
TCP/IP协议栈在Linux内核中的运行时序分析
TCP/IP协议栈在Linux内核中的运行时序分析
目录
1、Linux内核与网络体系结构
在我们了解整个linux系统的网络体系结构之前,我们需要对整个网络体系调用,初始化和交互的位置,同时也是Linux操作系统中最为关键的一部分代码-------内核,有一个初步的认知。
1.1 Linux内核的结构
首先,从功能上,我们将linux内核划分为五个不同的部分,分别是
(1)进程管理:主要负载CPU的访问控制,对CPU进行调度管理;
(2)内存管理:主要提供对内存资源的访问控制;
(3)文件系统:将硬盘的扇区组织成文件系统,实现文件读写等操作;
(4)设备管理:用于控制所有的外部设备及控制器;
(5)网洛:主要负责管理各种网络设备,并实现各种网络协议栈,最终
实现通过网络连接其它系统的功能;
每个部分分别处理一项明确的功能,又向其它各个部分提供自己所完成的功能,相互协调,共同完成操作系统的任务。
Linux内核架构如下图所示:

图1 Linux内核架构图
1.2 linux网络子系统
内核的基本架构我们已经了解清楚了,接下来我们重点关注到内核中的网络模块,观察在linux内核中,我们是如何实现及运用TCP/IP协议,并完成网络的初始化及各个模块调用调度。
我们将内核中的网络部分抽出,通过对比TCP/IP分层协议,与Linux网络实现体系相对比,深入的了解学习linux内核是怎样具体的实现TCP/IP协议栈的。
Linux网络体系与TCP/IP协议栈如下图所示
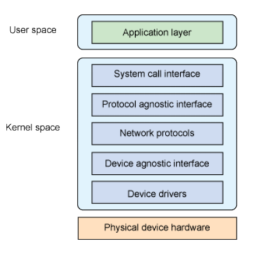

图2 linux网络体系 图3 TCP/IP协议栈和OSI参考模型对应关系
可以看到,在图2中,linux为了抽象与实现相分离,将内核中的网络部分划分为五层:
1、系统调用接口
系统调用接口是用户空间的应用程序正常访问内核的唯一途径,系统调用一般以sys开头。
2、协议无关接口
协议无关接口是由socket来实现的,它提供一组通用函数来支持各种不同的协议。Linux中socket结构是struct sock,这个结构定义了socket所需要的所有状态信息,包括socke所使用的协议以及可以在socket上执行的操作。
3、网络协议
Linux支持多种协议,每一个协议都对应net_family[]数组中的一项,net_family[]的元素为一个结构体指针,指向一个包含注册协议信息的结构体net_proto_family;
4、设备无关接口
设备无关接口net_device实现的,任何设备与上层通信都是通过net_device设备无关接口。它将设备与具有很多功能的不同硬件连接在一起,这一层提供一组通用函数供底层网络设备驱动程序使用,让它们可以对高层协议栈进行操作。
5、设备驱动程序
网络体系结构的最底部是负责管理物理网络设备的设备驱动程序层。
Linux网络子系统通过这五层结构的相互交互,共同完成TCP/IP协议栈的运行。
2、几个重要的数据结构
2.1 sk_buf
sk_buf是Linux网络协议栈最重要的数据结构之一,该数据结构贯穿于整个数据包处理的流程。由于协议采用分层结构,上层向下层传递数据时需要增加包头,下层向上层数据时又需要去掉包头。sk_buff中保存了L2,L3,L4层的头指针,这样在层传递时只需要对数据缓冲区改变头部信息,并调整sk_buff中的指针,而不需要拷贝数据,这样大大减少了内存拷贝的需要。
sk_buf的示意图如下:
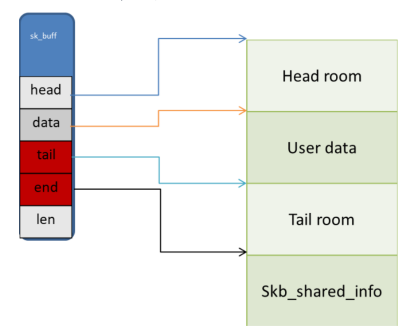
图4 sk_buf简单示意图
各字段含义如下:
head:指向分配给的线性数据内存首地址。
data:指向保存数据内容的首地址。
tail:指向数据的结尾。
end:指向分配的内存块的结尾。
len:数据的长度。
head room: 位于head至data之间的空间,用于存储:protocol header,例如:TCP header, IP header, Ethernet header等。
user data: 位于data至tail之间的空间,用于存储:应用层数据,一般系统调用时会使用到。
tail room: 位于tail至end之间的空间,用于填充用户数据未使用完的空间。
skb_shared_info: 位于end之后,用于存储特殊数据结构skb_shared_info,该结构用于描述分片信息。
sk_buf的常用操作函数如下:
alloc_skb:分配sk_buf。
skb_reserve:为sk_buff设置header空间。
skb_put:添加用户层数据。
skb_push:向header空间添加协议头。
