


手写汉字识别
data
#coding=utf-8
import struct
import os
from PIL import Image
DATA_PATH="C:\\Users\\PC\\Desktop\\pytorch\\wz\\HWDB11tst_gnt" #gnt数据文件路径
IMG_PATH="C:\\Users\\PC\\Desktop\\pytorch\\wz\\data\\test"#解析后的图片存放路径
files=os.listdir(DATA_PATH)
num=0
for file in files:
tag = []
img_bytes = []
img_wid = []
img_hei = []
f=open(DATA_PATH+"/"+file,"rb")
while f.read(4):
tag_code=f.read(2)
tag.append(tag_code)
width=struct.unpack('<h', bytes(f.read(2)))
height=struct.unpack('<h',bytes(f.read(2)))
img_hei.append(height[0])
img_wid.append(width[0])
data=f.read(width[0]*height[0])
img_bytes.append(data)
f.close()
for k in range(0, len(tag)):
im = Image.frombytes('L', (img_wid[k], img_hei[k]), img_bytes[k])
if os.path.exists(IMG_PATH + "/" + tag[k].decode('gbk')):
im.save(IMG_PATH + "/" + tag[k].decode('gbk') + "/" + str(num) + ".jpg")
else:
os.mkdir(IMG_PATH + "/" + tag[k].decode('gbk'))
im.save(IMG_PATH + "/" + tag[k].decode('gbk') + "/" + str(num) + ".jpg")
num = num + 1
print(tag.__len__())
files=os.listdir(IMG_PATH)
n=0
f=open("label.txt","w") #创建用于训练的标签文件
for file in files:
files_d=os.listdir(IMG_PATH+"/"+file)
for file1 in files_d:
f.write(file+"/"+file1+" "+str(n)+"\n")
n=n+1model
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
class VGG19(nn.Module):
def __init__(self, img_size=32, input_channel=3, num_classes=1000):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=input_channel, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
)
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
self.conv5 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
)
self.conv6 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
)
self.conv7 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
)
self.conv8 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
self.conv9 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
)
self.conv10 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
)
self.conv11 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
)
self.conv12 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
self.conv13 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
)
self.conv14 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
)
self.conv15 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
)
self.conv16 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
self.fc17 = nn.Sequential(
#nn.Linear(int(512 * img_size * img_size / 32 / 32), 4096),
nn.Linear(2048, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5) # 默认就是0.5
)
self.fc18 = nn.Sequential(
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5)
)
self.fc19 = nn.Sequential(
nn.Linear(4096, num_classes)
)
self.conv_list = [self.conv1, self.conv2, self.conv3, self.conv4, self.conv5, self.conv6, self.conv7,
self.conv8, self.conv9, self.conv10, self.conv11, self.conv12, self.conv13, self.conv14,
self.conv15, self.conv16]
self.fc_list = [self.fc17, self.fc18, self.fc19]
def forward(self, x):
for conv in self.conv_list:
x = conv(x)
output = x.view(x.size()[0], -1)
for fc in self.fc_list:
output = fc(output)
return output
if __name__ == "__main__":
model = VGG19(3755).cuda()
summary(model, input_size=(3, 32, 32), device='cuda')train
