【读书笔记】go语言学习指南 - 基础类型和变量声明
基础类型和变量声明
内置类型
go语言中内置了很多的基础类型:
- 布尔型(boolean)
- 整型(integer)
- 浮点型(float)
- 字符串(string)
零值
在go语言中,一个变量声明但是未赋值的变量会被go赋予零值,这样做的好处可以让代码变得更加简洁清晰。
字面量
在go中,一个值的字面形式被称为一个字面量。一个值可能有很多种字面量形式,它可能是数字(整数和浮点数)、字符或者字符串。
整数字面量
整数字面量默认情况下是十进制的数字序列,但是使用不同的特定前缀(前缀不区分大小写)来表示不同进制的数。
例如,当以0b或者0B为前缀时表示二进制(以2为基数),以0o或者0O为前缀时表示八进制,以0x或者0X为前缀时表示十六进制(以16为基数)。
定义整数字面量时以0为前缀也可以表示八进制,但是并不建议使用这种方式,容易让人产生误解。
浮点数字面量
浮点数字面量由整数部分、小数点、小数部分组成。也可以表示成指数形式,如6.03e23。当表示十六进制数时,可以使用0x作为前缀和字母p来表示指数。
字符字面量
字符字面量由被一对单引号包围的字符组成。
在go中,单引号和双引号表示的是不同的字面量。
字符字面量可以写成Unicode字符('a')、8位八进制数('\141')、8位十六进制数('\x61')、16位十六进制数('\u0061')或者32位Unicode数('\u00000061')。
反斜线还可以结合一些字符表示转义字符,常见的由换行符('\n')、制表符('\t')、单引号(''')、双引号('"')、和反斜杠('\')。
实际使用中,我们最好使用十进制来表示数字字面量,并且尽量避免使用十六进制转义来表示字符字面量,除非需要表达更清晰的表达意图。
八进制很少出现,主要用于表示POSIX文件系统中的权限值,比如可以使用0o777表示rwxrwxrwx。
字符串字面量
字符串字面量有两种格式:原始字符串字面量(raw string literal, 反引号风格) 和 解释性字符串字面量(interpreted string literal, 双引号风格)。
当希望在字符串中包含反斜杠、双引号或者换行符时,可以使用原始字符串字面量,在原始字符串字面量中可以包含除反引号之外的任意字符。
布尔型
go中使用bool类表示布尔变量,bool变量只有两种状态值:false 和 true。bool类型的零值是false。
var flag bool // no value assigned, set to false
数值类型
go中的数值类型体系,可以分为三大类和12种不同的数值类型。
整型
go中有带符号整型和无符号整型。由1-4个字节组成[我们使用字节byte作为值大小的度量单位。一个字节相当于8个比特,所以uint32类型的大小为4字节,即每个uint32值占用4个字节]。

这些整型的零值都是0。
特殊的整型
go有一些整型的名称十分特殊。byte是uint8的别名,所以可以在byte和uint8之间进行赋值、比较或者执行数学运算。更多的时候,在代码中使用byte更加直观,很少使用uint8.
