

MongoDB数据库,账号增删改,库的相关操作(增删查),集合(表)的相关操作,文档(记录)相关操作,python连接MongoDB
简介
分布式非关系型数据库 nosql数据库 用于爬虫的数据存储,大数据方向 mongoDB是最像关系型的非关系型数据,更加适用于大数据,redis则更倾向于,并发较小,数据较小,性能更高 功能全 MongoDB作为一款通用型数据库,除了能够创建、读取、更新和删除数据之外,还提供了一系列不断扩展的独特功能 1、索引 支持通用二级索引,允许多种快速查询,且提供唯一索引、复合索引、地理空间索引、全文索引 2、聚合 支持聚合管道,用户能通过简单的片段创建复杂的集合,并通过数据库自动优化 3、特殊的集合类型 支持存在时间有限的集合,适用于那些将在某个时刻过期的数据,如会话session。类似地,MongoDB也支持固定大小的集合,用于保存近期数据,如日志 4、文件存储 支持一种非常易用的协议,用于存储大文件和文件元数据。MongoDB并不具备一些在关系型数据库中很普遍的功能,如链接join和复杂的多行事务。省略 这些的功能是处于架构上的考虑,或者说为了得到更好的扩展性,因为在分布式系统中这两个功能难以高效地实现
# MongoDB概念 mongoDB mysql 数据库 数据库 集合 表 文档(类似字典) 记录 键值对 字段 # MongoDB注意事项 #1、文档中的键/值对是有序的。 #2、文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。 #3、MongoDB区分类型和大小写。 #4、MongoDB的文档不能有重复的键。 #5、文档中的值可以是多种不同的数据类型,也可以是一个完整的内嵌文档。文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。 # 文档键命名规范: #1、键不能含有\0 (空字符)。这个字符用来表示键的结尾。 #2、.和$有特别的意义,只有在特定环境下才能使用。 #3、以下划线"_"开头的键是保留的(不是严格要求的)。
下载与安装
安装时去除多余的组件安装提高速度:
# 下载 官网: https://mongoDB.com 下载地址:https://fastdl.mongodb.org/win32/mongodb-win32-x86_64-2008plus-ssl-4.0.8-signed.msi

安装:直接下一步安装,中间不要下载组件,加快安装
使用MongoDB
无账号密码登陆
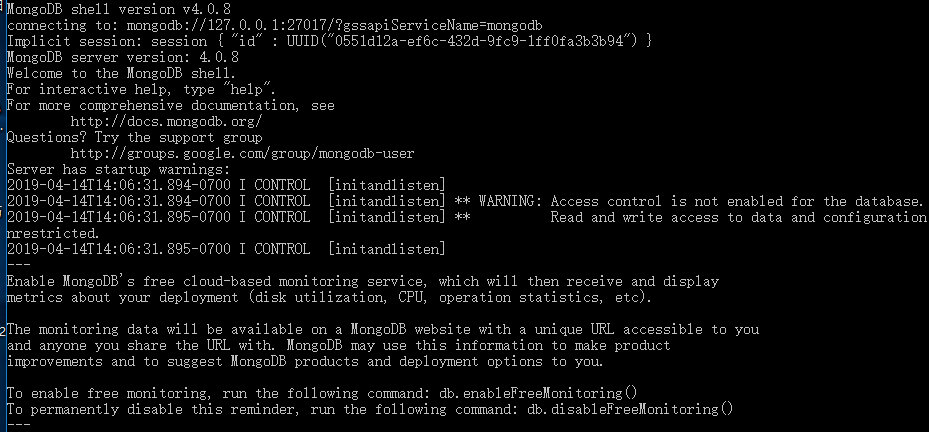
cmd使用,切换到安装MongoDB路径的bin文件下,启动mongo.exe
如图,说明登陆成功,默认最高权限,无账号密码登陆
账号密码登陆
创建账号
# 通过集合来确定所创用户的权限 use admin # 先切换到admin集合里(最高权限) db.createUser( { user: "root", # 创建账号 pwd: "123", # 创建密码 roles: [ { role: "root", db: "admin" } ] # root表示可以执行任何操作,admin 表示用户只能操作admin集合 } )
use test # 先切换到test集合里 # 用户操作多集合,(操作多库) db.createUser( { user: "lxx", # 创建账号 pwd: "123", # 创建密码 roles: [ { role: "readWrite", db: "test" }, # readWrite表示可以执行 读写 操作,test 表示用户只能操作test集合 { role: "read", db: "db1" } # # read表示用户可以执行 读 操作,db1 表示用户只能操作db1集合 ] } ) 更多角色请见:https://www.cnblogs.com/SamOk/p/5162767.html
# eg:
use admin # 先切换到admin集合里(最高权限)
db.createUser(
{
user: "root", # 创建账号
pwd: "123", # 创建密码
roles: [ { role: "root", db: "admin" } ] # root表示可以执行任何操作,admin 表示用户只能操作admin集合
}
)
修改配置文档,开启账号认证
注意:修改完以后重启MongoDB服务器!!!
