kafka 磁盘扩容与数据均衡实在操作讲解
一、概述
Kafka 的磁盘扩容和数据均衡是与保证Kafka集群可用性和性能相关的两个重要方面。在 Kafka 中,分区数据的存储和平衡对集群的运行至关重要。以下是有关Kafka磁盘扩容和数据均衡的一些建议:
1)Kafka 磁盘扩容概述
-
添加新磁盘:在服务器上添加新的磁盘,确保磁盘有足够的容量,并且其性能符合集群的需求。
-
修改
Kafka配置:在Kafka的配置文件(server.properties)中更新log.dirs属性,将新磁盘路径添加到现有的路径中。
log.dirs=/path/to/old/disk,/path/to/new/disk
- 重新启动
Kafka节点:重新启动Kafka节点,确保新的配置生效。在进行重启之前,确保已经备份了关键的配置文件和数据。
2)Kafka 数据均衡概述
-
分区重新平衡:在
Kafka中,分区数据的均衡很重要,以确保每个节点的负载相对均匀。您可以使用Kafka提供的工具或API来重新平衡分区,确保每个节点负责处理相似数量的分区和数据。 -
监控分区状态:使用Kafka的监控工具,例如
Kafka Manager、Burrow等,来监控分区的状态和分布情况。确保没有分区处于不平衡的状态。 -
手动干预:在某些情况下,可能需要手动干预来解决数据均衡问题。这可能包括手动重新分配分区或手动调整分区的副本分布。
-
考虑工作负载变化:在Kafka集群上部署新的生产者或消费者时,要考虑工作负载的变化。新的生产者可能导致更多的数据写入,而新的消费者可能导致更多的数据读取。
-
分区数量和副本:考虑适当的分区数量和副本数量。分区数太多可能导致管理和维护的困难,而分区数太少可能导致单个节点的负载过重。
-
使用Kafka工具:Kafka提供了一些工具,如
kafka-reassign-partitions.sh用于手动重新分配分区,以及kafka-preferred-replica-election.sh用于执行首选副本选举。
在进行磁盘扩容和数据均衡时,请确保在生产环境中小心操作,并在非生产环境中进行测试和模拟。细心的规划和执行可以确保Kafka集群的可用性和性能。
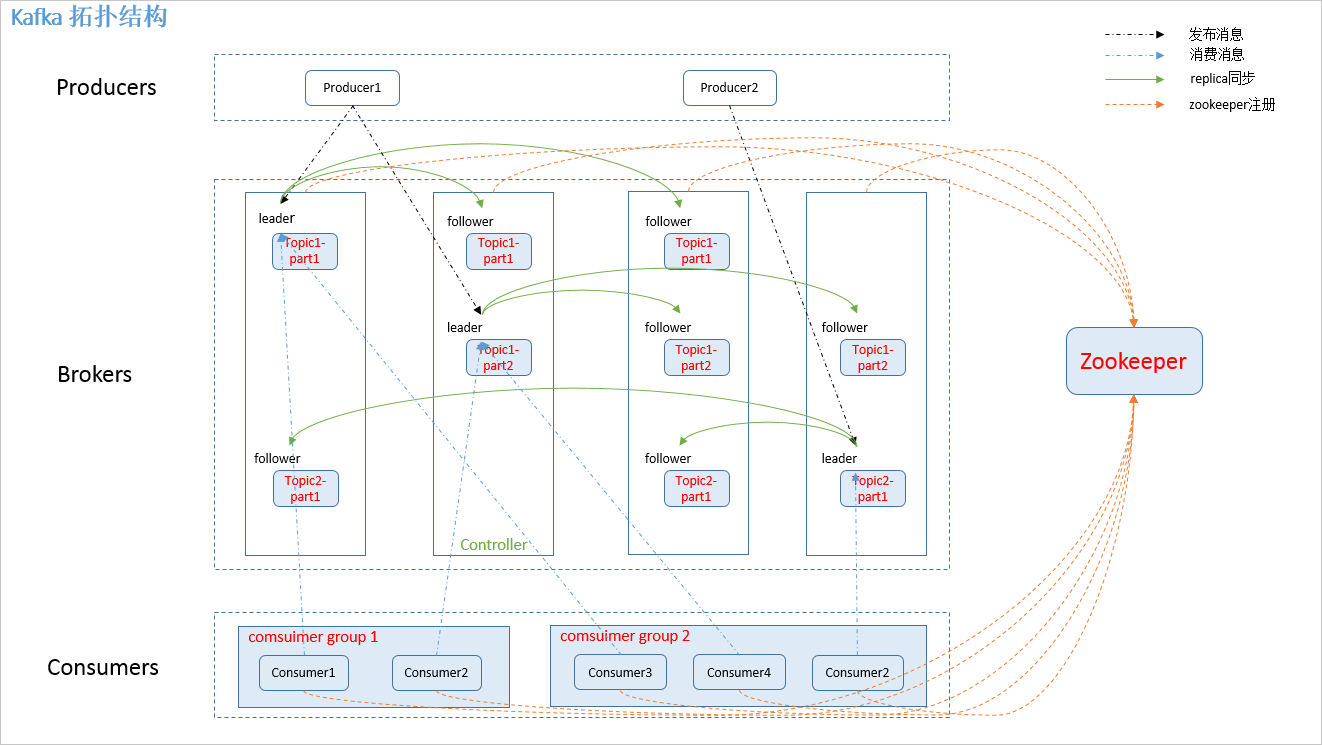
二、K8s 集群部署
k8s 环境安装之前写过很多文档,可以参考我以下几篇文章:
三、kafka on k8s 环境部署
这里为了快速演示,选择了 on k8s 部署方式,当然也可以选择物理机部署方式。以前也写过很多关于 kafka的文章,可以参考一下:
- Kafka原理介绍+安装+基本操作(kafka on k8s)
- 大数据Hadoop之——Kafka鉴权认证
- 大数据Hadoop之——Kafka安全机制(Kafka SSL认证实现)
- 大数据Hadoop之——Kafka Streams原理介绍与简单应用示例
- 大数据Hadoop之——Kafka 图形化工具 EFAK(EFAK环境部署)
- 大数据Hadoop之——EFAK安全认证实现(kafka+zookeeper)
- 【云原生】zookeeper + kafka on k8s 环境部署
- 【中间件】通过 docker-compose 快速部署 Kafka 保姆级教程
1)安装 helm
# 下载包
wget https://get.helm.sh/helm-v3.7.1-linux-amd64.tar.gz -O /tmp/helm-v3.7.1-linux-amd64.tar.gz
# 解压压缩包
tar -xf /tmp/helm-v3.7.1-linux-amd64.tar.gz -C /root/
# 软链
ln -s /root/linux-amd64/helm /usr/local/bin/helm
2)安装 zookeeper
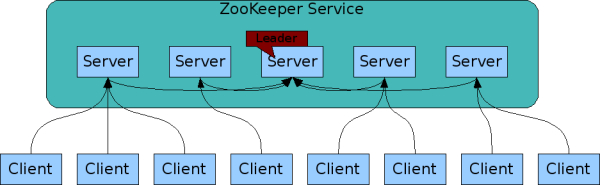
1、添加源并下载部署包
helm repo add bitnami https://charts.bitnami.com/bitnami
helm pull bitnami/zookeeper --version 10.2.1
tar -xf zookeeper-10.2.1.tgz
2、修改配置
- 修改
zookeeper/values.yaml
image:
registry: registry.cn-hangzhou.aliyuncs.com
repository: bigdata_cloudnative/zookeeper
tag: 3.8.0-debian-11-r36
...
