dump 日志收集与分析(jmap 和 jstack 工具)讲解与实战操作
一、概述
dump 通常指的是从一个系统或应用程序中生成一份详细的信息快照,以便进行调试、分析或故障排除。在不同的上下文中,dump 可能指的是不同类型的信息。
以下是一些常见的 "dump" 类型以及它们的介绍:
-
内存转储(
Memory Dump):内存转储是将程序的内存内容以二进制形式保存到文件中的过程。这对于在程序崩溃或发生问题时进行调试和分析非常有用。常见的工具有 gcore(用于 GDB)、jmap(用于 Java 应用程序)等。 -
核心转储(Core Dump):核心转储是在程序崩溃时生成的一个包含程序当前内存状态的文件。它通常包括内存、寄存器和堆栈信息。开发人员可以使用调试器(如 GDB)分析核心转储以了解程序崩溃的原因。
-
数据库转储:数据库转储是指将数据库的内容导出为一组 SQL 语句或其他格式,以便备份、还原或进行分析。例如,mysqldump 是 MySQL 数据库的常见转储工具。
-
日志转储:在软件系统中,"dump" 有时也用来描述将日志文件中的信息输出到另一个文件中,以便进行详细的分析。这对于了解系统的行为、故障排除和性能调整非常有用。
-
堆栈转储(
Stack Dump):堆栈转储是在程序执行期间生成的,记录了当前执行线程的调用堆栈信息。它对于分析程序的性能瓶颈和查找死锁等问题很有帮助。 -
网络转储(Network Dump):在网络领域,"dump" 可能指的是捕获网络通信的数据包,以进行协议分析或网络故障排除。Wireshark 是一个常用的网络分析工具,可以生成网络数据包转储。
总体而言,"dump" 是一个通用的术语,根据上下文可以指代不同类型的信息转储。在开发和运维中,生成适当类型的 "dump" 可以帮助解决各种问题,从而提高系统的稳定性和性能。
二、常见的 dump 工具
"dump" 工具在不同的上下文中可以指代不同类型的工具,用于生成详细信息的快照或转储。以下是一些常见上下文中使用的 "dump" 工具:
-
内存转储工具:
Linux:gcore是GDB的一部分,用于生成运行中程序的内存转储。Java:jmap用于生成 Java 进程的堆转储,用于分析 Java 内存使用情况。(本章讲解)
-
核心转储工具:
Linux: 当程序崩溃时,操作系统可以生成一个核心转储文件。使用gdb调试器可以分析这个核心转储文件。
-
数据库转储工具:
MySQL:mysqldump用于将 MySQL 数据库导出为 SQL 脚本,以备份或迁移数据库。PostgreSQL:pg_dump用于将 PostgreSQL 数据库导出为 SQL 脚本。
-
日志转储工具:
Linux:journalctl用于查看和导出systemd日志。- 应用程序: 一些应用程序提供日志导出工具,用于将日志信息保存到文件中。
-
堆栈转储工具:
Linux:gdb调试器可以生成运行中程序的堆栈转储,用于分析调用堆栈信息。Java:jstack用于生成 Java 进程的线程堆栈信息。(本章讲解)
-
网络转储工具:
Wireshark:Wireshark是一个网络分析工具,可以捕获和分析网络数据包,生成网络转储。
这些工具在调试、故障排除、性能分析和数据备份等方面都具有重要作用。具体使用哪个工具取决于上下文和需求。在使用这些工具时,务必了解工具的使用方法和生成的信息类型,以便更好地应对具体问题。
三、dump 可能会导致进程卡住风险(生产谨慎操作)
生成内存转储(Memory Dump)时,特别是在某些情况下,可能会导致目标进程暂时卡住。这是因为生成内存转储通常涉及到将整个进程的内存内容写入到一个文件中,这个过程可能会占用大量的系统资源和时间。
以下是一些可能导致进程卡住的原因和建议:
- 内存大小和速度:如果目标进程占用大量内存,生成内存转储可能需要较长时间,并且在此期间可能会导致进程卡住。尤其是在写入到磁盘的过程中,磁盘 I/O 操作可能成为瓶颈。
建议: 考虑在系统负载较低的时候执行内存转储,以减少对系统性能的影响。可以选择在非生产环境中进行以降低风险。
- 文件系统速度:如果将内存转储写入到磁盘,文件系统的性能可能成为瓶颈。特别是当生成大型的内存转储文件时,磁盘写入速度可能影响进程的响应性。