第二个特殊的是int,在32位cpu上,int等同于int32,在64位cpu上,int等于int64。
因为int在不同平台的差异性,所以在不做显示类型转换的情况下,在int和int32或者int64之间进行赋值、比较或者执行数学运算时会产生编译时错误。整数字面量默认使用int类型。
第三个特殊的是uint,它遵循与int一样的语言规范,但是因为uint是无符号整型,所以uint的值只能是0或者合法取值范围内的正数。
最后两个特殊的整型是rune和uintptr(后面章节会讲到)。
正确使用整型
go针对很多不同的场景提供了很多的整型,当对整型的使用存在疑惑时,go官方推荐了三条规则作为参考:
- 在处理二进制文件或者实现网络协议时,请根据实际需要的变量大小和有无符号来选择对应的整型。
- 如果正在编写一个可适用于任何整型的库函数,通常推荐编写一对函数,一个函数的参数和变量为int64,另一个为uint64。
这样的模式在go标准库中大量使用。例如strconv包中的FormatInt/FormatUint函数对和ParseInt/ParseUint函数对。这些函数对,算法和逻辑相同,但是函数参数类型不同,可以为不同类型编写单独的函数,在math/bits的包中大量使用了这种模式。
- 其他情况下,int可以通用。
除非需要集成其他新系统或者有特殊的性能要求,需要显示的说明整型大小或者有无符号,否则使用int即可。不必做过度设计和优化。
整型操作符
go中支持常用的算数运算符:
+-*/%
整型的除法运算结果还是整型,如果希望得到浮点型的结果,就需要使用类型转换将整型转换为浮点型。
整型除法的小数点后的数会被丢弃(这叫做“向零截断的原则”)。
上面的这些算数运算符可以和等号相结合,用于简化整型的运算:
+=-=*=/=%=
还有位运算符:
<<左移>>右移&与|或^异或&^与非
浮点型
浮点型支持两种浮点:float32和float64。
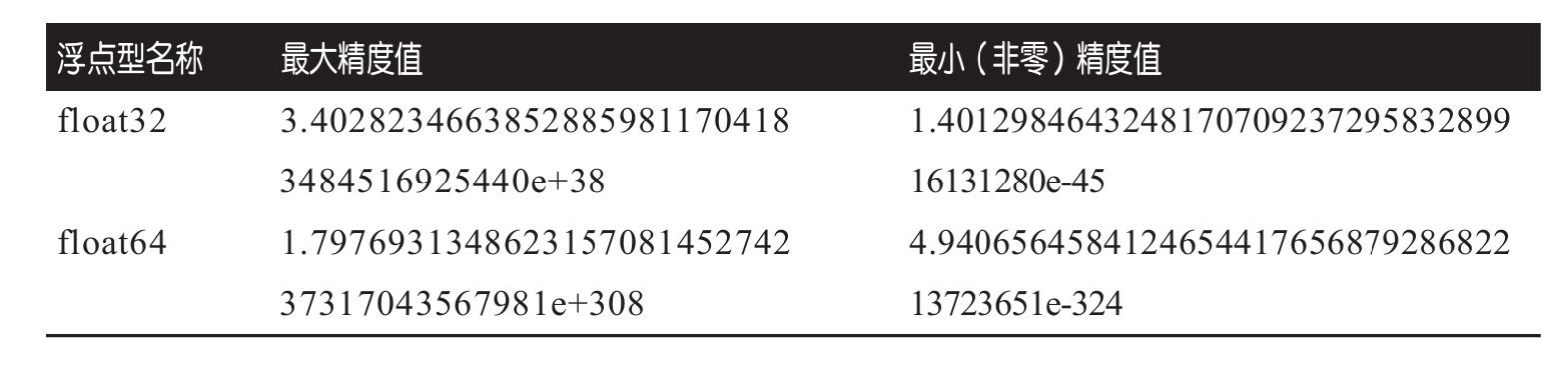
浮点型的零值也是0。
go中的浮点型遵循IEEE 754规范。float64比float32有更高的精度,建议在没有特定兼容性的要求下,尽量使用float64。浮点型字面量的默认类型也是float64,所以float64是最简单的选择。
因为存储的长度,浮点数只能取到近似值,丢失了部分精度,这在图形学和科学计算中尤为突出。
浮点数不能精确的表示十进制数。任何对精度要求比较高的情况下都不要使用浮点数,比如表示金额。

浮点数可以进行除了%之外的任意数学运算或者比较运算。
任何非0的数除以浮点数0,将返回+Inf(正无穷大)或者-Inf(负无穷大),其中正负号取决于被除数的符号。
当0除以0时得到NaN。
因为浮点数不精确的特点,最好不要对浮点型使用==和!=比较运算符,你可能会发现比较两个浮点数时结果和预期不一致,这是因为计算机在处理浮点数时会丢失精度。
通常比较两个浮点数是否相等需要定义一个最小方差,然后比较两个浮点数之间差异是否小于这个最小值。
字符串和字符
字符串的零值为空字符串。go支持Unicode编码,任何的Unicode编码字符都可以放入字符串中,同时可以使用== 和 != 进行比较,使用> 、>=、或者 < 或者<=进行比较排序,使用+将字符串合并成一个新的字符串。
字符串是不可变的,编程中这表示一个一旦被设置就不能改变的值,即当修改了一个字符串的变量值后,字符串就已经不再是原来的字符串了。