# 修改配置文档mongod.cfg(找到启动MongoDB的路径下,找到mongod.cfg)
# 改成:(缩进跟原文档一样)
security:
authorization: enabled
如图:
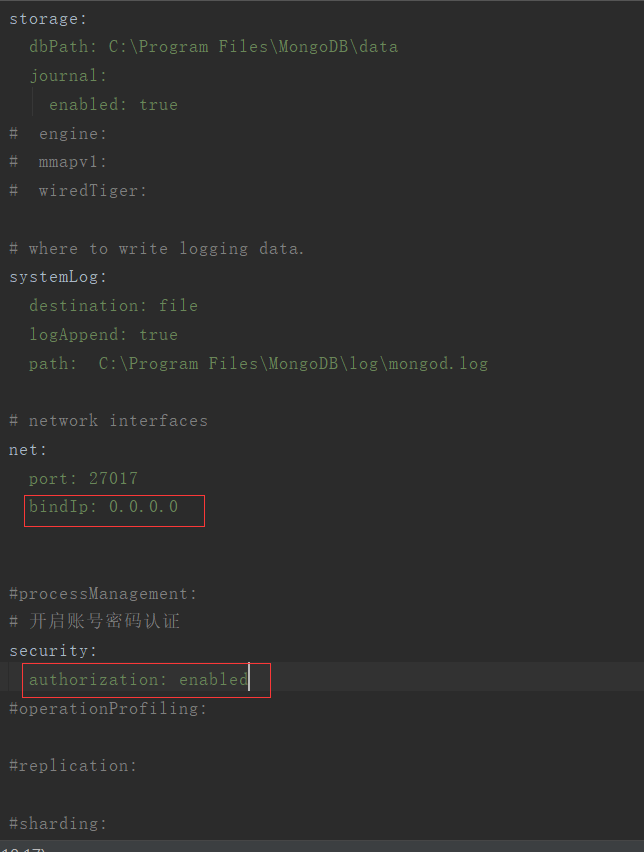
注意:修改完以后重启MongoDB服务器!!!
登陆MongoDB
show dbs # 登录方式1: authenticationDatabase指定数据库 mongo --port 27017 -u "root" -p "123" --authenticationDatabase "admin"
# 登录方式2:进入mongoDB后 use admin # 先切换到指定集合里 db.auth("root","123") # 显示1表示登陆成功,0表示登陆失败
账号增删改
# 创建账号 # 通过集合来确定所创用户的权限 use admin # 先切换到admin集合里(最高权限) db.createUser( { user: "root", # 创建账号 pwd: "123", # 创建密码 roles: [ { role: "root", db: "admin" } ] # root表示可以执行任何操作,admin 表示用户只能操作admin集合 } ) # 删除账号 db.dropUser('用户名'); # 修改密码 db.changeUserPassword(用户名, 新密码);
库的相关操作(增删查)
# 创建库 use xx # 有这个库切换到库里,没有则创建 # 查看库 show dbs # 库里没有集合,不显示(实际已经创好了) # 删除库 db.dropDatabase() # 删哪个库切换到哪个库执行,注意区分大小写 # > db.dropDatabase() # { "dropped" : "xx", "ok" : 1 } 表示删库成功 show dbs # 查看所有库 db # 查看当前所在库
集合(表)的相关操作
# 创建集合: db.user # 创建了user集合 # 查看集合: 同样的数据集合中没有数据则 不会显示 show collections # 查看当前库里的所有集合 show tables # 查看当前库里的所有集合 # 删除集合: # db.集合名.drop() db.blog.user.drop() # 集合里有文档才能删集合
mongodb支持的数据类型
# null:用于表示空或不存在的字段 d={'x':null} # 布尔型:true和false d={'x':true,'y':false} # 数值 d={'x':3,'y':3.1415926} # 字符串 d={'x':'egon'} # 日期 d={'x':new Date()} d.x.getHours() # 正则表达式,正则写在/.../内,后面的i代表: d={'pattern':/^egon.*?nb$/i} # # i 忽略大小写 # m 多行匹配模式 # x 忽略非转义的空白字符 # s 单行匹配模式 # 数组 d={'x':[1,'a','v']} # 内嵌文档 user={'name':'jerry','addr':{'country':'China','city':'YT'}} user.addr.country # 对象id:是一个12字节的ID,是文档的唯一标识,不可变 d={'x':ObjectId()} db.a.insert(d) # 插入上述文档
文档(记录)操作
插入
# 插入一条 insert db.user.insert({"_id":1}) # 插入多条 insertMany db.user.insertMany([ {"_id":3,"name":"张三封"}, {"_id":4,"name":"鹌鹑蛋"} ]) # 插入变量 insert var user1 = {"_id":10,"name":"王五"} # 先定义一个变量 var可以省略 # var user2 = {"_id":11,"name":"王六"} # 先定义一个变量 var可以省略 # db.user.insert(user1) # 再插入一个变量 db.user.insertMany([user1,user2]) # 再插入多个变量 # save方法,覆盖集合 # db.user.save( {"_id":10,"name":"鹌鹑蛋2"}) # 如果id已经存在则覆盖,没有添加,相当于先清空原集合里的文档,在设置新文档 # 插入布尔值 # {'key':null} 匹配key的值为null或者没有这个key db.t2.insert({'a':10,'b':111}) db.t2.insert({'a':20}) db.t2.insert({'b':null})
查询文档(记录)
# db.student.find({},{}}) 第一个字典参数表示查询所有的集合,第二个字典参数表示显示的字段 # find # 查找所有匹配数据 # findOne # 查找第一个匹配的 # pretty() # 文档格式化显示
# find 与 findone
db.user.find().pretty() # 查询user集合里的所有文档,相当于 select *from user db.user.findOne({"name":"张三"}) # 查询名字叫张三的第一个文档 db.user.find({"name":"张三"}) # 查询名字叫张三的文档,相当于 select *from user where name = "张三封" db.user.find({"name":"张三封","_id":3}) # 查询名字叫张三且id为3的文档,相当于 select *from user where name = "张三封 and _id = 3"