建议: 考虑使用性能较高的文件系统,或者将内存转储写入到专门用于存储的高性能存储介质上。
- 磁盘空间:如果目标磁盘空间不足,写入内存转储文件可能失败,导致进程卡住。
建议: 确保磁盘有足够的空间来存储生成的内存转储文件。
- 系统负载:如果系统负载很高,生成内存转储可能与其他系统任务竞争资源,导致进程响应变慢。
建议: 在系统负载较低的时候执行内存转储,或者在非生产环境中进行以降低影响。
- 调试器和断点:如果在生成内存转储的过程中使用调试器并设置了断点,这可能导致进程卡住。
建议: 确保在生成内存转储时没有设置不必要的断点。
在实际应用中,为了减少对生产环境的影响,可以选择合适的时机和条件来生成内存转储。在生产环境中谨慎操作,并在非生产环境中进行测试和调试。如果进程卡住问题持续存在,可能需要更深入地分析系统和应用程序的状态。
四、安装 JDK
jmap 和 jstack 工具都JDK自带的工具,所以得提前装好JDK
# jdk包在我下面提供的资源包里,当然你也可以去官网下载。
tar -xf jdk-8u212-linux-x64.tar.gz
# /etc/profile文件中追加如下内容:
echo "export JAVA_HOME=`pwd`/jdk1.8.0_212" >> /etc/profile
echo "export PATH=\$JAVA_HOME/bin:\$PATH" >> /etc/profile
echo "export CLASSPATH=.:\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar" >> /etc/profile
# 加载生效
source /etc/profile
官网下载:https://www.oracle.com/java/technologies/downloads/
百度云下载:
链接:https://pan.baidu.com/s/1-rgW-Z-syv24vU15bmMg1w
提取码:8888
五、jmap 介绍与示例讲解
1)jmap 介绍
jmap 是 Java 虚拟机(JVM)自带的一个命令行工具,用于生成 Java 进程的内存映像文件(heap dump)。它通过与 Java 进程通信获取内存信息,并将信息输出到文件中,以便后续离线分析。以下是 jmap 的实现机制简要概述:
-
Java进程通信:jmap使用Java进程中的Java Management Extensions(JMX)技术进行通信。JMX允许远程监控和管理 Java 进程。 -
获取内存信息:
jmap利用JMX获取Java进程的内存信息,包括堆的大小、堆的使用情况、各个区域的使用情况等。 -
生成内存映像文件:在获取了内存信息之后,jmap 将内存信息输出到一个文件中。这个文件通常以标准的堆转储(heap dump)格式保存,即 Java 堆的快照,可以由后续的分析工具读取和解析。
工作原理总结:
- jmap 通过 JMX 与 Java 进程通信,获取其内存信息。
- 获取的内存信息包括堆的使用情况、对象统计等。
- 将获取的信息输出到文件中,生成标准的堆转储文件。
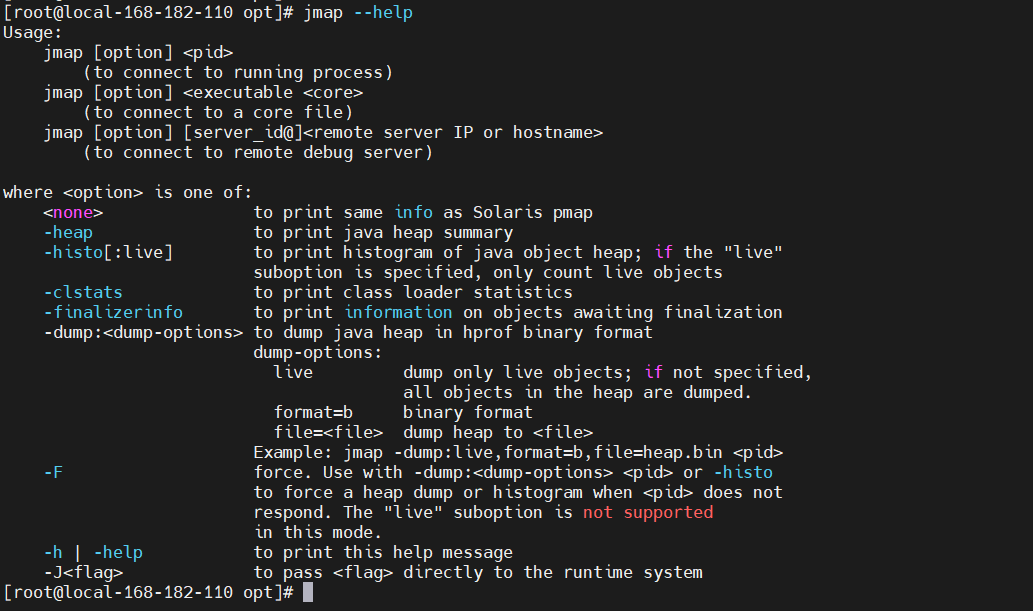
以下是 jmap 常见的参数和其作用的简要讲解:
jmap [option] <pid>
<pid>:Java进程的进程标识符。
常见参数:
-heap:显示 Java 堆的配置和使用情况。
jmap -heap <pid>
这个选项会输出 Java 堆的配置信息,包括堆的大小、各代的大小和使用情况。
-histo:显示 Java 堆中各个类的实例数量和占用内存。
jmap -histo <pid>
这个选项会输出 Java 堆中各个类的实例数量和占用内存,按照内存大小降序排列。
-dump:live,format=b,file=<filename>:生成堆转储文件。
jmap -dump:live,format=b,file=heap_dump.bin <pid>
这个选项用于生成 Java 堆的转储文件。live 表示只转储活动对象,format=b 表示使用二进制格式,file=<filename> 指定输出文件名。
