运维监控笔记分享:提高系统稳定性的关键!
-
运维监控笔记分享:提高系统稳定性的关键!
大家好,我是小斐呀。
准备把自己的运维监控笔记分享出来,希望能帮助到需要的朋友们,今天就来个全局概览。
为什么要监控?
最初始的需求,其实就是一句话:系统出问题了我们能及时感知到 。当然,随着时代的发展,我们对监控系统提出了更多的诉求,比如:
- 通过监控了解数据趋势,知道系统在未来的某个时刻可能出问题,预知问题。
- 通过监控了解系统的水位情况,为服务扩缩容提供数据支撑。
- 通过监控来给系统把脉,感知到哪里需要优化,比如一些中间件参数的调优。
- 通过监控来洞察业务,提供业务决策的数据依据,及时感知业务异常。
可观测性三大支柱
我们经常说的 监控系统 ,其实只是 指标监控 ,通常使用折线图形态呈现在图表上,比如某个机器的CPU利用率、某个数据库实例的流量或者网站的在线人数,都可以体现为随着时间而变化的趋势图。
可观测性其他二大支柱分别是日志和链路,业界相关的产品如下图所示:
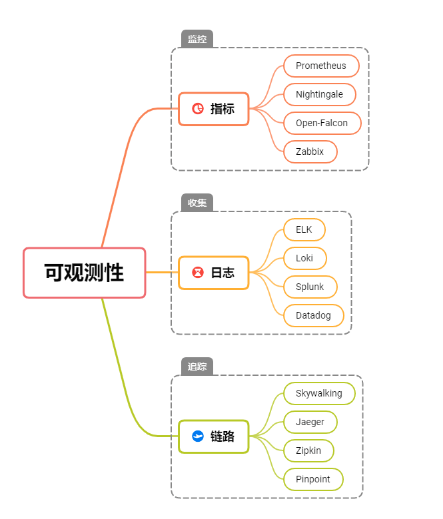
后续 《运维监控全套笔记》 体系文章中所说的监控都是指 指标监控 ,下面主要针对可观测性中的指标监控展开说明:
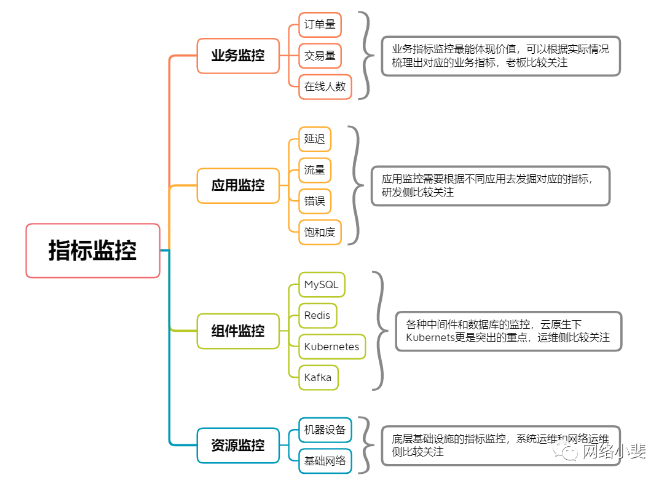
上图四个分类中,每类都有具体监控目标和对象,具体可以按照下面简单的分层关系图来看:
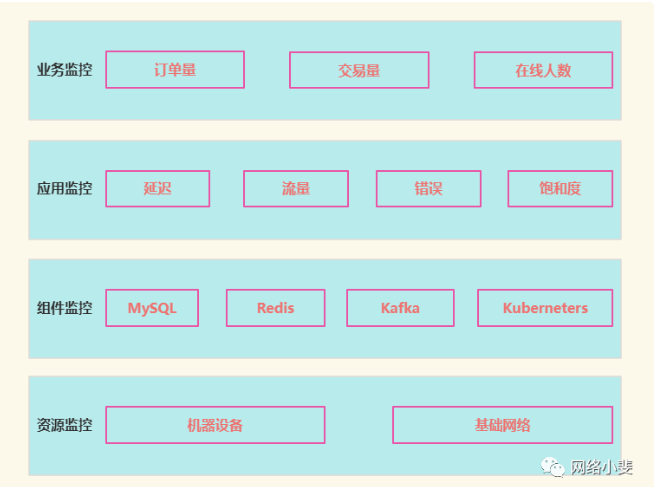
业务监控
这类指标是管理层非常关注的,代表企业营收,或者跟客户主流程相关,类似BI数据。不过相比BI数据,业务监控指标有两点不同。
对精确度要求没有那么高:因为监控只要发现趋势异常就可以,至于是从 5000 变成了 1000 还是变成了 1001,没有什么区别。对实时性要求很高:很多BI数据可能是小时级别或天级别的,这个时效性无法满足监控的需求,监控是希望越早发现问题越好,要是一个小时才发现问题,黄花菜都凉了。
技术人员应该针对这类指标做高优保障,如果所有的指标都同等对待,重要的告警就容易被普通告警淹没,所以 告警一定要分级对待 。
很多公司的故障管理比较粗放,只要有报警事件产生,就认为是有故障,这是不对的。在微服务和云原生技术盛行的当下,某个机器的 CPU 飙高了,或者 IO 打满了,对最终用户的体验可能是没有任何影响的,但是核心业务指标异常,一定是故障,因为这类指标异常代表着最终用户体验受损,或者造成了直接资损。
作为中后台的团队,做的很多稳定性保障的工作不容易让管理层看到, 业务指标是一个突破口 ,如果能够把这类指标梳理清楚,是很容易让老板看到我们的价值的。
应用监控
应用监控就是指对 应用程序 的监控,Google的四个黄金指标、RED方法主要就是针对应用监控的。
每个公司都应该有统一的APM,也就是应用性能管理方案,从指标着手的话一般使用埋点机制来做,比如 StatsD 、 Prometheus SDK 等,或者直接分析接入层日志,从日志提取指标;从链路追踪着手的话可以使用 Zipkin 、 SkyWalking 等。