skb_pull:复位data至数据区。
操作sk_buf的简单示意图如下:
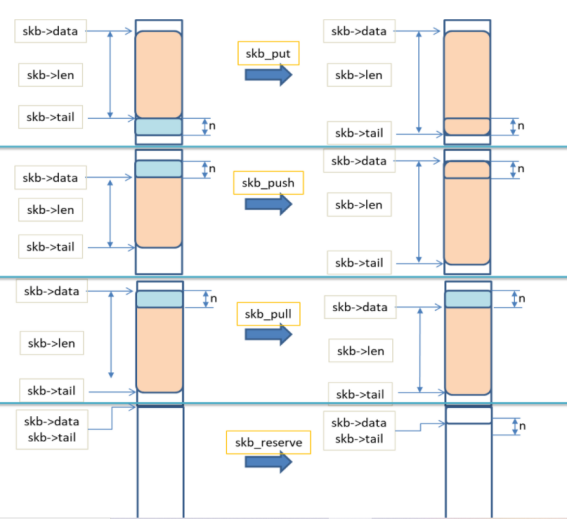
图5 sk_buf操作前后示意图
2.2 net_device
在网络适配器硬件和软件协议栈之间需要一个接口,共同完成操作系统内核中协议栈数据处理与异步收发的功能。在Linux网络体系结构中,这个接口要满足以下要求:
(1)抽象出网络适配器的硬件特性。
(2)为协议栈提供统一的调用接口。
以上两个要求在Linux内核的网络体系结构中分别由两个软件(设备独立接口文件dev.c和网络设备驱动程序)和一个主要的数据结构struct net_device实现。
2.2.1 设备独立接口文件dev.c
dev.c文件中实现了对上层协议的统一调用接口,dev.c文件中的函数实现了以下主要功能。
(1)协议调用与驱动程序函数对应;
dev.c文件中的函数查看数据包由哪个网络设备(由struct sk_buff结构中*dev数据域指明该数据包由哪个网络设备net_device实例接收/发送)传送,根据系统中注册的设备实例,调用网络设备驱动程序函数,实现硬件的收发。
(2)对struct net_device数据结构的数据域统一初始化;
dev.c提供了一些常规函数,来初始化 struct net_device结构中的这样一些数据域:它们的值对所有类型的设备都一样,驱动程序可以调用这些函数来设置其设备实例的默认值,也可以重写由内核初始化的值。
2.2.2 网络驱动程序
每一个网络设备都必须有一个驱动程序,并提供一个初始化函数供内核启动时调用,或在装载网络驱动程序模块时调用。不管网络设备内部有什么不同,有一件事是所有网络设备驱动程序必须首先完成的任务:初始化一个structnet_device数据结构的实例作为网络设备在内核中的实体,并将struct net_device数据结构实例的各数据域初始化为可工作的状态,然后将设备实例注册到内核中,为协议栈提供传送服务。
2.2.3 struct net_device数据结构
struct net_device数据结构从以下两个方面描述了网络设备的硬件特性在内核中的表示。
(1)描述设备属性
struct net_device数据结构实例是网络设备在内核中的表示,它是每个网络设备在内核中的基础数据结构,它包含的信息不仅仅是网络设备的硬件属性(中断、端口地址、驱动程序函数等),还包括网络中与设备有关的上层协议栈的配置信息(如IP地址、子网掩码等)。它跟踪连接到 TCP/IP协议栈上的所有设备的状态信息。
(2)实现设备驱动程序接口
struct net_device数据结构代表了上层的网络协议和硬件之间的一个通用接口,使我们可以将网络协议层的实现从具体的网络硬件部件中抽象出来,独立于硬件设备。为了有效地实现这种抽象,struct net_device中使用了大量函数指针,这样相对于上层的协议栈,它们在做数据收发操作时调用的函数的名字是相同的,但具体的函数实现细节可以根据不同的网络适配器而不同,由设备驱动程序提供,对网络协议栈透明。
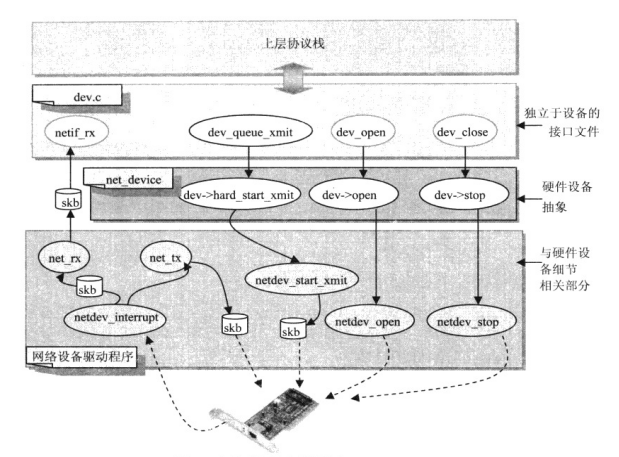
图6 网络设备抽象数据结构
3、内核启动与网络子系统初始化
在系统运行过程中,物理网络设备在Linux内核代码中的实体是struct net _device数据结构的实例。struct net_device数据结构的实例要成为能被内核识别、代表正常工作网络设备的代码描述,与内核代码融为一体,需要经过实例创建、初始化、设备注册等一系列过程。这个过程涉及以下几个方面的问题:
(1)linux内核识别网络设备的步骤
(2)网络设备初始化的一般过程
作为Linux内核组件之一的网络子系统,网络协议栈和网络设备驱动程序都运行在内核的地址空间,它们的初始化是整个内核初始化的一个部分,具有内核启动、初始化过程的一般特点。
3.1 内核初始化
bootloader中的指令是系统上电后执行的第一条指令,完成系统基本的硬件初始化,然后将控制权交给Linux内核,并将命令行参数传给内核,进入secondloader。
内核启动过程从init/main.c文件中的start_kernel函数开始。start_kernel函数的首要任务是建立内核运行的基线,即基础子系统的初始化,包括:初始化系统时钟,初始化中断系统,初始化内存,解析命令行参数,建立文件系统等。
在start_kernel函数结束处调用rest_init函数创建第一个内核进程,执行kernel_init函数,kernel_init函数执行do_basic_setup函数转而调用do_initcalls 函数,按照常规子系统注册初始化函数的优先级顺序调用它们提供的初始化函数,完成整个内核的启动、初始化过程。
