
第一次个人编程作业
软件工程第二次作业
仓库
gitcode仓库:https://gitcode.net/qq_41695394/test.git
PSP表格
| PSP2.1 | Personal Software Process Stages | 预计耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 45 |
| · Estimate | 估计这个任务需要多少时间 | 10 | 15 |
| Development | 开发 | 240 | 300 |
| · Analysis | 需求分析 (包括学习新技术) | 60 | 75 |
| · Design Spec | 生成设计规格 | 30 | 45 |
| · Design Review | 设计复审 | 20 | 30 |
| · Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 15 |
| · Design | 具体设计 | 40 | 50 |
| · Coding | 具体编码 | 80 | 100 |
| · Code Review | 代码复审 | 20 | 30 |
| · Test | 测试(自我测试,修改代码,提交修改) | 20 | 25 |
| Reporting | 报告 | 60 | 75 |
| · Test Report | 测试报告 | 30 | 40 |
| · Size Measurement | 计算工作量 | 10 | 15 |
| · Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 340 | 420 |
计算模块接口的设计与实现过程
这是一个简单的文本相似度检测工具,它主要用于比较两个文本文件(例如学术论文或代码)之间的相似度,以检查可能的抄袭情况。代码是用Python编写的,并且不包含任何类定义,只有函数。
组织结构
代码包含了四个主要函数和一个主程序入口:
read_file(file_path): 读取指定路径的文件内容。calculate_similarity(file1_content, file2_content): 计算两个文件内容的相似度比例。write_result(result, output_file_path): 将相似度比例写入到指定的输出文件中。main(): 程序的主入口,负责处理命令行参数并调用上述函数。
函数关系
main()函数是程序的起点,它首先检查命令行参数的数量是否正确,然后依次调用read_file来读取两个文件的内容,接着使用calculate_similarity来计算相似度,最后调用write_result将结果写入文件。read_file、calculate_similarity和write_result是辅助函数,它们被main()调用,执行具体的读写和计算任务。
算法关键
- 文件读取:使用
with open语句确保文件被正确读取和关闭。 - 相似度计算:利用Python标准库中的
difflib.SequenceMatcher类来计算两个字符串序列的相似度比例。这个类提供了一个快速而简单的方法来比较字符串,并返回一个0到1之间的比例值,其中1表示完全相同。 - 结果输出:将计算出的相似度比例格式化为两位小数,并写入到指定的输出文件中。
独到之处
- 命令行工具:此脚本设计为命令行工具,方便用户直接从命令行传入文件路径和获取输出结果。
- 简单易用:不需要复杂的安装或配置,用户只需安装Python并拥有正确的文件路径即可运行。
- 清晰的代码结构:每个函数执行单一任务,使得代码易于理解和维护。
流程图
由于代码结构简单,流程图可能不是必需的,但如果需要,流程图将展示以下步骤:
- 用户通过命令行提供两个文件路径和一个输出文件路径。
main()函数检查命令行参数的有效性。read_file函数分别读取两个文件的内容。calculate_similarity函数计算两个文本内容的相似度。write_result函数将相似度结果写入到输出文件中。
这个工具的目的是提供一个基础的方法来比较两个文本文件,但它可能无法检测到复杂的抄袭情况,例如改写或语义上的相似。更高级的抄袭检测工具可能会使用更复杂的算法,比如自然语言处理(NLP)技术,来更准确地评估内容相似度。
计算模块部分单元测试展示
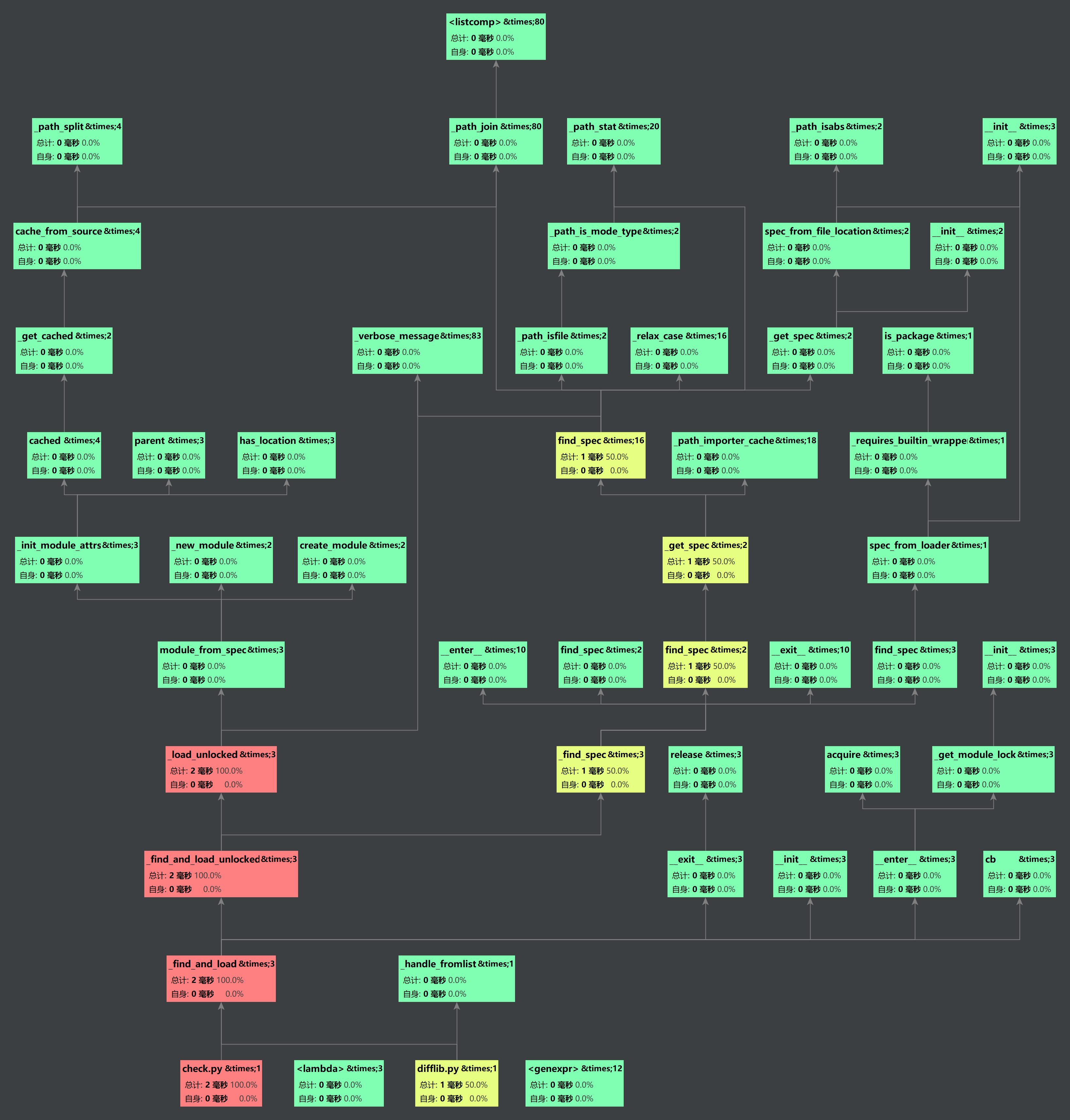
计算模块部分异常处理说明
在此没有使用具体的文本(.txt)将程序实例化,所有测试都是0毫秒

