

大数据课堂测试要求用spark对数据进行清洗处理,可视化展示,完成结果截图如下
1、 数据采集及数据预处理

3. 数据统计:生成Hive用户评论数据:
(1)在Hive创建一张表,用于存放清洗后的数据,表名为pinglun

需求1:分析用户使用移动端购买还是PC端购买,及移动端和PC端的用户比例,生成ismobilehive表,存储统计结果;

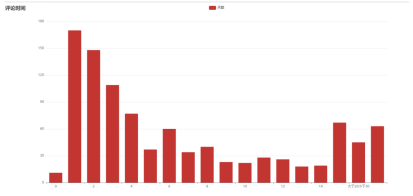
需求2:分析用户评论周期(收到货后,一般多久进行评论),生成dayssql表,存储统计结果;

需求3:分析会员级别(判断购买此商品的用户级别),生成userlevelname_out表,存储统计结果;
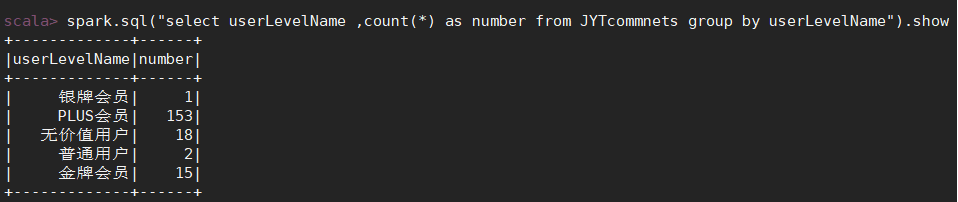
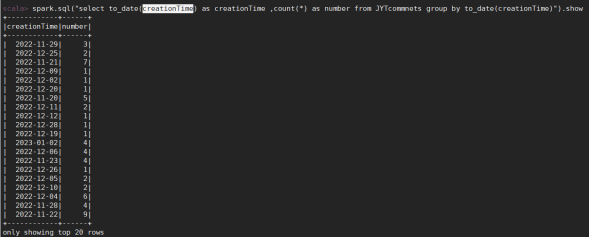
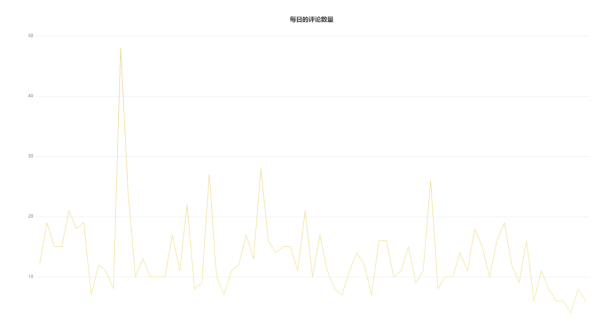
需求4:分析每天评论量,生成creationtime_out表,存储统计结果;
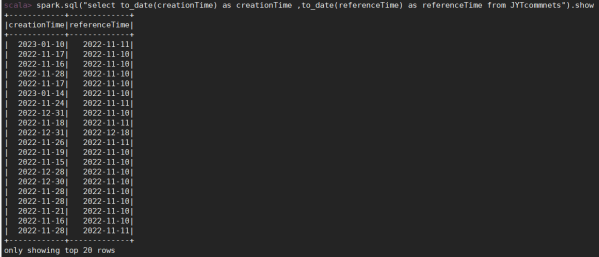
需求5:日期格式标准化
功能为:去掉评论时间的时分秒,只保留年月日
4. 利用Sqoop进行数据迁移至Mysql数据库:(5分)
将上述五个表倒入到相对应的mysql数据表中。
5. 数据可视化:利用JavaWeb+Echarts完成数据图表展示过程(20分)
(实现前五步,获得60分)
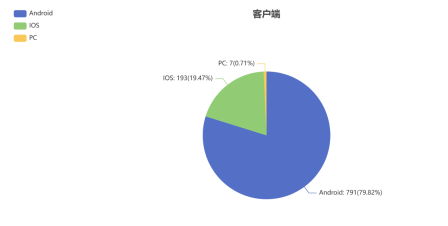
需求1:把用户对京东进行评论时使用的是客户端还是移动端的统计数据,用饼图进行数据展示,从而达到让观者能从中熟悉某个项目与整个数据组间所存在的比例关系的目的。
需求2:把用户在收到货后,一般多久进行评论,即用户评论周期用柱状图展示,可以达到展现数据并将数据进行比较的目的。
需求3:将购买某商品的用户级别进行统计的结果数据用饼状图展示,从而可以展现用户级别的比例构成关系,让观者能从中熟悉某个级别的用户数量与所有购买用户所存在的比例关系。

需求4:将某件商品的每天的评论量的统计数据用折线图进行展现,可以展现出这个商品每天的评论量的变化趋势。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号