具体流程如下:
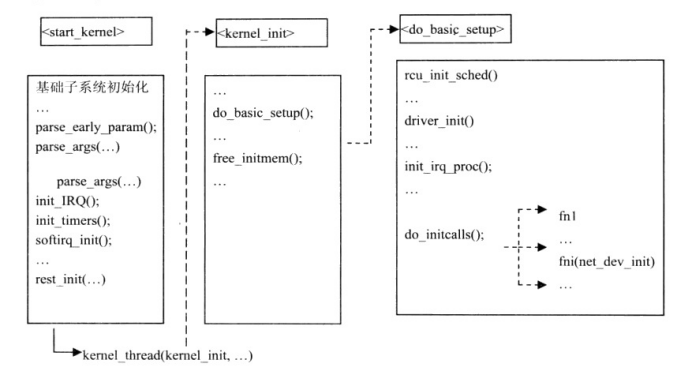
图7 内核初始化过程
函数调用栈如下图所示:
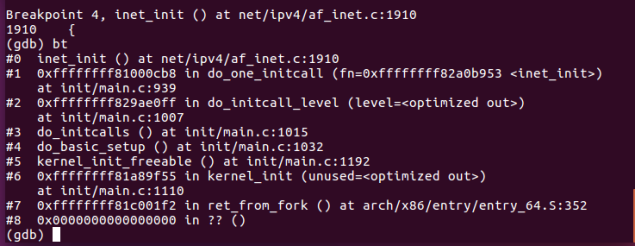
图8 内核初始化调用过程
3.2 struct net_device的初始化
网络设备驱动程序的初始化任务需要完成以下几方面的任务:
(1)创建设备的代码实例,即 struct net_device数据结构类型变量。
主要调用alloc_netdev_mq申请内存空间,为网络设备分配设备名,建立网络设备发送队列,并初始化部分数据域。
(2)初始化网络设备实例,即struct net_device数据结构类型变量的数
据域。网络设备实例的数据域,有的由内核代码(xxx_setup函数)赋值,有的由网络设备驱动程序赋值。
(3)将网络设备实例注册到内核中(调用register_dev)。
具体初始化及注册/注销流程如下:
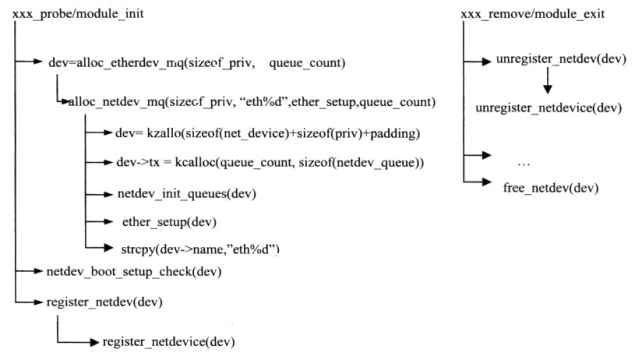
图9 net_device的创建设备实例与初始化
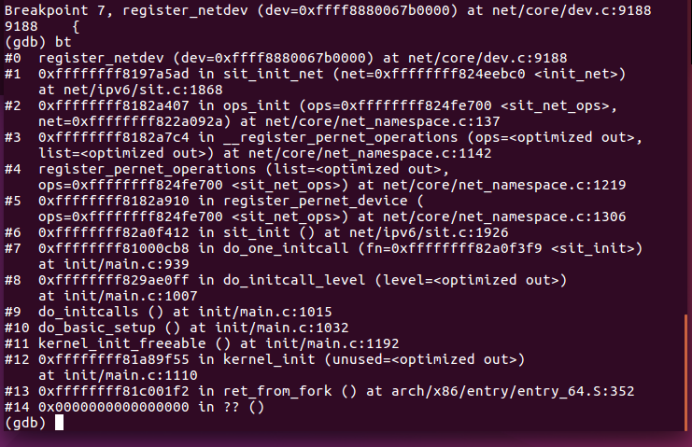
图10 注册net_device的函数调用栈
一旦一个网络设备注册到内核后,该网络设备就可以使用了。但它还不能进行数据包的接收和传送操作,直到用户允许该网络设备后,网络设备才被激活,随后才能开始数据收发操作。
激活网络设备由dev_open函数完成,而禁止网络设备则由dev_close完成。
网络设备的struct net_device 数据结构实例在创建后会插入到一个全局链表dev_base_head和两个哈希链表中,这些数据结构使内核查找设备更容易。
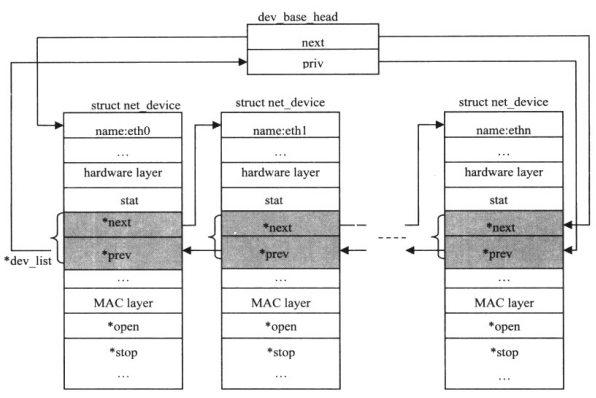
图11 管理全局实例的dev_base_head
3.3 事件通知链
Linux网络设备自身并不知道有哪些协议实例在使用它的服务,存储了对它的引用。为了满足让协议栈实例获取网络设备状态信息的需求,Linux内核中实现了事件通知链(notification chain)机制。
事件通知链是一个事件处理函数的列表,每个通知链都与某个或某些事件相关,当特定的事件发生时,列在通知链中的函数就依次被执行,通知事件处理函数所属的子系统某个事件发生了,子系统接到通知后做相应的处理。每个通知链中都存在被通知方和通知方。
被通知方:内核中的某个子系统,提供事件处理的回调函数。
通知方:内核中发生事件的子系统,通知链的创建者,事件发生后通知方依次调用事件通知链上的事件处理函数,通知其他子系统某个事件发生,对方应做出相应处理。
通知方是事件通知链创建方,它定义事件通知链,需要获取通知方事件消息的其他子系统编写自己的事件处理函数,并向通知方的事件通知链中注册函数。
事件通知链中是一个一个的struct notifier_block 数据结构类型的成员列表,struct notifier_block 数据结构描述了通知链的成员由哪些属性组成,这样当事件通知链中的成员接收到事件通知后,才能做出正确反应。struct notifier_block包括三个数据成员,分别是:notifier_call函数指针,指向事件处理函数,struct noyifier_block *next指针,将事件通知链中成员连接成链表的指针,和事件处理函数的优先级priority。
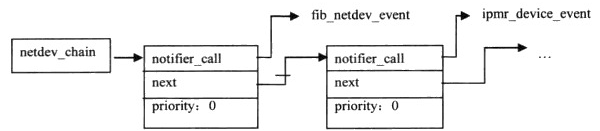
图12 网络子系统的事件通知链netdev_chain
网络子系统共创建了3个事件的通知链:inetaddr_chain、inet6addr_chain和netdev_chain。其中 netdev_chain为网络设备状态发生变化时的事件通知链,该事件通知链定义在net/core/dev.c文件中。
向网络子系统事件通知链注册的步骤如下:
1、声明struct notifier_block数据结构实例。
2、编写事件处理回调函数。
3、将事件处理回调函数的地址赋给struct notifier_block 数据结构实例的*notifier_call 成员。
4、调用特定事件通知链的注册函数,将struct notifier_block 数据结构实例注册到通知链中。
拥有事件通知链的事件通知方在事件发生时,调用notifier_call_chain函数(定义在kernel/notifier.c文件中)通知其他子系统有事件发生。