replicaCount: 3
...
service:
type: NodePort
nodePorts:
#NodePort 默认范围是 30000-32767
client: "32181"
tls: "32182"
...
persistence:
storageClass: "zookeeper-local-storage"
size: "10Gi"
# 目录需要提前在宿主机上创建
local:
- name: zookeeper-0
host: "local-168-182-110"
path: "/opt/bigdata/servers/zookeeper/data/data1"
- name: zookeeper-1
host: "local-168-182-111"
path: "/opt/bigdata/servers/zookeeper/data/data1"
- name: zookeeper-2
host: "local-168-182-112"
path: "/opt/bigdata/servers/zookeeper/data/data1"
...
# Enable Prometheus to access ZooKeeper metrics endpoint
metrics:
enabled: true
- 添加
zookeeper/templates/pv.yaml
{{- range .Values.persistence.local }}
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: {{ .name }}
labels:
name: {{ .name }}
spec:
storageClassName: {{ $.Values.persistence.storageClass }}
capacity:
storage: {{ $.Values.persistence.size }}
accessModes:
- ReadWriteOnce
local:
path: {{ .path }}
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- {{ .host }}
---
{{- end }}
- 添加
zookeeper/templates/storage-class.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: {{ .Values.persistence.storageClass }}
provisioner: kubernetes.io/no-provisioner
- 设置时区,
zookeeper/templates/statefulset.yaml
env:
- name: TZ
value: Asia/Shanghai
3、开始安装 zookeeper
docker pull docker.io/bitnami/zookeeper:3.8.0-debian-11-r36
# 为了方便下次快速拉取镜像,将镜像推送到阿里云上
docker tag docker.io/bitnami/zookeeper:3.8.0-debian-11-r36 registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/zookeeper:3.8.0-debian-11-r36
docker push registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/zookeeper:3.8.0-debian-11-r36
# 开始安装
helm install zookeeper ./zookeeper -n zookeeper --create-namespace
NOTES
NAME: zookeeper
LAST DEPLOYED: Sun Nov 12 22:39:36 2023
NAMESPACE: zookeeper
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: zookeeper
CHART VERSION: 10.2.1
APP VERSION: 3.8.0
** Please be patient while the chart is being deployed **
ZooKeeper can be accessed via port 2181 on the following DNS name from within your cluster:
zookeeper.zookeeper.svc.cluster.local
To connect to your ZooKeeper server run the following commands:
export POD_NAME=$(kubectl get pods --namespace zookeeper -l "app.kubernetes.io/name=zookeeper,app.kubernetes.io/instance=zookeeper,app.kubernetes.io/component=zookeeper" -o jsonpath="{.items[0].metadata.name}")
kubectl exec -it $POD_NAME -- zkCli.sh
To connect to your ZooKeeper server from outside the cluster execute the following commands:
export NODE_IP=$(kubectl get nodes --namespace zookeeper -o jsonpath="{.items[0].status.addresses[0].address}")
export NODE_PORT=$(kubectl get --namespace zookeeper -o jsonpath="{.spec.ports[0].nodePort}" services zookeeper)
zkCli.sh $NODE_IP:$NODE_PORT
查看pod状态
kubectl get pods,svc -n zookeeper -owide
4、测试验证
# 登录zookeeper pod
kubectl exec -it zookeeper-0 -n zookeeper -- zkServer.sh status
kubectl exec -it zookeeper-1 -n zookeeper -- zkServer.sh status
kubectl exec -it zookeeper-2 -n zookeeper -- zkServer.sh status
kubectl exec -it zookeeper-0 -n zookeeper -- bash
5、卸载
helm uninstall zookeeper -n zookeeper
kubectl delete pod -n zookeeper `kubectl get pod -n zookeeper|awk 'NR>1{print $1}'` --force
kubectl patch ns zookeeper -p '{"metadata":{"finalizers":null}}'
kubectl delete ns zookeeper --force
3)安装 kafka
1、添加源并下载部署包
helm repo add bitnami https://charts.bitnami.com/bitnami
helm pull bitnami/kafka --version 18.4.2
tar -xf kafka-18.4.2.tgz
2、修改配置
- 修改
kafka/values.yaml
image:
registry: registry.cn-hangzhou.aliyuncs.com
repository: bigdata_cloudnative/kafka
tag: 3.2.1-debian-11-r16
...
replicaCount: 3
...
service:
type: NodePort
nodePorts:
client: "30092"
external: "30094"
...
externalAccess
enabled: true
service:
type: NodePort
nodePorts:
- 30001
- 30002
- 30003
useHostIPs: true
...
persistence:
storageClass: "kafka-local-storage"
size: "10Gi"
# 目录需要提前在宿主机上创建
local:
- name: kafka-0
host: "local-168-182-110"
path: "/opt/bigdata/servers/kafka/data/data1"
- name: kafka-1
host: "local-168-182-111"
path: "/opt/bigdata/servers/kafka/data/data1"
- name: kafka-2
host: "local-168-182-112"
path: "/opt/bigdata/servers/kafka/data/data1"
...
