去哪儿网旅游信息可视化
去哪儿网旅游信息可视化
一、摘要
该项目爬取去哪儿网旅游数据进行数据可视化,使用pyecharts库进行实现。
二、选题背景:
我国旅游行业的极速发展,因为疫情原因,使得国内旅游成为新风潮,由于国内疫情控制得当,使得中国成为最先开放旅游的国家,
本次项目可视化就是分析国内旅游的数据,分析适合出行旅游的时间与地点信息。
三、过程及代码:
1.设计爬取去哪儿网网页代码
import requests from bs4 import BeautifulSoup import re import time import csv import random #爬取每个网址的分页 fb = open(r'url.txt','w') url = 'http://travel.qunar.com/travelbook/list.htm?page={}&order=hot_heat&avgPrice=1_2' #请求头,cookies在电脑网页中可以查到 headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.360', 'cookies':'JSESSIONID=5E9DCED322523560401A95B8643B49DF; QN1=00002b80306c204d8c38c41b; QN300=s%3Dbaidu; QN99=2793; QN205=s%3Dbaidu; QN277=s%3Dbaidu; QunarGlobal=10.86.213.148_-3ad026b5_17074636b8f_-44df|1582508935699; QN601=64fd2a8e533e94d422ac3da458ee6e88; _i=RBTKSueZDCmVnmnwlQKbrHgrodMx; QN269=D32536A056A711EA8A2FFA163E642F8B; QN48=6619068f-3a3c-496c-9370-e033bd32cbcc; fid=ae39c42c-66b4-4e2d-880f-fb3f1bfe72d0; QN49=13072299; csrfToken=51sGhnGXCSQTDKWcdAWIeIrhZLG86cka; QN163=0; Hm_lvt_c56a2b5278263aa647778d304009eafc=1582513259,1582529930,1582551099,1582588666; viewdist=298663-1; uld=1-300750-1-1582590496|1-300142-1-1582590426|1-298663-1-1582590281|1-300698-1-1582514815; _vi=6vK5Gry4UmXDT70IFohKyFF8R8Mu0SvtUfxawwaKYRTq9NKud1iKUt8qkTLGH74E80hXLLVOFPYqRGy52OuTFnhpWvBXWEbkOJaDGaX_5L6CnyiQPPOYb2lFVxrJXsVd-W4NGHRzYtRQ5cJmiAbasK8kbNgDDhkJVTC9YrY6Rfi2; viewbook=7562814|7470570|7575429|7470584|7473513; QN267=675454631c32674; Hm_lpvt_c56a2b5278263aa647778d304009eafc=1582591567; QN271=c8712b13-2065-4aa7-a70b-e6156f6fc216', 'referer':'http://travel.qunar.com/travelbook/list.htm?page=1&order=hot_heat&avgPrice=1'} count = 1 #共200页 for i in range(1,201): url_ = url.format(i) try: response = requests.get(url=url_,headers = headers) response.encoding = 'utf-8' html = response.text soup = BeautifulSoup(html,'lxml') #print(soup) all_url = soup.find_all('li',attrs={'class': 'list_item'}) #print(all_url[0]) ''' for i in range(len(all_url)): #p = re.compile(r'data-url="/youji/\d+">') url = re.findall('data-url="(.*?)"', str(i), re.S) #url = re.search(p,str(i)) print(url) ''' print('正在爬取第%s页' % count) for each in all_url: each_url = each.find('h2')['data-bookid'] #print(each_url) fb.write(each_url) fb.write('\n') #last_url = each.find('li', {"class": "list_item last_item"})['data-url'] #print(last_url) time.sleep(random.randint(3,5)) count+=1 except Exception as e: print(e) url_list = [] with open('url.txt','r') as f: for i in f.readlines(): i = i.strip() url_list.append(i) the_url_list = [] for i in range(len(url_list)): url = 