-F:当进程不响应时,强制生成堆转储文件。
jmap -F -dump:format=b,file=heap_dump.bin <pid>
-F 选项用于在 Java 进程不响应时强制生成堆转储文件。
-hprof[:
jmap -hprof:port=<port> <pid>
这个选项以 HPROF 格式生成堆转储文件,并可以通过指定的端口进行远程连接。
-finalizerinfo:显示等待终结的对象的信息。
jmap -finalizerinfo <pid>
这个选项显示等待终结的对象的信息,有助于识别终结线程是否正常工作。
-permstat:显示永久代的详细信息。
jmap -permstat <pid>
这个选项用于显示永久代的详细信息,包括类加载器、类元数据等信息。
以上是一些常见的 jmap 参数,通过这些参数可以获取关于 Java 进程内存使用情况的详细信息,用于诊断和解决内存相关的性能问题。
2)Kafka安装(单机)
1、下载安装包
官方下载地址:http://kafka.apache.org/downloads
wget https://dlcdn.apache.org/kafka/3.6.0/kafka_2.12-3.6.0.tgz --no-check-certificate
tar -xvf kafka_2.12-3.6.0.tgz
2、配置环境变量
# ~/.bashrc添加如下内容:
export PATH=$PATH:/opt/kafka_2.12-3.6.0/bin
加载生效
source ~/.bashrc
3、配置kafka
cd ./kafka_2.12-3.6.0/config
vi server.properties
#添加以下内容:
broker.id=0
listeners=PLAINTEXT://local-168-182-110:9092
zookeeper.connect=local-168-182-110:2181
# 可以配置多个:zookeeper.connect=local-168-182-110:2181,local-168-182-111:2181,local-168-182-112:2181
【温馨提示】其中0.0.0.0是同时监听localhost(127.0.0.1)和内网IP(例如local-168-182-110或192.168.182.110),建议改为localhost或c1或192.168.0.113。每台机的broker.id要设置一个唯一的值。
3、配置ZooKeeper
新版Kafka已内置了ZooKeeper,如果没有其它大数据组件需要使用ZooKeeper的话,直接用内置的会更方便维护。
cd /opt/kafka_2.12-3.6.0/config
mkdir -p /tmp/zookeeper && echo 0 > /tmp/zookeeper/myid
vi zookeeper.properties
#注释掉
#maxClientCnxns=0
#设置连接参数,添加如下配置
#为zk的基本时间单元,毫秒
tickTime=2000
#Leader-Follower初始通信时限 tickTime*10
initLimit=10
#Leader-Follower同步通信时限 tickTime*5
syncLimit=5
#设置broker Id的服务地址
#hadoop-node1对应于前面在hosts里面配置的主机映射,0是broker.id, 2888是数据同步和消息传递端口,3888是选举端口
server.0=local-168-182-110:2888:3888
4、启动kafka
【温馨提示】kafka启动时先启动zookeeper,再启动kafka;关闭时相反,先关闭kafka,再关闭zookeeper
cd /opt/kafka_2.12-3.6.0/
./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
./bin/kafka-server-start.sh -daemon config/server.properties
jps
# 会看到jps、QuorumPeerMain、Kafka

5、验证
