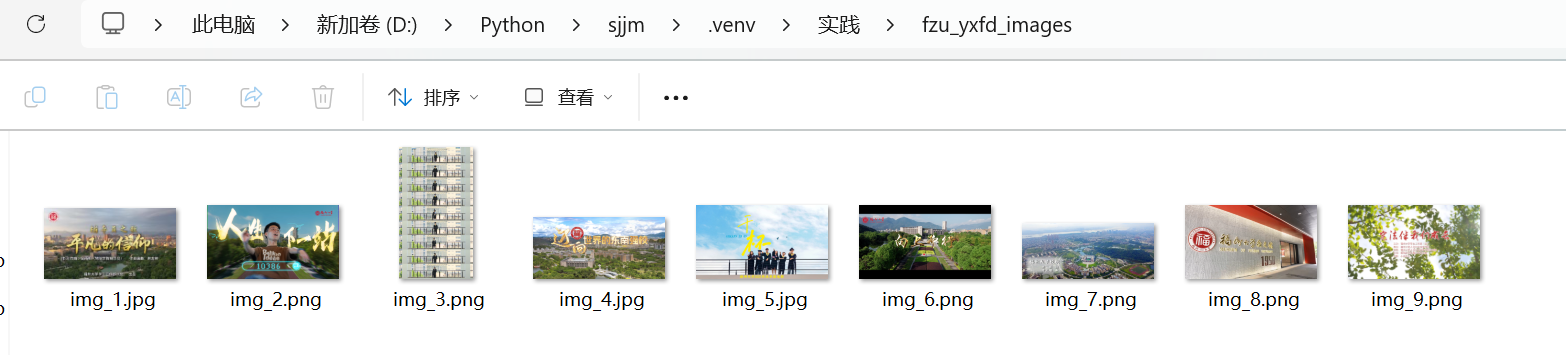
与网页中出现的图片数量及画面一致。
实验心得:
(1)没有反爬机制,泥福还是太善良了
(2)正则表达式的读写有时十分复杂,需要大量实践
代码保存:
https://gitee.com/liu-yi-huang/data_project/tree/master/作业1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号