

java集合-HashMap
大纲:
- 数据结构
- 主要成员变量
- 主要方法
- 补充
- ConcurrentHashMap
一、数据结构
1.1Node节点
static class Node<K,V> implements Map.Entry<K,V> { final int hash;//key的hash值 final K key; V value; Node<K,V> next; //下一个node结点 }
HashMap单链表节点。
java8还新增了树结点、这里暂不讨论树化。
1.2table数组
transient Node<K,V>[] table;
HashMap中一个table数组存放Node链表头结点
这个数组+链表,组成了HashMap的内部结构。
1.3HashMap结构示意图,图中黑点为Node节点。
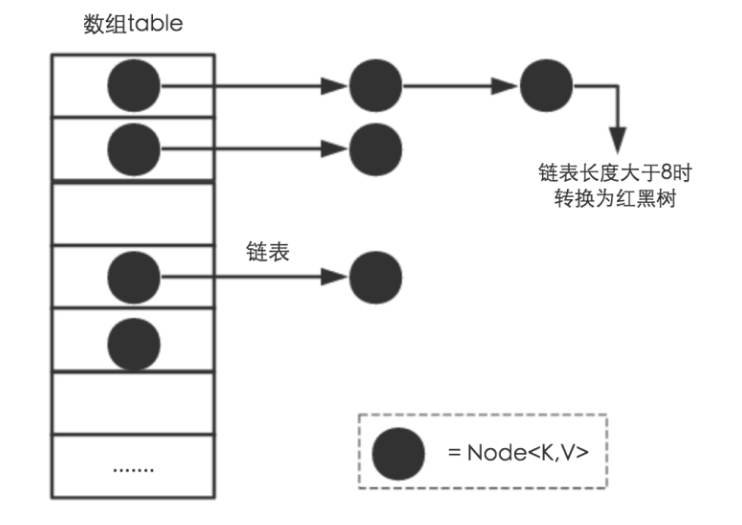
二、主要成员变量
/** * HashMap默认参数 */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //默认table数组大小16。 static final float DEFAULT_LOAD_FACTOR = 0.75f; //默认装载因子。 static final int MAXIMUM_CAPACITY = 1 << 30; //默认数组最大容量。 static final int TREEIFY_THRESHOLD = 8; //默认树化最小节点数。 static final int UNTREEIFY_THRESHOLD = 6;//默认链表化最大节点数,当树的节点数减少到这个数字的时候则将树链表化。 static final int MIN_TREEIFY_CAPACITY = 64; //默认树化时,最小数组数量。当数组数量大于这个值时,才会出现节点链表转成红黑树,小于等于这个值时直接扩容。 /** * 主要成员变量 */ transient Node<K,V>[] table;//哈希桶数组,存放一个个链表的数组。参考1.3中图。默认大小16。 transient Set<Map.Entry<K,V>> entrySet;//Entry集合。 transient int size;//键值对数量。 transient int modCount;//hashMap被修改的次数,比如put,remove。用于迭代器操作中,如果hashMap被修改,则抛出异常,快速失败。 //装载因子。默认0.75。 final float loadFactor; //当前装载因子下算出的允许键值对的最大容量,超过这个量则table扩容。threshold=loadFactor*size int threshold;
三、重要函数
3.1构造函数
public HashMap() //空参,装载因子和容量都为默认值。 public HashMap(int initialCapacity) //指定容量,内部会计算得到一个大于等于指定容量值的2的次方数(table数组的数量一定是2的次方)。 public HashMap(int initialCapacity, float loadFactor) //指定容量,指定装载因子,但不建议修改装载因子,0.75是经验值,已经权衡时间和空间的结果。
3.2hash与node位置
hash:
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
根据key运算hash值
1.(h = key.hashCode())获取key的hashcode
2.将hashcode右移16位,异或上原来的hashcode。这样可以使高16位的hashcode也参与到运算当中。
node下标计算:
put操作首先要确定node存放在table数组的位置,table.length-1时一个掩码,和hash与运算得到0-table.length-1之间的值。
tab[i = (n - 1) & hash] //(n - 1) & hash就是计算数组下标 ,tab是table、n是table.length
3.3put
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; //桶数组为空则扩容。 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; //根据key的hash值计算对应的桶数组下标 //检查对应桶数组该下标位置是否为null,为null则新增一个node,不为null进入下面else部分 if ((p = tab[i = (n - 1) & hash]) == null) //p节点为table对应下标的节点 tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; //头结点的hash与插入node的hash相同,头结点赋值给e。
//在后面判断这个e是否为null,不为null说明同key(hashcode相同,key相等) if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //如果p节点为红黑树则进行树插入,有hash相同的节点就返回hash相同的节点 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { //遍历链表所有节点 for (int binCount = 0; ; ++binCount) { //p节点下一个节点赋值给e //如果p的下一个节点为空,p为链表尾部,尾插一个节点,break,此时e为null if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) //树化 treeifyBin(tab, hash); break; } //e的hash与新插入的相同,break if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; //下一个节点 p = e; } } //已经存在的key-value对的key的hash和本次插入的相等,e为老节点 //1.覆盖原有的key的value //2.返回老值 if (e != null) { V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; //iterator用的 //当key-value个数超出threshod则扩容 if (++size > threshold) resize(); afterNodeInsertion(evict); //LinkedHashMap用的 return null; }