像 Java 这种字节码技术的语言,采用 JavaAgent 技术可以做到代码无侵入埋点。但是像 Go 、 C++ 这类语言,一般都是采用埋点机制来做,由统一的工具团队提供一些框架,在框架里内置埋点逻辑,这样普通研发人员也就基本不会有代码侵入的感觉了。
组件监控
这里我们把各类数据库、中间件、云平台,统称为组件,组件监控是非常考验知识广度的。一般监控系统的研发人员,很难把每个组件的机理都搞清楚,所以定义统一的接入数据规范,让专业的人去采集各个组件的数据是更合理的做法。
有个好现象是,很多组件的研发人员,已经开始让组件自身直接支持 Prometheus ,吐出 metrics 数据,除了 etcd 、 Kubernetes 这些云原生时代的组件,一些老的组件,比如 RabbitMQ 、 ZooKeeper 等,也在新版本里直接做了支持,这种直接通过调用lib库,实现产品在代码中就埋点好的监控指标,真的很方便,希望越来越多的中间件产品能覆盖。
资源监控
基础资源的监控,主要是针对 设备和网络 ,设备又分为服务器、网络设备,网络监控又分为连通性监控、质量监控、流量监控,下面我们分别做个简单介绍。
设备监控
一提起设备监控,你可能立马会想到 CPU、内存使用率监控,除了这些之外,如果我们想获取硬件模块的健康状况,比如电源电压、风扇转速、主板环境温度等,就需要走 IPMI 协议,通过带外网络采集。网络设备,典型的就是交换机、防火墙,一般是通过 SNMP 协议获取指标,比如交换机各个网口的流量、包量。也可以通过 syslog 的方式,把交换机的日志转存出来,到服务器上分析。
现在越来越多的厂商对交换机已经开始支持Telemetry ,后续文章将展示如何使用 Telemetry 获取交换机的指标数据。
网络监控
网络连通性监控最为常见,通过 ICMP 协议,部署探针机器,对目标设备做 PING 探测,能探通就表示能连通,探测失败就是连不通。当然,有些机器可能是禁 PING 的,此时就需要用 TCP 或 HTTP 之类的协议去探测了。Prometheus生态组件中就有Blackbox Exporter采集器适配关于协议探测的数据采集。
PING 探测可以拿到丢包率和延迟数据,我们可以用这些数据分析网络质量。比如两个机房之间的专线,我们用 A 机房的探针去探测 B 机房的目的设备,就能轻易知道机房之间的网络质量情况。
最后是流量监控,也会用在多个地方,比如机器的网卡流量、交换机的网口流量、机房出口流量,也是整个监控体系的重要一环。
以上都是针对服务端监控,还有一个大类是端监控(比如 iOS 应用,我们会关注是否卡顿、有没有崩溃、白屏之类的,这算是另一个领域),这里就不展开说明。
