缓存与分布式锁
1、缓存
为了提升系统性能,加速访问,减少数据库压力,我们往往会把一些即时性、数据一致性要求不高、访问量大且更新频率不高的数据
放入缓存中
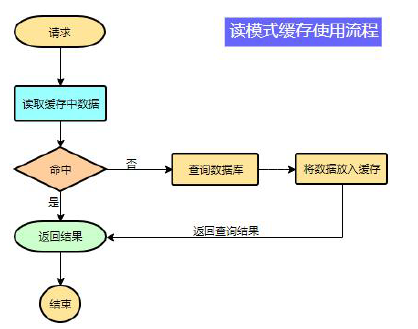
- 读取缓存使用流程
![]()
需要注意的是存入缓存中的数据我们应该设置过期时间,使其可以在系统即使没有主动更新数据,也能自动触发数据更新,避免业务崩溃导致的数据永久不一致问题
redis
当服务只是单机部署时,我们往往使用java自带的一些容器就能实现本地缓存,例如map集合,可是在分布式系统中,一个服务往往需要部署多个,此时本地缓存就会出现问题,所有必须引入一些缓存中间件
- springboot整合redis
![]()
- 高并发下缓存失效问题
- 缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存不命中,将会去查询数据库,数据库也无此记录,我们也没有把这次查询的null写入缓存,这就导致每次都要去数据库查询,当流量很大时,数据库可能会挂掉,有人也可能利用不存在的key频繁攻击我们的应用,这就是会形成一个漏洞
解决:
缓存空结果,并设置短的过期时间 - 缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,而此时又有大量请求转发到数据库,数据库瞬时压力过大雪崩
解决:
在原有的失效时间上加一个随机值,这样每一个缓存的过期时间的重复率就会降低,很难引发集体失效事件 - 缓存击穿
对于一些设置了过期时间的key,如果这些key在某个时间点被高并发的访问,是一种热点数据,而此时这个key正好在缓存中失效,那么所有请求都会去数据库查询,称为缓存击穿
解决:
加锁
- 缓存穿透
- 缓存数据一致性
- 保证一致性模式
1、双写模式
对数据库进行写操作时,同时也更新缓存中的数据,但这会存在一些问题,当有多个线程同时对数据库写操作时,由于系统网络io,cpu随机性调度等问题导致缓存中的数据并不一定是当前最新写入的数据,但是这只是暂时性的,当数据稳定,缓存过期后又能得到最新的正确数据
2、失效模式
对数据库写操作时,同时删除缓存,但这也会和上面出现同样的问题 - 解决方案
加入分布式读写锁,读数据时需要等待写数据的操作所有完成
使用cananl由阿里巴巴开源的技术,对数据库更新时同时更新redis
- 保证一致性模式

2、分布式锁
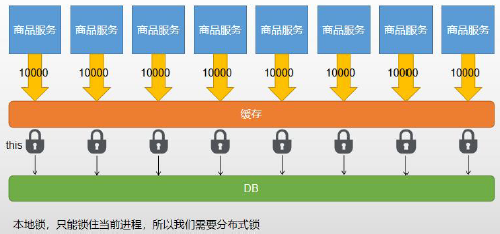
- 分布式锁与本地锁
![]()
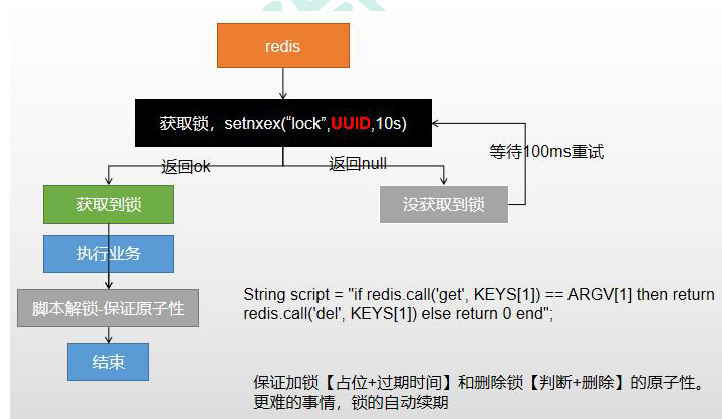
- reids实现分布式锁原理
![]()
当请求过来时先去redis占位,占位成功后,其他请求就不能再占位,只能等待当前任务执行完后,释放锁,才能继续去占位,这期间会出现一些问题,所以我们必须保证加锁【占位+过期时间】和删除锁【判断+删除】的原子性,但是更难的事情是锁的自动续期,redis已经帮我们封装好客户端redisson,可以对多种锁进行操作 - redisson
redisson是架设在redis基础上的一个java驻内存数据网格,充分利用redis键值数据库提供的一系列优势,基于java实用工具包中常用接口,为使用者提供了一系列具有分布式特性的常用工具类。使得原本做为协调单机多线程并发程序的工具包获得了协调分布式多机多线程并发系统的能力。
官方文档:https://github.com/redisson/redisson/wiki/Redisson项目介绍
3、Spring Cache
spring从3.1开始定义了org.springframework.cache.Cache和org.springframework.cache.CacheManager接口来统一不同的缓存技术,并支持使用JCache(JSR-107)注解简化我们开发
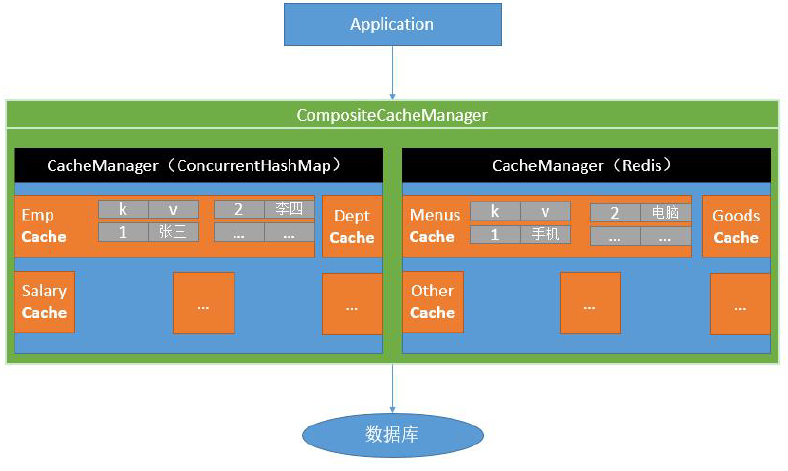
- 基础概念
![]()
- 注解
![]()
![]()
详细理解参照官方文档(观看的雷神视频总结的,一言不合就源码分析)
https://docs.spring.io/spring-framework/docs/5.2.12.RELEASE/spring-framework-reference/integration.html#cache



 浙公网安备 33010602011771号
浙公网安备 33010602011771号