metrics:
kafka:
enabled: true
image:
registry: registry.cn-hangzhou.aliyuncs.com
repository: bigdata_cloudnative/kafka-exporter
tag: 1.6.0-debian-11-r8
jmx:
enabled: true
image:
registry: registry.cn-hangzhou.aliyuncs.com
repository: bigdata_cloudnative/jmx-exporter
tag: 0.17.1-debian-11-r1
annotations:
prometheus.io/path: "/metrics"
...
zookeeper:
enabled: false
...
externalZookeeper
servers:
- zookeeper-0.zookeeper-headless.zookeeper
- zookeeper-1.zookeeper-headless.zookeeper
- zookeeper-2.zookeeper-headless.zookeeper
- 添加
kafka/templates/pv.yaml
{{- range .Values.persistence.local }}
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: {{ .name }}
labels:
name: {{ .name }}
spec:
storageClassName: {{ $.Values.persistence.storageClass }}
capacity:
storage: {{ $.Values.persistence.size }}
accessModes:
- ReadWriteOnce
local:
path: {{ .path }}
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- {{ .host }}
---
{{- end }}
- 添加
kafka/templates/storage-class.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: {{ .Values.persistence.storageClass }}
provisioner: kubernetes.io/no-provisioner
- 设置时区,
kafka/templates/statefulset.yaml
env:
- name: TZ
value: Asia/Shanghai
3、开始安装
docker pull docker.io/bitnami/kafka:3.2.1-debian-11-r16
# 为了方便下次快速拉取镜像,将镜像推送到阿里云上
docker tag docker.io/bitnami/kafka:3.2.1-debian-11-r16 registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/kafka:3.2.1-debian-11-r16
docker push registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/kafka:3.2.1-debian-11-r16
# node-export
docker pull docker.io/bitnami/kafka-exporter:1.6.0-debian-11-r8
docker tag docker.io/bitnami/kafka-exporter:1.6.0-debian-11-r8 registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/kafka-exporter:1.6.0-debian-11-r8
docker push registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/kafka-exporter:1.6.0-debian-11-r8
# JXM
docker pull docker.io/bitnami/jmx-exporter:0.17.1-debian-11-r1
docker tag docker.io/bitnami/jmx-exporter:0.17.1-debian-11-r1 registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/jmx-exporter:0.17.1-debian-11-r1
docker push registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/jmx-exporter:0.17.1-debian-11-r1
#开始安装
helm install kafka ./kafka -n kafka --create-namespace
NOTES
NAME: kafka
LAST DEPLOYED: Sun Nov 12 23:32:49 2023
NAMESPACE: kafka
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: kafka
CHART VERSION: 18.4.2
APP VERSION: 3.2.1
** Please be patient while the chart is being deployed **
Kafka can be accessed by consumers via port 9092 on the following DNS name from within your cluster:
kafka.kafka.svc.cluster.local
Each Kafka broker can be accessed by producers via port 9092 on the following DNS name(s) from within your cluster:
kafka-0.kafka-headless.kafka.svc.cluster.local:9092
kafka-1.kafka-headless.kafka.svc.cluster.local:9092
kafka-2.kafka-headless.kafka.svc.cluster.local:9092
To create a pod that you can use as a Kafka client run the following commands:
kubectl run kafka-client --restart='Never' --image registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/kafka:3.2.1-debian-11-r16 --namespace kafka --command -- sleep infinity
kubectl exec --tty -i kafka-client --namespace kafka -- bash
PRODUCER:
kafka-console-producer.sh \
--broker-list kafka-0.kafka-headless.kafka.svc.cluster.local:9092,kafka-1.kafka-headless.kafka.svc.cluster.local:9092,kafka-2.kafka-headless.kafka.svc.cluster.local:9092 \
--topic test
CONSUMER:
kafka-console-consumer.sh \
--bootstrap-server kafka.kafka.svc.cluster.local:9092 \
--topic test \
--from-beginning
查看pod状态
kubectl get pods,svc -n kafka -owide
4、测试验证
# 登录zookeeper pod
kubectl exec -it kafka-0 -n kafka -- bash
# 1、创建分区
kafka-topics.sh --create --topic test001 --bootstrap-server kafka.kafka:9092 --partitions 1 --replication-factor 1
# 查看
kafka-topics.sh --describe --bootstrap-server kafka.kafka:9092 --topic test001
问题处理:Error: Exception thrown by the agent : java.rmi.server.ExportException: Port already in use: 5555; nested exception is:
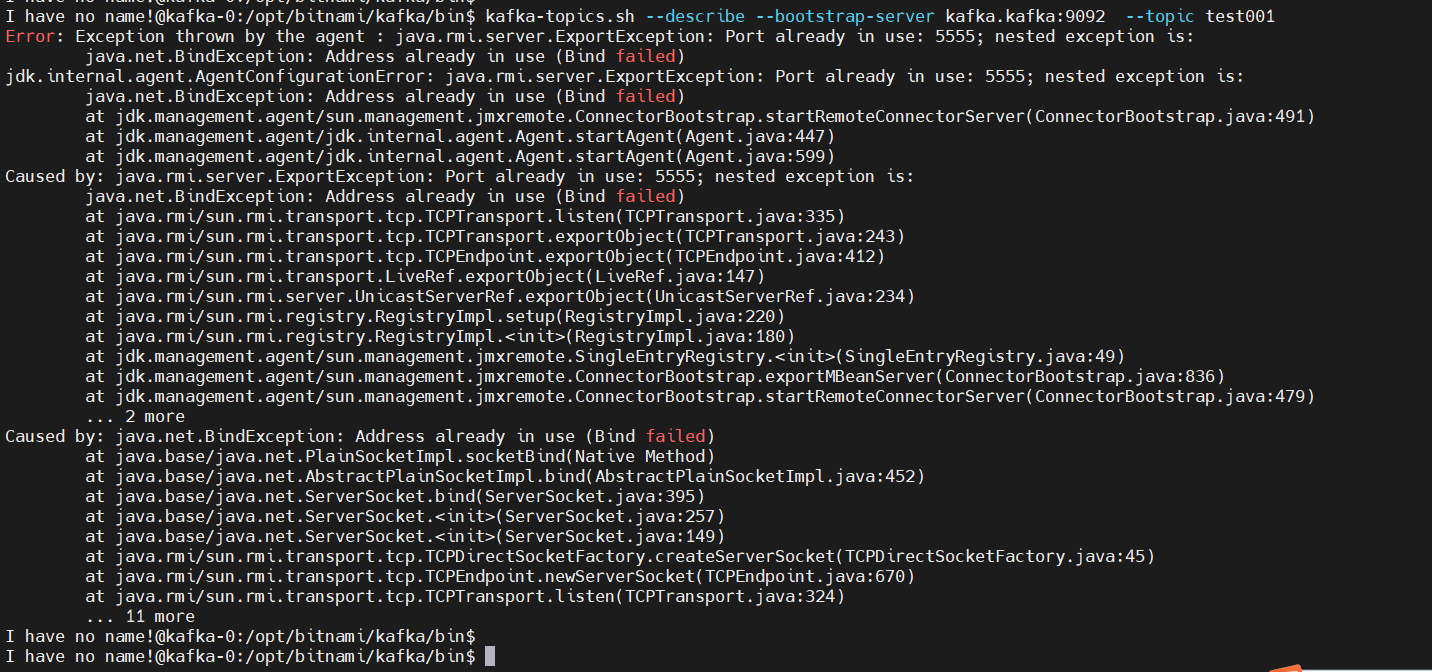
修改 /opt/bitnami/kafka/bin/kafka-run-class.sh 脚本,修改内容如下:
# 增加
ISKAFKASERVER="false"
if [[ "$*" =~ "kafka.Kafka" ]]; then
ISKAFKASERVER="true"
fi
# 修改
# if [ $JMX_PORT ];then
if [ $JMX_PORT ] && [ -z "$ISKAFKASERVER" ]; then
修改后的完整脚本
#!/bin/bash
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
if [ $# -lt 1 ];
then
echo "USAGE: $0 [-daemon] [-name servicename] [-loggc] classname [opts]"