'http://travel.qunar.com/youji/' the_url = url + str(url_list[i]) the_url_list.append(the_url) last_list = [] def spider(): headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.360', 'cookies': 'QN1=00002b80306c204d8c38c41b; QN300=s%3Dbaidu; QN99=2793; QN205=s%3Dbaidu; QN277=s%3Dbaidu; QunarGlobal=10.86.213.148_-3ad026b5_17074636b8f_-44df|1582508935699; QN601=64fd2a8e533e94d422ac3da458ee6e88; _i=RBTKSueZDCmVnmnwlQKbrHgrodMx; QN269=D32536A056A711EA8A2FFA163E642F8B; QN48=6619068f-3a3c-496c-9370-e033bd32cbcc; fid=ae39c42c-66b4-4e2d-880f-fb3f1bfe72d0; QN49=13072299; csrfToken=51sGhnGXCSQTDKWcdAWIeIrhZLG86cka; QN163=0; Hm_lvt_c56a2b5278263aa647778d304009eafc=1582513259,1582529930,1582551099,1582588666; viewdist=298663-1; uld=1-300750-1-1582590496|1-300142-1-1582590426|1-298663-1-1582590281|1-300698-1-1582514815; viewbook=7575429|7473513|7470584|7575429|7470570; QN267=67545462d93fcee; _vi=vofWa8tPffFKNx9MM0ASbMfYySr3IenWr5QF22SjnOoPp1MKGe8_-VroXhkC0UNdM0WdUnvQpqebgva9VacpIkJ3f5lUEBz5uyCzG-xVsC-sIV-jEVDWJNDB2vODycKN36DnmUGS5tvy8EEhfq_soX6JF1OEwVFXk2zow0YZQ2Dr; Hm_lpvt_c56a2b5278263aa647778d304009eafc=1582603181; QN271=fc8dd4bc-3fe6-4690-9823-e27d28e9718c', 'Host': 'travel.qunar.com' } count = 1 for i in range(len(the_url_list)): try: print('正在爬取第%s页'% count) response = requests.get(url=the_url_list[i],headers = headers) response.encoding = 'utf-8' html = response.text soup = BeautifulSoup(html,'lxml') information = soup.find('p',attrs={'class': 'b_crumb_cont'}).text.strip().replace(' ','') info = information.split('>') if len(info)>2: location = info[1].replace('\xa0','').replace('旅游攻略','') introduction = info[2].replace('\xa0','') else: location = info[0].replace('\xa0','') introduction = info[1].replace('\xa0','') other_information = soup.find('ul',attrs={'class': 'foreword_list'}) when = other_information.find('li',attrs={'class': 'f_item when'}) time1 = when.find('p',attrs={'class': 'txt'}).text.replace('出发日期','').strip() howlong = other_information.find('li',attrs={'class': 'f_item howlong'}) day = howlong.find('p', attrs={'class': 'txt'}).text.replace('天数','').replace('/','').replace('天','').strip() howmuch = other_information.find('li',attrs={'class': 'f_item howmuch'}) money = howmuch.find('p', attrs={'class': 'txt'}).text.replace('人均费用','').replace('/','').replace('元','').strip() who = other_information.find('li',attrs={'class': 'f_item who'}) people = who.find('p',attrs={'class': 'txt'}).text.replace('人物','').replace('/','').strip() how = other_information.find('li',attrs={'class': 'f_item how'}) play = how.find('p',attrs={'class': 'txt'}).text.replace('玩法','').replace('/','').strip() Look = soup.find('span',attrs={'class': 'view_count'}).text.strip() if time1: Time = time1 else: Time = '-' if day: Day = day else: Day = '-' if money: Money = money else: Money = '-' if people: People = people else: People = '-' if play: Play = play else: Play = '-' last_list.append([location,introduction,Time,Day,Money,People,Play,Look]) #设置爬虫时间 time.sleep(random.randint(3,5)) count+=1 except Exception as e : print(e) #写入csv with open('Travel.csv', 'a', encoding='utf-8-sig', newline='') as csvFile: csv.writer(csvFile).writerow(['地点', '短评', '出发时间', '天数','人均费用','人物','玩法','浏览量']) for rows in last_list: csv.writer(csvFile).writerow(rows) if __name__ == '__main__': spider()
根据网页结构获取所需要的数据值,将数据插入csv文件,共爬取了1603个页面的数据
2.设计数据可视化代码
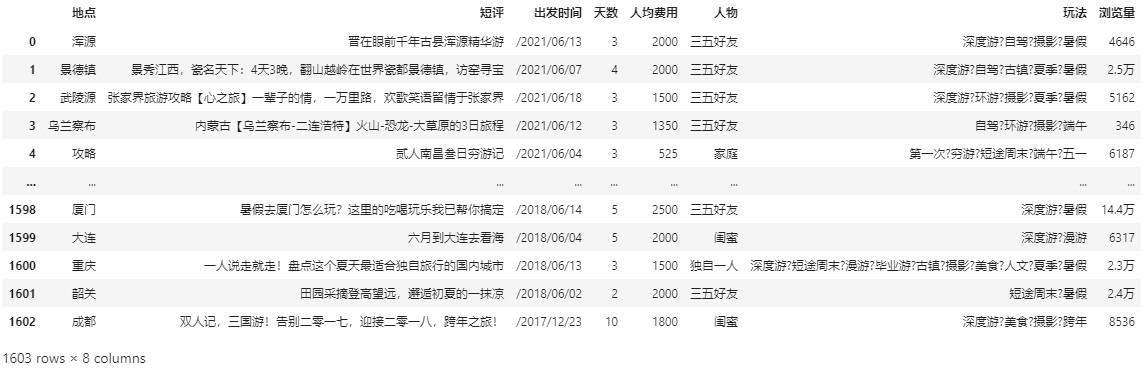
(1)读取爬取到的The_Travel.csv文件
import pandas as pd data = pd.read_csv('The_Travel.csv') data
(2)查看数据框的所有信息
data.info()

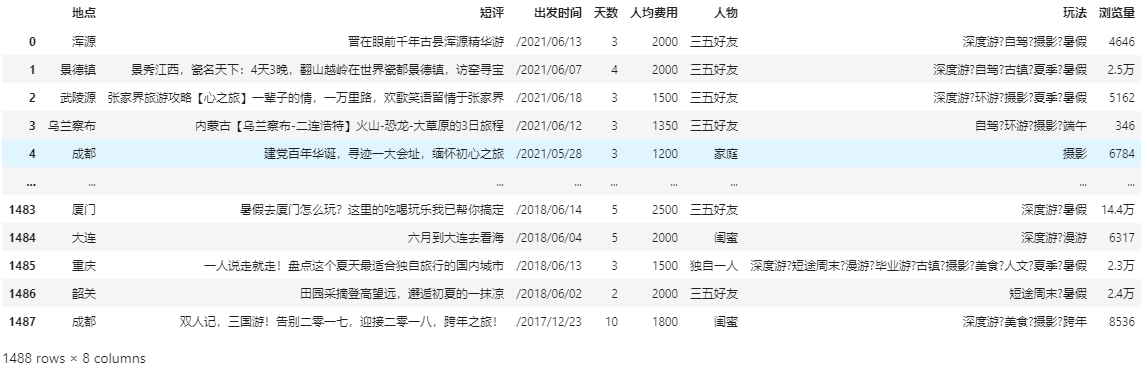
(3)根据条件把数据进行清洗
data = data[~data['地点'].isin(['攻略'])] data = data[~data['天数'].isin(['99+'])] data['天数'] = data['天数'].astype(int) data = data[data['人均费用'].values>200] data = data[data['天数']<=15] data = data.reset_index(drop=True) data
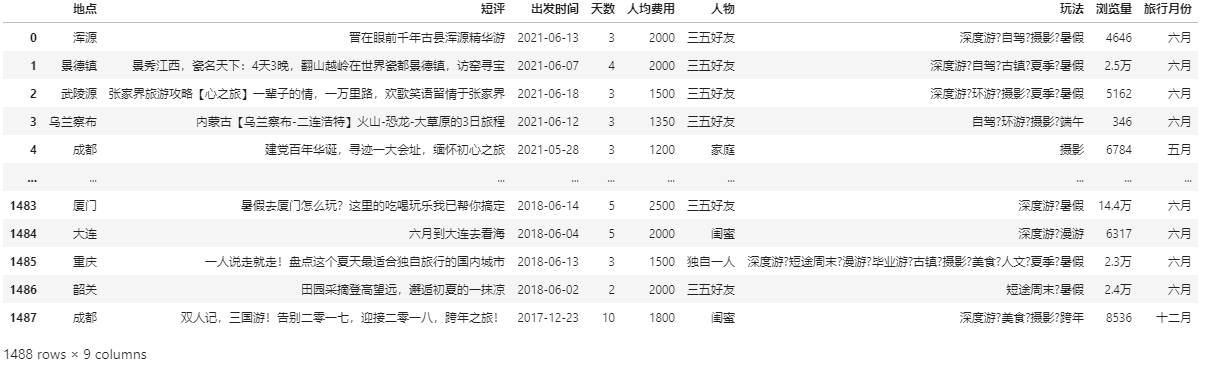
(4)筛选出旅行月份
def Month(e): m = str(e).split('/')[2] if m=='01': return '一月' if m=='02': return '二月' if m=='03': return '三月' if m=='04': return '四月' if m=='05': return '五月' if m=='06': return '六月' if m=='07': return '七月' if m=='08': return '八月' if m=='09': return '九月' if m=='10': return '十月' if m=='11': return '十一月' if m=='12': return '十二月' data['旅行月份'] = data['出发时间'].apply(Month) data['出发时间']=pd.to_datetime(data['出发时间']) data
(5)筛选出浏览次数,显示前几行
import re def Look(e): if '万' in e: num1 = re.findall('(.*?)万',e) return float(num1[0])*10000 else: return float(e) data['浏览次数'] = data['浏览量'].apply(Look) data.drop(['浏览量'],axis = 1,inplace = True) data['浏览次数'] = data['浏览次数'].astype(int) data.head()

(6)将旅行城市前几名进行计数并排序
data1 = data data1['地点'].value_counts().head(10)

(7)算出前十个城市的人均费用进行排序
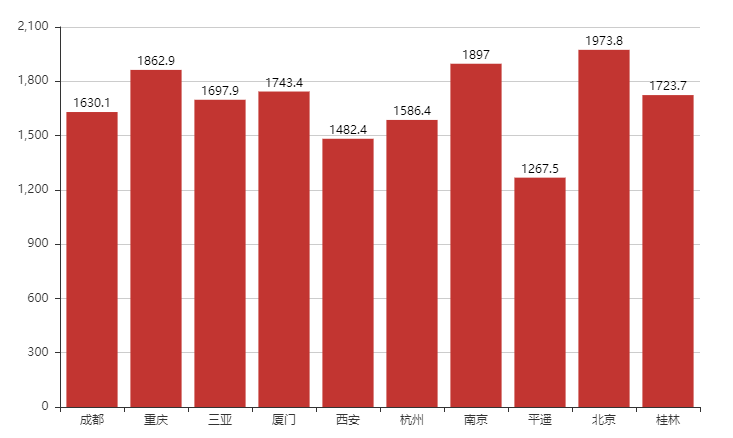
loc = data1['地点'].value_counts().head(10).index.tolist() print(loc) loc_data = data1[data1['地点'].isin(loc)] price_mean = round(loc_data['人均费用'].groupby(loc_data['地点']).mean(),1) print(price_mean) price_mean2 = [1630.1,1862.9,1697.9,1743.4,1482.4,1586.4,1897.0,1267.5,1973.8,1723.7]

(8)绘制前十个城市人均消费的柱状图
from pyecharts import Bar bar = Bar('目的地Top10人均费用',width = 800,height = 500,title_text_size = 20) bar.add('',loc,price_mean2,is_label_show = True,is_legend_show= True) bar.render('人均费用.html')