# 比较符查询 != > < >= <= "$ne","$gt","$lt","gte","lte" db.user.find({"name":{"$ne":"张三"}}) # 查询user集合里名字不叫张三的文档
# 逻辑运算符查找and,or,not # and查询 db.user.find({'_id':{"$gte":2,"$lt":4}}) # 查询id>=2,且小于4的文档 db.user.find({"_id":{"$gte":2},"age":{"$lt":40}}) # 查询id>=2,且年龄<40的文档 # or 查询 db.user.find( # 查询id大于5,或者name是cxx的文档 {"$or":[{'_id':{"$gte":5}},{"name":"cxx"}]} ) # not查询 {"$mod":[2,1]} mod表示取余,除以2余1 db.user.find({'_id':{"$not":{"$mod":[2,1]}}}) # 查询id不是奇数的文档 # "$in","$nin" 成员查询 db.user.find({"age":{"$in":[20,30,31]}}) # 查看年龄在[20,30,31]的文档 db.user.find({"name":{"$nin":['alex','yuanhao']}}) 查看名字不是alex,yuanhao的文档
# /正则表达式/ 正则查询 db.user.find({'name':/^j.*?(g|n)$/i}) # 查询以j开头,g或n结尾的文档(忽略大小写) # i 忽略大小写 # m 多行匹配模式 # x 忽略非转义的空白字符 # s 单行匹配模式
# 指定字段查询 db.user.find({'_id':3},{'_id':0,'name':1,'age':1}) # 查询id为3的文档,只显示name,age,其它字段都不显示 # 0表示不显示 默认为0 1为显示
# 数组查询 db.user.find({'hobbies':'dancing'}) # 查询有爱好为 dancing的文档 # $all 查询 db.user.find({ # 查询爱好有dancing,tea的文档 'hobbies':{ "$all":['dancing','tea'] } }) # 通过$size获取数组的长度,但是$size不能和比较操作符联合使用 db.user.find({},{"hobbies":{"$size":3}}) # 查询拥有三个爱好的用户文档 # 数组索引查询 db.user.find({},{"hobbies.3":'tea'}) # 查询第四个爱好为tea的文档 # 数组切片查询 # $slice [1,1] 表示的是从第1个开始取1个 db.student.find({},{"hobbies":{"$slice":[1,1]}}).pretty() # 表示查看学生集合的第二个爱好 db.student.find({},{"hobbies":{"$slice":[2,2]}}).pretty() # 表示查看学生集合的 第二个,第三个 爱好的文档 db.student.find({},{"hobbies":{"$slice":[0,1]}}).pretty() # 表示查看学生集合的第一个爱好 db.student.find({},{"hobbies":{"$slice":[-1]}}).pretty() # 表示查看学生集合的最后一个爱好 db.student.find({},{"hobbies":{"$slice":[-2]}}).pretty() # 表示查看学生集合的最后两个爱好 # 排序升序显示,1代表升序,-1代表降序 db.user.find().sort({"name":1,}) # user集合的name字段升序显示 db.user.find().sort({"age":-1,'_id':1}) # user集合的age字段降序显示,id字段升序显示 # 分页查询,limit代表取多少个document,skip代表跳过前多少个document。 # 先排好序,在分页查询 db.user.find().sort({'age':1}).limit(1).skip(2) # 查询年龄第三名的user文档 db.user.find().limit(1).skip(2) # 查询第三条文档
# 数量查询 count db.user.count({'age':{"$gt":30}}) # 查询年龄大于三十的文档个数 db.user.find({'age':{"$gt":30}}).count() # 查询年龄大于三十的文档个数
# 布尔查询 db.t2.insert({'a':10,'b':111}) db.t2.insert({'a':20}) db.t2.insert({'b':null}) # db.t2.find({"b":null}) { "_id" : ObjectId("5a5cc2a7c1b4645aad959e5a"), "a" : 20 } { "_id" : ObjectId("5a5cc2a8c1b4645aad959e5b"), "b" : null } # 查询没有b字段,或者b字段为空的文档
更新文档
