《机器学习》第一次作业——第一至三章学习记录和心得
第一章 模式识别基本概念
1.含义:
根据已有知识的表达,针对待识别模式,判别决策其所属的类别或者预测其对应的回归值。模式识别本质上是一种推理过程。
2.两种形式:
模式识别可划分为“分类”和“回归”。分类的输出量是离散的类别表达,而回归的输出量是连续的信号表达(回归值)。回归是分类的基础,离散的类别值是由回归值做判别决策得到的。
3.模型的组成:
模型由特征提取、回归器(和判别函数)组成,特征提取即从原始输入数据中提取更有效的信息,回归器即将将特征映射到回归值,而判别函数是一些特定的非线性函数。
4.特征的特性
特征是用于区分不同类别模式、可测量的量,其具有辨别能力和鲁棒性。
5.特征向量点积
A.代数定义

B.几何定义

6.特征向量投影
向量x到y的投影(projection)︰将向量x垂直投射到向量y方向上的长度(标量)。
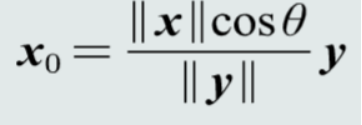
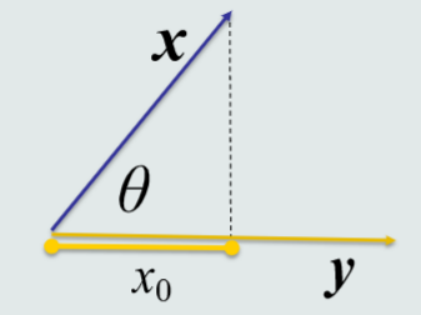
7.特征向量的欧式距离
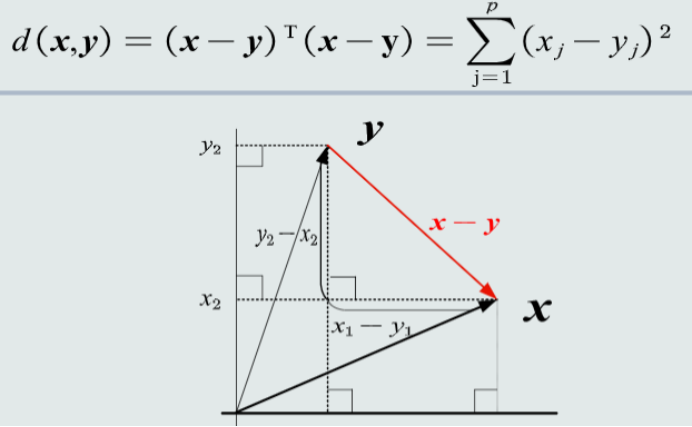
两个特征向量之间的欧式距离:表征两个向量之间的相似程度(综合考虑方向和模长)。
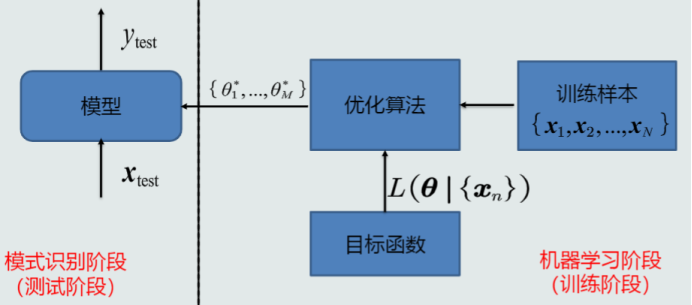
8.机器学习的流程
9.机器学习的方式
A.监督式学习
定义:训练样本及其输出真值都给定情况下的机器学习算法。
监督式学习是最常见的机器学习方式且通常使用最小化训练误差作为目标函数进行优化。
B.无监督式学习
定义:只给定训练样本、没有给输出真值情况下的机器学习算法。
无监督式学习算法的难度远高于监督式算法且根据训练样本之间的相似程度来进行决策。
C.半监督式学习
定义:既有标注的训练样本、又有未标注的训练样本情况下的学习算法。
典型应用:网络流数据
D.强化学习
定义:机器自行探索决策、真值滞后反馈的过程。
典型应用:Alpha Go、CNN
10.训练集和测试集
模型训练所用的样本数据,集合中的每个样本称作训练样本。
测试模型性能所用的样本数据,集合中的每个样本称作测试样本。
测试集和训练集是互斥的,但假设是同分布的。
11.泛化能力和过拟合
泛化能力概念:训练模型要对训练样本和新的模式都具有决策能力。
模型训练阶段表现很好,但是在测试阶段表现很差。
模型过于拟合训练数据。
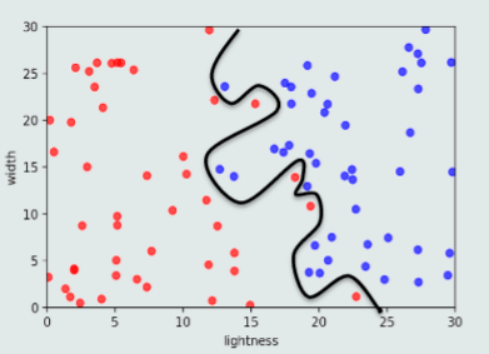
提高泛化能力思路:不要过度训练。
方法:
A.模型选择:选择复杂度适合的模型。
B.正则化:在目标函数中加入正则项。
第二章 基于距离的分类器
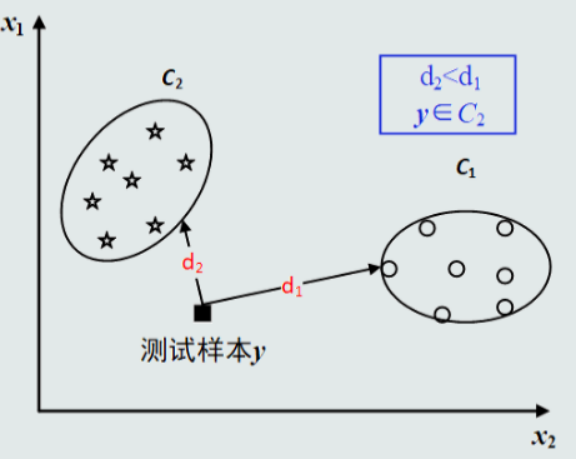
1.基于距离的决策
把测试样本到每个类之间的距离作为决策模型,将测试样本判定为与其距离最近的类。
该技术是初级的模式识别技术,是其它识别决策技术的基础。
2.MED分类器
定义:最小欧式距离分类器
距离衡量:欧式距离
类的原型:均值
二类的决策边界:一次函数
多类的决策边界:超平面
3.特征白化