exit 1
fi
# CYGWIN == 1 if Cygwin is detected, else 0.
if [[ $(uname -a) =~ "CYGWIN" ]]; then
CYGWIN=1
else
CYGWIN=0
fi
if [ -z "$INCLUDE_TEST_JARS" ]; then
INCLUDE_TEST_JARS=false
fi
# Exclude jars not necessary for running commands.
regex="(-(test|test-sources|src|scaladoc|javadoc)\.jar|jar.asc|connect-file.*\.jar)$"
should_include_file() {
if [ "$INCLUDE_TEST_JARS" = true ]; then
return 0
fi
file=$1
if [ -z "$(echo "$file" | egrep "$regex")" ] ; then
return 0
else
return 1
fi
}
ISKAFKASERVER="false"
if [[ "$*" =~ "kafka.Kafka" ]]; then
ISKAFKASERVER="true"
fi
base_dir=$(dirname $0)/..
if [ -z "$SCALA_VERSION" ]; then
SCALA_VERSION=2.13.6
if [[ -f "$base_dir/gradle.properties" ]]; then
SCALA_VERSION=`grep "^scalaVersion=" "$base_dir/gradle.properties" | cut -d= -f 2`
fi
fi
if [ -z "$SCALA_BINARY_VERSION" ]; then
SCALA_BINARY_VERSION=$(echo $SCALA_VERSION | cut -f 1-2 -d '.')
fi
# run ./gradlew copyDependantLibs to get all dependant jars in a local dir
shopt -s nullglob
if [ -z "$UPGRADE_KAFKA_STREAMS_TEST_VERSION" ]; then
for dir in "$base_dir"/core/build/dependant-libs-${SCALA_VERSION}*;
do
CLASSPATH="$CLASSPATH:$dir/*"
done
fi
for file in "$base_dir"/examples/build/libs/kafka-examples*.jar;
do
if should_include_file "$file"; then
CLASSPATH="$CLASSPATH":"$file"
fi
done
if [ -z "$UPGRADE_KAFKA_STREAMS_TEST_VERSION" ]; then
clients_lib_dir=$(dirname $0)/../clients/build/libs
streams_lib_dir=$(dirname $0)/../streams/build/libs
streams_dependant_clients_lib_dir=$(dirname $0)/../streams/build/dependant-libs-${SCALA_VERSION}
else
clients_lib_dir=/opt/kafka-$UPGRADE_KAFKA_STREAMS_TEST_VERSION/libs
streams_lib_dir=$clients_lib_dir
streams_dependant_clients_lib_dir=$streams_lib_dir
fi
for file in "$clients_lib_dir"/kafka-clients*.jar;
do
if should_include_file "$file"; then
CLASSPATH="$CLASSPATH":"$file"
fi
done
for file in "$streams_lib_dir"/kafka-streams*.jar;
do
if should_include_file "$file"; then
CLASSPATH="$CLASSPATH":"$file"
fi
done
if [ -z "$UPGRADE_KAFKA_STREAMS_TEST_VERSION" ]; then
for file in "$base_dir"/streams/examples/build/libs/kafka-streams-examples*.jar;
do
if should_include_file "$file"; then
CLASSPATH="$CLASSPATH":"$file"
fi
done
else
VERSION_NO_DOTS=`echo $UPGRADE_KAFKA_STREAMS_TEST_VERSION | sed 's/\.//g'`
SHORT_VERSION_NO_DOTS=${VERSION_NO_DOTS:0:((${#VERSION_NO_DOTS} - 1))} # remove last char, ie, bug-fix number
for file in "$base_dir"/streams/upgrade-system-tests-$SHORT_VERSION_NO_DOTS/build/libs/kafka-streams-upgrade-system-tests*.jar;
do
if should_include_file "$file"; then
CLASSPATH="$file":"$CLASSPATH"
fi
done
if [ "$SHORT_VERSION_NO_DOTS" = "0100" ]; then
CLASSPATH="/opt/kafka-$UPGRADE_KAFKA_STREAMS_TEST_VERSION/libs/zkclient-0.8.jar":"$CLASSPATH"
CLASSPATH="/opt/kafka-$UPGRADE_KAFKA_STREAMS_TEST_VERSION/libs/zookeeper-3.4.6.jar":"$CLASSPATH"
fi
if [ "$SHORT_VERSION_NO_DOTS" = "0101" ]; then
CLASSPATH="/opt/kafka-$UPGRADE_KAFKA_STREAMS_TEST_VERSION/libs/zkclient-0.9.jar":"$CLASSPATH"
CLASSPATH="/opt/kafka-$UPGRADE_KAFKA_STREAMS_TEST_VERSION/libs/zookeeper-3.4.8.jar":"$CLASSPATH"
fi
fi
for file in "$streams_dependant_clients_lib_dir"/rocksdb*.jar;
do
CLASSPATH="$CLASSPATH":"$file"
done
for file in "$streams_dependant_clients_lib_dir"/*hamcrest*.jar;
do
CLASSPATH="$CLASSPATH":"$file"
done
for file in "$base_dir"/shell/build/libs/kafka-shell*.jar;
do
if should_include_file "$file"; then
CLASSPATH="$CLASSPATH":"$file"
fi
done
for dir in "$base_dir"/shell/build/dependant-libs-${SCALA_VERSION}*;
do
CLASSPATH="$CLASSPATH:$dir/*"
done
for file in "$base_dir"/tools/build/libs/kafka-tools*.jar;
do
if should_include_file "$file"; then
CLASSPATH="$CLASSPATH":"$file"