#创建topic
kafka-topics.sh --bootstrap-server local-168-182-110:9092 --create --topic topic1 --partitions 8 --replication-factor 1
#列出所有topic
kafka-topics.sh --bootstrap-server local-168-182-110:9092 --list
#列出所有topic的信息
kafka-topics.sh --bootstrap-server local-168-182-110:9092 --describe
#列出指定topic的信息
kafka-topics.sh --bootstrap-server local-168-182-110:9092 --describe --topic topic1
#生产者(消息发送程序)
kafka-console-producer.sh --broker-list local-168-182-110:9092 --topic topic1
#消费者(消息接收程序)
kafka-console-consumer.sh --bootstrap-server local-168-182-110:9092 --topic topic1
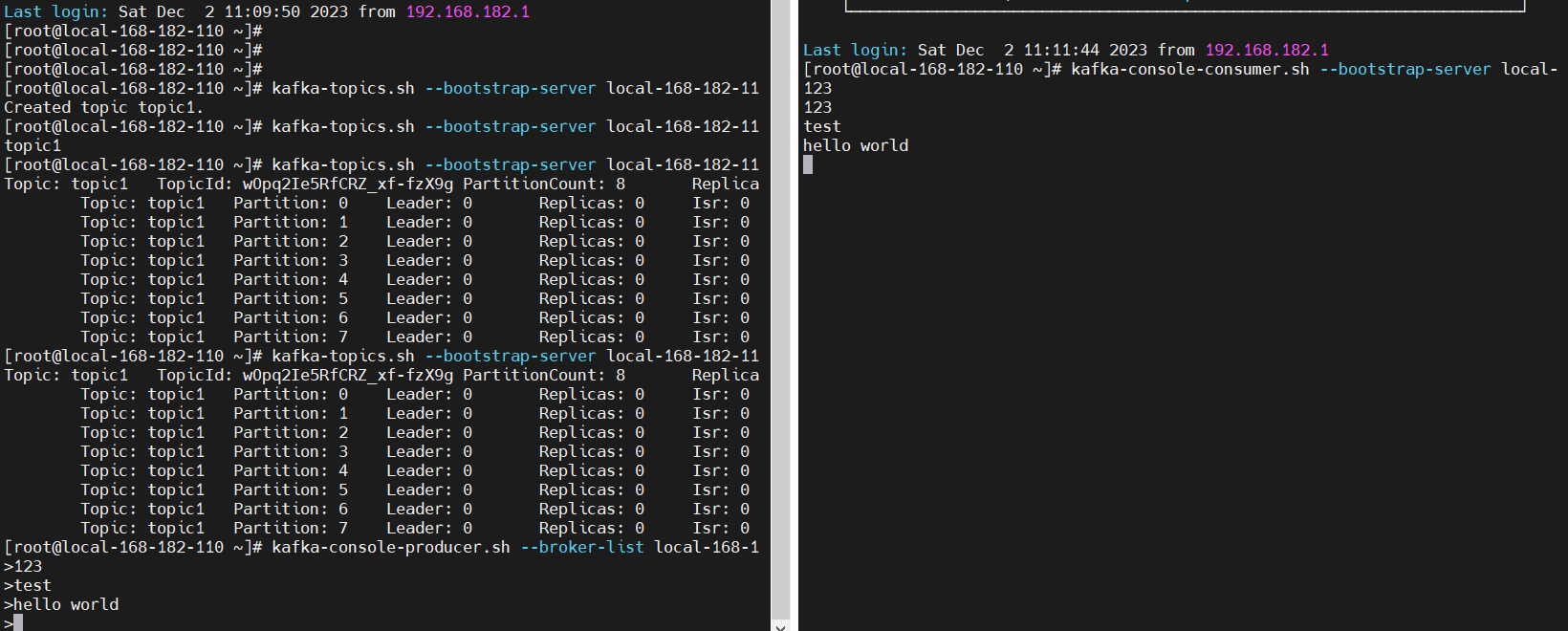
这里只是搭建一个单机版的只为下面做实验用,更对关于kafka的内容,可以参考我之前的博文(基于k8s部署):Kafka原理介绍+安装+基本操作
3)示例讲解
jmap 参数总览:
示例讲解:
【示例一】 执行jmap命令查看内存使用情况
jps
jmap -heap 42626
输出信息:
[root@local-168-182-110 ~]# jmap -heap 42626
Attaching to process ID 42626, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.212-b10
using thread-local object allocation.
Garbage-First (G1) GC with 4 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 1073741824 (1024.0MB)
NewSize = 1363144 (1.2999954223632812MB)
MaxNewSize = 643825664 (614.0MB)
OldSize = 5452592 (5.1999969482421875MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 1048576 (1.0MB)
Heap Usage:
G1 Heap:
regions = 1024
capacity = 1073741824 (1024.0MB)
used = 174063616 (166.0MB)
free = 899678208 (858.0MB)
16.2109375% used
G1 Young Generation:
Eden Space:
regions = 17
capacity = 49283072 (47.0MB)
used = 17825792 (17.0MB)
free = 31457280 (30.0MB)
36.170212765957444% used
Survivor Space:
regions = 7
capacity = 7340032 (7.0MB)
used = 7340032 (7.0MB)
free = 0 (0.0MB)
100.0% used
G1 Old Generation:
regions = 143
capacity = 1017118720 (970.0MB)
used = 148897792 (142.0MB)
free = 868220928 (828.0MB)
14.639175257731958% used
12169 interned Strings occupying 1376472 bytes.