(9)筛选出旅行天数
data1['旅行时长'] = data1['天数'].apply(lambda x:str(x) + '天') data1
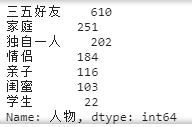
(10)将出游人物进行排序
data1['人物'].value_counts()
(11)筛选出浏览次数,并进行排序
m = data1['浏览次数'].sort_values(ascending=False).index[:].tolist() data1 = data1.loc[m] data1 = data1.reset_index(drop = True) data1
(12)将旅行次数最多的月份进行排序
data1['旅行月份'].value_counts()

(13)取出玩法数据加入列表
word_list = [] for i in data1['玩法']: s = re.split('\xa0',i) word_list.append(s) dict = {} for j in range(len(word_list)): for i in word_list[j]: if i not in dict: dict[i] = 1 else: dict[i]+=1 list = [] for item in dict.items(): list.append(item) for i in range(1,len(list)): for j in range(0,len(list)-1): if list[j][1]<list[j+1][1]: list[j],list[j+1] = list[j+1],list[j] print(list)

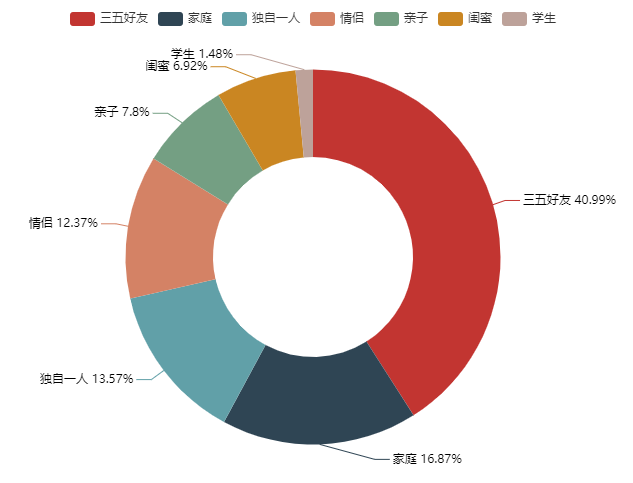
(14)绘制出游方式的环形图
from pyecharts import Pie m1 = data1['人物'].value_counts().index.tolist() n1 = data1['人物'].value_counts().values.tolist() pie =Pie('出游结伴方式',background_color = 'white',width = 800,height = 500,title_text_size = 20) pie.add('',m1,n1,is_label_show = True,is_legend_show= True,radius=[40, 75]) pie.render('1.html')
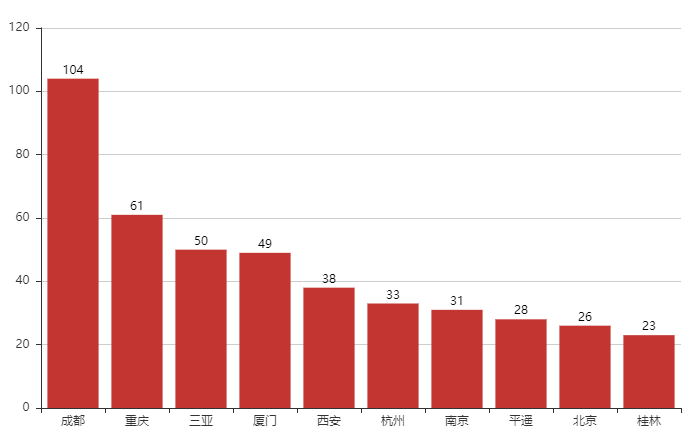
(15)绘制目的地前十的柱形图
from pyecharts import Bar m2 = data1['地点'].value_counts().head(10).index.tolist() n2 = data1['地点'].value_counts().head(10).values.tolist() bar = Bar('',width = 800,height = 500,title_text_size = 20) bar.add('',m2,n2,is_label_show = True,is_legend_show= True) bar.render('前十目的地'.html')
(16)绘制2021年出游曲线
from pyecharts import Line m3 = data1['出发时间'].value_counts().sort_index()[:] m4 = m3['2021'].index n4 = m3['2021'].values m3['2021'].sort_values().tail(10) line = Line('出游时间曲线',width = 800,height = 500,title_text_size = 20) line.add('',m4,n4,is_legend_show= True) line.render('出游曲线.html')

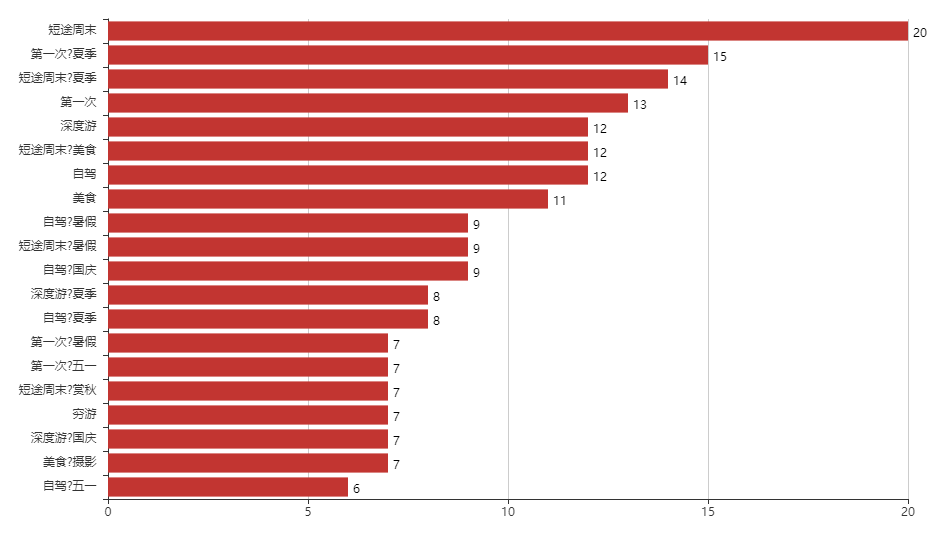
(17)绘制出游玩法柱状图
m5 = [] n5 = [] for i in range(20): m5.append(list[i][0]) n5.append(list[i][1]) m5.reverse() m6 = m5 n5.reverse() n6 = n5 bar = Bar('出游玩法',width = 1000,height = 600,title_text_size = 30) bar.add('',m6,n6,is_convert = True,is_label_show = True,label_pos = 'right') bar.render('出游玩法.html')
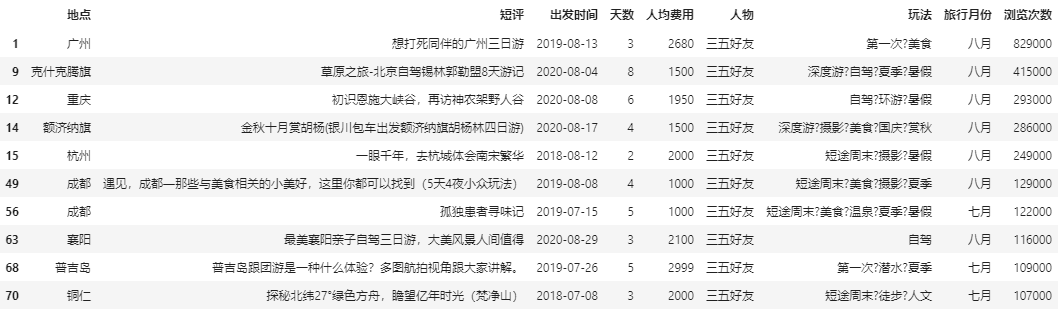
(18)筛选七月和八月人物为三五好友按照浏览次数进行排序
data_mo = data1[((data1['旅行月份'] =='七月')|(data1['旅行月份'] =='八月'))&(data1['人物']=='三五好友')].drop(['旅行时长'],axis = 1) data_mo.head(10)
主要代码:
1 import requests 2 from bs4 import BeautifulSoup 3 import re 4 import time 5 import csv 6 import random 7 #爬取每个网址的分页 8 fb = open(r'url.txt','w') 9 url = 'http://travel.qunar.com/travelbook/list.htm?page={}&order=hot_heat&avgPrice=1_2' 10 #请求头,cookies在电脑网页中可以查到 11 headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.360', 12 'cookies':'JSESSIONID=5E9DCED322523560401A95B8643B49DF; QN1=00002b80306c204d8c38c41b; QN300=s%3Dbaidu; QN99=2793; QN205=s%3Dbaidu; QN277=s%3Dbaidu; QunarGlobal=10.86.213.148_-3ad026b5_17074636b8f_-44df|1582508935699; QN601=64fd2a8e533e94d422ac3da458ee6e88; _i=RBTKSueZDCmVnmnwlQKbrHgrodMx; QN269=D32536A056A711EA8A2FFA163E642F8B; QN48=6619068f-3a3c-496c-9370-e033bd32cbcc; fid=ae39c42c-66b4-4e2d-880f-fb3f1bfe72d0; QN49=13072299; csrfToken=51sGhnGXCSQTDKWcdAWIeIrhZLG86cka; QN163=0; Hm_lvt_c56a2b5278263aa647778d304009eafc=1582513259,1582529930,1582551099,1582588666; viewdist=298663-1; uld=1-300750-1-1582590496|1-300142-1-1582590426|1-298663-1-1582590281|1-300698-1-1582514815; _vi=6vK5Gry4UmXDT70IFohKyFF8R8Mu0SvtUfxawwaKYRTq9NKud1iKUt8qkTLGH74E80hXLLVOFPYqRGy52OuTFnhpWvBXWEbkOJaDGaX_5L6CnyiQPPOYb2lFVxrJXsVd-W4NGHRzYtRQ5cJmiAbasK8kbNgDDhkJVTC9YrY6Rfi2; viewbook=7562814|7470570|7575429|7470584|7473513; QN267=675454631c32674; Hm_lpvt_c56a2b5278263aa647778d304009eafc=1582591567; QN271=c8712b13-2065-4aa7-a70b-e6156f6fc216', 13 'referer':'http://travel.qunar.com/travelbook/list.htm?page=1&order=hot_heat&avgPrice=1'} 14 count = 1 15 #共200页 16 for i in range(1,201): 17 url_ = url.format(i) 18 try: 19 response = requests.get(url=url_,headers = headers) 20 response.encoding = 'utf-8' 21 html = response.text 22 soup = BeautifulSoup(html,'lxml') 23 #print(soup) 24 all_url = soup.find_all('li',attrs={'class': 'list_item'}) 25 #print(all_url[0]) 26 ''' 27 for i in range(len(all_url)): 28 #p = re.compile(r'data-url="/youji/\d+">') 29 url = re.findall('data-url="(.*?)"', str(i), re.S) 30 #url = re.search(p,str(i)) 31 print(url) 32 ''' 33 print('正在爬取第%s页' % count) 34 for each in all_url: 35 each_url = each.find('h2')['data-bookid'] 36 #print(each_url) 37 fb.write(each_url) 38 fb.write('\n') 39 #last_url = each.find('li', {"class": "list_item last_item"})['data-url'] 40 #print(last_url) 41 time.sleep(random.randint(3,5)) 42 count+=1 43 except Exception as e: 44 print(e) 45 46 url_list = [] 47 with open('url.txt','r') as f: 48 for i in f.readlines(): 49 i = i.strip() 50 url_list.append(i) 51 52 the_url_list = [] 53 for i in range(len(url_list)): 54 url = 'http://travel.qunar.com/youji/' 55 the_url = url + str(url_list[i]) 56 the_url_list.append(the_url) 57 last_list = [] 58 def spider(): 59 headers = { 60 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.360', 61 'cookies': 