



(转)Linux之split命令详解
Linux之split命令详解
原文:http://m.jb51.net/article/73632.htm
https://blog.csdn.net/qq_24256877/article/details/106406734
命令功能:切割文件,将文件以行为单位或以字节为单位进行切割
命令语法:
split [–help][–version]
split [-<行数>][-l <行数>] [要切割的文件][输出文件名]
,以行数为单位
split [-b <字节>][-C <字节>] [要切割的文件][输出文件名],以字节为单位
输出文件名是指切割后的文件会以此为前缀。
1. 以行为单位切割文件
首先创建一个有5行的文件hello,
#cat hello
Hello, World1
Hello, World2
Hello, World3
Hello, World4
Hello, World5
使用命令:
#split -2 hello split1_
split命令会将文件以两行为单位进行切割,每两行组成一个新文件,5行就有三个文件,名称会分别为:
split1_aa , split1_ab , split_ac
2. 以字节为单位的切割
还是文件hello,使用命令ls -l hello 可以看到文件的大小为65字节,以10字节切割文件,会有7个文件
先使用-b命令,如下:
#split -b 10 hello split2_
文件切出来有7个,
split2_aa , split2_ab , split2_ac , split2_ad , split2_ae , split2_af , split2_ag
下面使用-C参数,如下:
#split -C 10 hello split3_
切出了10个文件,用ls -l 命令输出如下:
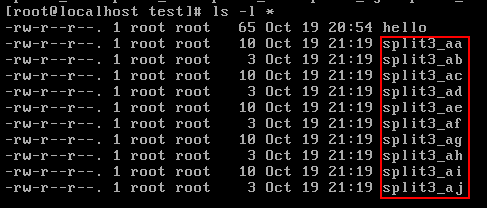

-b 指定大小
split -b 500k /etc/inittab new*
虽然同样是以字节为单位切割文件,但-C参数会尽量保持每行的完整性,也就是说,一行有13个字节,那么会切割成两个文件,一个10字节,一个3字节,而-b参数会将8字节累计到下一行凑足十字节再切,所以-b参数只有7个文件,而-C参数有10个文件。
Split --help
[root@dw-hsd02-pe connect]# split --help
Usage: split [OPTION]... [INPUT [PREFIX]]
Output fixed-size pieces of INPUT to PREFIXaa, PREFIXab, ...; default
size is 1000 lines, and default PREFIX is 'x'. With no INPUT, or when INPUT
is -, read standard input.
Mandatory arguments to long options are mandatory for short options too.
-a, --suffix-length=N 生成长度为N的后缀(默认值2)
--additional-suffix=SUFFIX 文件名后面附加一个后缀
-b, --bytes=SIZE 按大小切割文件 -b 10k/10m/..
-C, --line-bytes=SIZE 按字节切割文件类-b
-d, --numeric-suffixes[=FROM] 使用数字后缀替代字母
FROM changes the start value (default 0)
-e, --elide-empty-files 不生成带有'-n'的空输出文件
--filter=COMMAND write to shell COMMAND; file name is $FILE
-l, --lines=NUMBER 按行切割文件
-n, --number=CHUNKS 按生成文件个数切割
-u, --unbuffered immediately copy input to output with '-n r/...'
--verbose 打印日志
--help 打印帮助文档
--version 输出版本信息并退出
按文件大小切分,并指定后缀
[root@]# split -b 1k biz_date.txt -d -a 1 date_
date_0
date_1
按字节切分
[root@ tmp]# split -C 200 biz_date.txt -d -a 1 date_
date_0
date_1
date_2
date_3
date_4
date_5
date_6
(按大小切分有或许会把一行文件拆开,放到另一文件导致数据不完整,需要手动处理数据)
批量为文件添加后缀
[root@ tmp]# ls | grep date_|xargs -n1 -i{} mv {} {}.txt
date_0.txt
date_1.txt
date_2.txt
date_3.txt
date_4.txt
date_5.txt
date_6.txt
按行数切割,并重命名文件
[root@ tmp]# split -l 50 biz_date.txt -d -a 1 date_
date_0
date_1
date_2
[root@ tmp]# ls |grep date_|xargs -n1 -i{} mv {} {}.txt
date_0.txt
date_1.txt
date_2.txt
按输出文件个数切割
[root@ tmp]# split -n 5 biz_date.txt -d -a 2 biz_
biz_00
biz_01
biz_02
biz_03
biz_04
————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号