这个执行结果显示了与Java堆配置和使用相关的信息。下面是对每个部分的解释:
Attaching to process ID 42626, please wait...:正在连接到进程ID为42626的进程,请稍等…Debugger attached successfully.:成功附加调试器。Server compiler detected.:检测到服务器编译器。说明正在使用JVM的C2(客户端编译器)进行即时编译。JVM version is 25.212-b10:JVM版本号为25.212-b10。
接下来是Java堆的配置信息:
using thread-local object allocation.:使用线程本地对象分配。Garbage-First (G1) GC with 4 thread(s):采用并行GC(垃圾收集器),共有4个线程。
Heap Configuration 部分列出了Java堆的配置设置,包括以下目录:
MinHeapFreeRatio:最小的可用于自由空间的堆比例。MaxHeapFreeRatio:最大的可用于自由空间的堆比例。MaxHeapSize:堆的最大大小。NewSize:新生代的初始大小。MaxNewSize:新生代的最大大小。OldSize:老年代的初始大小。NewRatio:新生代与老年代的比例。SurvivorRatio:Eden区和Survivor区的比例。MetaspaceSize:元空间(Metaspace)的初始大小。CompressedClassSpaceSize:压缩类空间的大小。MaxMetaspaceSize:元空间的最大大小。G1HeapRegionSize:使用G1收集器时的堆区域大小。
Heap Usage 部分显示了Java堆的使用情况,包括各个区域的容量、已用空间和空闲空间:
PS Young Generation:表示Parallel Scavenge GC中的新生代(Parallel Scavenge是一种垃圾收集器)Eden Space:伊甸园区域的容量、已用空间和空闲空间。From Space:幸存者(Survivor)区中的From区域的容量、已用空间和空闲空间。To Space:幸存者(Survivor)区中的To区域的容量、已用空间和空闲空间。PS Old Generation:表示Parallel Scavenge GC中的老年代。capacity:容量。used:已使用的空间。free:可用的空闲空间。- 最后一行
12169 interned Strings occupying 1376472 bytes.:表示共有12169 个interned字符串占用了1376472 字节的内存。
这些信息提供了有关Java堆配置和使用情况的详细数据,可用于分析和优化应用程序的内存使用。