# update() 方法用于更新已存在的文档。语法格式如下: db.collection.update( <query>, <update>, { upsert: <boolean>, multi: <boolean>, writeConcern: <document> } ) 参数说明:对比update db1.t1 set name='EGON',sex='Male' where name='egon' and age=18; query : 相当于where条件。 update : update的对象和一些更新的操作符(如$,$inc...等,相当于set后面的 upsert : 可选,默认为false,代表如果不存在update的记录不更新也不插入,设置为true代表插入。 multi : 可选,默认为false,代表只更新找到的第一条记录,设为true,代表更新找到的全部记录。 writeConcern :可选,抛出异常的级别。 # 更新操作是不可分割的:若两个更新同时发送,先到达服务器的先执行,然后执行另外一个,不会破坏文档。 # 覆盖式更新:(少用) 注意:除非是删除,否则_id是始终不会变的 db.user.update({'age':20},{"name":"Wxx","hobbies_count":3}) # 将age=20的文档全部替换为 {"name":"Wxx","hobbies_count":3} # 是用{"_id":2,"name":"Wxx","hobbies_count":3}覆盖原来的记录 # 一种最简单的更新就是用一个新的文档完全替换匹配的文档。这适用于大规模式迁移的情况。例如 var obj=db.user.findOne({"_id":2}) # 设置一个新的变量 obj.username=obj.name+'SB' # 添加username字段 obj.hobbies_count++ # hobbies_count字段自加一 delete obj.age # 删除age字段 db.user.update({"_id":2},obj) # 更新完以后的文档为 {"_id":2,"username":"usernameSB"} # $set 更新具体某些字段 db.user.update({'_id':2},{"$set":{"name":"WXX",}}) # 将id为2的文档的 name字段更新为 WXX # {"upsert":true} 有则更新,没有某一条文档,则添加这条文档, db.user.update({'_id':6},{"$set":{"name":"egon","age":18}},{"upsert":true}) # {"multi":true} 默认只改匹配成功的第一条 db.user.update({'_id':{"$gt":4}},{"$set":{"age":28}}) # 只改id大于4的第一条文档 db.user.update({'_id':{"$gt":4}},{"$set":{"age":38}},{"multi":true}) # id大于4的文档全部更新 # 修改内嵌文档,把名字为alex的人所在的地址国家改成Japan db.user.update({'name':"alex"},{"$set":{"addr.country":"Japan"}}) db.user.update({'name':"alex"},{"$set":{"hobbies.1":"piao"}}) # 把名字为alex的文档的第二个爱好改成piao
$unset 删除文档指定字段
db.user.update({'name':"alex"},{"$unset":{"hobbies":""}}) # 把名字为alex的文档的hobbies字段删除掉
$inc 增加 与 $i 减少
db.user.update({}, # 所有人年龄增加1岁
{"$inc":{"age":1}},{"multi":true}
)
db.user.update({}, # 所有人年龄减5岁
{"$i":{"age":5}},{"multi":true}
)
数组相关操作
# 往数组内添加元素:$push # 添加一个爱好 db.user.update({"name":"yuanhao"},{"$push":{"hobbies":"read"}}) # 为名字为yuanhao的人添加一个爱好read # 添加多个爱好 db.user.update({"name":"yuanhao"},{"$push":{ # 为名字为yuanhao的人一次添加多个爱好tea,dancing "hobbies":{"$each":["tea","dancing"]} }})
# 按照位置且只能从开头或结尾删除元素:$pop # {"$pop":{"key":1}} 从数组末尾删除一个元素 db.user.update({"name":"yuanhao"},{"$pop":{ # 删除文档的最后一种爱好 "hobbies":1} })
# {"$pop":{"key":-1}} 从头部删除 db.user.update({"name":"yuanhao"},{"$pop":{ # 删除文档的第一种爱好 "hobbies":-1} })
# 按照条件删除元素,:"$pull" 把符合条件的统统删掉,而$pop只能从两端删 db.user.update({'addr.country':"China"},{"$pull":{ # 把位于中国的文档删除read的爱好 "hobbies":"read"} },{ "multi":true} )
删除文档