字符串中每一个Unicode字符都被称为字符(rune), 而且字符是一个特殊的类型,是int32的别名,类似于前面说过的byte是uint8的别名一样。
字符字面量默认类型是字符,字符串字面量的默认类型是字符串。
显示类型转换
在go中为了让设计逻辑和代码可读性更强,并不允许变量之间进行自动类型转换,当变量之间的类型不一致时,就必须进行显式类型准换。
就算变量值是整型或者浮点型,只要类型的大小不同,也必须转换成相同的类型。
例如:
var x int = 10
var y float64 = 30.2
var z float64 = float64(x) + y
var d int = x + int(y)
上面的代码中定义了4个变量,x是一个值为10的整型变量(int), y是一个值为30.2的浮点型变量(float64)。由于它们的类型不同,因此需要转换后才能将它们相加,计算结果z是一个浮点型(float64),所以需要将x转换为float64类型。计算结果d是一个整型(int),所以需要将float64类型的y转换成int类型。这段代码的运行结果是z值为40.2,d是40。
在go中较为严格的类型还有其他意义,由于在go中所有类型转换都必须是显式的,所以不能将一些类型看作是布尔类型。在一些编程语言中,一个非0数字或者非空字符串都可以被解释为布尔值true,这是上面提到的自动类型转换,这样的“真值”行为在go中是不被支持的,无论是使用显示还是隐式类型转换都不行,只能通过比较运算符
==、!=、>、<、<=或者>=。例如,如果需要判断x是否等于0,则使用x==0;如果判断字符串s是否为空字符串,则需要使用s==""。
var 与 :=
go中提供了多种声明变量的方法,这么做的目的是希望通过每种不同的变量声明风格来精确的传达出使用变量的意图。
最冗长的方式是使用var关键字,同时需要显式的设置标注类型,然后赋值。例如:
var x int = 10
如果=右侧是变量的预期类型,那么可以省略=左侧的类型。因为整数字面量的默认类型是整型,所以下面声明的变量x是整型:
var x = 10
如果声明了一个变量,并没有对其赋值,即没有=及右边的部分,则变量的值是零值:
var x int
当有多个类型相同的变量需要声明时,可以使用:
var x, y int = 10, 20
声明多个零值变量,可以使用:
var x, y int
如果多个变量的类型不一致,可以使用上面介绍的省略类型的方式:
var x, y = 10, "hello"
使用关键字var一次声明多个变量时,可以使用如下形式:
var (
x int
y = 20
z int = 30
d, e = 40, "hello"
f, g string
)
go还支持短声明格式,即使用赋值运算符:=代替var的形式。下面的两行代码都声明一个值为10的整型变量x:
var x = 10
x := 10
与var一样,:=也可以一次性声明多个变量,下面的两行代码都是将10赋值给变量x,将"hello"赋值给y:
var x, y = 10, "hello"
x, y := 10, "hello"
:= 运算符还有使用var关键字无法完成的功能:它允许对已经赋值的变量再次进行赋值,只要:=左边有任意一个新变量即可:
x := 10
x, y := 30, "hello"
上面这种:=的短声明格式只能用来声明在函数内部的局部变量,如果在包级别声明变量,只能使用var关键字,:=是不合法的。
该如何选择变量的声明方式呢?