fi
done
for dir in "$base_dir"/tools/build/dependant-libs-${SCALA_VERSION}*;
do
CLASSPATH="$CLASSPATH:$dir/*"
done
for file in "$base_dir"/trogdor/build/libs/trogdor-*.jar;
do
if should_include_file "$file"; then
CLASSPATH="$CLASSPATH":"$file"
fi
done
for dir in "$base_dir"/trogdor/build/dependant-libs-${SCALA_VERSION}*;
do
CLASSPATH="$CLASSPATH:$dir/*"
done
for cc_pkg in "api" "transforms" "runtime" "mirror" "mirror-client" "json" "tools" "basic-auth-extension"
do
for file in "$base_dir"/connect/${cc_pkg}/build/libs/connect-${cc_pkg}*.jar;
do
if should_include_file "$file"; then
CLASSPATH="$CLASSPATH":"$file"
fi
done
if [ -d "$base_dir/connect/${cc_pkg}/build/dependant-libs" ] ; then
CLASSPATH="$CLASSPATH:$base_dir/connect/${cc_pkg}/build/dependant-libs/*"
fi
done
# classpath addition for release
for file in "$base_dir"/libs/*;
do
if should_include_file "$file"; then
CLASSPATH="$CLASSPATH":"$file"
fi
done
for file in "$base_dir"/core/build/libs/kafka_${SCALA_BINARY_VERSION}*.jar;
do
if should_include_file "$file"; then
CLASSPATH="$CLASSPATH":"$file"
fi
done
shopt -u nullglob
if [ -z "$CLASSPATH" ] ; then
echo "Classpath is empty. Please build the project first e.g. by running './gradlew jar -PscalaVersion=$SCALA_VERSION'"
exit 1
fi
# JMX settings
if [ -z "$KAFKA_JMX_OPTS" ]; then
KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false "
fi
# JMX port to use
if [ $JMX_PORT ] && [ -z "$ISKAFKASERVER" ]; then
KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT "
fi
# Log directory to use
if [ "x$LOG_DIR" = "x" ]; then
LOG_DIR="$base_dir/logs"
fi
# Log4j settings
if [ -z "$KAFKA_LOG4J_OPTS" ]; then
# Log to console. This is a tool.
LOG4J_DIR="$base_dir/config/tools-log4j.properties"
# If Cygwin is detected, LOG4J_DIR is converted to Windows format.
(( CYGWIN )) && LOG4J_DIR=$(cygpath --path --mixed "${LOG4J_DIR}")
KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:${LOG4J_DIR}"
else
# create logs directory
if [ ! -d "$LOG_DIR" ]; then
mkdir -p "$LOG_DIR"
fi
fi
# If Cygwin is detected, LOG_DIR is converted to Windows format.
(( CYGWIN )) && LOG_DIR=$(cygpath --path --mixed "${LOG_DIR}")
KAFKA_LOG4J_OPTS="-Dkafka.logs.dir=$LOG_DIR $KAFKA_LOG4J_OPTS"
# Generic jvm settings you want to add
if [ -z "$KAFKA_OPTS" ]; then
KAFKA_OPTS=""
fi
# Set Debug options if enabled
if [ "x$KAFKA_DEBUG" != "x" ]; then
# Use default ports
DEFAULT_JAVA_DEBUG_PORT="5005"
if [ -z "$JAVA_DEBUG_PORT" ]; then
JAVA_DEBUG_PORT="$DEFAULT_JAVA_DEBUG_PORT"
fi
# Use the defaults if JAVA_DEBUG_OPTS was not set
DEFAULT_JAVA_DEBUG_OPTS="-agentlib:jdwp=transport=dt_socket,server=y,suspend=${DEBUG_SUSPEND_FLAG:-n},address=$JAVA_DEBUG_PORT"
if [ -z "$JAVA_DEBUG_OPTS" ]; then
JAVA_DEBUG_OPTS="$DEFAULT_JAVA_DEBUG_OPTS"
fi
echo "Enabling Java debug options: $JAVA_DEBUG_OPTS"
KAFKA_OPTS="$JAVA_DEBUG_OPTS $KAFKA_OPTS"
fi
# Which java to use
if [ -z "$JAVA_HOME" ]; then
JAVA="java"
else
JAVA="$JAVA_HOME/bin/java"
fi
# Memory options
if [ -z "$KAFKA_HEAP_OPTS" ]; then
KAFKA_HEAP_OPTS="-Xmx256M"
fi
# JVM performance options
# MaxInlineLevel=15 is the default since JDK 14 and can be removed once older JDKs are no longer supported
if [ -z "$KAFKA_JVM_PERFORMANCE_OPTS" ]; then
KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:MaxInlineLevel=15 -Djava.awt.headless=true"
fi
while [ $# -gt 0 ]; do
COMMAND=$1
case $COMMAND in
-name)
DAEMON_NAME=$2
CONSOLE_OUTPUT_FILE=$LOG_DIR/$DAEMON_NAME.out
shift 2
;;
-loggc)
if [ -z "$KAFKA_GC_LOG_OPTS" ]; then
GC_LOG_ENABLED="true"
fi
shift
;;
-daemon)
DAEMON_MODE="true"
shift
;;
*)
break
;;
esac
done
# GC options
GC_FILE_SUFFIX='-gc.log'
GC_LOG_FILE_NAME=''
