大数据Hadoop之——Hadoop 3.3.4 HA(高可用)原理与实现(QJM)
一、前言
在 Hadoop 2.0.0 之前,一个集群只有一个Namenode,这将面临单点故障问题。如果 Namenode 机器挂掉了,整个集群就用不了了。只有重启 Namenode ,才能恢复集群。另外正常计划维护集群的时候,还必须先停用整个集群,这样没办法达到 7 * 24小时可用状态。Hadoop 2.0 及之后版本增加了 Namenode 高可用机制,下面详细介绍。
非高可用部署,可参考我之前的文章:大数据Hadoop原理介绍+安装+实战操作(HDFS+YARN+MapReduce)
二、Hadoop HDFS HA 架构与原理
1)Hadoop NameNode HA 架构
我们知道
NameNode上存储的是 HDFS 上所有的元数据信息,因此最关键的问题在于 NameNode 挂了一个,备份的要及时顶上,这就意味着我们要把所有的元数据都同步到备份节点。好,接下来我们考虑如何同步呢?每次 HDFS 写入一个文件,都要同步写 NameNode 和其备份节点吗?如果备份节点挂了就会写失败?显然不能这样,只能是异步来同步元数据。如果 NameNode 刚好宕机却没有将元数据异步写入到备份节点呢?那这部分信息岂不是丢失了?这个问题就自然要引入第三方的存储了,在 HA 方案中叫做“共享存储”。每次写文件时,需要将日志同步写入共享存储,这个步骤成功才能认定写文件成功。然后备份节点定期从共享存储同步日志,以便进行主备切换。
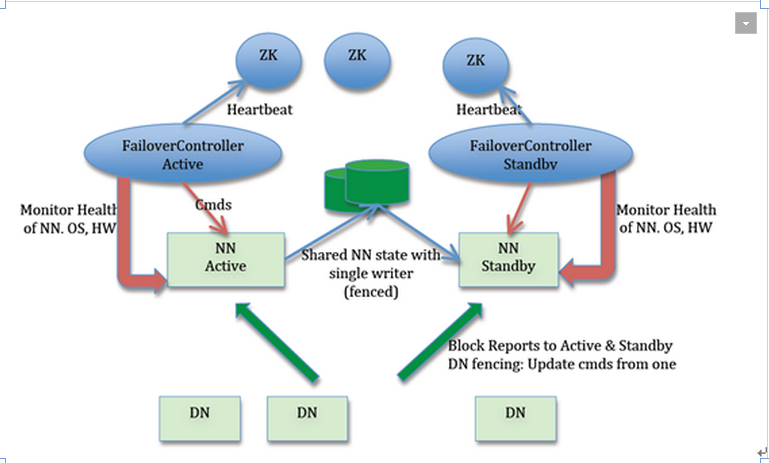
- Active NameNode 和 Standby NameNode——两台 NameNode 形成互备,一台处于 Active 状态,为主 NameNode,另外一台处于 Standby 状态,为备 NameNode,只有主 NameNode 才能对外提供读写服务。
- 主备切换控制器 ZKFailoverController-——ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换,当然 NameNode 目前也支持不依赖于 Zookeeper 的手动主备切换。
- Zookeeper 集群——分布式协调器,NameNode选主用的。
- ZKFS——Zookeeper客户端,监控NameNode状态,并与Zookeeper保持长连接,与NameNode在一台机器上部署
- 共享存储系统——共享存储系统是实现 NameNode 的高可用最为关键的部分,共享存储系统保存了 NameNode 在运行过程中所产生的 HDFS 的元数据。Active NameNode 和 Standby NameNode 通过共享存储系统实现元数据同步。在进行主备切换的时候,新的主 NameNode 在确认元数据完全同步之后才能继续对外提供服务。
- DataNode 节点——除了通过共享存储系统共享 HDFS 的元数据信息之外,主 NameNode 和备 NameNode 还需要共享 HDFS 的数据块和 DataNode 之间的映射关系。DataNode 会同时向主 NameNode 和备 NameNode 上报数据块的位置信息。
2)Hadoop NameNode HA原理
1、核心组件介绍
NameNode 主备切换主要由 ZKFailoverController、HealthMonitor 和 ActiveStandbyElector 这 3 个组件来协同实现:
-
ZKFailoverController作为 NameNode 机器上一个独立的进程启动 (在 hdfs 启动脚本之中的进程名为 zkfc),启动的时候会创建 HealthMonitor 和 ActiveStandbyElector 这两个主要的内部组件,ZKFailoverController 在创建 HealthMonitor 和 ActiveStandbyElector 的同时,也会向 HealthMonitor 和 ActiveStandbyElector 注册相应的回调方法。 -
HealthMonitor主要负责检测 NameNode 的健康状态,如果检测到 NameNode 的状态发生变化,会回调 ZKFailoverController 的相应方法进行自动的主备选举。 -
ActiveStandbyElector主要负责完成自动的主备选举,内部封装了 Zookeeper 的处理逻辑,一旦 Zookeeper 主备选举完成,会回调 ZKFailoverController 的相应方法来进行 NameNode 的主备状态切换。
2、NameNode 的主备切换流程
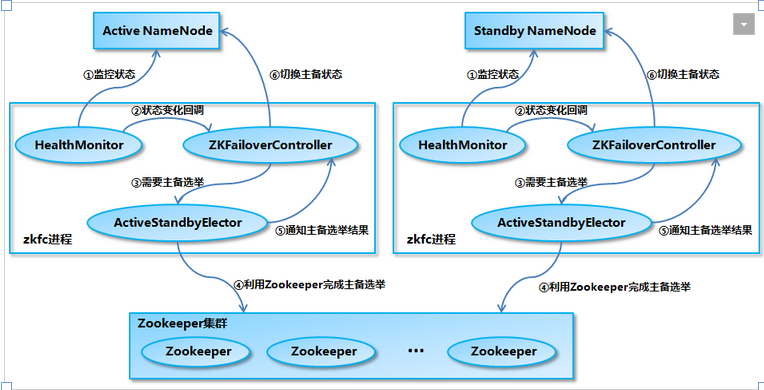
HealthMonitor初始化完成之后会启动内部的线程来定时调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法,对 NameNode 的健康状态进行检测。- HealthMonitor 如果检测到 NameNode 的健康状态发生变化,会回调
ZKFailoverController注册的相应方法进行处理。 - 如果 ZKFailoverController 判断需要进行主备切换,会首先使用
ActiveStandbyElector来进行自动的主备选举。 - ActiveStandbyElector 与 Zookeeper 进行交互完成自动的主备选举。
- ActiveStandbyElector 在主备选举完成后,会回调 ZKFailoverController 的相应方法来通知当前的 NameNode 成为主 NameNode 或备 NameNode。
ZKFailoverController调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法将 NameNode 转换为 Active 状态或 Standby 状态。
三、基于 QJM 的共享存储系统原理分析
过 去几年中 Hadoop 社区涌现过很多的 NameNode 共享存储方案,比如 shared NAS+NFS、BookKeeper、BackupNode 和 QJM(Quorum Journal Manager) 等等。目前社区已经把由 Clouderea 公司实现的基于 QJM 的方案合并到 HDFS 的 trunk 之中并且作为默认的共享存储实现,本部分只针对基于 QJM 的共享存储方案的内部实现原理进行分析。为了理解 QJM 的设计和实现,首先要对 NameNode 的元数据存储结构有所了解。