notifier_call_chain函数会按照事件通知链上各成员的优先级顺序调用注册在通知链中的所有回调函数。
4、网络接口收发数据
网络接口最主要的任务是数据收发,数据发送相对于数据接收要简单一些,我们先介绍数据包是如何由内核向网络发送的。
4.1 发送网络数据
发送数据是将数据包通过网络连接线路送出。无论什么时候,内核准备好要发送的数据包后(数据包存放在Socket Buffer 中),都会调用驱动程序的ndo_start_xmit函数把数据包放到网络设备的硬件数据缓冲区,并启动硬件发送。ndo_start_xmit是一个函数指针,指向驱动程序实现的数据发送函数。传给ndo_start_xmit的 Socket Buffer 包含了实际要传输的物理数据、协议栈的协议头;接口无须关心数据包的具体内容,也无须修改数据包的值。struct sk_buff 中skb->data给出了要发送数据的起始地址。
如果ndo_start_xmit执行成功则返回0,这时负责发送该数据的驱动程序应尽最大努力保证数据包的发送成功,最后释放存放发送完成数据包的Socket Buffer。如果ndo_start_xmit返回值非0,则说明这次发送不成功,内核过一段时间后会重发。这时驱动程序应停止发送队列,直到发送失败错误恢复。
当CPU需要发送数据给网络设备时,CPU将数据写到IO端口,并向网络设备的命令寄存器写发送控制命令;相反,当网络设备需要发送数据给CPU时,它产生一个中断,CPU执行中断处理程序来为网络设备服务。
4.2 接收网络数据
与发送数据包相反,接收数据包是内核事先无法预见的事件。网络设备接收数据包的过程与内核的操作是并行的,网络设备驱动程序把数据包推送给内核,有两种方式通知内核数据到达。
轮询,即内核周期性地查询网络设备。这种方式的问题是内核需要多长时间询问网络设备一次。如果间隔太短,会无谓地浪费CPU时间;如果间隔太长,数据发送的延迟会增加,可能会丢失数据。
中断,即内核执行中断处理程序接收数据包,将其存放在CPU的接收队列中,其后的处理可以等CPU空闲时再完成。net_rx是在接收中断中调用的处理接收数据的函数。
net_rx 的任务是申请一个Socket Buffer,将硬件数据复制到Socket Buffer中,再将接收设备注册到Socket Buffer的dev数据域,识别数据包的协议类型。接着由netif_rx()函数将接收到的数据包放入CPU的接收队列,更新接收统计信息,这时接收处理程序继续接收下一个数据包,或者结束返回。
5、数据链路层
在TCP/IP协议栈中,数据链路层的关键任务是:将由网络设备驱动程序从设备硬件缓冲区复制到内核地址空间的网络数据帧挂到CPU的输入队列,并通知上层协议有网络数据帧到达,随后上层协议就可以从CPU的输入队列中获取网络数据帧并处理。
另外,上层协议实例要向外发送的数据帧会由数据链路层放到设备输出队列,再由设备驱动程序的硬件发送函数 hard_start_xmit将设备输出队列中的数据帧复制到设备硬件缓冲区,实现对外发送。
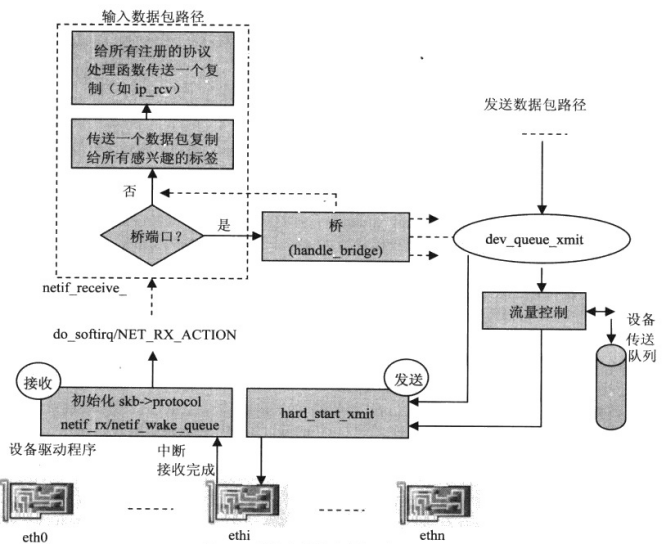
图13 数据包接收/发送流程
5.1 数据帧的接收处理
网络设备收到的数据帧由网络设备驱动程序推送到内核地址空间后,在数据链路层中,Linux内核网络子系统实现了两种机制,将数据帧放入CPU的输入队列中。
1、netif_rx
这是目前大多数网络设备驱动程序将数据帧复制到Socket Buffer 后,调用的数据链路层方法。它通知内核接收到了网络数据帧;标记网络接收软件中断,执行接收数据帧的后续处理。这种机制每接收一个数据帧会产生一个接收中断。
2、NAPI
这是内核实现的新接口,在一次中断中可以接收多个网络数据帧,减少了CPU响应中断请求进行中断服务程序与现行程序之间切换所花费的时间。
5.1.1 NAPI的实现
NAPI的核心概念是使用中断与轮询相结合的方式来代替纯中断模式:当网络设备从网络上收到数据帧后,向CPU 发出中断请求,内核执行设备驱动程序的中断服务程序接收数据帧;在内核处理完前面收到的数据帧前,如果设备又收到新的数据帧,这时设备不需产生新的中断(设备中断为关闭状态),内核继续读入设备输入缓冲区中的数据帧(通过调用驱动程序的poll函数来完成),直到设备输入缓冲区为空,再重新打开设备中断。这样设备驱动程序同时具有了中断与轮询两种工作模式的优点。
异步事件通知:当有数据帧到达时用中断通知内核,内核无须不断查询设备的状态。
如果设备队列中仍有数据,无须浪费时间处理中断通知、程序切换等。
使用NAPI工作模式需要对网络驱动程序做以下的升级:
(1)新增新的数据结构struct napi_struct;