if [ "x$GC_LOG_ENABLED" = "xtrue" ]; then
GC_LOG_FILE_NAME=$DAEMON_NAME$GC_FILE_SUFFIX
# The first segment of the version number, which is '1' for releases before Java 9
# it then becomes '9', '10', ...
# Some examples of the first line of `java --version`:
# 8 -> java version "1.8.0_152"
# 9.0.4 -> java version "9.0.4"
# 10 -> java version "10" 2018-03-20
# 10.0.1 -> java version "10.0.1" 2018-04-17
# We need to match to the end of the line to prevent sed from printing the characters that do not match
JAVA_MAJOR_VERSION=$("$JAVA" -version 2>&1 | sed -E -n 's/.* version "([0-9]*).*$/\1/p')
if [[ "$JAVA_MAJOR_VERSION" -ge "9" ]] ; then
KAFKA_GC_LOG_OPTS="-Xlog:gc*:file=$LOG_DIR/$GC_LOG_FILE_NAME:time,tags:filecount=10,filesize=100M"
else
KAFKA_GC_LOG_OPTS="-Xloggc:$LOG_DIR/$GC_LOG_FILE_NAME -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M"
fi
fi
# Remove a possible colon prefix from the classpath (happens at lines like `CLASSPATH="$CLASSPATH:$file"` when CLASSPATH is blank)
# Syntax used on the right side is native Bash string manipulation; for more details see
# http://tldp.org/LDP/abs/html/string-manipulation.html, specifically the section titled "Substring Removal"
CLASSPATH=${CLASSPATH#:}
# If Cygwin is detected, classpath is converted to Windows format.
(( CYGWIN )) && CLASSPATH=$(cygpath --path --mixed "${CLASSPATH}")
# Launch mode
if [ "x$DAEMON_MODE" = "xtrue" ]; then
nohup "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp "$CLASSPATH" $KAFKA_OPTS "$@" > "$CONSOLE_OUTPUT_FILE" 2>&1 < /dev/null &
else
exec "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp "$CLASSPATH" $KAFKA_OPTS "$@"
fi
将脚本覆盖容器里的
kubectl cp kafka-run-class.sh kafka-0:/opt/bitnami/kafka/bin/kafka-run-class.sh -n kafka
再执行创建topic
# 登录zookeeper pod
kubectl exec -it kafka-0 -n kafka -- bash
# 参数解释:
# --create: 指定创建topic动作
# --topic:指定新建topic的名称
#--bootstrap-server: 指定kafka连接地址
#--config:指定当前topic上有效的参数值,参数列表参考文档为: Topic-level configuration
#--partitions:指定当前创建的kafka分区数量,默认为1个
# --replication-factor:指定每个分区的副本数,默认1个
# 1、创建topic,三分区,三副本,设置数据过期时间72小时(-1表示不过期,默认是永久保存的,不会自动过期),单位ms,72*3600*1000=259200000
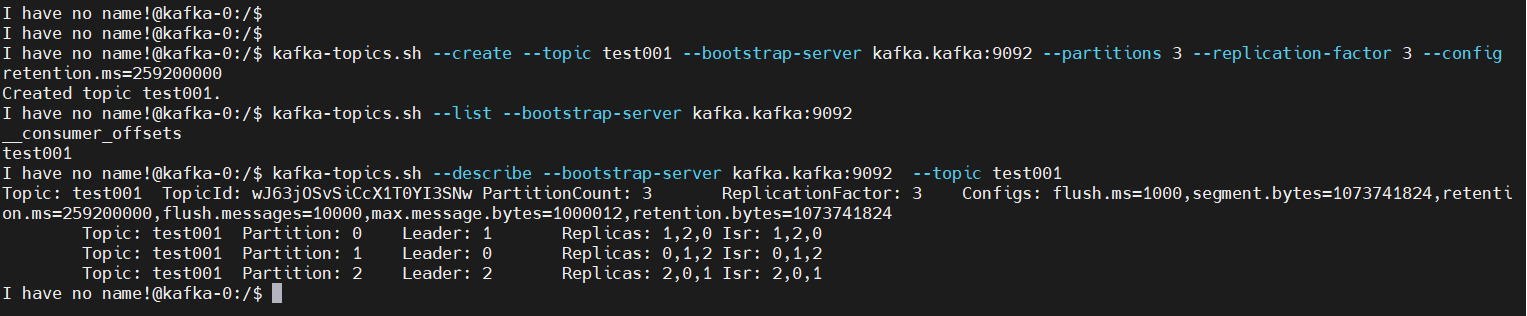
kafka-topics.sh --create --topic test001 --bootstrap-server kafka.kafka:9092 --partitions 3 --replication-factor 3 --config retention.ms=259200000
# 查看
kafka-topics.sh --list --bootstrap-server kafka.kafka:9092
kafka-topics.sh --describe --bootstrap-server kafka.kafka:9092 --topic test001
生产者/消费者测试
# 【生产者】
kafka-console-producer.sh --broker-list kafka.kafka:9092 --topic test001
{"id":"1","name":"n1","age":"20"}
{"id":"2","name":"n2","age":"21"}
{"id":"3","name":"n3","age":"22"}
# 【消费者】
# 从头开始消费
kafka-console-consumer.sh --bootstrap-server kafka.kafka:9092 --topic test001 --from-beginning
# 指定从分区的某个位置开始消费,这里只指定了一个分区,可以多写几行或者遍历对应的所有分区
kafka-console-consumer.sh --bootstrap-server kafka.kafka:9092 --topic test001 --partition 0 --offset 100 --group test001
# 查看数据积压
kafka-consumer-groups.sh --bootstrap-server kafka.kafka:9092 --describe --group test001
删除 topic
# 删除topic,默认是没有启用删除topic的
kafka-topics.sh --delete --topic test001 --bootstrap-server kafka.kafka:9092