- 基 于 QJM 的共享存储系统主要用于保存 EditLog,并不保存 FSImage 文件。
- FSImage 文件还是在 NameNode 的本地磁盘上。
- QJM 共享存储的基本思想来自于
Paxos 算法,采用多个称为JournalNode的节点组成的JournalNode集群来存储 EditLog。 - 每个 JournalNode 保存同样的 EditLog 副本。
- 每次 NameNode 写 EditLog 的时候,除了向本地磁盘写入 EditLog 之外,也会并行地向 JournalNode 集群之中的每一个 JournalNode 发送写请求,只要大多数 (majority) 的 JournalNode 节点返回成功就认为向 JournalNode 集群写入 EditLog 成功。
- 如果有 2N+1 台 JournalNode,那么根据大多数的原则,最多可以容忍有 N 台 JournalNode 节点挂掉。
1)QJM 的共享存储系统架构
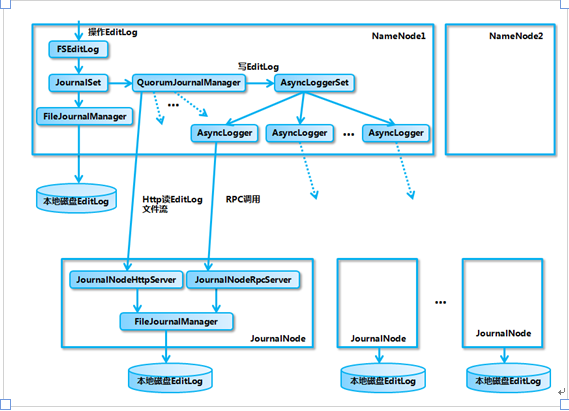
FSEditLog:这个类封装了对 EditLog 的所有操作,是 NameNode 对 EditLog 的所有操作的入口。JournalSet: 这个类封装了对本地磁盘和 JournalNode 集群上的 EditLog 的操作,内部包含了两类JournalManager,一类为 FileJournalManager,用于实现对本地磁盘上 EditLog 的操作。一类为QuorumJournalManager,用于实现对 JournalNode 集群上共享目录的 EditLog 的操作。FSEditLog 只会调用 JournalSet 的相关方法,而不会直接使用 FileJournalManager 和 QuorumJournalManager。FileJournalManager: 封装了对本地磁盘上的 EditLog 文件的操作,不仅 NameNode 在向本地磁盘上写入 EditLog 的时候使用 FileJournalManager,JournalNode 在向本地磁盘写入 EditLog 的时候也复用了 FileJournalManager 的代码和逻辑。QuorumJournalManager:封装了对 JournalNode 集群上的 EditLog 的操作,它会根据 JournalNode 集群的 URI 创建负责与 JournalNode 集群通信的类 AsyncLoggerSet, QuorumJournalManager 通过 AsyncLoggerSet 来实现对 JournalNode 集群上的 EditLog 的写操作,对于读操作,QuorumJournalManager 则是通过 Http 接口从 JournalNode 上的 JournalNodeHttpServer 读取 EditLog 的数据。AsyncLoggerSet:内部包含了与 JournalNode 集群进行通信的 AsyncLogger 列表,每一个 AsyncLogger 对应于一个 JournalNode 节点,另外 AsyncLoggerSet 也包含了用于等待大多数 JournalNode 返回结果的工具类方法给 QuorumJournalManager 使用。AsyncLogger:具体的实现类是 IPCLoggerChannel,IPCLoggerChannel 在执行方法调用的时候,会把调用提交到一个单线程的线程池之中,由线程池线程来负责向对应的 JournalNode 的 JournalNodeRpcServer 发送 RPC 请求。JournalNodeRpcServer:运行在 JournalNode 节点进程中的 RPC 服务,接收 NameNode 端的 AsyncLogger 的 RPC 请求。JournalNodeHttpServer:运行在 JournalNode 节点进程中的 Http 服务,用于接收处于 Standby 状态的 NameNode 和其它 JournalNode 的同步 EditLog 文件流的请求。
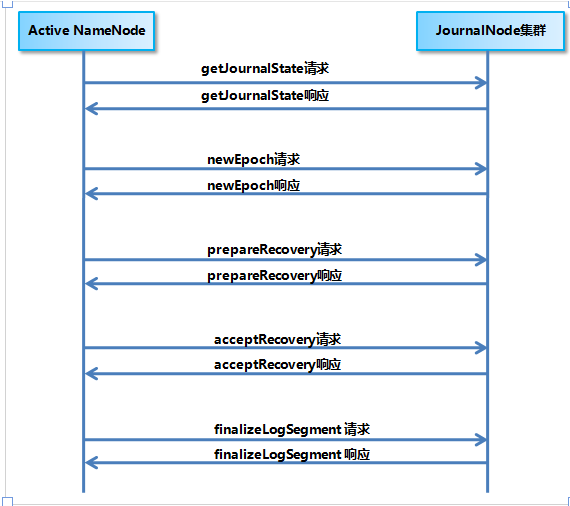
2)QJM 的共享存储系统的数据同步机制
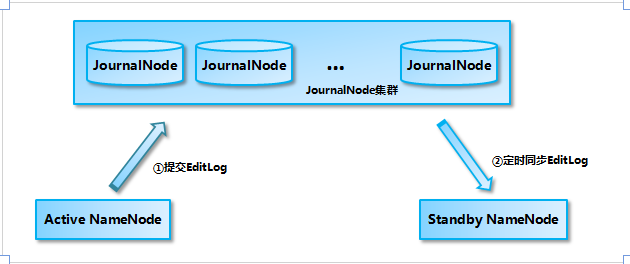
Active NameNode 和 StandbyNameNode 使用 JouranlNode 集群来进行数据同步的过程如下图 所示,Active NameNode 首先把 EditLog 提交到 JournalNode 集群,然后 Standby NameNode 再从 JournalNode 集群定时同步 EditLog:
3)QJM 的共享存储系统的数据恢复机制
处 于 Standby 状态的 NameNode 转换为 Active 状态的时候,有可能上一个 Active NameNode 发生了异常退出,那么 JournalNode 集群中各个 JournalNode 上的 EditLog 就可能会处于不一致的状态,所以首先要做的事情就是让 JournalNode 集群中各个节点上的 EditLog 恢复为一致。另外如前所述,当前处于 Standby 状态的 NameNode 的内存中的文件系统镜像有很大的可能是落后于旧的 Active NameNode 的,所以在 JournalNode 集群中各个节点上的 EditLog 达成一致之后,接下来要做的事情就是从 JournalNode 集群上补齐落后的 EditLog。只有在这两步完成之后,当前新的 Active NameNode 才能安全地对外提供服务。
四、Hadoop YARN HA 架构与原理
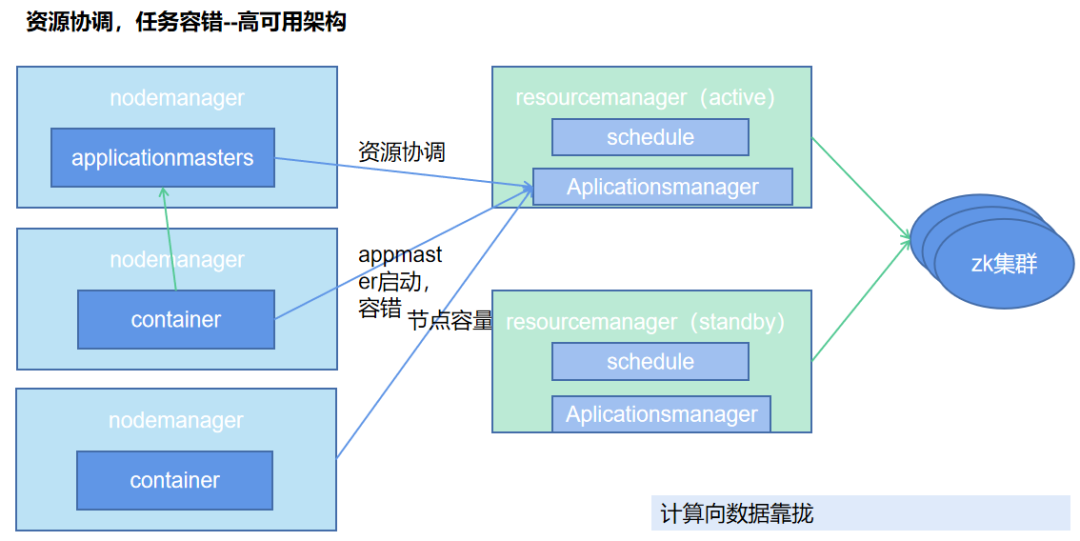
对比一下就会看到,yarn集群的高可用架构比hdfs namenode的要简单太多了,没有zkfc,没有QJM集群,只需要一个zookeeper集群来负责选举出active的resourcemanager就好了。
为什么差别这么大?