该实例描述了与NAPI相关的属性与操作。
(2)实现poll 函数;
设备驱动程序要实现自己的poll 函数,来轮询自己的设备,将网络输入数据帧复制到内核地址空间的Socket Buffer,再放入CPU 输入队列。
(3)对接收中断处理程序进行修改;
执行中断处理程序后,不是调用netif_rx函数将Socket Buffer放入CPU 输入队列,而是调用netif_rx_schedule函数。
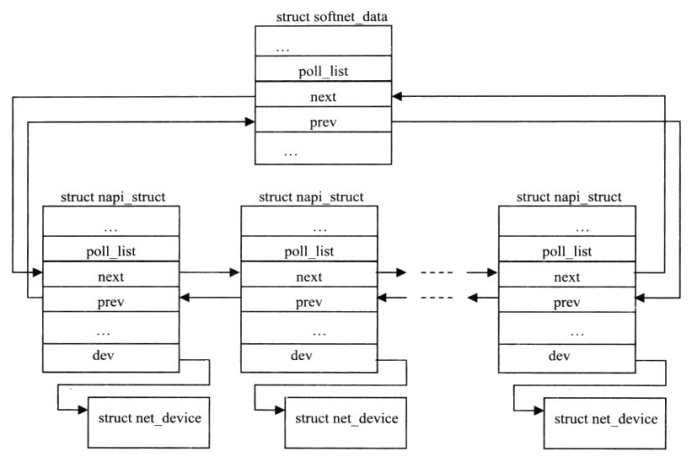
图14 softnet_data、napi_struct、net_device数据结构之间的关系
其中struct softnet_data是管理CPU队列的数据结构。
NAPI接收机制的工作流程如下:
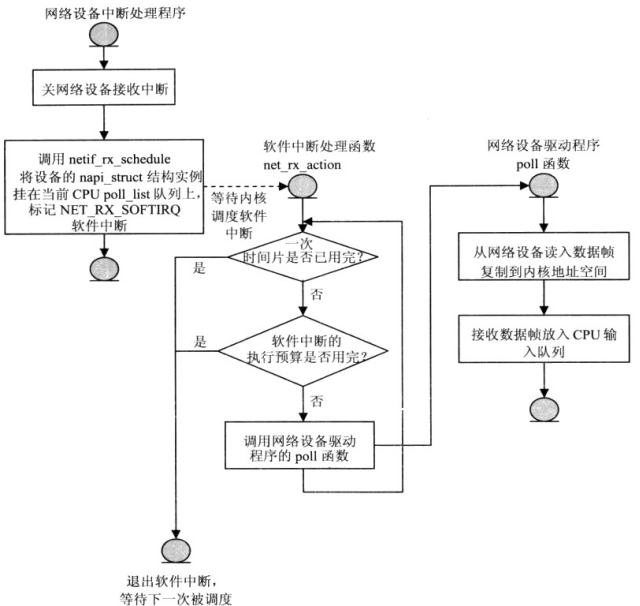
图15 NAPI接收机制的工作流程
5.1.2 netif_rx的实现
netif_rx函数由常规网络设备驱动程序在接收中断中调用,它的任务就是把输入数据帧放入CPU的输入队列中,随后标记软件中断来处理后续上传数据帧给TCP/IP协议栈功能。
netif_rx的函数调用流程如下:
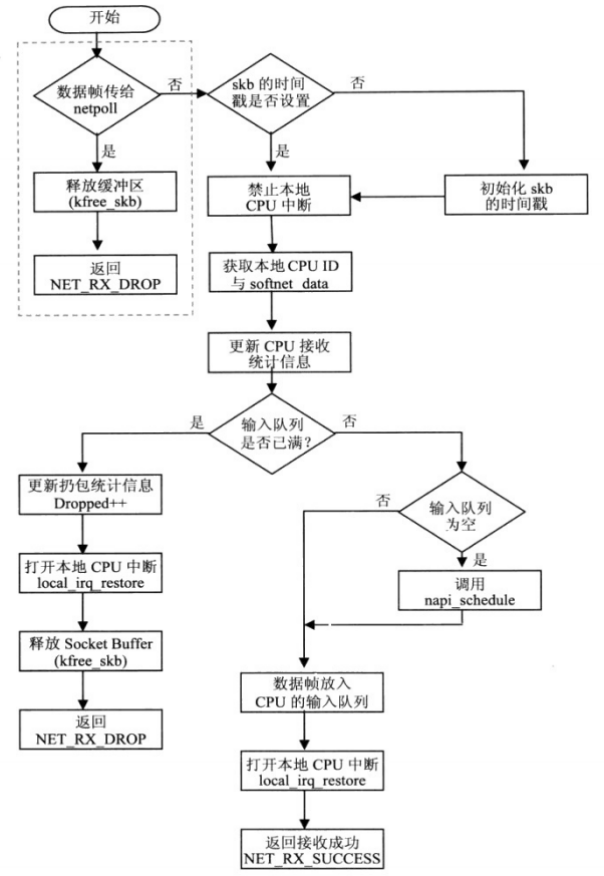
图16 netif_rx函数调用流程
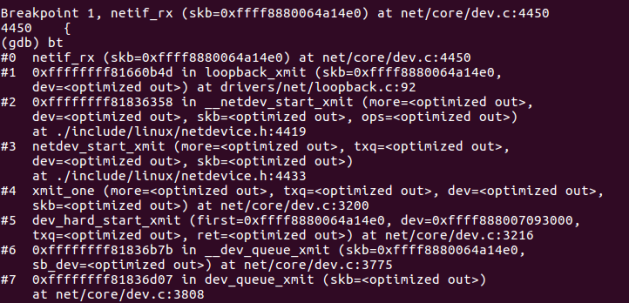
图17 netif_rx调用函数栈
napi_schedule函数是_napi_schedule函数的包装函数,_napi_schedule完成的功能就是将struct napi_struct 数据结构实例放入CPU的poll_list队列,挂起网络接收软件中断NET_RX_SOFTIRQ。这样推送数据帧给上层协议实例的处理函数,就会在内核调度的网络接收软件中断处理程序的net_rx _action函数中被执行。
网络接收软件中断(NET_RX_SOFTIRQ)的处理程序net_rx_action是接收网络数据中断的后半段。引起net_rx _action函数执行的是网络设备产生的接收数据硬件中断,它通知内核收到了网络数据帧,触发内核调度接收中断的后半段。net_rx_action函数的任务就是将设备收到的数据帧上传给TCP/IP 协议栈的上层协议处理。
5.2 数据帧的发送处理
在数据帧的处理过程中,发送和接收的许多步骤都有对称性。大部分数据结构、处理函数与前面讨论的接收过程的数据结构和处理函数都是成对出现,只是其处理过程相反。例如接收软件中断是 NET_RX_SOFTIRQ,相对应的发送数据有软件中断NET_TX_SOFTIRQ;它们的软件中断处理程序分别是net_rx_action和 net_tx_action。
相较于接收过程,可预期的发送过程更为简单,主要流程如下:
(1)启动设备发送数据
Linux设置了一系列的API来操纵检查网络发送队列的状态,常用如下:netif_start_queue/netif_stop_queue(启动/禁止网络发送队列),netif_queue_stopped(返回网络队列当前发送状态),netif_wake_queue(唤醒网络发送队列,重启网络发送过程)。
(2)调度设备发送数据帧
内核实现了dev_queue_xmit函数,该函数将上层协议发送来的数据帧放到网络设备的发送队列(针对有发送队列的网络设备),随后流量控制系统按照内核配置的队列管理策略,将网络设备发送队列中的数据帧依次发送出去。发送时,从网络设备的输出队列上获取一个数据帧,将数据帧发送给设备驱动程序的dev->netdev_ops->ndo_start_xmit方法。
如果获取保护输出队列并发访问的锁失败,内核实现了函数_netif_schedule来重新调度网络设备发送数据帧,它将网络设备放到CPU的发送队列softnet_data->output_queue 上,随后标识网络发送软件中断NET_TX_SOFTIRQ,当发送软件中断被内核调度执行时,CPU输出队列output queue 中的设备会重新被调度来发送数据帧。(其作用就类似netif_rx_schedule函数处理输入路径的功能)。

图18 dev_queue_xmit函数调用栈
6、网络层
网络层协议是TCP/IP协议栈与网络设备驱动程序所管理的硬件发送的连接处,网络数据包经过网络层的处理后,已包含了所有向外发送需要的信息,如源地址、目标地址、协议头等,可交由网络设备发送。另一方面,接收到的网络数据包在网络层确定其进一步发送的路径,是在本机向上传递,还是继续向前发送。数据链路层的驱动程序只关心将上层交给的数据包向外发送,将接到的数据包向上投递,而网络层协议的关键任务就是决定数据包的去向。