【示例二】执行jmap命令打印对象统计信息
# jmap -histo <pid>
jps
jmap -histo 42626

上述命令会输出Java堆中各个类的实例数目和内存占用情况,可以帮助开发人员了解应用程序的内存使用情况。输出结果:
这个执行结果是一个对象直方图,列出了不同类的实例数量和占用的内存大小。下面是对每个列的解释:
num:序号,表示第几行。#instances:实例数量,表示内存中存在多少个该类的实例。#bytes:内存大小,表示该类实例所占用的总字节数。class name:类名,表示相应实例的类名。
接下来的表格显示了一系列对象的统计数据,从最多实例到最少实例进行排序。其中每一行对应一个类的统计信息。
例如,在第4行:
-
6: 54043 1297032 java.lang.String:表示有54043个java.lang.String类的实例,占用1297032字节的内存。 -
最后一行
Total 969508 181582288表示总共有969508个对象实例,占用181582288字节的内存。
通过分析对象直方图,可以了解系统中不同类型的对象的创建情况和内存消耗,从而帮助开发人员找到内存相关的问题,并进行性能优化和内存管理。
【示例三】统计 heap 中所有生存的对象的情况
统计 heap 中所有生存的对象的情况, 这个命令会先触发 gc 再统计:
# jmap -histo:live pid
jmap -histo:live 42626
【示例四】生成堆转储文件
jps
jmap -F -dump:format=b,file=heap_dump.bin 42626
# -dump:以 hprof 二进制格式将 Java 堆信息输出到文件内,该文件可以用 JProfiler、VisualVM 或 jhat 等工具查看;
【注意】执行以上命令,JVM 会将整个 heap 的信息 dump 到一个文件,heap 如果比较大的话会导致这个过程比较耗时,并且执行的过程中为了保证 dump 的信息是可靠的【会暂停应用】。
使用 jhat 分析工具
# 查看帮助
jhat -h
jhat 命令分析 heap_dump.bin 文件,在浏览器中访问jhat分析界面:
jhat jhat heap_dump.bin
http://localhost:7000/

六、jstack 介绍与示例讲解
jstack(Java Stack Trace)是java虚拟机自带的一种堆栈跟踪工具。
功能简介:
jstack常用来打印Java进程/core文件/远程调试端口的Java线程堆栈跟踪信息,包含当前虚拟机中所有线程正在执行的方法堆栈信息的集合。- 主要用来定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待。