- 这就是持久化数据的高可用(HDFS)和无状态高可用(YARN)的区别了;
HDFS的NameNode要保持高可用,必须要保证数据同步,从而需要一个共享存储QJM来存放edits日志,然后同步到standby的节点上去;- 而对于
ResourceManager来说,并不需要持久化啥数据,也就是无状态的,就像容器一样,直接删除,再创建一个完全没问题,所以差别来说,就是因为需要保存一些数据,这就是有状态和无状态之分。
五、Hadoop HA(高可用)实现
如果在开始部署 Hadoop 集群的时候就启用 NameNode 的高可用的话,那么相对会比较容易。但是如果在采用传统的单 NameNode 的架构运行了一段时间之后,升级为 NameNode 的高可用架构的话,就要特别注意在升级的时候需要按照以下的步骤进行操作:
- 对
Zookeeper进行初始化,创建 Zookeeper 上的/hadoop-ha/${dfs.nameservices} 节点。创建节点是为随后通过 Zookeeper 进行主备选举做好准备,在进行主备选举的时候会在这个节点下面创建子节点。这一步通过在原有的 NameNode 上执行命令 hdfs zkfc -formatZK 来完成。 - 启动所有的
JournalNode,这通过脚本命令hadoop-daemon.sh start journalnode来完成。 - 对
JouranlNode集群的共享存储目录进行格式化,并且将原有的 NameNode 本地磁盘上最近一次checkpoint操作生成FSImage文件之后的EditLog拷贝到JournalNode集群上的共享目录之中,这通过在原有的NameNode上执行命令hdfs namenode -initializeSharedEdits来完成。 - 启动原有的 NameNode 节点,这通过脚本命令
hadoop-daemon.sh start namenode完成。
对新增的 NameNode 节点进行初始化,将原有的 NameNode 本地磁盘上最近一次 checkpoint 操作生成 FSImage 文件拷贝到这个新增的 NameNode 的本地磁盘上,同时需要验证 JournalNode 集群的共享存储目录上已经具有了这个 FSImage 文件之后的 EditLog(已经在第 3 步完成了)。这一步通过在新增的 NameNode 上执行命令 hdfs namenode -bootstrapStandby 来完成。 - 启动新增的 NameNode 节点,这通过脚本命令
hadoop-daemon.sh start namenode完成。
在这两个 NameNode 上启动zkfc(ZKFailoverController)进程,谁通过 Zookeeper 选主成功,谁就是主 NameNode,另一个为备 NameNode。这通过脚本命令hadoop-daemon.sh start zkfc完成。
| 主机名 | NameNode | DataNode | Zookeeper | ZKFC | JournalNode | ResourceManager | NodeManager |
|---|---|---|---|---|---|---|---|
| local-168-182-110 | * | * | * | * | * | ||
| local-168-182-111 | * | * | * | * | |||
| local-168-182-112 | * | * | * | * | |||
| local-168-182-113 | * | * | * | * | * |
1)部署Zookeeper
也可以参考我之前的文章:分布式开源协调服务——Zookeeper
1、下载解压
下载地址:https://zookeeper.apache.org/releases.html
cd /opt/bigdata/
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz --no-check-certificate
tar -xf apache-zookeeper-3.8.0-bin.tar.gz
2、配置环境变量
vi /etc/profile
export ZOOKEEPER_HOME=/opt/bigdata/apache-zookeeper-3.8.0-bin/
export PATH=$ZOOKEEPER_HOME/bin:$PATH
# 加载生效
source /etc/profile
3、配置
cd $ZOOKEEPER_HOME
cp conf/zoo_sample.cfg conf/zoo.cfg
mkdir $ZOOKEEPER_HOME/data
cat >conf/zoo.cfg<<EOF
# tickTime:Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。session最小有效时间为tickTime*2
tickTime=2000
# Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。不要使用/tmp目录
dataDir=/opt/bigdata/apache-zookeeper-3.8.0-bin/data
# 端口,默认就是2181
clientPort=2181
# 集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量),超过此数量没有回复会断开链接
initLimit=10
# 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)
syncLimit=5
# 最大客户端链接数量,0不限制,默认是0
maxClientCnxns=60
# zookeeper集群配置项,server.1,server.2,server.3是zk集群节点;hadoop-node1,hadoop-node2,hadoop-node3是主机名称;2888是主从通信端口;3888用来选举leader
server.1=local-168-182-110:2888:3888
server.2=local-168-182-111:2888:3888
server.3=local-168-182-112:2888:3888
EOF
4、配置myid
echo 1 > $ZOOKEEPER_HOME/data/myid
5、将配置推送到其它节点
scp -r $ZOOKEEPER_HOME local-168-182-111:/opt/bigdata/
scp -r $ZOOKEEPER_HOME local-168-182-112:/opt/bigdata/
# 也需要添加环境变量和修改myid,local-168-182-111的myid设置2,local-168-182-112的myid设置3
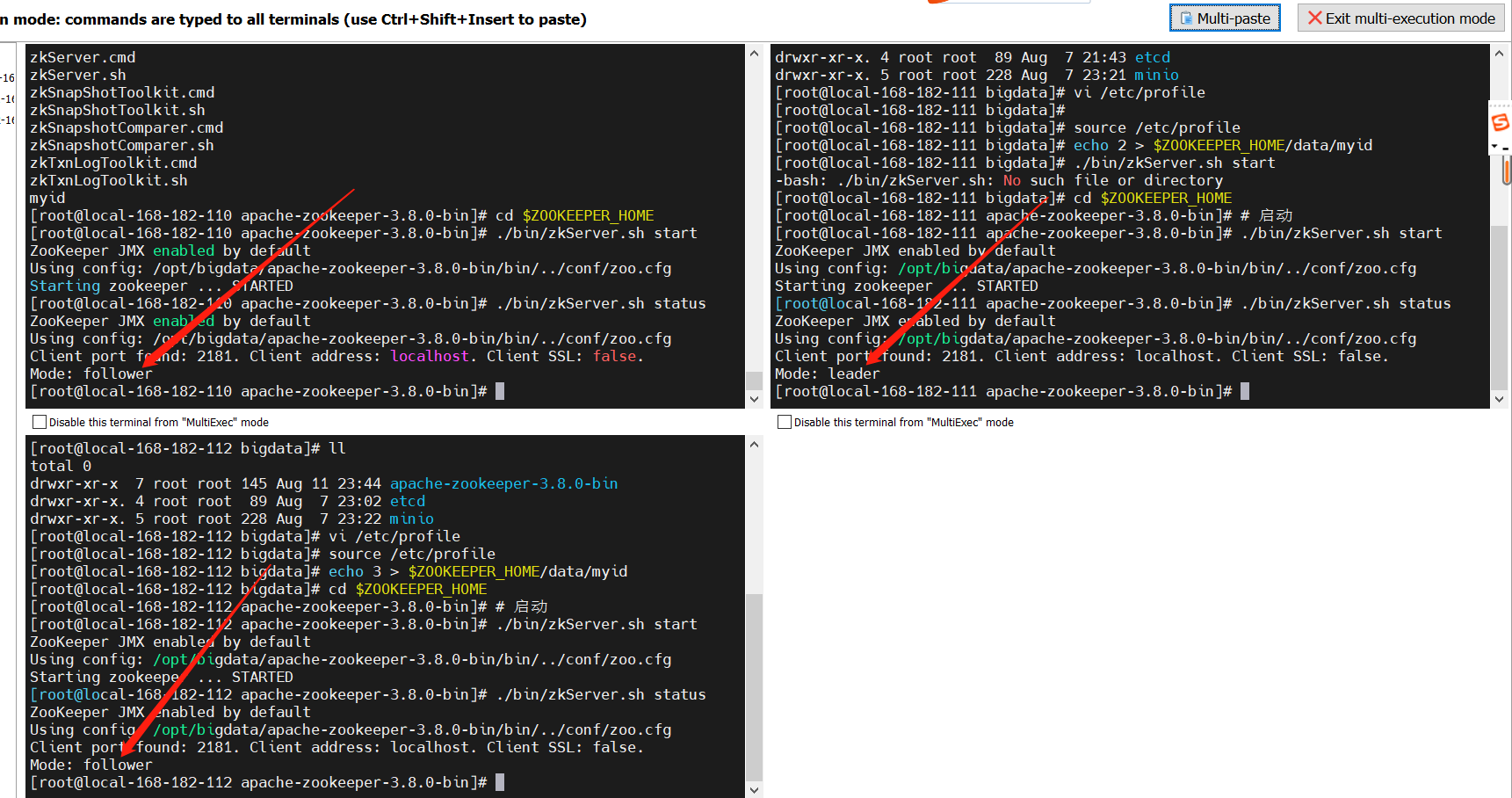
6、启动服务
cd $ZOOKEEPER_HOME
# 启动
./bin/zkServer.sh start
# 查看状态
./bin/zkServer.sh status
2)Hadoop安装
1、下载解压
下载地址:https://dlcdn.apache.org/hadoop/common/
mkdir -p /opt/bigdata/hadoop && cd /opt/bigdata/hadoop
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz --no-check-certificate
# 解压
tar -zvxf hadoop-3.3.4.tar.gz
2、HDFS HDFS高可用配置
- 配置环境变量
vi /etc/profile
export HADOOP_HOME=/opt/bigdata/hadoop/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 加载生效
source /etc/profile
- 修改
$HADOOP_HOME/etc/hadoop/hadoop-env.sh
# 在hadoop-env.sh文件末尾追加
export JAVA_HOME=/opt/jdk1.8.0_212
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- 修改
$HADOOP_HOME/etc/hadoop/core-site.xml#核心模块配置
# 创建存储目录
mkdir -p /opt/bigdata/hadoop/hadoop-3.3.4/data/namenode
mkdir -p /opt/bigdata/hadoop/hadoop-3.3.4/data/journalnode
<configuration>
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://myhdfs</value>
</property>
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop/hadoop-3.3.4/data/namenode</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>local-168-182-110:2181,local-168-182-111:2181,local-168-182-112:2181</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 配置该root允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!-- 配置该root允许代理的用户所属组 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 配置该root允许代理的用户 -->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