# 配置启用可以删除topic,topic 配置文件里,delete.topic.enable=true;k8s helm chat包里开启这个参数:
deleteTopicEnable: true
5、卸载
helm uninstall kafka -n kafka
kubectl delete pod -n kafka `kubectl get pod -n kafka|awk 'NR>1{print $1}'` --force
kubectl patch ns kafka -p '{"metadata":{"finalizers":null}}'
kubectl delete ns kafka --force
四、kafka 分区与副本
Kafka中的分区(Partitions)和副本(Replicas)是关键的概念,它们有助于实现高可用性、容错性和扩展性。下面是有关Kafka分区和副本的基本概念:
1)分区(Partitions):
定义:分区是Kafka中用于存储消息的基本单元。每个主题(Topic)都可以被划分为一个或多个分区。分区中的每条消息都会被分配到一个特定的分区中。
1、作用:
- 水平扩展:通过将主题划分为多个分区,Kafka可以水平扩展,允许消息的并行处理和更好的性能。
- 顺序保证:每个分区中的消息保持有序。在同一分区中,消息的写入和读取顺序是严格有序的。
2、分区的属性:
- 编号:每个分区都有一个唯一的编号(从0开始),用于标识分区。
- 持久化:分区的数据是持久化的,可以在多个节点之间复制以提高可用性和容错性。
- 副本数量:每个分区可以有一个或多个副本。
3、生产者和消费者:
- 生产者可以指定消息发送到特定的分区。
- 消费者订阅主题时,会消费所有分区中的消息。
2)副本(Replicas):
定义:副本是分区的复制。每个分区可以配置多个副本,这些副本分布在Kafka集群的不同节点上。
1、作用:
- 高可用性:副本提供了故障恢复和高可用性。当某个节点或分区不可用时,仍然可以从其他节点或副本读取数据。
- 容错性:通过在多个节点上存储相同的数据,即使某个节点发生故障,数据仍然可用。
2、副本的属性:
- 同步复制:副本之间可以配置为同步或异步复制。同步复制确保写入操作在所有副本上都完成后才返回成功。
- 领导者和追随者:每个分区都有一个领导者(Leader)和零个或多个追随者(Follower)。生产者和消费者通常与分区的领导者进行交互。
3、ISR(In-Sync Replicas):
ISR是指与分区领导者保持同步的副本集合。只有ISR中的副本才能成为新的领导者。当某个副本无法保持同步时,它将从ISR中移除。
生产者和消费者与分区和副本的关系:
- 生产者可以选择将消息发送到特定的分区,也可以根据分区键选择。
- 消费者订阅主题时,会消费分区中的消息,与分区中的领导者和追随者进行交互。
总体而言,Kafka的分区和副本机制提供了高度的可伸缩性、高可用性和容错性,使其成为处理大规模实时数据流的强大平台。
五、kafka 磁盘扩容
场景:可能因为数据量上涨,就得靠谱扩容磁盘了,这里每个节点增加一块磁盘,如果不新增topic的情况下,是不会写到对应新磁盘的。kafka配置文件log.dirs增加了几个目录。
# log.dirs用来配置多个根目录(以逗号分隔)
log.dirs=/data1,/data2
# 修改完配置重启kafka即可
六、数据均衡(分区迁移)
场景:kafka配置文件log.dirs增加了几个目录,但是新目录没有分区数据写入,所以打算进行重分区一下。
1)查看topic分区情况
# 登录zookeeper pod
kubectl exec -it kafka-0 -n kafka -- bash
# 为了测试这里多建几个topic
kafka-topics.sh --create --topic test002 --bootstrap-server kafka.kafka:9092 --partitions 1 --replication-factor 1 --config retention.ms=259200000
kafka-topics.sh --create --topic test003 --bootstrap-server kafka.kafka:9092 --partitions 1 --replication-factor 1 --config retention.ms=259200000
kafka-topics.sh --create --topic test004 --bootstrap-server kafka.kafka:9092 --partitions 1 --replication-factor 1 --config retention.ms=259200000
kafka-topics.sh --create --topic test005 --bootstrap-server kafka.kafka:9092 --partitions 2 --replication-factor 2 --config retention.ms=259200000
kafka-topics.sh --create --topic test006 --bootstrap-server kafka.kafka:9092 --partitions 2 --replication-factor 2 --config retention.ms=259200000
kafka-topics.sh --create --topic test007 --bootstrap-server kafka.kafka:9092 --partitions 2 --replication-factor 2 --config retention.ms=259200000
# 查看分区情况
kafka-topics.sh --describe --bootstrap-server kafka.kafka:9092 --topic test001

2)查看分区大小
# 显示所有的topic详情
kafka-log-dirs.sh --describe --bootstrap-server kafka.kafka:9092
# 只显示test001信息
kafka-log-dirs.sh --describe --bootstrap-server kafka.kafka:9092 --topic-list test001

数据格式化:
{
"version": 1,
"brokers": [
{
"broker": 2,
"logDirs": [
{
"logDir": "/bitnami/kafka/data",
"error": null,
"partitions": [
{
"partition": "test001-0",
"size": 380,
"offsetLag": 0,
"isFuture": false
},
{
"partition": "test001-2",
"size": 198,
"offsetLag": 0,
"isFuture": false
},
{