命令格式:
jstack [ options ] pid //Java进程
jstack [ options ] executable core //core文件
jstack [ options ] [ server-id@ ] remote-hostname-or-IP //远程调试端口
其中options选项可有:
-F:当正常输出的请求不被响应时,强制输出线程堆栈-l:除了堆栈外,显示关于锁的附加信息-m:如果调用到本地方法的话,可以显示C/C++的堆栈信息gc:GC 相关的统计信息。
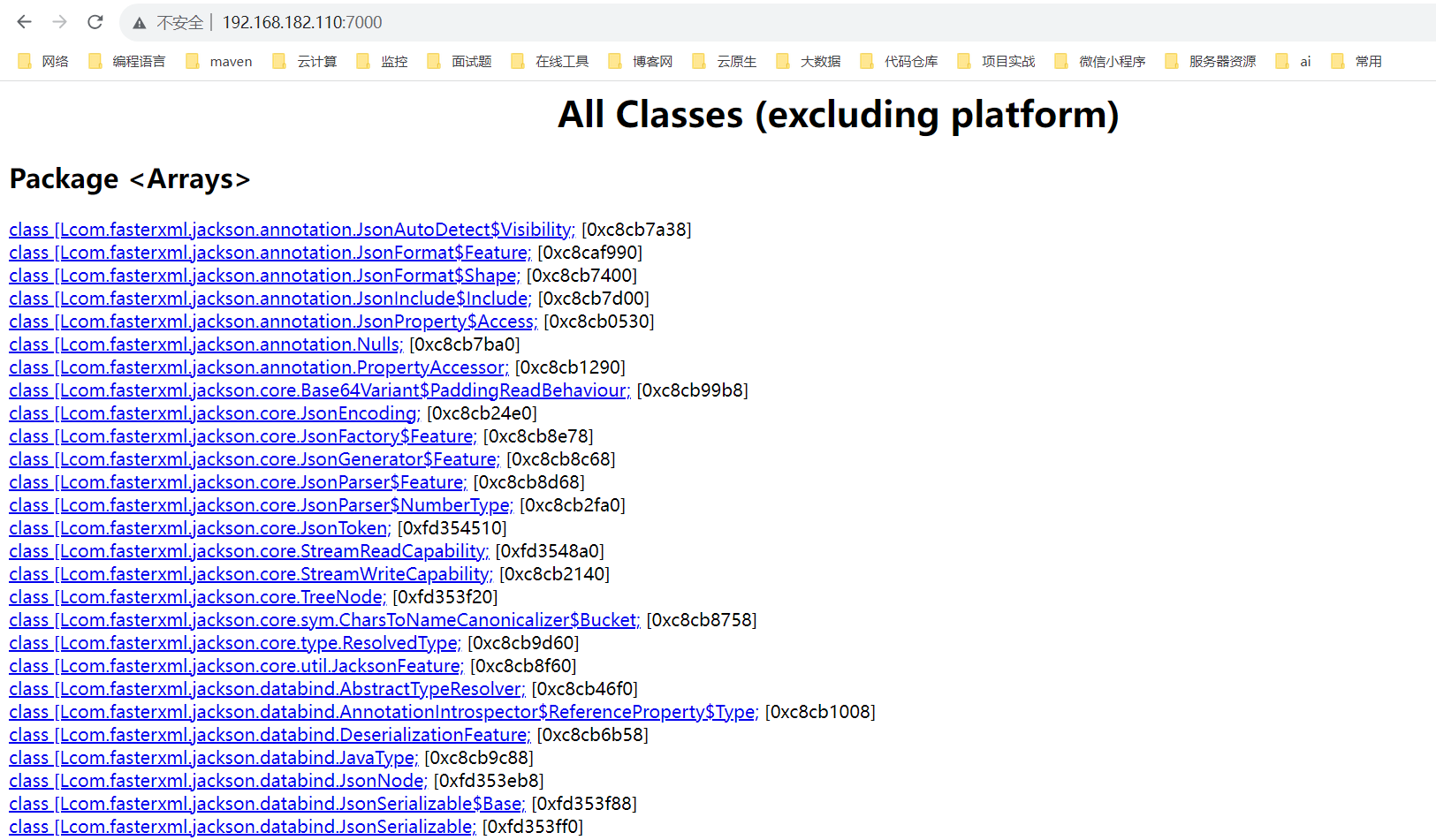
线程状态图讲解:
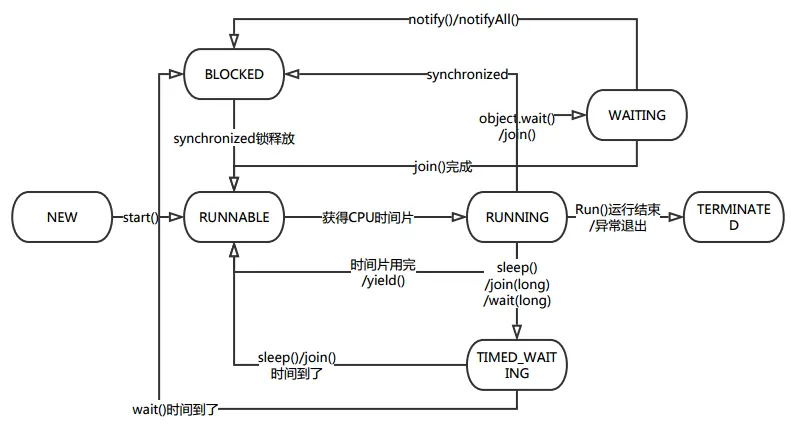
线程状态说明:
NEW:当线程对象创建时存在的状态,此时线程不可能执行;RUNNABLE:当调用thread.start()后,线程变成为Runnable状态。只要得到CPU,就可以执行;RUNNING:线程正在执行;WAITING:执行thread.join()或在锁对象调用obj.wait()等情况就会进该状态,表明线程正处于等待某个资源或条件发生来唤醒自己;TIMED_WAITING:执行Thread.sleep(long)、thread.join(long)或obj.wait(long)等就会进该状态,与Waiting的区别在于Timed_Waiting的等待有时间限制;BLOCKED:如果进入同步方法或同步代码块,没有获取到锁,则会进入该状态;DEAD:线程执行完毕,或者抛出了未捕获的异常之后,会进入dead状态,表示该线程结束。
【示例一】输出是该进程下的所有线程的堆栈集合
jps
jstack 42626
jstack 的输出是该进程下的所有线程的堆栈集合,下面是一个线程的堆栈快照信息:
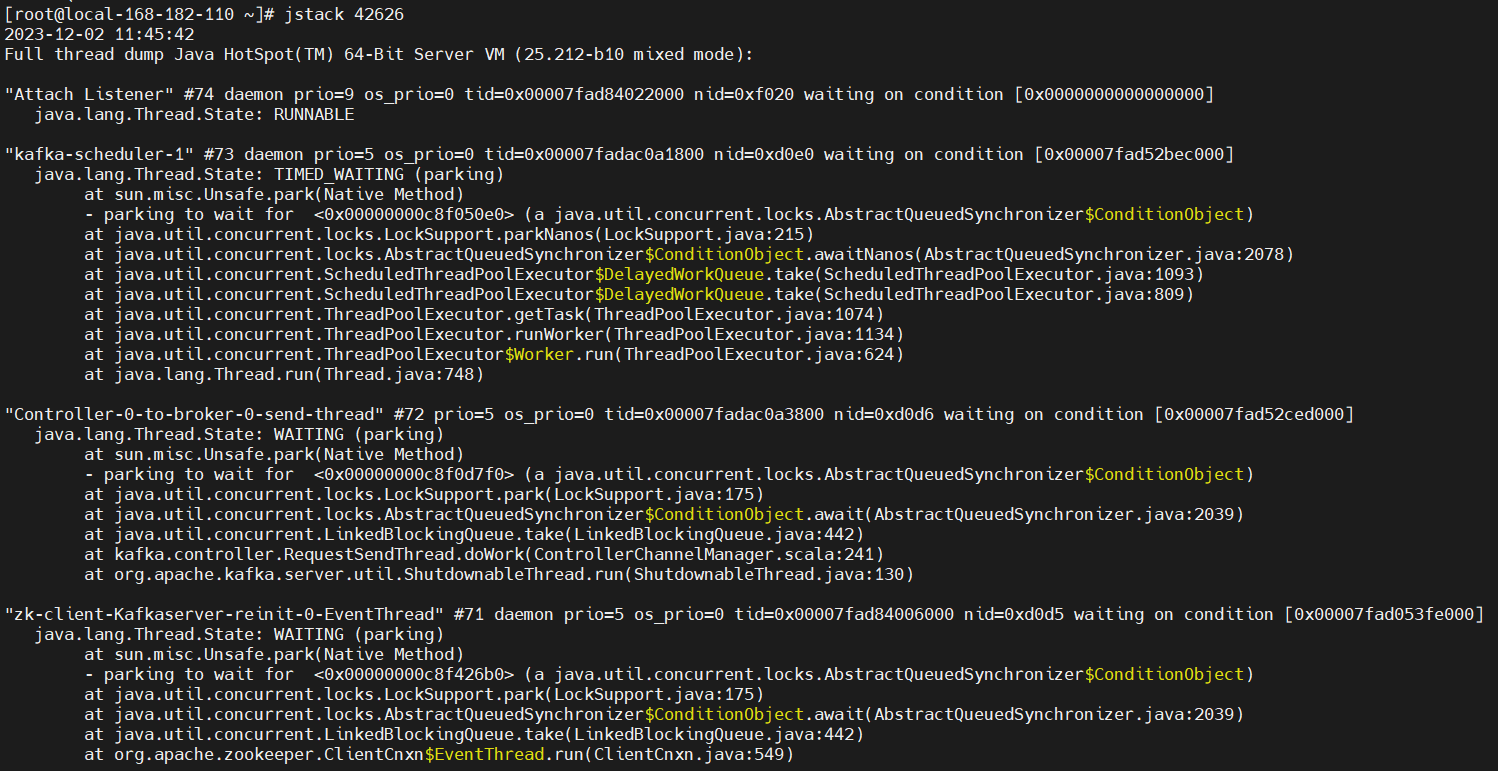
输出信息讲解:
kafka-scheduler-1:线程名称prio:该线程JVM中的优先级os_prio:该线程在OS中的优先级tid:JVM内的thread id (Java-level thread ID)nid:Native thread ID,本地操作系统相关的线程iddaemon:表明这个线程是一个守护线程
【示例二】使用 jstat -gc:GC 相关的统计信息
jstack 命令本身并没有直接支持查看 GC 相关信息的选项。jstack 主要用于生成线程堆栈信息,帮助诊断 Java 进程的线程状态、死锁等问题。如果您想要查看 GC 相关信息,可以使用其他工具来实现。
jstat 是用于监控 HotSpot 虚拟机统计信息的工具,可以用来查看 GC 相关的统计信息。例如,可以使用以下命令查看 GC 的统计信息:
jstat -gc <pid> <interval> <count>
<pid>:Java 进程的进程标识符。<interval>:采样间隔(单位:毫秒)。<count>:采样次数。
示例:
jps
jstat -gc
# 输出信息
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
0.0 0.0 0.0 0.0 55296.0 44032.0 993280.0 146367.6 50480.0 45005.1 6704.0 6042.0 7 0.496 1 0.073 0.569
输出信息解释:
S0C:第一个幸存区的大小S1C:第二个幸存区的大小S0U:第一个幸存区的使用大小S1U:第二个幸存区的使用大小EC:伊甸园区的大小EU:伊甸园区的使用大小OC:老年代大小OU:老年代使用大小MC:方法区大小MU:方法区使用大小CCSC:压缩类空间大小CCSU:压缩类空间使用大小YGC:年轻代垃圾回收次数YGCT:年轻代垃圾回收消耗时间FGC:老年代垃圾回收次数FGCT:老年代垃圾回收消耗时间GCT:垃圾回收消耗总时间
单位:KB
【示例三】使用 jstat -gccause:额外输出上次GC原因
jstat 工具的 -gccause 选项用于监控 HotSpot 虚拟机的 GC 相关信息,并显示 GC 的原因(Cause)信息。该选项会输出每个 GC 事件的原因,例如是因为老年代空间不足还是因为系统触发的 GC 等。
# jstat -gccause <pid> <interval> <count>
# <pid>:Java 进程的进程标识符。
# <interval>:采样间隔(单位:毫秒)。
# <count>:采样次数。
jstat -gccause 42626
jstack日志关键字说明:
deadlock:死锁Waiting on condition:等待某个资源或条件发生来唤醒自己。具体需要结合jstacktrace来分析,比如线程正在sleep,网络读写繁忙而等待Blocked:阻塞waiting on monitor entry:在等待获取锁in Object.wait():获取锁后又执行obj.wait()放弃锁
总体而言,jstack 是一个强大的工具,可用于实时监测 Java 进程的线程状态,有助于排查性能问题和死锁。
dump 日志收集与分析(jmap 和 jstack 工具)讲解与实战操作就先到这里了,有任何疑问也可关注我公众号:大数据与云原生技术分享,进行技术交流,如本篇文章对您有所帮助,麻烦帮忙一键三连(点赞、转发、收藏)~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号