# deleteOne 删除一条文档 db.user.deleteOne({ 'age': 8 }) # 删除age字段为8的第一条文档
# deleteMany 删除多条文档 db.user.deleteMany( {'addr.country': 'China'} ) # 把国家 为 "china" 的所有文档删除 db.user.deleteMany({}) # 删除集合里的全部文档
# $unset 删除文档指定字段 db.user.update({'name':"alex"},{"$unset":{"hobbies":""}}) # 把名字为alex的文档的hobbies字段删除掉
自动去除重复 $addToSet
db.urls.insert({"_id":1,"urls":[]})
db.urls.update({"_id":1},{"$addToSet":{"urls":'http://www.baidu.com'}})
db.urls.update({"_id":1},{"$addToSet":{"urls":'http://www.baidu.com'}})
db.urls.update({"_id":1},{"$addToSet":{"urls":'http://www.baidu.com'}})
# 将连接地址去重
db.urls.update({"_id":1},{
"$addToSet":{
"urls":{
"$each":[
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.xxxx.com'
]
}
}
}
)
python连接MongoDB
from pymongo import MongoClient # 方法一: client = MongoClient("mongodb://root:123@127.0.0.1:27017") # 建立连接 table = client['jd_db']['aa'] # 切换到表 # print(table.collection_names(include_system_collections=False)) # 不显示系统集合的名字 include_system_collections=False为不显示 table_data = table.insert({"name": "cxx", "age": 16}, {"sex": "男"}) # 插入 table.update({"name":"cxx"},{"$set":{"name":"yyy"}}) # 更新 table.delete_many({"name":"yyy"}) # 删除 print(list(table.find())) # 方法二: client = MongoClient(host="127.0.0.1", port=27017) # 连接mongodb数据库 table = client["admin"] # 切到admin表 table.authenticate(name="root", password="123") # 验证账号,密码 # print(table.collection_names(include_system_collections=False)) # 不显示系统集合的名字 if table: # 验证通过 table = client["jd_db"]["aa"] # 切换到相应的表里执行操作 print(list(table.find()))
# 3、查看库下所有的集合 print(db.collection_names(include_system_collections=False)) #4、创建集合 table_user=db['userinfo'] #等同于:db.user #5、插入文档 import datetime user0={ "_id":1, "name":"egon", "birth":datetime.datetime.now(), "age":10, 'hobbies':['music','read','dancing'], 'addr':{ 'country':'China', 'city':'BJ' } } user1={ "_id":2, "name":"alex", "birth":datetime.datetime.now(), "age":10, 'hobbies':['music','read','dancing'], 'addr':{ 'country':'China', 'city':'weifang' } } res=table_user.insert_many([user0,user1]).inserted_ids # 插入多条 # print(res) # print(table_user.count()) #6、查找 # from pprint import pprint # 格式化 # pprint(table_user.find_one()) # for item in table_user.find(): # pprint(item) print(table_user.find_one({"_id":{"$gte":1},"name":'egon'})) # 查一条 #7、更新 table_user.update({'_id':1},{'name':'EGON'}) #8、传入新的文档替换旧的文档 table_user.save( # 覆盖是更新 { "_id":2, "name":'egon_xxx' } )

 浙公网安备 33010602011771号
浙公网安备 33010602011771号