<!-- 对于每个<root>用户,hosts必须进行配置,而groups和users至少需要配置一个。-->
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
- 修改
$HADOOP_HOME/etc/hadoop/hdfs-site.xml#hdfs文件系统模块配置
<configuration>
<!-- 为namenode集群定义一个services name,默认值:null -->
<property>
<name>dfs.nameservices</name>
<value>myhdfs</value>
</property>
<!-- 说明:nameservice 包含哪些namenode,为各个namenode起名,默认值:null,比如这里设置的nn1, nn2 -->
<property>
<name>dfs.ha.namenodes.myhdfs</name>
<value>nn1,nn2</value>
</property>
<!-- 说明:名为nn1的namenode 的rpc地址和端口号,rpc用来和datanode通讯,默认值:9000,local-168-182-110为节点hostname-->
<property>
<name>dfs.namenode.rpc-address.myhdfs.nn1</name>
<value>local-168-182-110:8082</value>
</property>
<!-- 说明:名为nn2的namenode 的rpc地址和端口号,rpc用来和datanode通讯,默认值:9000,local-168-182-113为节点hostname-->
<property>
<name>dfs.namenode.rpc-address.myhdfs.nn2</name>
<value>local-168-182-113:8082</value>
</property>
<!-- 说明:名为nn1的namenode 的http地址和端口号,web客户端 -->
<property>
<name>dfs.namenode.http-address.myhdfs.nn1</name>
<value>local-168-182-110:9870</value>
</property>
<!-- 说明:名为nn2的namenode 的http地址和端口号,web客户端 -->
<property>
<name>dfs.namenode.http-address.myhdfs.nn2</name>
<value>local-168-182-113:9870</value>
</property>
<!-- 说明:namenode间用于共享编辑日志的journal节点列表 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://local-168-182-110:8485;local-168-182-111:8485;local-168-182-112:8485/myhdfs</value>
</property>
<!-- 说明:客户端连接可用状态的NameNode所用的代理类,默认值:org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider -->
<property>
<name>dfs.client.failover.proxy.provider.myhdfs</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 说明:HDFS的HA功能的防脑裂方法。可以是内建的方法(例如shell和sshfence)或者用户定义的方法。
建议使用sshfence(hadoop:9922),括号内的是用户名和端口,注意,这需要NN的2台机器之间能够免密码登陆
fences是防止脑裂的方法,保证NN中仅一个是Active的,如果2者都是Active的,新的会把旧的强制Kill
-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 指定上述选项ssh通讯使用的密钥文件在系统中的位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 说明:失效转移时使用的秘钥文件。 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/bigdata/hadoop/hadoop-3.3.4/data/journalnode</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.myhdfs</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 设置数据块应该被复制的份数,也就是副本数,默认:3 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 说明:是否开启权限检查 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