'QN1=00002b80306c204d8c38c41b; QN300=s%3Dbaidu; QN99=2793; QN205=s%3Dbaidu; QN277=s%3Dbaidu; QunarGlobal=10.86.213.148_-3ad026b5_17074636b8f_-44df|1582508935699; QN601=64fd2a8e533e94d422ac3da458ee6e88; _i=RBTKSueZDCmVnmnwlQKbrHgrodMx; QN269=D32536A056A711EA8A2FFA163E642F8B; QN48=6619068f-3a3c-496c-9370-e033bd32cbcc; fid=ae39c42c-66b4-4e2d-880f-fb3f1bfe72d0; QN49=13072299; csrfToken=51sGhnGXCSQTDKWcdAWIeIrhZLG86cka; QN163=0; Hm_lvt_c56a2b5278263aa647778d304009eafc=1582513259,1582529930,1582551099,1582588666; viewdist=298663-1; uld=1-300750-1-1582590496|1-300142-1-1582590426|1-298663-1-1582590281|1-300698-1-1582514815; viewbook=7575429|7473513|7470584|7575429|7470570; QN267=67545462d93fcee; _vi=vofWa8tPffFKNx9MM0ASbMfYySr3IenWr5QF22SjnOoPp1MKGe8_-VroXhkC0UNdM0WdUnvQpqebgva9VacpIkJ3f5lUEBz5uyCzG-xVsC-sIV-jEVDWJNDB2vODycKN36DnmUGS5tvy8EEhfq_soX6JF1OEwVFXk2zow0YZQ2Dr; Hm_lpvt_c56a2b5278263aa647778d304009eafc=1582603181; QN271=fc8dd4bc-3fe6-4690-9823-e27d28e9718c', 62 'Host': 'travel.qunar.com' 63 } 64 count = 1 65 for i in range(len(the_url_list)): 66 try: 67 print('正在爬取第%s页'% count) 68 response = requests.get(url=the_url_list[i],headers = headers) 69 response.encoding = 'utf-8' 70 html = response.text 71 soup = BeautifulSoup(html,'lxml') 72 information = soup.find('p',attrs={'class': 'b_crumb_cont'}).text.strip().replace(' ','') 73 info = information.split('>') 74 if len(info)>2: 75 location = info[1].replace('\xa0','').replace('旅游攻略','') 76 introduction = info[2].replace('\xa0','') 77 else: 78 location = info[0].replace('\xa0','') 79 introduction = info[1].replace('\xa0','') 80 other_information = soup.find('ul',attrs={'class': 'foreword_list'}) 81 when = other_information.find('li',attrs={'class': 'f_item when'}) 82 time1 = when.find('p',attrs={'class': 'txt'}).text.replace('出发日期','').strip() 83 howlong = other_information.find('li',attrs={'class': 'f_item howlong'}) 84 day = howlong.find('p', attrs={'class': 'txt'}).text.replace('天数','').replace('/','').replace('天','').strip() 85 howmuch = other_information.find('li',attrs={'class': 'f_item howmuch'}) 86 money = howmuch.find('p', attrs={'class': 'txt'}).text.replace('人均费用','').replace('/','').replace('元','').strip() 87 who = other_information.find('li',attrs={'class': 'f_item who'}) 88 people = who.find('p',attrs={'class': 'txt'}).text.replace('人物','').replace('/','').strip() 89 how = other_information.find('li',attrs={'class': 'f_item how'}) 90 play = how.find('p',attrs={'class': 'txt'}).text.replace('玩法','').replace('/','').strip() 91 Look = soup.find('span',attrs={'class': 