在linux中相应的协议处理函数都会分两个阶段实现。
第一阶段函数名通常为do_something (如 ip_rcv),do_something 函数只对数据包做必要的合法性检查,或为数据包预留需要的内存空间。
第二阶段函数名通常为do_something_finish(如 ip_rcv_finish),是实际完成接收/发这操作的函数。
6.1 输入数据包在IP层的处理
Linux内核定义了ptype_base链表来实现数据链路层与网络层之间接收数据包的接口,网络层各协议将自己的接收数据包处理函数注册到ptype_base链表中,数据链路层按接收数据包的skb->protocol值在ptype_base链表中找到匹配的协议实例,将数据包传给注册的处理函数。IP协议在PF_INET协议族初始化函数inet_init中调用dev_add _pack注册的处理函数是ip_rcv。 ip_rcv函数是网络层IP协议处理输入数据包的入口函数,IP协议通过ip_rcv、ip_rcv_finish等函数,完成IP层对输入数据包的处理。
1、ip_rcv函数
Ip_rcv函数主要都是在对skb 中的数据包做各种合法性检查:协议头长度、协议版本、数据包长度、校验和等。传给ip_rcv函数处理的数据包存放在skb中,ip_rcv函数需要从 skb管理结构中获取各种信息,作为处理的依据,并将数据链路层与网络层的处理关联在一起。
主要步骤如下:
(1)检查当前skb各数据域的状态
(2)skb->pkt_type数据域的值,确定上交还是丢弃
(3)数据包共享的处理
(4)IP协议头信息的正确性检查
(5)数据包的正确性检查
(6)清理工作,获得一个干净的数据包
(7)函数结束,回调ip_rcv_finish完成对数据包的处理
2、ip_rcv_finish函数
Ip_rcv_finish函数主要功能如下:
确定数据包是前送还是在本机协议栈中上传,如果是前送,需要确定输出网络设备和下一个接收站点的地址。
解析和处理部分IP选项。
处理流程如下:
(1)获取路由信息
(2)更新流量控制系统使用的统计信息
(3)处理路由选项
函数结束处理,调用dst_input确定对数据包的处理函数是哪一个,实际的调用存放在 skb->dst->input数据域,根据数据包的目标地址,skb->dst->input设置成ip_local_deliver或ip_forward。
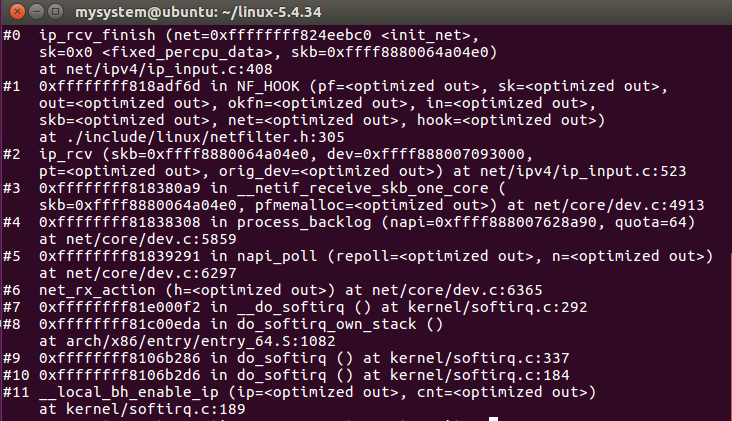
图19 ip_rcv_finish函数调用栈
6.2 发送数据包在IP层的处理
在 ip_rcv_finish 函数结束处,如果数据包的目标地址不是本机,内核需要将数据包前送给适当的主机;反之,如果数据包的目标地址是本地主机,内核需要将数据包上传给TCP/IP 协议栈网络层以上的协议实例。处理函数的选择由dst_input完成,它根据路由将处理函数设置为 ip_forward或ip_local_deliver。
6.2.1 数据包的前送(发送至下一主机)
与数据包接收处理过程类似,数据包前送也分为两个阶段完成:ip_forward和 ip_forward_finish。第二个函数在第一个函数执行结束时调用。
函数处理流程如下:
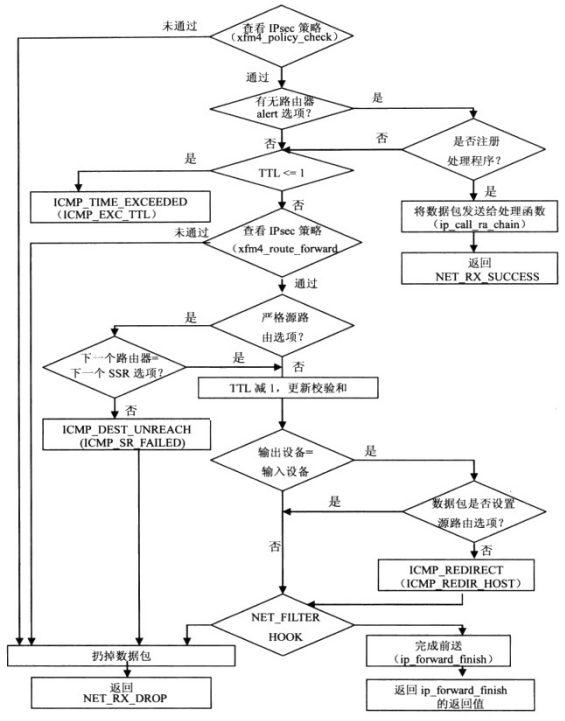
图20 ip_forward 函数处理流程
当ip_forward_finish处理完前送数据包的所有IP选项后,交由dst_output函数送达目的主机。
dst_output 调用虚函数output,虚函数output根据数据包的目标地址类型来初始化。目标地址为某一主机地址时,output初始化成ip_output,如果目标地址是组发送地址,则它初始化成ip_mc_output,数据包的发送分3个阶段处理,分别由ip_output,ip_finish_output,ip_finish_output2三个函数完成,对应如下:
ip_output函数初始化数据包的输出网络设备和传输协议,最后由网络过滤子系统对数据包进行过滤,并调用ip_finish_output函数完成实际的发送操作。
ip_finish_output 的主要任务是根据网络配置确定是否需要对数据包进行重路由,是否需要对数据包进行分割,最后调用ip_finish_output2与相邻子系统接口,将数据包目标地址中的IP地址转换成目标主机的MAC地址。
ip_finish_output2函数是与相邻子系统接口的函数,该函数的主要任务是,在数据包中为数据链路层协议插入其协议头,或为数据链路层协议头预留分配空间,然后将数据包交给相邻子系统发送函数dst->neighbour->output处理。