修改$HADOOP_HOME/etc/hadoop/workers
将下面内容覆盖文件,默认只有localhost,works配置的为
DataNode节点的主机名或IP,如果配置了works文件,并且配置ssh免密登录,可以使用 start-dfs.sh 启动 HDFS集群
local-168-182-111
local-168-182-112
local-168-182-113
3、YARN ResourceManager高可用配置
- 修改
$HADOOP_HOME/etc/hadoop/yarn-site.xml#yarn模块配置
<configuration>
<!--开启ResourceManager HA功能-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--标志ResourceManager-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>myyarn</value>
</property>
<!--集群中ResourceManager的ID列表,后面的配置将引用该ID-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 设置YARN集群主角色运行节点rm1-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>local-168-182-110</value>
</property>
<!-- 设置YARN集群主角色运行节点rm2-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>local-168-182-113</value>
</property>
<!--ResourceManager1的Web页面访问地址-->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>local-168-182-110:8088</value>
</property>
<!--ResourceManager2的Web页面访问地址-->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>local-168-182-113:8088</value>
</property>
<!--ZooKeeper集群列表-->
<property>
<name>hadoop.zk.address</name>
<value>local-168-182-110:2181,local-168-182-111:2181,local-168-182-112:2181</value>
</property>
<!--启用ResouerceManager重启的功能,默认为false-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--用于ResouerceManager状态存储的类-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://local-168-182-110:19888/jobhistory/logs</value>
</property>
<!-- 设置yarn历史日志保存时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604880</value>
</property>
</configuration>
- 修改
$HADOOP_HOME/etc/hadoop/ mapred-site.xml#MapReduce模块配置
<configuration>
<!-- 设置MR程序默认运行模式,yarn集群模式,local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>local-168-182-110:10020</value>
</property>
<!-- MR程序历史服务web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>local-168-182-110:19888</value>
</property>