import pickle
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from torchsummary import summary
from hwdb import HWDB
#from model import ConvNet
from model_2 import VGG19
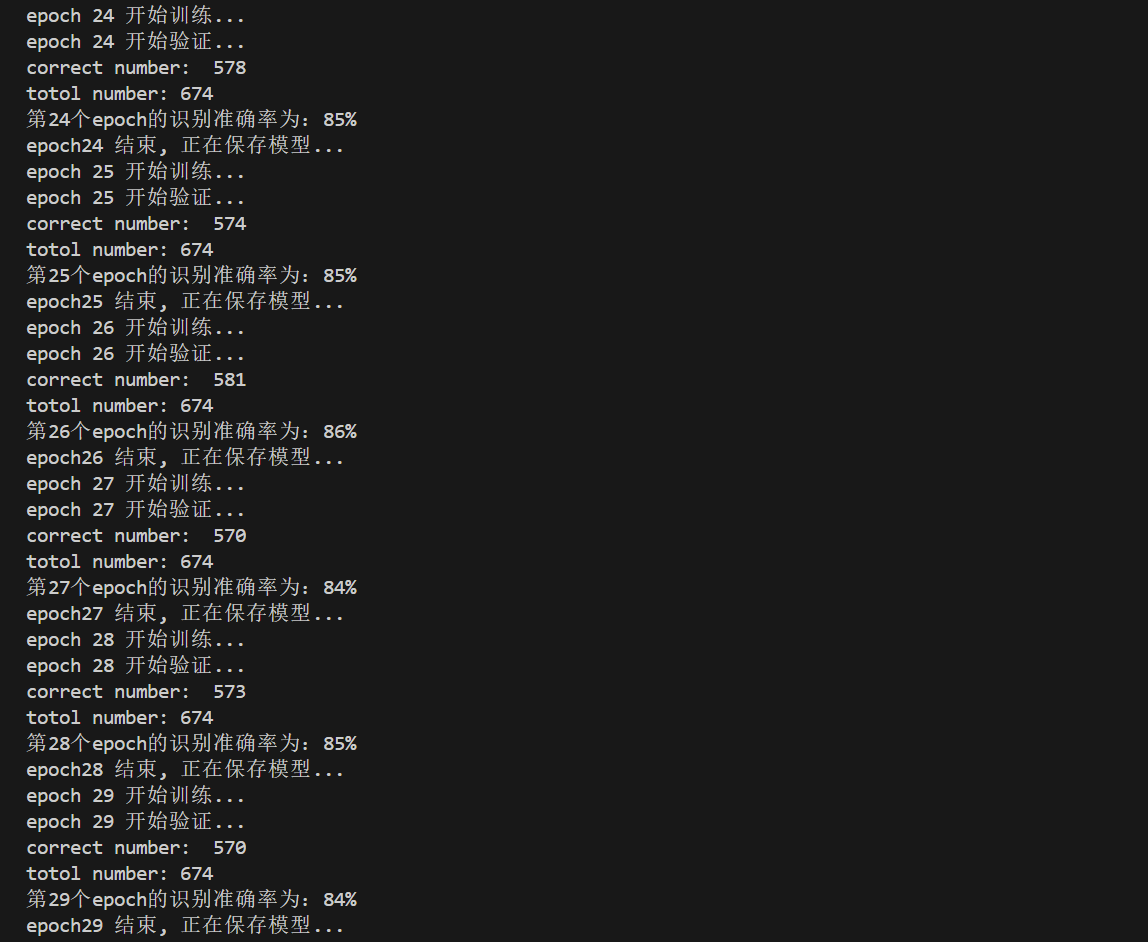
def valid(epoch, net, test_loarder, writer):
print("epoch %d 开始验证..." % epoch)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loarder:
images, labels = images.cuda(), labels.cuda()
outputs = net(images)
# 取得分最高的那个类
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('correct number: ', correct)
print('totol number:', total)
acc = 100 * correct / total
print('第%d个epoch的识别准确率为:%d%%' % (epoch, acc))
writer.add_scalar('valid_acc', acc, global_step=epoch)
def train(epoch, net, criterion, optimizer, train_loader, writer, save_iter=100):
print("epoch %d 开始训练..." % epoch)
net.train()
sum_loss = 0.0
total = 0
correct = 0
# 数据读取
for i, (inputs, labels) in enumerate(train_loader):
# 梯度清零
optimizer.zero_grad()
if torch.cuda.is_available():
inputs = inputs.cuda()
labels = labels.cuda()
outputs = net(inputs)
loss = criterion(outputs, labels)
# 取得分最高的那个类
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
loss.backward()
optimizer.step()
# 每训练100个batch打印一次平均loss与acc
sum_loss += loss.item()
if (i + 1) % save_iter == 0:
batch_loss = sum_loss / save_iter
# 每跑完一次epoch测试一下准确率
acc = 100 * correct / total
print('epoch: %d, batch: %d loss: %.03f, acc: %.04f'
% (epoch, i + 1, batch_loss, acc))
writer.add_scalar('train_loss', batch_loss, global_step=i + len(train_loader) * epoch)
writer.add_scalar('train_acc', acc, global_step=i + len(train_loader) * epoch)
for name, layer in net.named_parameters():
writer.add_histogram(name + '_grad', layer.grad.cpu().data.numpy(),
global_step=i + len(train_loader) * epoch)
writer.add_histogram(name + '_data', layer.cpu().data.numpy(),
global_step=i + len(train_loader) * epoch)
total = 0
correct = 0
sum_loss = 0.0
if __name__ == "__main__":
# 超参数
epochs = 30
batch_size = 100
lr = 0.05
data_path = r'C:\\Users\\PC\\Desktop\\pytorch\\wz\\data'
log_path = r'logs/batch_{}_lr_{}'.format(batch_size, lr)
save_path = r'checkpoints/'
if not os.path.exists(save_path):
os.mkdir(save_path)
# 读取分类类别
with open('char_dict', 'rb') as f:
class_dict = pickle.load(f)
num_classes = len(class_dict)
# 读取数据
transform = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor(),
])
dataset = HWDB(path=data_path, transform=transform)
print("训练集数据:", dataset.train_size)
print("测试集数据:", dataset.test_size)
trainloader, testloader = dataset.get_loader(batch_size)
net = VGG19(num_classes)
if torch.cuda.is_available():
net = net.cuda()
# net.load_state_dict(torch.load('checkpoints/handwriting_iter_004.pth'))
print('网络结构:\n')
summary(net, input_size=(3, 64, 64), device='cuda')
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=lr)
writer = SummaryWriter(log_path)
for epoch in range(epochs):
train(epoch, net, criterion, optimizer, trainloader, writer=writer)
valid(epoch, net, testloader, writer=writer)
print("epoch%d 结束, 正在保存模型..." % epoch)
torch.save(net.state_dict(), save_path + 'handwriting_iter_%03d.pth' % epoch)运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号