put流程:
- 桶数组为空,初始化数组。
- 根据key计算桶数组位置,这个位置为空,则直接插入一个节点。
- 若不为空,进入插入链表(尾插)和插入树的流程。
- 若在遍历链表的过程中发生相同key(hashcode && equals),将原来节点的value替换为新的value,将老的value返回。
- key为null存在table[0]
3.4resize
final Node<K,V>[] resize() { //初始化table部分略,计算成员变量略... Node<K,V>[] oldTab = table; Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//newCap为原来数组长度2倍 table = newTab; if (oldTab != null) { //遍历旧数组 for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap);//树操作 else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; //(e.hash & oldCap) == 0,注意这里是&oldCap。计算下标的时候是位运算,而且数组长度为2的n次。 // 因此oldCap二进制为00000001、00000010、00000100这样的形式,结合上面章节计算&lenth-1就能明白,这个操作是判断新增的一位是不是0。 // 如果是0表示,下标不变,是1,表示下标为(j+oldCap) if ((e.hash & oldCap) == 0) {//下标不变的 if (loTail == null)//数组第j个位置第一次插入,记录头 loHead = e; else loTail.next = e;//尾插法 loTail = e;//记录tail } else {//下标变的 if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null;//有些非尾节点可能被排到尾节点,所以他们next置为null newTab[j] = loHead; } //同上 if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead;//下标为(j+oldCap),这个是位运算的结果 } } } } } return newTab; }
resize流程:
- 重新计算主要成员变量。
- 新建长度为原来2倍的数组。
- 每个结点下标重新计算,要么在原位,要么在原位置+扩容前数组长度。(位置计算时(n-1)&hash,注意n是2的n次,n-1转化位2进制就是一个全1的数,n-1是掩码,那么resize后相当于掩码多了一位,这样和原来的hash与运算,区别就是多出来的这1位要么是0要么是1)
- 尾插法重新将节点插入对应位置,这里暂不讨论树节点的变化。
四、补充
- 尾插法是java1.8优化的,1.7用的是头插法,并发resize有概率变成死链,假设一个桶有2个结点(node1->node2),线程1判断要resize,拿到链表后交出执行权,线程2判断要resize,将这个桶中的2个结点头插到新位置,变成(node2->node1),这时线程1重新获得执行权,持有原来的链表再次resize头插到新位置形成(node1->node2->node1)死链。
- 红黑树的特性:
- 根节点是黑色。
- 每个叶子节点(NIL)是黑色。
- 如果一个节点是红色的,则它的子节点必须是黑色的。
- 任意结点到叶子结点的路径上包含相同数量的黑结点
- 从根结点到叶子结点的最大路径不能多于2倍最短路径
五、ConcurrentHashMap
重要变量:
- sizeCtl:0entry数组没有初始化(entry是懒加载);-1正在初始化;小于-1正在扩容,-(n+1),有n个线程正在帮助扩容;大于0,初始化前表示初始化容量,初始化后表示扩容阈值。
- forward结点:在扩容的时候把forward结点放置在头结点上表示数组下标上的结点已经完成迁移,且数组正在扩容。forward结点通过特殊的hashcode值来标识。
主要方法:
- 初始化:put的时候会检查entry是否未初始化,如果未初始化sizeCtl cas置-1,开始初始化,这时有并发进来发现sizeCtl是-1,或cas失败,调用yield让出线程执行权。
- put:第一次put时候发现组数为空,cas放置头结点,如果发现头结点是forward结点说明正在扩容,当前线程去帮助扩容,否则synchronized锁住头结点再操作。
- resize:put时发现数组需要扩容,主动扩容,创建新数组,并把原数组计算出若干份,每个参与扩容的线程迁移不同的部分,通过transferindex标记,这样可以防止多个线程争抢扩容同一段数组。迁移时同样synchronized锁住头结点再操作,每迁移完成一个数组上的链表后,放置一个forward结点标识这个数组下标的数据已经被迁移了。
- get:判断数组头结点是否forward结点,是则通过forward结点的find方法去已经扩容好的新数组中查找,否则直接在查找,全程没有加锁。
- size:为了提高并发读,size的计算是通过一个数组和一个baseCount总和计算出来的,每次添加元素后,cas增加baseCount,失败则计算出一个数组下标,cas+自旋增加数组中对应的值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号