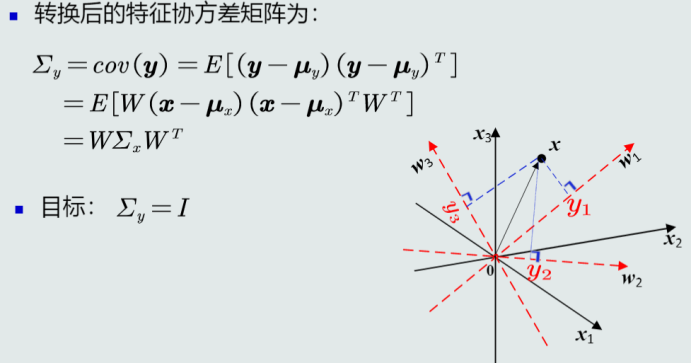
4.MICD分类器
定义:最小类内距离分类器,基于马氏距离的分类器
距离衡量:马氏距离
类的原型:均值
记A为协方差矩阵:
当A=I时,马氏距离等于欧式距离,其等距图是球面;
当A为对角矩阵时,等距图是超椭球面;
当A为任意值时,等距图是有方向的超椭球面。
MICD分类器的缺陷是会选择方差较大的类。
第三章 贝叶斯决策与学习
1.贝叶斯决策与MAP分类器
A.后验概率
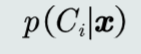
该条件概率称作后验概率,表达给定模式𝒙属于类𝐶𝑖可能性。
决策方法:找到后验概率最大的类。
B.后验概率计算公式:

2.MAP分类器
定义:最大后验概率分类器,即将测试样本决策分类给后验概率最大的那个类。
判别公式:
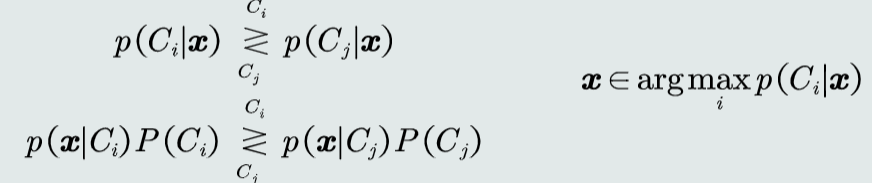
决策边界
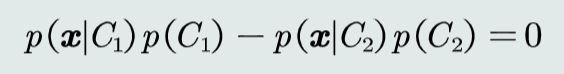
MAP分类器决策目标:最小化概率误差,即分类误差最小化。
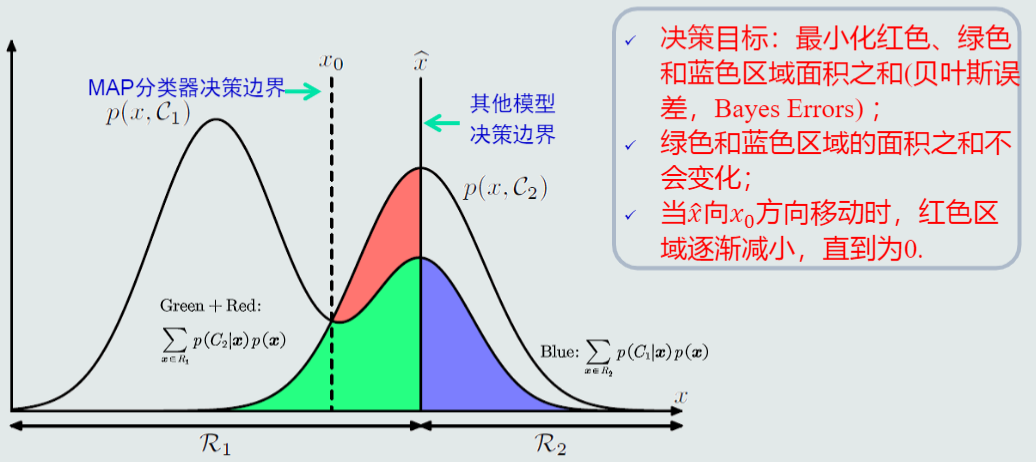
给定所有测试样本,MAP分类器选择后验概率最大的类,等于最小化平均概率误差,即最小化决策误差。
3.决策风险

4.最大似然估计

5.贝叶斯估计



 浙公网安备 33010602011771号
浙公网安备 33010602011771号