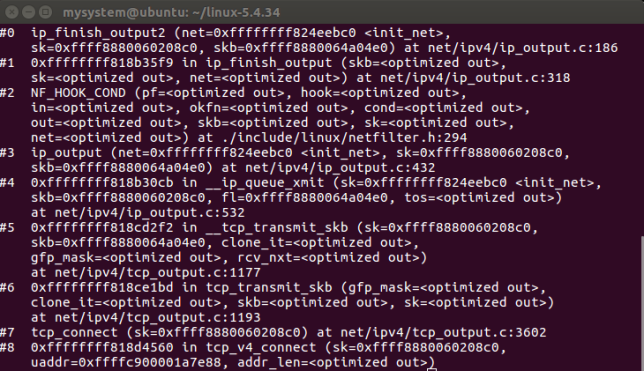
图21 ip层发送过程函数调用栈
6.2.2 数据包上传本地主机
当数据包的目标地址为地本机时,在 ip_rcv_finish 函数中会将skb->dst->input初始化为ip_local_deliver。本地发送功能也分两个阶段完成: ip_local_deliver和 ip_local_deliver_finish。
ip_local_deliver函数的主要任务就是重组数据包,重组数据包的功能通过调用ip_defrag函数完成。ip_defrag完成数据包重组后返回指向完整数据包的指针,如果这时还没有收到数据包的所有分片,数据包还不完整,则它返回NULL。
数据包重组成功,调用网络过滤子系统的回调函数来查看数据包的配置,并执行ip_local_deliver_finish完成数据包上传功能。
ip_local_ deliver_finish函数完成后,数据包就离开网络层上传至TCP/IP协议栈的传输层。

图22 ip层本地接收函数调用栈
ip层时序图具体如下:
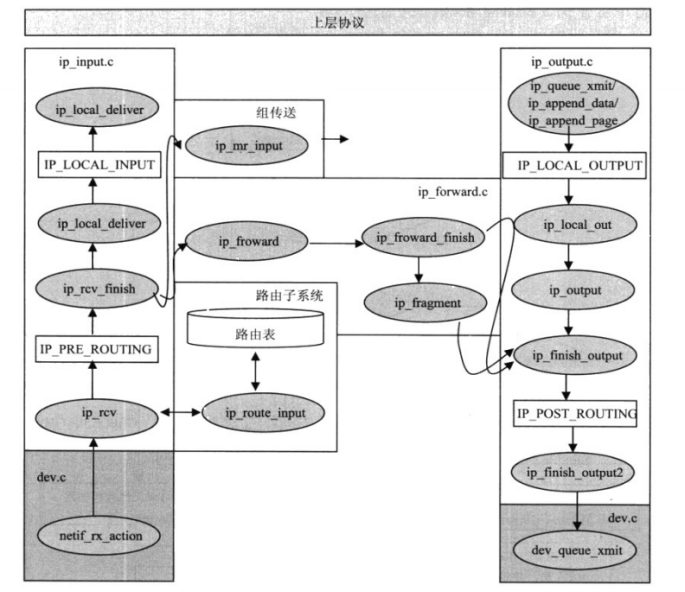
图23 网络层实现数据包接收/发送的API调用关系总图
7、传输层
传输层的主要任务是保证数据能准确传送到目的地。在TCP/IP 协议栈中这个功能由传输控制协议(TCP,Transmission Control Protocol)完成。同时传输层紧接在应用层下,它也是用户地址空间的数据进入内核地址空间的接口。TCP/IP 协议栈在传输层提供两个最常用的协议:TCP和UDP,这里我们研究TCP协议的实现。

图24 套接字,TCP,IP层之间的接口函数关系
7.1 传输层的接收过程的实现
为了将输入数据包传送给传输层正确的协议处理函数,输入数据包使用的传输层协议在IP层处理时已设定。在传输层,各协议输入处理函数在协议初始化时注册到内核TCP/IP协议栈接口,IP层通过调用ip_local_deliver函数在IP数据包协议头 iphdr->protocol数据域中设定的值,在传输层与IP层之间管理协议处理接口的哈希链表inet_protocol中查询,找到正确的传输层协议处理函数块,并上传数据包。对于TCP协议,它在inet _protocol结构中初始化的输入数据包处理函数是tcp_v4_rcv。
1、tcp_v4_rcv函数
在 tcp_v4_rcv函数的起始部分同样也需要对接收到的skb数据包做一系列的正确性检查。tcp_v4_rcv函数主要功能包括以下两个方面:
(1)数据包合法性检查。
(2)确定数据包是“快速路径”处理,还是“慢速路径”处理。
Linux TCP/IP协议栈中,在TCP层有两条路径处理输入数据包:“Fast Path”和“SlowPath”。“Fast Path”是内核优化TCP处理输入数据包的方式。当TCP协议实例收到一个数据包后,它首先通过协议头来预定向数据包的去处:“Fast Path”或“Slow Path”。
进入快速路径的数据段会放入prequeue队列中,这时用户进程被唤醒,在 prequeue队列中的数据段就由用户层的进程来处理,这个过程省略很多“Slow Path”处理中的步骤,从而加大了数据吞吐量。而慢路径放入backlog queue,需要调用tcp_v4_do_rcv进行处理。

图25 tvp_v4_rcv函数处理流程
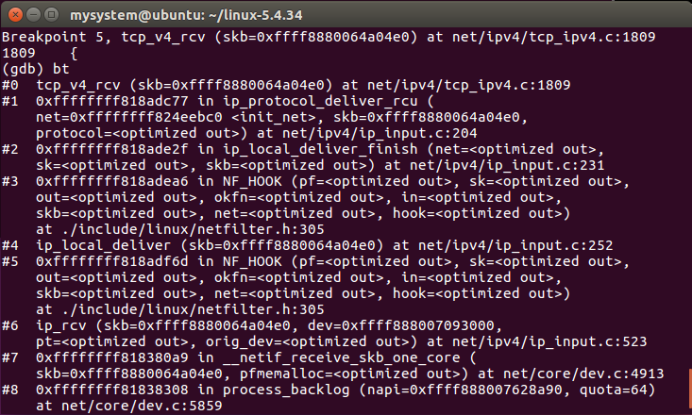
图26 tcp_v4_rcv函数调用栈
7.2 传输层发送数据流程
TCP协议实现的传送功能是指将从应用层通过打开的套接字写入的数据移入内核,通过TCP/IP协议栈,最终通过网络设备发送到远端接收主机。一旦应用层打开一个SOCK_STREAM类型的套接字,并发出写数据请求,就会调用TCP协议实现的传送例程tcp_sendmsg来处理所有从打开的套接字上传来的写数据请求。
tcp_sendmsg 函数是TCP协议初始化时在协议函数块中注册发送函数。完成的功能为:
(1)将数据复制到Socket Buffer 中。
(2)把Socket Buffer放入发送队列。
(3)设置TCP控制块结构,用于构造TCP协议发送方的头信息。
tcp_sendmsg将数据从用户地址空间复制到内核空间,最终所有这些从用户地址空传来的数据包,都是通过tcp_write_xmit函数调用 tcp_transmit_skb函数向IP层传送的。
tcp_transmit_skb函数发送过程主要如下:
(1)tcp_transmit_skb函数初始化
(2)确定TCP数据段协议头包含的内容
(3)发送数据,调用实际传送函数将该数据段传送给IP层
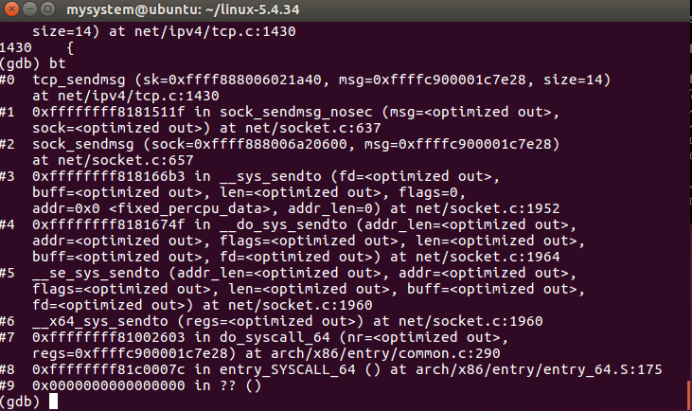
图27 tcp_sendmsg函数调用栈
传输层TCP发送接收时序图:
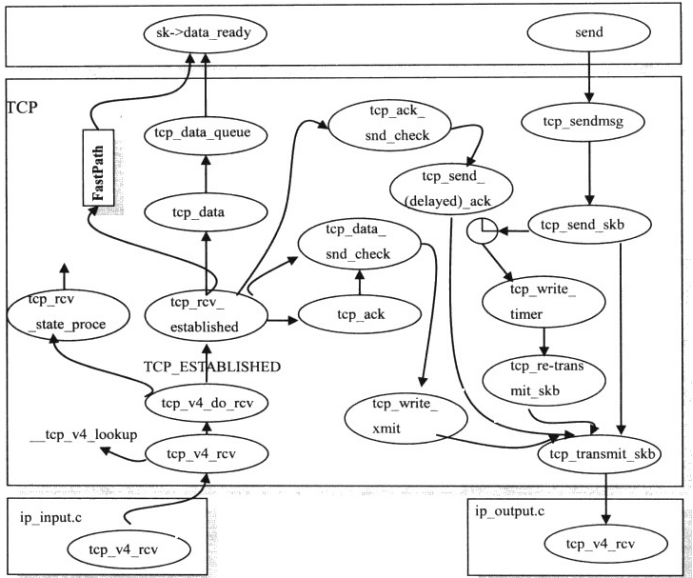
图28 传输层接收/发送路径
8、套接字接口层
套接字接口最初是BSD操作系统的一部分,在应用层与TCP/IP协议栈之间接供了一套标准的独立于协议的接口。从TCP/IP 协议栈的角度来看,传输层以上的都是应用程序的一部分。Linux与传统的UNIX类似,TCP/IP协议栈驻留在内核中,与内核的其他组件共享内存。传输层以上执行的网络功能都是在用户地址空间完成的。Linux使用内核套接字概念与用户空间套接字通信,这样使实现和操作更简单。Linux 提供了一套API和套接字数据结构,这些服务向下与内核接口,向上与用户空间接口,应用程序使用这一套API访问内核中的网络功能。
8.1 套接字API系统调用的实现
系统调用完成将用户程序的函数调用转换成对内核功能服务调用,并获取内核功能服务的返回值,然后传递给用户程序。
Linux中实现系统调用主要分为下列三步:
(1)内核实现了一系列的系统调用.所有系统调用函数以sys_为前缀名(如sys_bind),对应用户程序的函数调用。内核为每个系统调用分配一个索引号,索引号与系统调用函数的对应关系保存在系统调用表中。
(2)用户程序调用参数在用户地址空间,内核功能函数要访问这些参数,需将其从用户地址空间映射到内核地址空间。
(3)返回系统调用结果,成功返回0,失败返回错误代码。
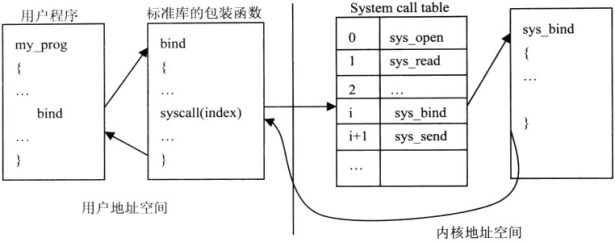
图29 系统调用示意图
8.1.1 socketcall系统调用
在Linux内核中只有一个系统调用sys_socketcall 完成用户程序对所有套接字操作的调用,这需要以不同的参数来决定如何处理用户程序的调用。传给sys_socketcall函数的第-一个参数是一个数字常数,sys_socketcall 以该常数为索引选择需要调用的实际函数。
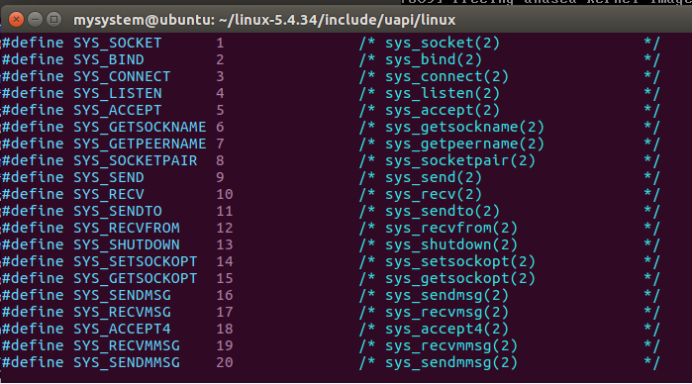
图30 linux中socketcall系统调用
8.1.2 sys_socketcall 套接字分路器
sys_socketcall函数接收所有来自应用程序对套接字的20种操作的系统调用,sys_socketcall函数的功能并不复杂,它犹如一个分路器,将来自应用程序的系统调用分支到其他函数上,每个函数实现个小的系统调用功能。
应用程序调用应用层套接字的API函数时,会产生一个内核系统调用中断,该中断转而调用sys_socketcall 函数。
sys_socketcall 函数主要完成两个功能:
(1)将从用户地址空间传来的每一个地址映射到内核地址空间。该功能通过调用copy_from_user函数完成。
(2)将应用层套接字的API函数映射到内核实现函数上。
sys_socketcall函数首先检查函数调用索引号是否正确,其后调用copy_from_user函数将用户地址空间参数复制到内核地址空间。最后switch词句根据系统调用函数索引号,实现套接字分路器的功能,将来自应用程序的系统调用转到内核实现函数sys_xxx 上。
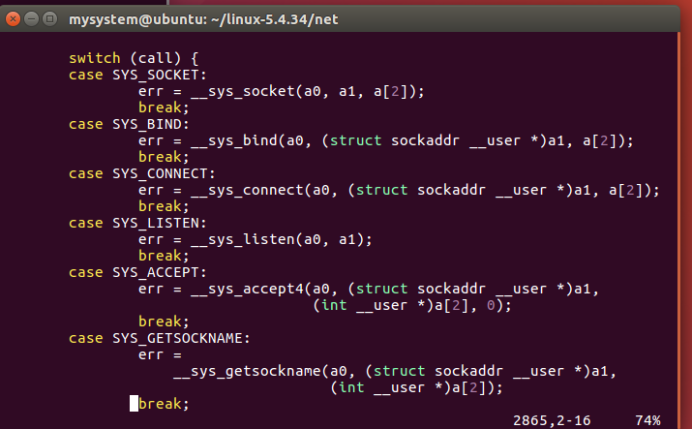
图31 sys_socketcall函数分路逻辑
8.1.3 sys_sendto,sys_recvfrom,sys_socket调用流程
1、创建套接字sys_socket
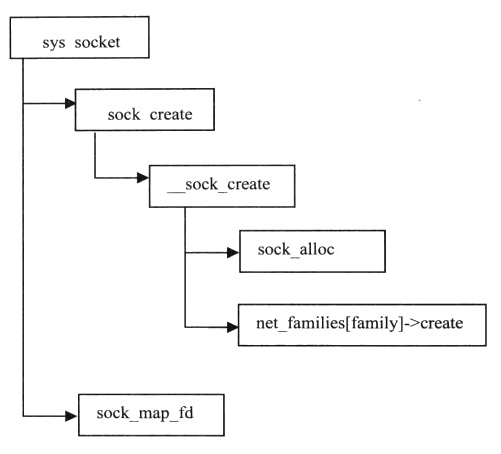
图32 创建套接字函数调用流程
2、发送sys_sendto
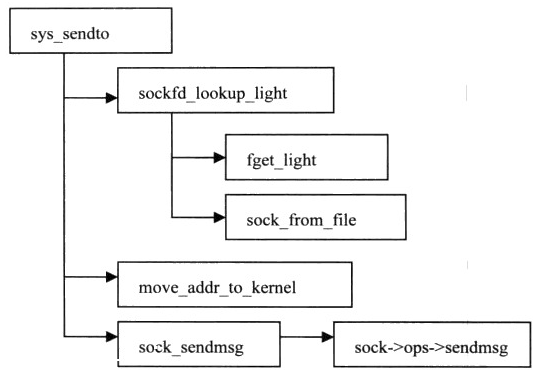
图33 放送系统函数调用流程
2、接收sys_recvfrom
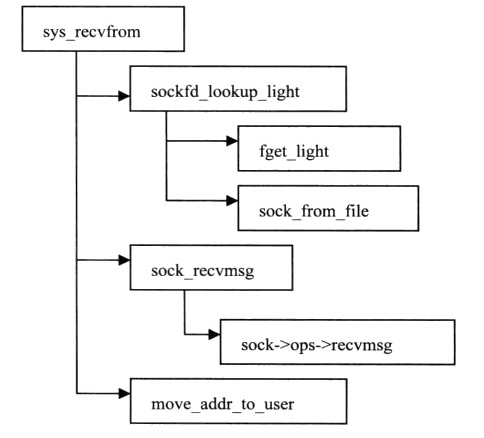
图34 接收系统调用流程
9、课程小结
本文从Linux操作系统实现入手,深入的分析了Linux操作系统对于TCP/IP栈的实现原理与具体过程,了解了Linux网络子系统的具体构成及流程,通过这次调研,使我对TCP/IP协议的原理及具体实现有了极其深入的理解,使我受益匪浅。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号