"partition": "test001-1",
"size": 190,
"offsetLag": 0,
"isFuture": false
}
]
}
]
},
{
"broker": 1,
"logDirs": [
{
"logDir": "/bitnami/kafka/data",
"error": null,
"partitions": [
{
"partition": "test001-0",
"size": 380,
"offsetLag": 0,
"isFuture": false
},
{
"partition": "test001-2",
"size": 198,
"offsetLag": 0,
"isFuture": false
},
{
"partition": "test001-1",
"size": 190,
"offsetLag": 0,
"isFuture": false
}
]
}
]
},
{
"broker": 0,
"logDirs": [
{
"logDir": "/bitnami/kafka/data",
"error": null,
"partitions": [
{
"partition": "test001-0",
"size": 380,
"offsetLag": 0,
"isFuture": false
},
{
"partition": "test001-2",
"size": 198,
"offsetLag": 0,
"isFuture": false
},
{
"partition": "test001-1",
"size": 190,
"offsetLag": 0,
"isFuture": false
}
]
}
]
}
]
}
3)编写 move-json-file.json,生成执行计划
move-json-file.json 这个文件就是告知想对哪些Topic进行重新分配的计算。
【示例一】分区迁移
{
"topics": [{
"topic": "test002"
}],
"version": 1
}
# 查看分区
kafka-topics.sh --describe --bootstrap-server kafka.kafka:9092 --topic test002
# 查看分区大小
kafka-log-dirs.sh --describe --bootstrap-server kafka.kafka:9092 --topic-list test002
开始执行
# 当前topic在,0节点,迁移到1节点
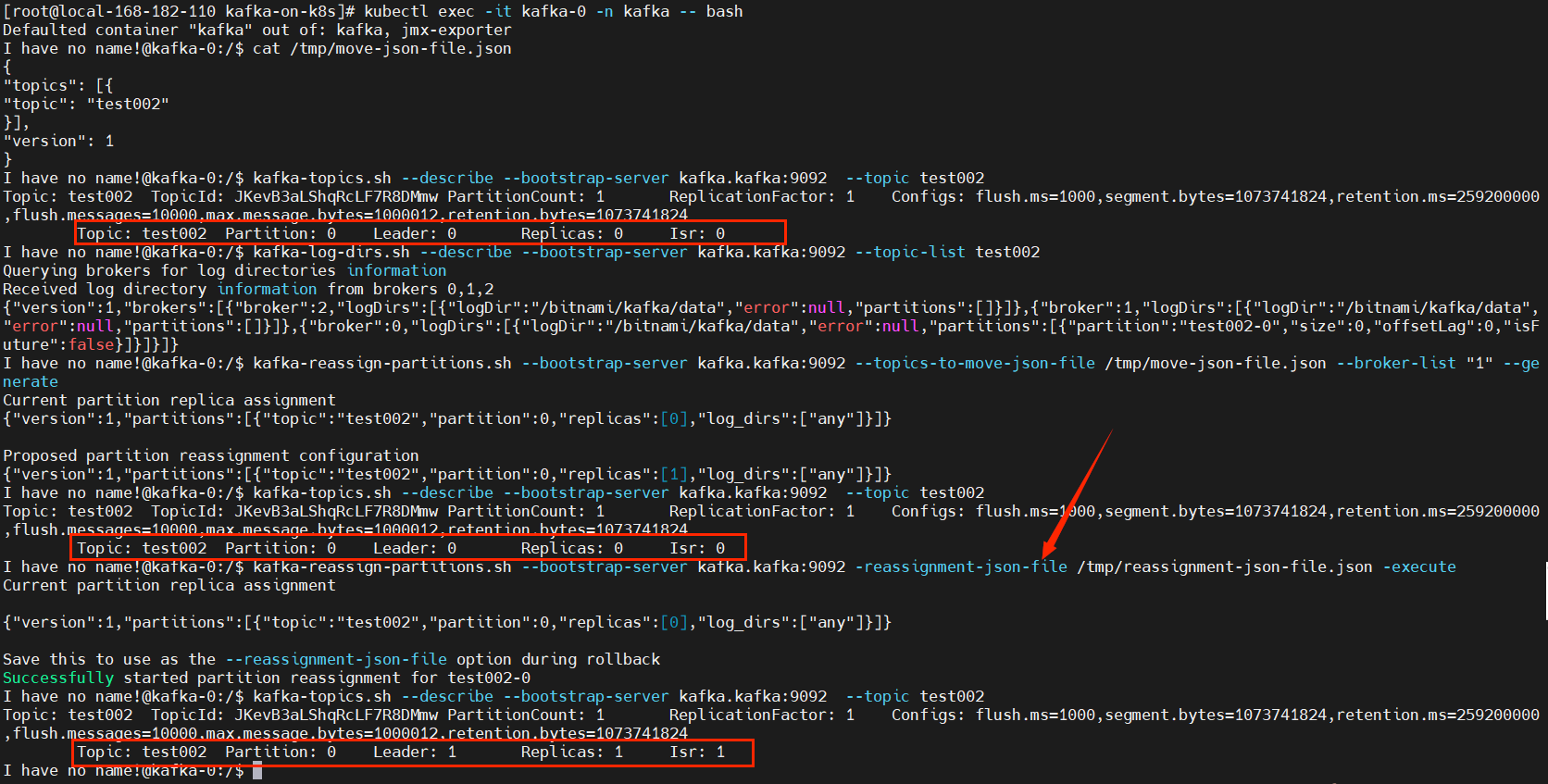
kafka-reassign-partitions.sh --bootstrap-server kafka.kafka:9092 --topics-to-move-json-file /tmp/move-json-file.json --broker-list "1" --generate
# 输出信息:生成了两条信息,第一条为现在的分配情况,第二条为计划更改的内容
# 当前:Current partition replica assignment
{"version":1,"partitions":[{"topic":"test002","partition":0,"replicas":[0],"log_dirs":["any"]}]}
# 迁移:Proposed partition reassignment configuration
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"test002","partition":0,"replicas":[1],"log_dirs":["any"]}]}
把计划修改的结果复制,放在第二个json文件中,这里取名为reassignment-json-file.json
【注意】现在还没真正迁移,只是输出迁移信息。可以执行查看就知道了。
kafka-topics.sh --describe --bootstrap-server kafka.kafka:9092 --topic test002
{"version":1,"partitions":[{"topic":"test002","partition":0,"replicas":[1],"log_dirs":["any"]}]}
【温馨提示】--broker-list "1":扩容后的所有机器的broker.id。
4)开始迁移
运行kafka-reassign-partition.sh命令根据上述执行计划生成的结果进行分配,命令如下:
echo '{"version":1,"partitions":[{"topic":"test002","partition":0,"replicas":[1],"log_dirs":["any"]}]}' >/tmp/reassignment-json-file.json
kafka-reassign-partitions.sh --bootstrap-server kafka.kafka:9092 -reassignment-json-file /tmp/reassignment-json-file.json -execute
【示例二】磁盘间、不同路径分区迁移
{
"version": 1,
"partitions": [{
"topic": "test01",
"partition": 2,
"replicas": [0],
"log_dirs": ["/data1"]
}, {
"topic": "test01",
"partition": 1,
"replicas": [0],
"log_dirs": ["/data2"]
}]
}
version:固定值 1
开始执行迁移
kafka-reassign-partitions.sh --zookeeper --bootstrap-server kafka.kafka:9092 --reassignment-json-file config/move-json-file.json --execute --bootstrap-server
kafka.kafka:9092 --execute --replica-alter-log-dirs-throttle 10000 --throttle 50000000
参数讲解:
--replica-alter-log-dirs-throttle:需要注意的是,如果你迁移的时候包含 副本跨路径迁移(同一个Broker多个路径)那么这个限流措施不会生效,你需要再加上--replica-alter-log-dirs-throttle这个限流参数,它限制的是同一个Broker不同路径直接迁移的限流。--throttle 50000000:那么执行移动分区的时候,会被限制流量在50000000 B/s。
kafka 磁盘扩容与数据均衡实在操作讲解就先到这里了,有任何疑问也可关注我公众号:大数据与云原生技术分享,进行技术交流,如本篇文章对您有所帮助,麻烦帮忙一键三连(点赞、转发、收藏)~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号