只要编写的代码能表达意图、让代码保持可读性即可。通常,在函数内部选择使用:=这种短声明方式,在函数外,包级别使用var的多变量声明格式。
不过,以下的几种情况在函数内应该避免使用:= :
- 当需要初始化一个变量为零值时,使用var x int,这清晰的表达了零值的意图。
- 当需要将无类型常量或者字面量赋值给一个变量时,如果常量或者字面量的默认类型不是变量的预期类型,需要使用var标准形式声明变量。尽管可以使用:=的方式进行类型转换,例如 x := byte(20),但是还是建议使用go语言的惯用方法var x byte = 20。
- 因为:=既可以赋值给新变量也可以赋值给现有变量,所以会导致当你认为在重用现有变量时,却在创建变量。为了避免这种存在歧义的方式,建议显示的使用var关键字声明所有的新变量,然后用赋值运算符=为新旧变量进行赋值。
要谨慎在函数外的包代码块(package block)内声明变量。当一个变量在函数外时,意味着它可能有太多被修改的途径 ,理解和追踪这些途径太困难,会导致一些不易察觉的bug。所以包代码块中声明的变量应该是不可变的。
避免在函数外声明变量,否则会导致数据流分析变得复杂。
在go中如果想要声明一个不可变的值,那么可以使用常量const。
常量const
常量const表示一个不可变的量,一旦声明就无法做出更改。下面是使用常量的示例:
const x int64 = 10
const (
idKey = "id"
nameKey = "name"
)
const z = 20 * 10
func main() {
const y = "hello"
fmt.Println(x)
fmt.Println(y)
x = x + 1
y = "bye"
fmt.Println(x)
fmt.Println(y)
}
运行上面的代码,会看到如下的报错:

从上面的代码中可以看出,常量就像使用var关键字一样,可以在包级声明,也可以在函数中声明,还可以在一组小括号内声明多个常量。
同时,const关键字也有一些规则约束。首先,需要理解常量是一个字面量命名。编译的时候常量就已经被赋值了,这就意味着可以使用以下的方式给常量赋值:
- 数字字面量
- true和false
- 字符串
- 字符
- 内置函数complex、real、img、len和cap
- 包含预声明(内置)的值和运算符的表达式。
go中没有提供一种方法来指定在运行时计算的值是不可变的。
go中只有常量具有不可变性,变量是不能不可变的。
有类型的常量和无类型的常量
常量可以是有类型的也可以是无类型的。有类型的常量与字面量非常相似:虽然没有自己的类型,但是有默认类型,当不能确定其他类型时使用默认类型。有类型的常量只能赋值给类型相同的变量。
常量有无类型取决于常量的声明,如果要为一个可以用于多个数字类型的数字常量指定名称,请使用无类型的常量,这样具有更大的灵活性。在有些情况下,你要强制常量是某个类型,比如希望使用iota创建一个枚举时,应该使用有类型的常量。
无类型常量声明如下:
const x = 10
由于x此时的类型不确定,所以以下的赋值操作都是合法的:
var y int = x
var z float64 = x
var d byte = x
有类型的常量声明如下:
const typedX int = 10
typedX是一个有类型的常量(int类型),并且只能使用int类型的值对其赋值,如果使用其他类型的值进行赋值,比如使用float64的值进行赋值,会产生编译错误:

未使用的变量
go的初衷之一是使大型团队更容易在程序上进行协作。为此,go拥有一些其他编程语言没有的规则。比如,可以使用特有的go fmt工具对代码进行标准的格式化,go要求每个声明的局部变量必须被读取,声明局部变量而不读取其值就会导致编译时错误。
但是编译器无法对未使用的变量进行全面且详尽的检查,只要变量被读取一次,哪怕仅仅对变量进行了写操作后再没有读取其变量的值,编译器也不会报错。
下面是一段不符合go初衷,但是却可以运行的程序:
func main() {
x := 10
x = 20
fmt.Println(x)
x = 30
}
尽管这段代码正常通过编译,而且go vet也通过检查,但是使用golangci-lint可以检测到错误:

go语言编译器无法检查出包级别的未读变量,所以应该尽量避免创建包级别的未读变量。
未使用的常量
go编译器允许使用const创建未读常量,这是因为在编译时常量的值就被计算,而且之后不会被修改,所以不会带来未知的副作用。这意味着这些未使用的常量易于被消除:即然常量没有使用,它就不会包含在编译后的二进制文件里。
常量与变量的命名
go中的命名规范和实际开发中的常量与变量的命名模式往往有所不同。go要求标识符名称以字母或者下划线开头,名称中可以包含任意数字、下划线或者字母,而且在go中,字母和数字有更广泛的定义,任何unicode字符的字母或者字符都是允许的。
在变量或者常量命名时,虽然下划线在go中是合法的字符,但是尽量不要使用它。因为在go中当变量名包含多个单词时,约定使用驼峰命名法,而不是蛇形命名法(index_counter)。
在函数内部,建议使用简短的变量名。变量的范围越小,使用的名称越短。所以在go中单字母变量名十分常见。例如,变量名k和v(key和value的缩写)在for-range循环中经常使用。
在命名变量时建议使用首字母作为变量名(例如, i代表整数,f表示浮点数,b表示布尔值),自定义类型时这个约定同样适用。
在包代码块中命名变量和常量时,为了名称具有更强的描述性和可读性,可自行取舍变量名是否包含类型名。
go语言外部访问可见性采用:首字母大写为PUBLIC则包外部可以访问,首字母小写为priveate则仅能包内访问。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号