'view_count'}).text.strip() 92 if time1: 93 Time = time1 94 else: 95 Time = '-' 96 if day: 97 Day = day 98 else: 99 Day = '-' 100 if money: 101 Money = money 102 else: 103 Money = '-' 104 if people: 105 People = people 106 else: 107 People = '-' 108 if play: 109 Play = play 110 else: 111 Play = '-' 112 last_list.append([location,introduction,Time,Day,Money,People,Play,Look]) 113 #设置爬虫时间 114 time.sleep(random.randint(3,5)) 115 count+=1 116 except Exception as e : 117 print(e) 118 #写入csv 119 with open('Travel.csv', 'a', encoding='utf-8-sig', newline='') as csvFile: 120 csv.writer(csvFile).writerow(['地点', '短评', '出发时间', '天数','人均费用','人物','玩法','浏览量']) 121 for rows in last_list: 122 csv.writer(csvFile).writerow(rows) 123 if __name__ == '__main__': 124 spider() 125 #读取爬取到的The_Travel.csv文件 126 import pandas as pd 127 data = pd.read_csv('The_Travel.csv') 128 data 129 #查看数据框的所有信息 130 data.info() 131 #根据条件把数据进行清洗 132 data = data[~data['地点'].isin(['攻略'])] 133 data = data[~data['天数'].isin(['99+'])] 134 data['天数'] = data['天数'].astype(int) 135 data = data[data['人均费用'].values>200] 136 data = data[data['天数']<=15] 137 data = data.reset_index(drop=True) 138 data 139 #筛选出旅行月份 140 def Month(e): 141 m = str(e).split('/')[2] 142 if m=='01': 143 return '一月' 144 if m=='02': 145 return '二月' 146 if m=='03': 147 return '三月' 148 if m=='04': 149 return '四月' 150 if m=='05': 151 return '五月' 152 if m=='06': 153 return '六月' 154 if m=='07': 155 return '七月' 156 if m=='08': 157 return '八月' 158 if m=='09': 159 return '九月' 160 if m=='10': 161 return '十月' 162 if m=='11': 163 return '十一月' 164 if m=='12': 165 return '十二月' 166 data['旅行月份'] = data['出发时间'].apply(Month) 167 data['出发时间']=pd.to_datetime(data['出发时间']) 168 data 169 #筛选出浏览次数,显示前几行 170 import re 171 def Look(e): 172 if '万' in e: 173 num1 = re.findall('(.*?)万',e) 174 return float(num1[0])*10000 175 else: 176 return float(e) 177 data['浏览次数'] = data['浏览量'].apply(Look) 178 data.drop(['浏览量'],axis = 1,inplace = True) 179 data['浏览次数'] = data['浏览次数'].astype(int) 180 data.head() 181 #将旅行城市前几名进行计数并排序 182 data1 = data 183 data1['地点'].value_counts().head(10) 184 #算出前十个城市的人均费用进行排序 185 loc = data1['地点'].value_counts().head(10).index.tolist() 186 print(loc) 187 loc_data = data1[data1['地点'].isin(loc)] 188 price_mean = round(loc_data['人均费用'].groupby(loc_data['地点']).mean(),1) 189 print(price_mean) 190 price_mean2 = [1630.1,1862.9,1697.9,1743.4,1482.4,1586.4,1897.0,1267.5,1973.8,1723.7] 191 #绘制前十个城市人均消费的柱状图 192 from pyecharts import Bar 193 bar = Bar('目的地Top10人均费用',width = 800,height = 500,title_text_size = 20) 194 