<!-- yarn环境变量 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- map环境变量 -->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- reduce环境变量 -->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
4、分发配置文件其它节点
scp -r $HADOOP_HOME local-168-182-111:/opt/bigdata/hadoop/
scp -r $HADOOP_HOME local-168-182-112:/opt/bigdata/hadoop/
scp -r $HADOOP_HOME local-168-182-113:/opt/bigdata/hadoop/
# 注意在其它节点先创建/opt/bigdata/hadoop/和环境变量
5、启动服务
1)启动HDFS相关服务
- 启动
journalnode
# 在local-168-182-110、local-168-182-111、local-168-182-112机器上启动
hdfs --daemon start journalnode
- HDFS
NameNode数据同步
# 格式化(第一次配置情况下使用,已运行集群不能用),在local-168-182-110执行
hdfs namenode -format
- 共享日志文件初初始化(已运行的非HA集群使用,这里不执行)
hdfs namenode -initializeSharedEdits
- 启动
local-168-182-110上的NameNode节点
hdfs --daemon start namenode
local-168-182-113节点同步镜像数据
hdfs namenode -bootstrapStandby
local-168-182-113节点上启动NameNode
hdfs --daemon start namenode
- zookeeper FailerController格式化
# 在local-168-182-110上执行
hdfs zkfc -formatZK
- namenode节点安装psmisc(ZKFC主机)
# 在local-168-182-110,local-168-182-113上执行,ZKFC远程杀死假死SNN使用的killall namenode命令属于psmisc软件中的。建议所有节点都安装psmisc。
yum install -y psmisc
- 添加环境变量
~/.bash_profile,记得source 加载
# 或者在start-dfs.sh,stop-dfs.sh(在hadoop安装目录的sbin里)两个文件顶部添加以下参数
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_ZKFC_USER=root
2)启动YARN相关服务
- 启动
hdfs
# 在local-168-182-110节点上执行
start-dfs.sh
- 验证hdfs
jps
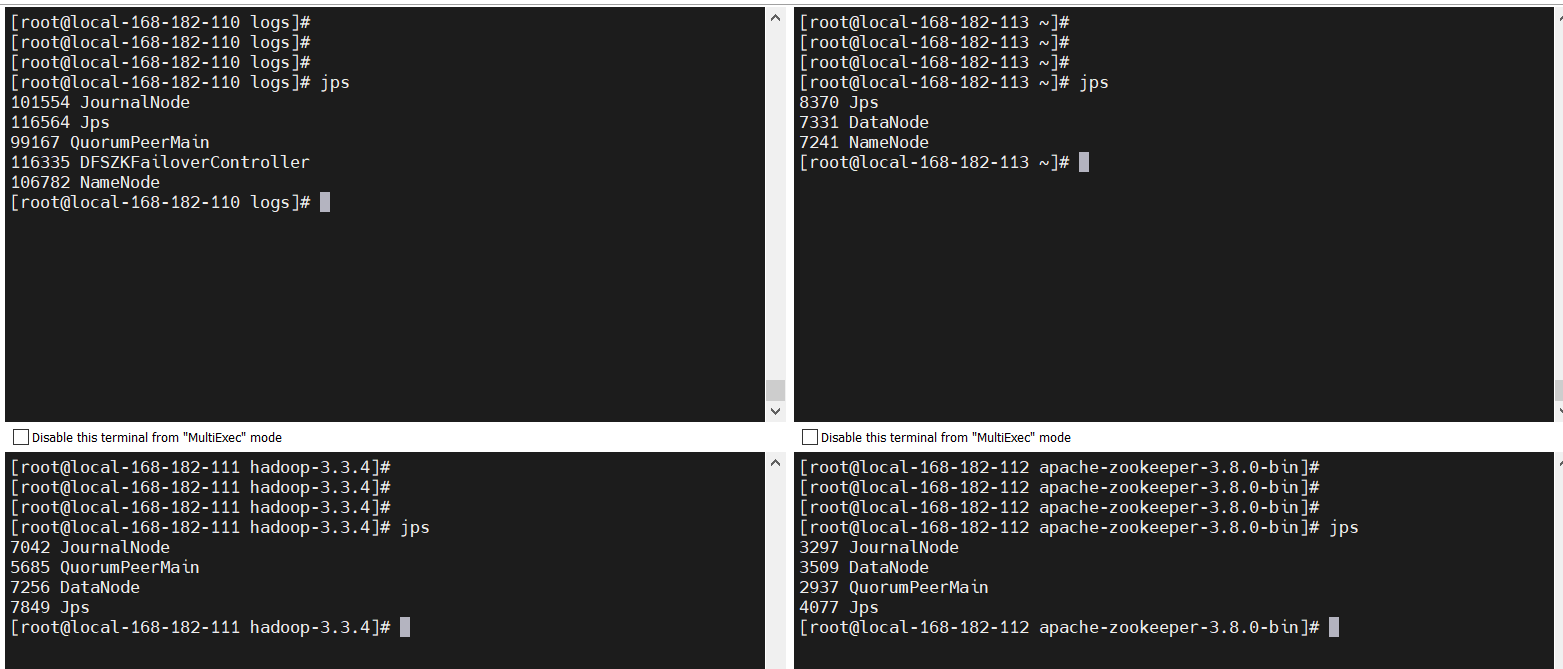
web地址:
http://local-168-182-110:9870/
http://local-168-182-113:9870/
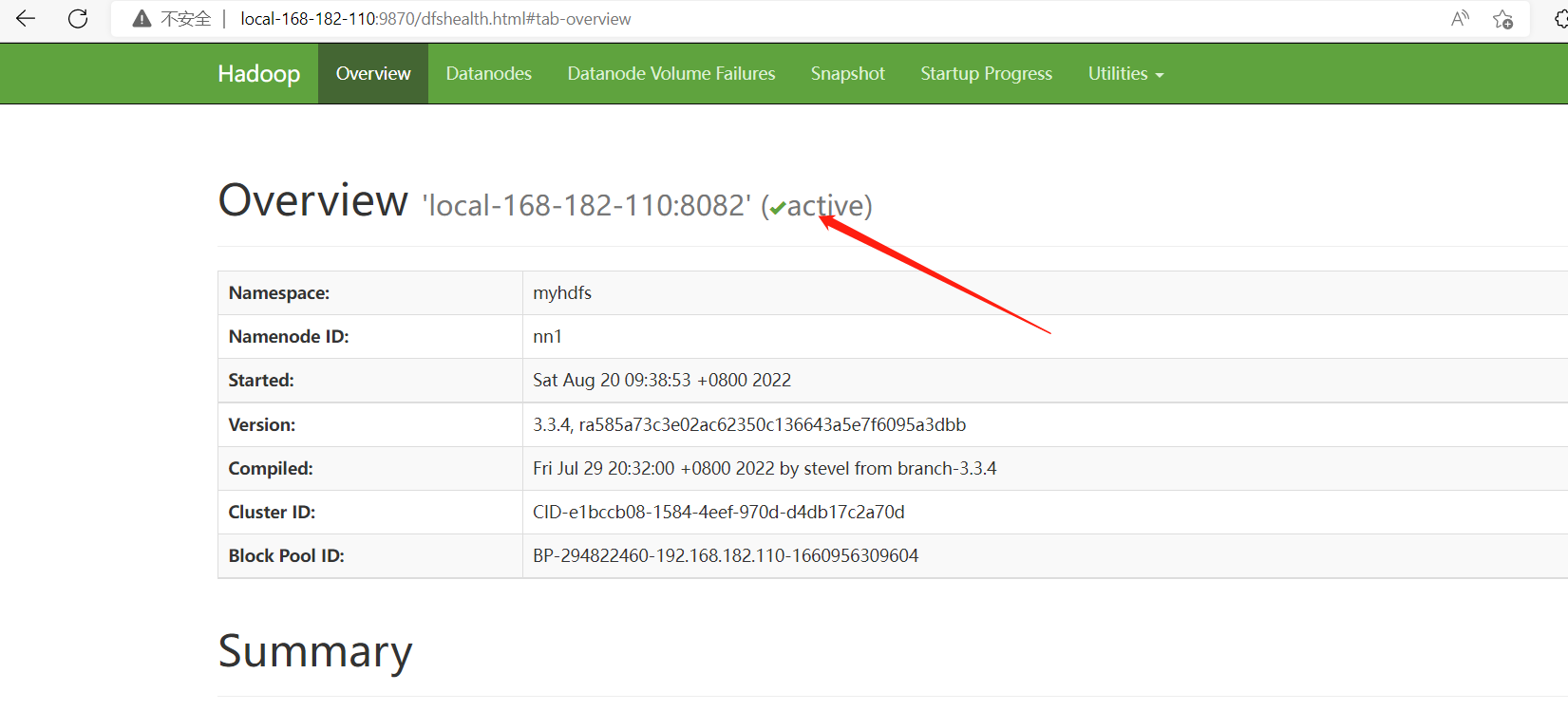
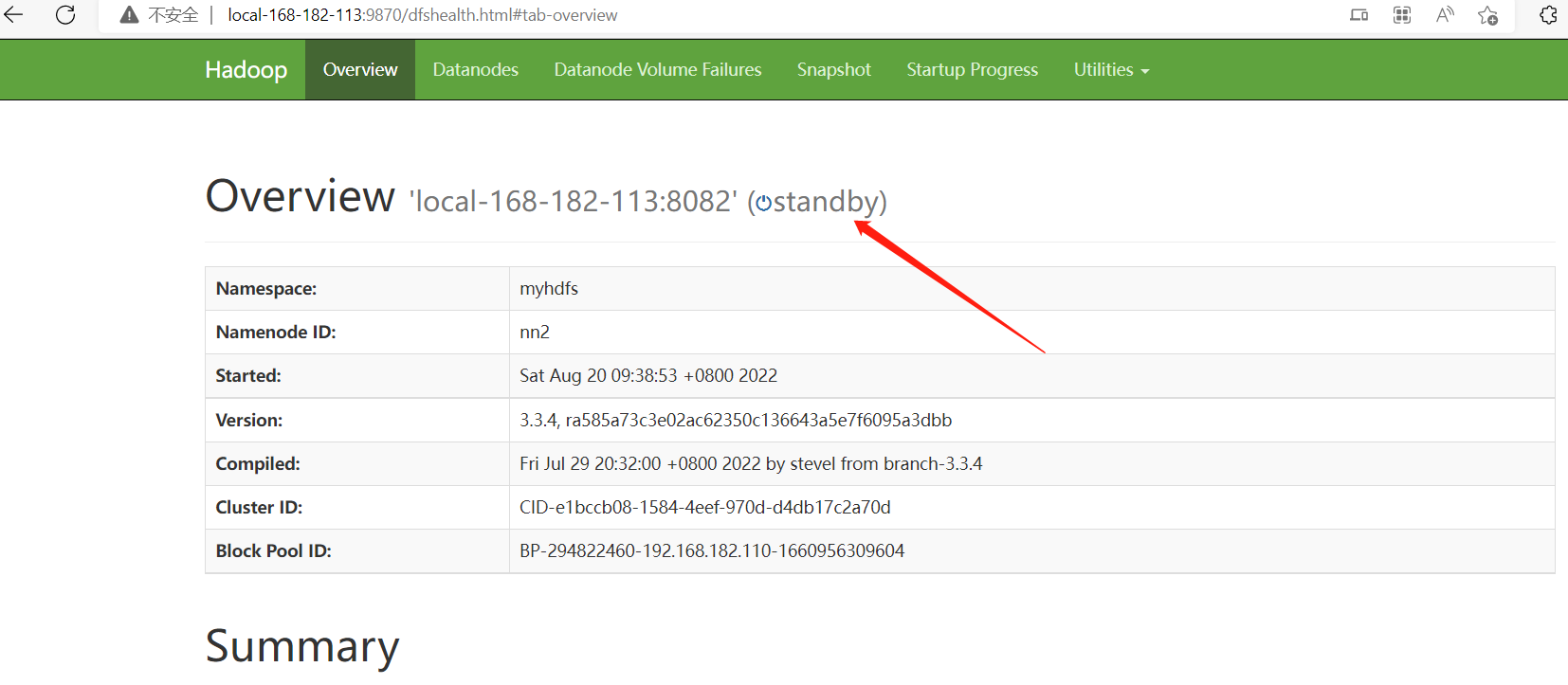
- 启动
yarn
start-yarn.sh
jps
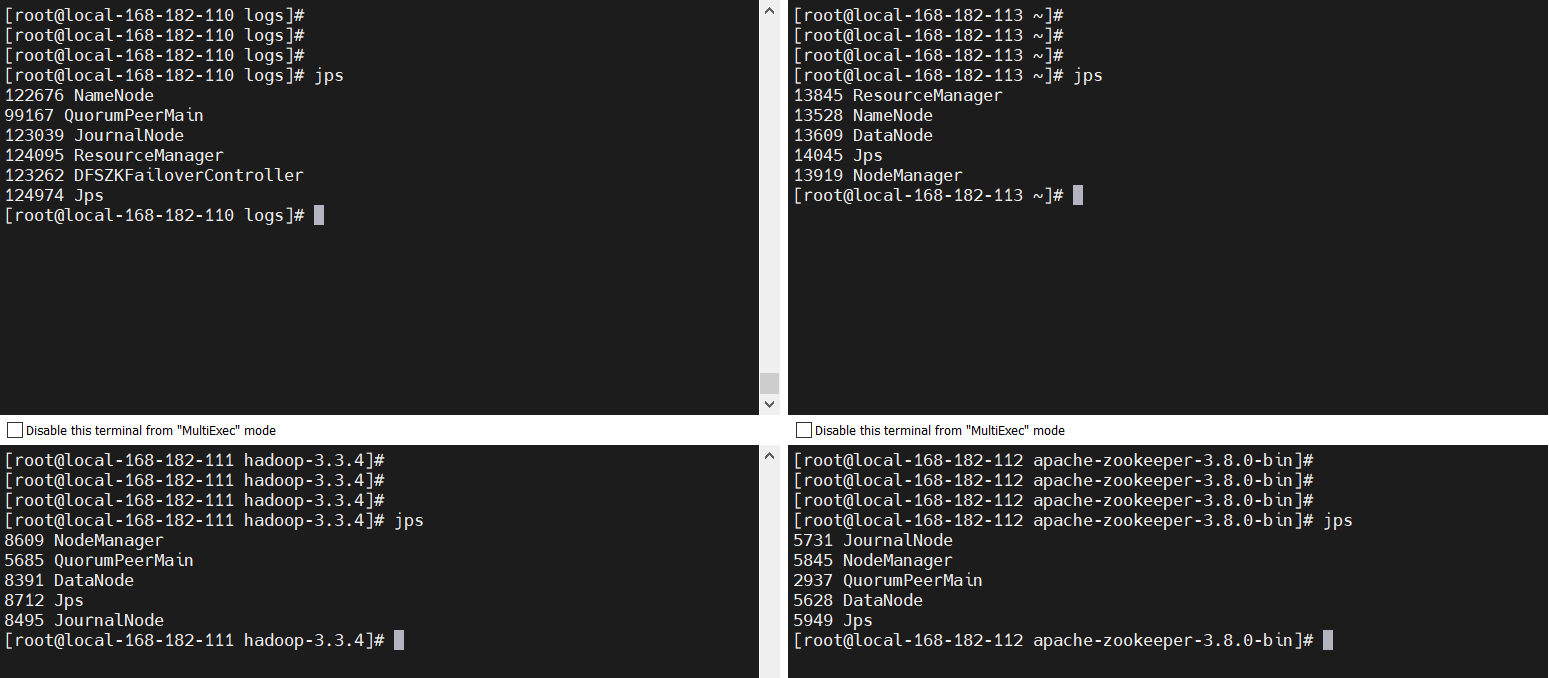
web地址:
http://local-168-182-110:8088/cluster/cluster
http://local-168-182-113:8088/cluster/cluster
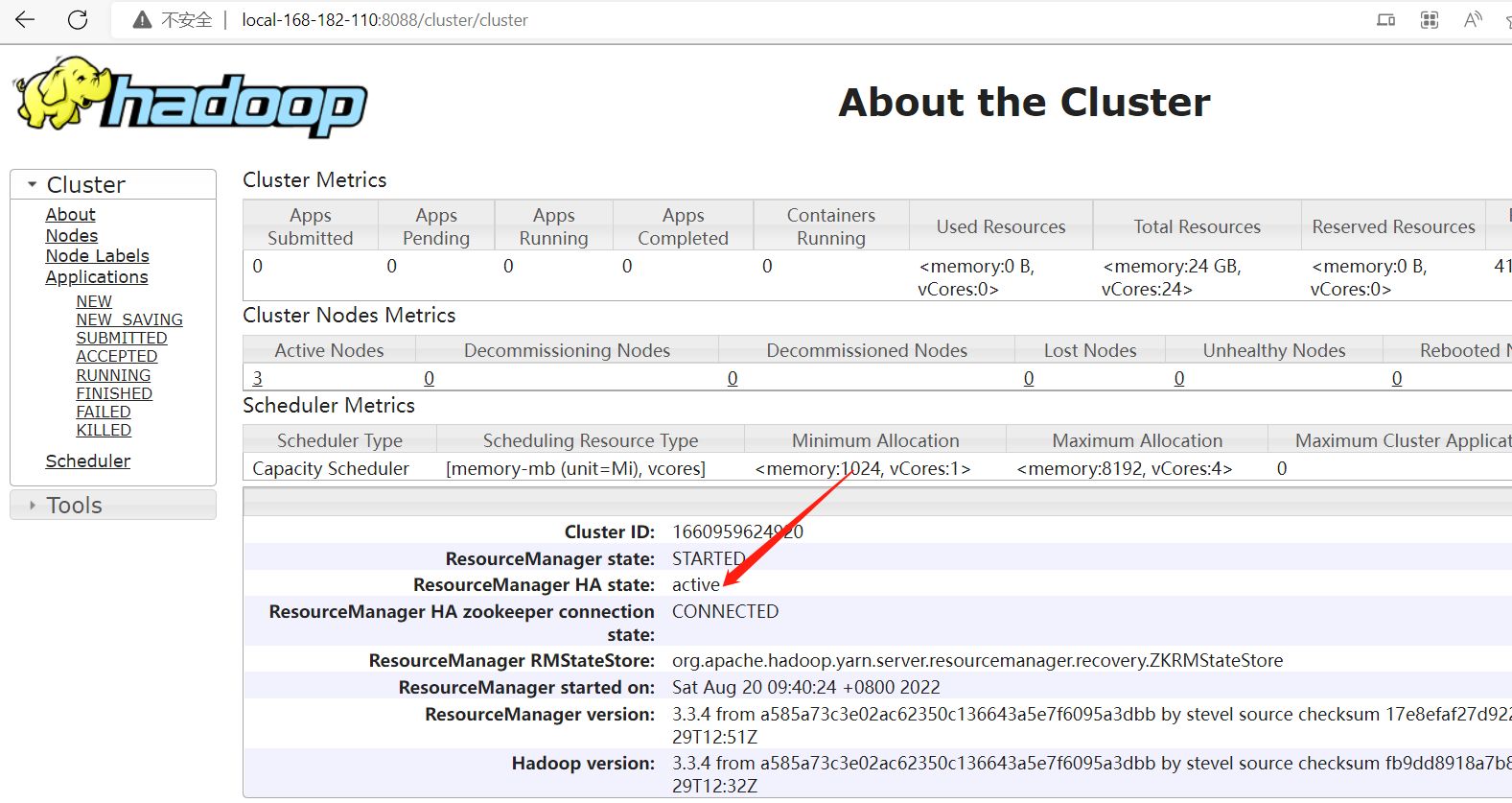
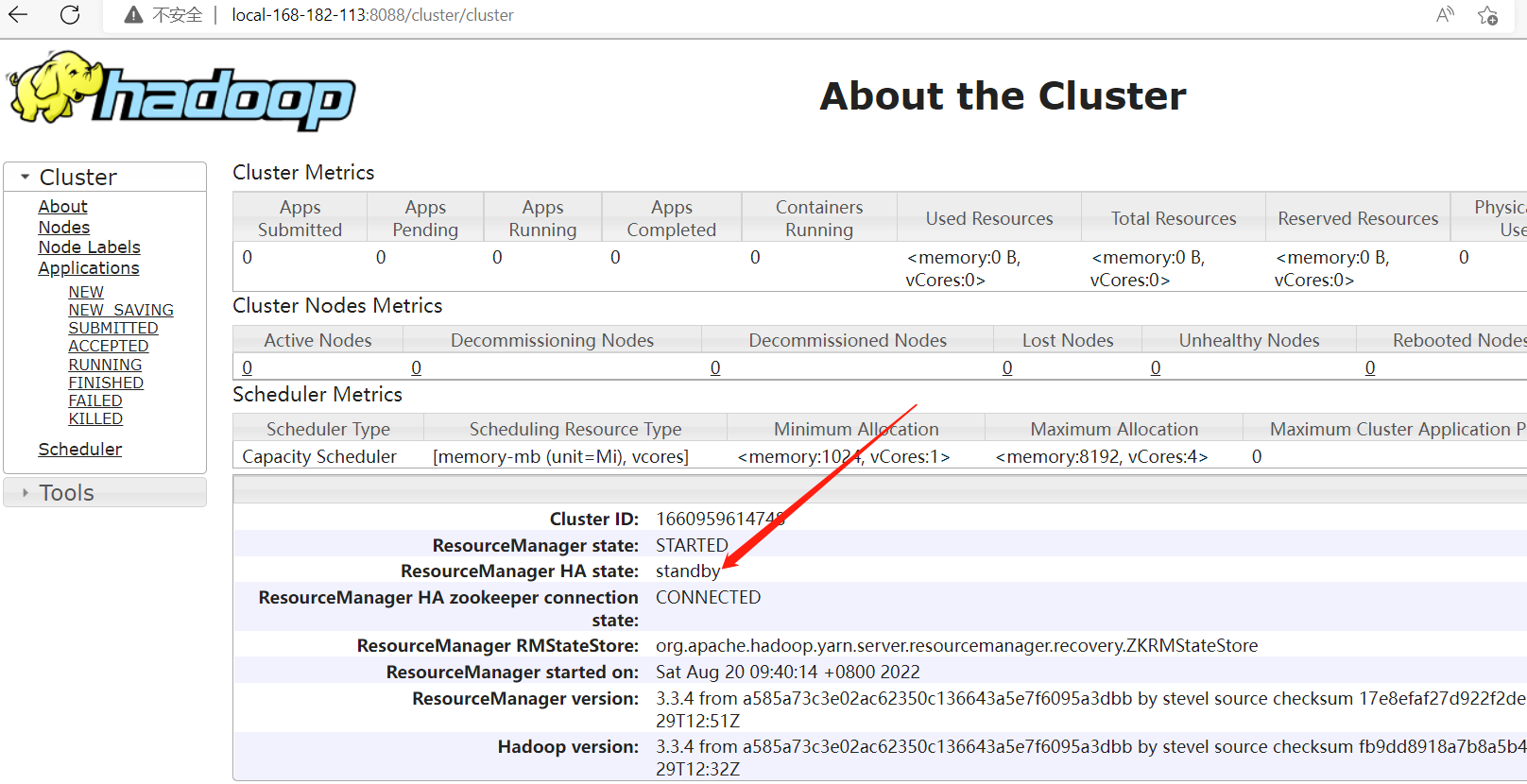
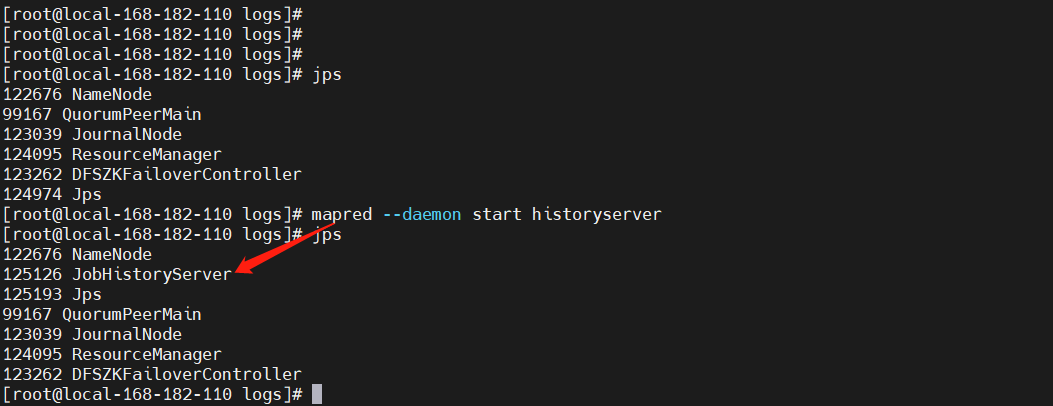
- 启动mapreduce任务历史服务
mapred --daemon start historyserver
五、Hadoop HA(高可用)测试验证
1)Hadoop HDFS NameNode HA 验证
1、查看NameNode节点状态
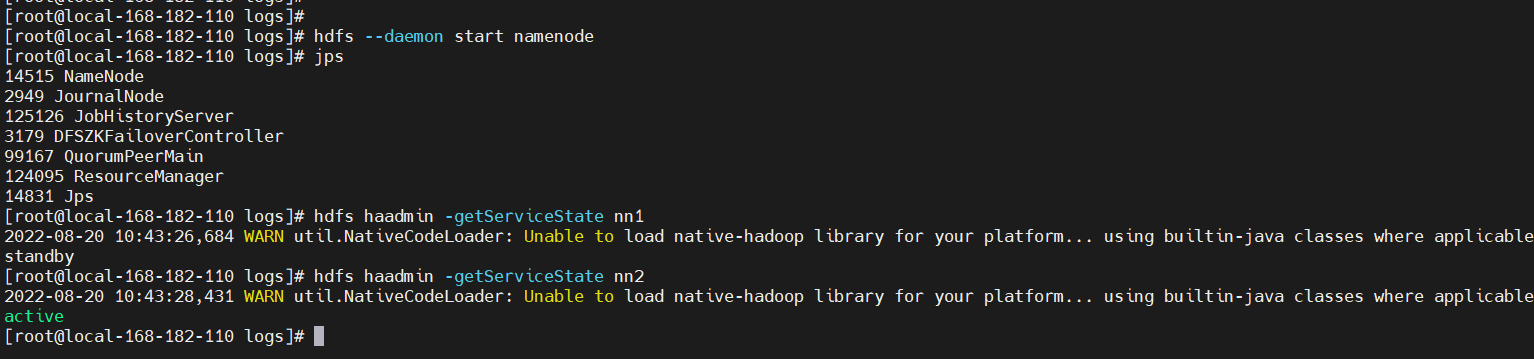
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
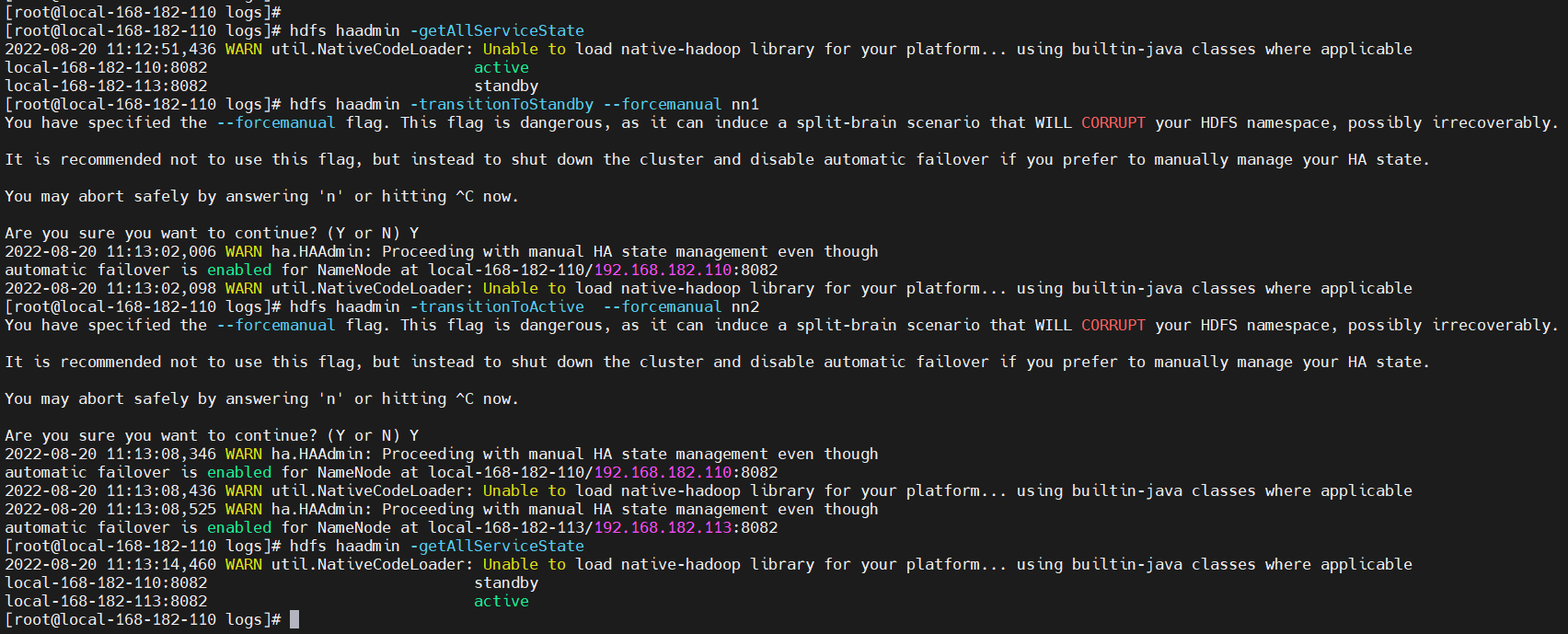
2、手动切换主备
# 设置nn1为Standby,nn2为Active
# 当HDFS的HA配置中开启了自动故障转移时,需加上--forcemanual参数(谨慎使用此参数)
hdfs haadmin -transitionToStandby --forcemanual nn1