后续我将在资源监控和组件监控做具体展开说明,并做出具体的说明和配置分享,应用和业务没有具体标准,故不做具体详细讲解。我总是秉持着 授人以鱼不如授人以渔 ,当把原理搞清楚,并且做了最佳实践,后续遇到任何问题都可以一通百通。特别是针对网络工程师很少涉及的设备监控的领域,之前很多都是基于 zabbix 做的网络设备监控,但是 zabbix 已经算是 监控1.0 时代的产品,并不太符合当下 监控2.0 ,甚至 监控3.0 的时代。最后说一句:最符合自己的监控那就是好监控,不必一定拘泥于小节。
关于监控1.0和2.0或者3.0可以查看这篇文章:[监控时代](https://mp.weixin.qq.com/s?search_click_id=12488940065080021477-1701615268483-7322543365&__biz=MzkzNjI5OTM5Nw&mid=2247485190&idx=1&sn=b29917ad2892dbb1a008ddd863a0b625&chksm=c2a199ecf5d610fa589aa790de390c013b8f250d24826618ff65448b586176a2cb0cb3e31312&ascene=21&devicetype=android-34&version=28002b50&nettype=WIFI&abtest_cookie=AAACAA&lang=zh_CN&countrycode=CN&exportkey=n_ChQIAhIQtyoUjSrRhTbfz6/1LLG6EhLcAQIE97dBBAEAAAAAANKqDKSFg6MAAAAOpnltbLcz9gKNyK89dVj0urkKO8WEAt0koLbOzm3KFi5t WJA7KuQuxUoiqkdFvvKuKgSsUX4aD8H6H0jK3mrATRR1TApNCxatrKbvY0vvsPN0//suy3BIeD PX/4QEeqMpll prbGbbuOTUb/oyTCjnNsR9yuBglqrtfpYjMdmS5MoC c7iZzTCY47Vpz0YCBv2aX/2ZtZ/X8GGKOw DQbDsd8d0TLk1WyEWoZ2sCbng ZdyRlsSZxB StZsRQC0Kan 65I=&pass_ticket=f9TmSUlErRL3a8aKjWr0p/2oek0XgzyGpYx/PtVARuDWys P3IGzEVBde/dbAHlvE4ZjeLKb8KP3mZwwm9mjug==&wx_header=3#wechat_redirect)
最后
这是我的《运维监控全套笔记》体系文章的开头篇,后续维持稳定更新,整套体系已完成70%左右,通过简单概览监控系统,初步对监控有个全局的认识,文章中的内容有些是自己总结的,有些是通过官网文档和网上课程以及极客时间上的课程学习摘抄的笔记,不过后续文章的具体实践分享都是原创内容,可以放心食用。
整套笔记目录共有五个阶段,比较全面。第一阶段如下:第一阶段是基础,需要的朋友可以细细品读。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号