bar.add('',loc,price_mean2,is_label_show = True,is_legend_show= True) 195 bar.render('人均费用.html') 196 #筛选出旅行天数 197 data1['旅行时长'] = data1['天数'].apply(lambda x:str(x) + '天') 198 data1 199 #将出游人物进行排序 200 data1['人物'].value_counts() 201 #筛选出浏览次数,并进行排序 202 m = data1['浏览次数'].sort_values(ascending=False).index[:].tolist() 203 data1 = data1.loc[m] 204 data1 = data1.reset_index(drop = True) 205 data1 206 #将旅行次数最多的月份进行排序 207 data1['旅行月份'].value_counts() 208 #取出玩法数据加入列表 209 word_list = [] 210 for i in data1['玩法']: 211 s = re.split('\xa0',i) 212 word_list.append(s) 213 dict = {} 214 for j in range(len(word_list)): 215 for i in word_list[j]: 216 if i not in dict: 217 dict[i] = 1 218 else: 219 dict[i]+=1 220 list = [] 221 for item in dict.items(): 222 list.append(item) 223 for i in range(1,len(list)): 224 for j in range(0,len(list)-1): 225 if list[j][1]<list[j+1][1]: 226 list[j],list[j+1] = list[j+1],list[j] 227 print(list) 228 #绘制出游方式的环形图 229 from pyecharts import Pie 230 231 m1 = data1['人物'].value_counts().index.tolist() 232 n1 = data1['人物'].value_counts().values.tolist() 233 pie =Pie('出游结伴方式',background_color = 'white',width = 800,height = 500,title_text_size = 20) 234 pie.add('',m1,n1,is_label_show = True,is_legend_show= True,radius=[40, 75]) 235 pie.render('1.html') 236 #绘制目的地前十的柱形图 237 from pyecharts import Bar 238 239 m2 = data1['地点'].value_counts().head(10).index.tolist() 240 n2 = data1['地点'].value_counts().head(10).values.tolist() 241 242 bar = Bar('',width = 800,height = 500,title_text_size = 20) 243 bar.add('',m2,n2,is_label_show = True,is_legend_show= True) 244 bar.render('前十目的地'.html') 245 #绘制2021年出游曲线 246 from pyecharts import Line 247 248 m3 = data1['出发时间'].value_counts().sort_index()[:] 249 m4 = m3['2021'].index 250 n4 = m3['2021'].values 251 252 m3['2021'].sort_values().tail(10) 253 254 line = Line('出游时间曲线',width = 800,height = 500,title_text_size = 20) 255 line.add('',m4,n4,is_legend_show= True) 256 line.render('出游曲线.html') 257 #绘制出游玩法柱状图 258 m5 = [] 259 n5 = [] 260 for i in range(20): 261 m5.append(list[i][0]) 262 n5.append(list[i][1]) 263 m5.reverse() 264 m6 = m5 265 n5.reverse() 266 n6 = n5 267 bar = Bar('出游玩法',width = 1000,height = 600,title_text_size = 30) 268 bar.add('',m6,n6,is_convert = True,is_label_show = True,label_pos = 'right') 269 bar.render('出游玩法.html') 270 #筛选七月和八月人物为三五好友按照浏览次数进行排序 271 data_mo = data1[((data1['旅行月份'] =='七月')|(data1['旅行月份'] =='八月'))&(data1['人物']=='三五好友')].drop(['旅行时长'],axis = 1) 272 data_mo.head(10)
四、总结
综上所有数据可知,我们用去哪儿网对于国内旅游城市进行了一定的分析以及排名,让人们出游有更加合理的选择,更体现国内疫情后每个城市旅行的情况。