hdfs haadmin -transitionToActive --forcemanual nn2
# 查看
#hdfs haadmin -getServiceState nn1
#hdfs haadmin -getServiceState nn2
# 查看所有节点状态
hdfs haadmin -getAllServiceState
# 设置nn1为Active,nn1为Standby
# 当HDFS的HA配置中开启了自动故障转移时,需加上--forcemanual 参数(谨慎使用此参数)
hdfs haadmin -transitionToActive --forcemanual nn1
hdfs haadmin -transitionToStandby --forcemanual nn2
# 查看
#hdfs haadmin -getServiceState nn1
#hdfs haadmin -getServiceState nn2
# 查看所有NameNode节点状态
hdfs haadmin -getAllServiceState
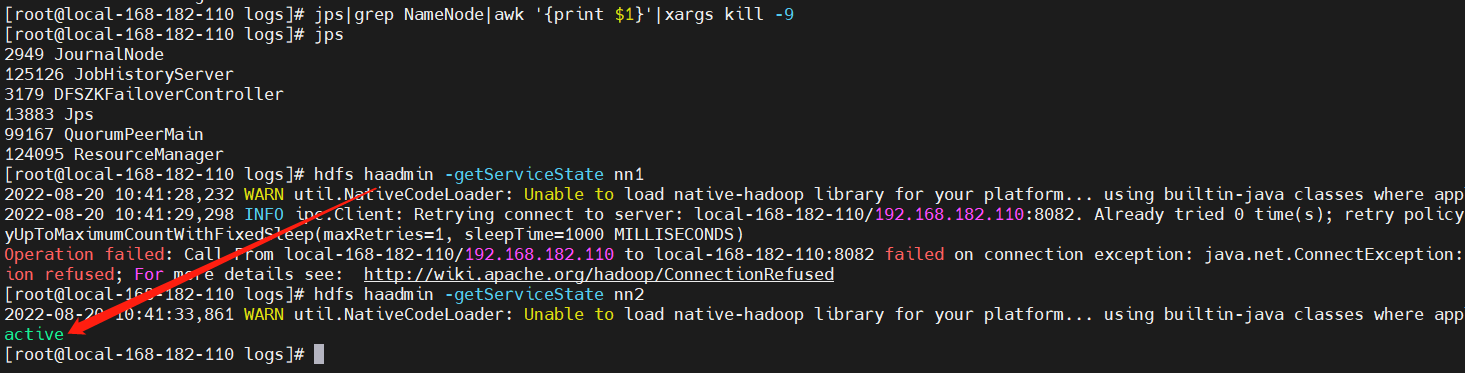
3、故障模拟测试
在active的NameNode节点上,kill掉NameNode进程:
jps
jps|grep NameNode|awk '{print $1}'|xargs kill -9
jps
# 再查看节点状态
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
# 查看所有NameNode节点状态
hdfs haadmin -getAllServiceState
4、故障恢复
# 启动namenode
hdfs --daemon start namenode
jps
# 查看节点状态
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
# 查看所有NameNode节点状态
hdfs haadmin -getAllServiceState
2)Hadoop YARN ResourceManager HA 验证
1、查看ResourceManager节点状态
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
2、手动切换主备
# 设置rm1为Standby,设置rm2为Active
# 当YARN的HA配置中开启了自动故障转移时,需加上-forcemanual 参数(谨慎使用此参数)
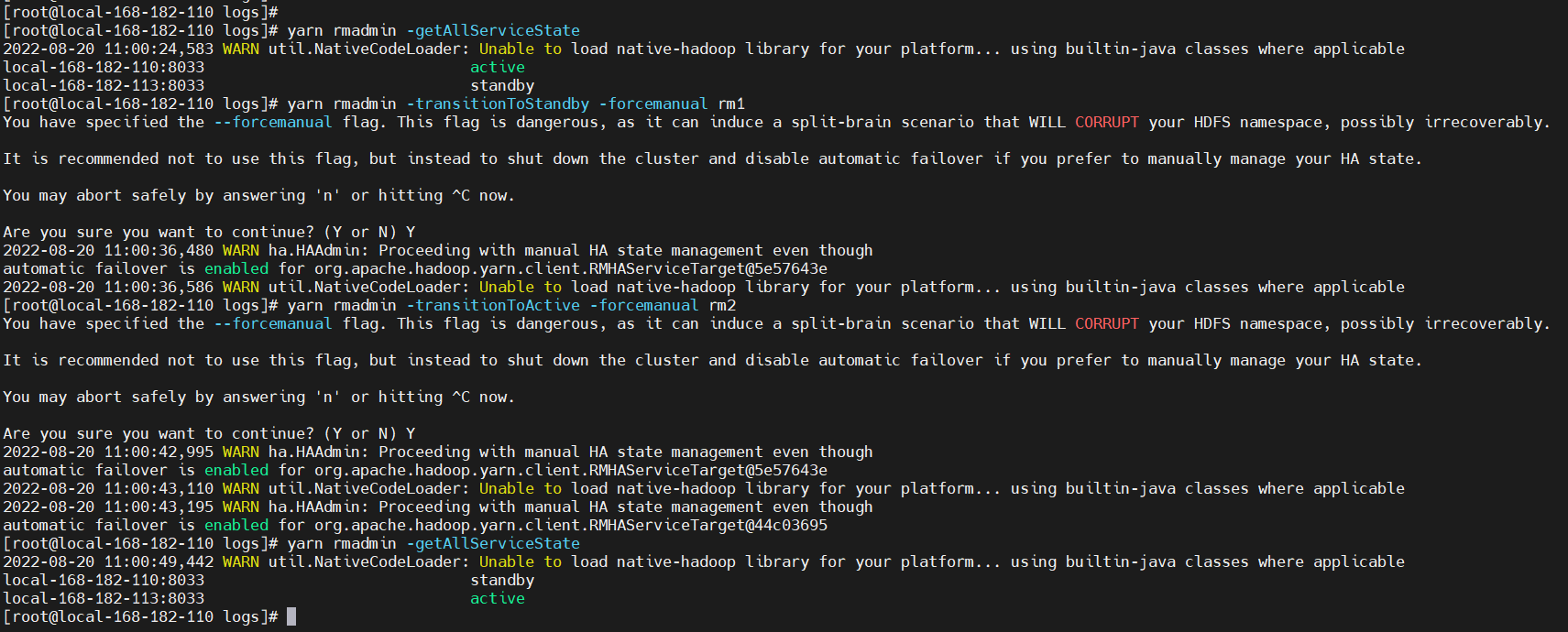
yarn rmadmin -transitionToStandby -forcemanual rm1
yarn rmadmin -transitionToActive -forcemanual rm2
# 查看
#yarn rmadmin -getServiceState rm1
#yarn rmadmin -getServiceState rm2
yarn rmadmin -getAllServiceState
# 设置rm1为Active,设置rm2为Standby
# 当YARN的HA配置中开启了自动故障转移时,需加上-forcemanual 参数
yarn rmadmin -transitionToActive -forcemanual rm1
yarn rmadmin -transitionToStandby -forcemanual rm2
# 查看所有ResourceManager节点状态
yarn rmadmin -getAllServiceState
3、故障模拟测试
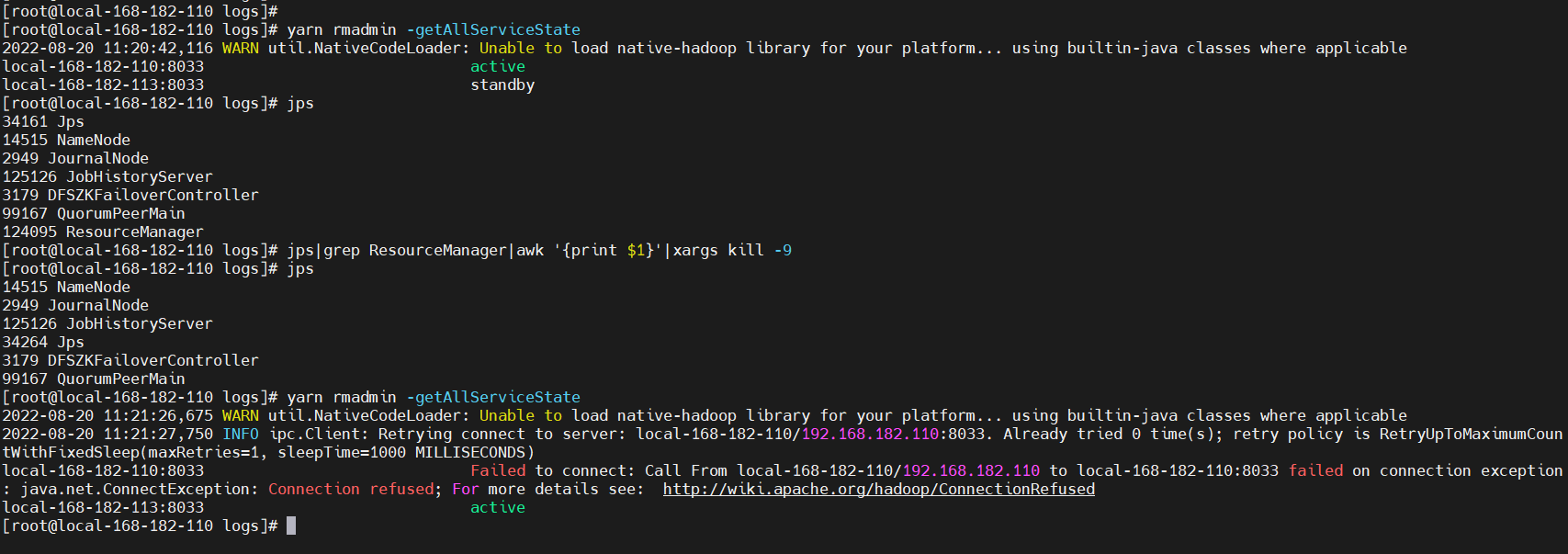
在active的ResourceManager节点上,kill掉ResourceManager进程:
yarn rmadmin -getAllServiceState
jps
jps|grep ResourceManager|awk '{print $1}'|xargs kill -9
jps
# 再查看节点状态
#yarn rmadmin -getServiceState rm1
#yarn rmadmin -getServiceState rm2
# 查看所有ResourceManager节点状态
yarn rmadmin -getAllServiceState
4、故障恢复
yarn --daemon start resourcemanager
jps
# 查看所有ResourceManager节点状态
yarn rmadmin -getAllServiceState

Hadoop 3.3.4 HA(高可用)原理与实现就先到这里了,有疑问的小伙伴欢迎给我留言哦,后面会持续更新关于大数据方面的文章,请小伙伴耐心等待~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号