
爬虫简介,爬虫流程,浏览器分析请求(有用信息),模拟get请求,session模拟发请求, get请求常用参数,post请求常用参数, 验证请求是否成功
爬虫简介
爬虫是一个位于客户端(Client)的,用于爬取数据的应用程序
爬取得目标:
整个互联网,某一单独服务器。 爬虫的价值: 互联网中最有价值的就是数据 爬虫首要任务就是通过网络取获取模板服务器的数据;来为自己创造最大价值。
爬虫原理:
分析浏览器与服务器之间到底是如何通讯的,然后模拟浏览器来与服务器通讯,从而获取数据。
爬虫流程
明确爬取得数据 借助网络编程,传输数据(HTTP协议) 1. 明确爬取的url地址 2. 模拟发送请求 _借助第三发模块(requests) # 推荐使用 安装:pip3 install requests requests.get() 模拟发送get请求 requests.post() 模拟发送post请求 _python内置的模块(urllib) _Selenium (自动化测试模块)用程序驱动浏览器发送请求 _针对移动app可以使用代理服务器,可以截获app端发送的请求信息 Charles(青花瓷) 3. 接受响应(一般通过浏览器分析请求详情) requests,urllib模块直接返回响应体 # eg: response = request.get("https://www.pearvideo.com") # response.text # 接受的字符串信息 # response.content # 接受的Bytes类型 Selenium模块提供了find_element***的接口用于获取数据 eg: 4. 解析数据 re 正则表达式 BeautifulSoup 封装了常用的正则表达式 移动端返回的/ajax返回的json数据 直接json.load 5. 存储数据 mysql存储,redis存储,文件存储( json形式 )
浏览器分析请求(有用信息)
主要接口分析
# Request URL: https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=2&start=12&mrd=0.05746713547672622&filterIds=1540723,1540697,1540834,1541181,1541182,1541173,1541149,1540993,1541086,1541105,1540503,1541041,1541053,1541046,1541003 分析有用接口:https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=2&start=12 (手动模拟测试分析)
请求链接地址
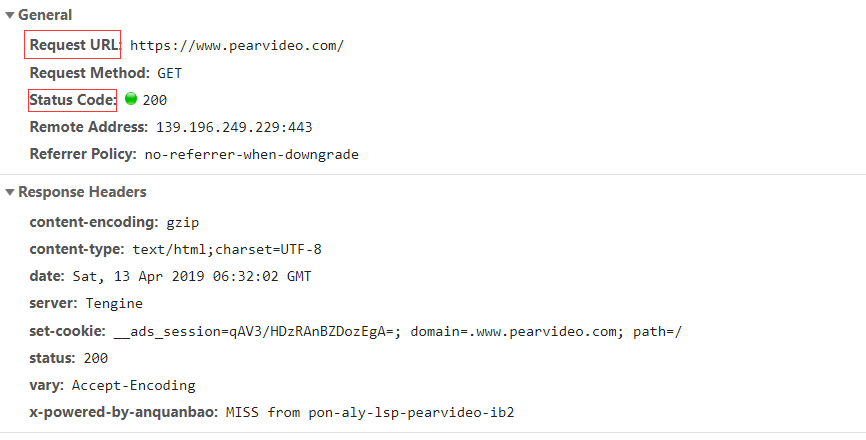
请求头里的重要信息
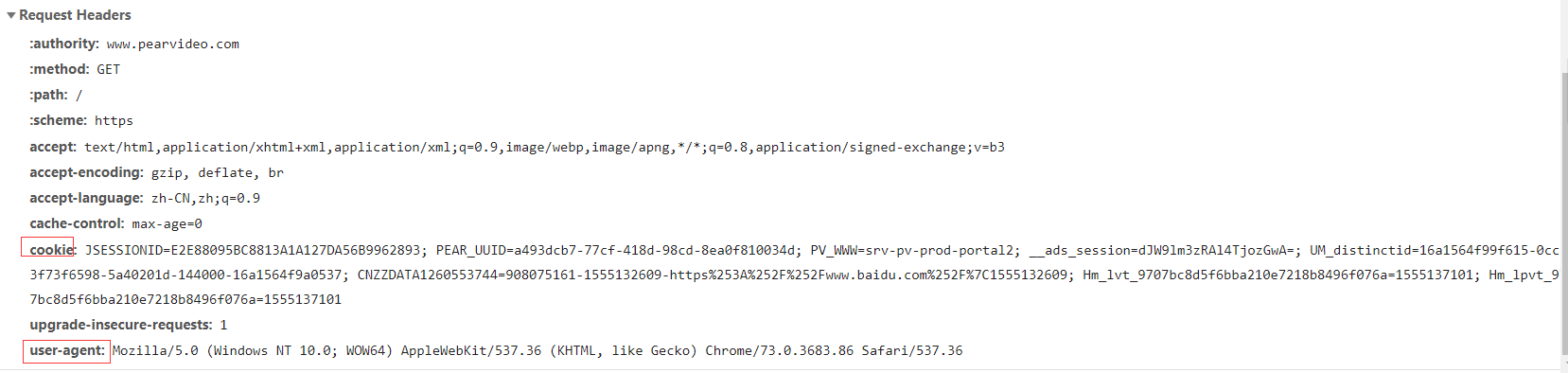
分析请求头有用信息
user-agent 用来识别客户端类型(是否是浏览器)
refer 用来识别用户从哪个页面过来的
Cookie 一般用来当页面需要验证用户身份时 使用
分析响应头有用信息
location 当请求被重定向时 就会带有该字段 可以通过状态码30* 来识别重定向
模拟get请求
获取连接地址 ,request.get(url)
resp = requests.get(url=url) # requests模块模拟发get请求 if resp.status_code == 200: # 获取响应的状态码 print("响应成功") print(resp.text) # 请求回来的数据字符串类型 print(resp.content) # 请求回来的数据 bytes类型 result = re.findall('<a href="(video_\d+?)" class="vervideo-lilink actplay">', resp.text) # 找我想要数据进行过滤
解析标签
result = re.findall('<a href="(video_\d+?)" class="vervideo-lilink actplay">', resp.text) # 找我想要数据进行过滤 for i in result: detail_url = "https://www.pearvideo.com/" + i # 请求头: detail_result = requests.get(detail_url) # 标题 title = re.search('<h1 class="video-tt">(.*?)</h1>', detail_result.text).group(1) # print(title) # 点赞 up_count = re.search('<div class="fav" data-id="\d+">(\d+?)</div>', detail_result.text).group(1) # print(up_count) # 详情内容 detail_content = re.search('<div class="summary">(.*?)</div>', detail_result.text).group(1) # print(detail_content) # 作者名字 author_name = re.search('alt=".*"></i>(.*?)</div>', detail_result.text).group(1) # print(author_name) video_url = re.search('srcUrl="(.*?)"', detail_result.text).group(1) # 解析视频链接地址 # print(video_url) # 将爬取的信息存入字典 detail_dic = {"title": title, "up_count": up_count, "detail_content": detail_content, "author_name": author_name, "video_url": video_url} get_dic_list.append(detail_dic) # 循环玩以后全部加入一个列表里
下载视频
# 拿着视频地址,模拟发请求 video_result = requests.get(video_url)
path = str(video_path) + "/" + str(author_name) + str(random_num) + ".mp4" with open(path, "wb") as f: f.write(video_result.content) # 发的是视频的连接地址,响应回来的就是视频的bytes文件 print("下载好了")
存入文件
path = datajs_path + "/" + "get_dic_list.json" # 爬取的数据持久化处理 with open(path, "wt") as f: json.dump(get_dic_list, f) # 自动写入json的字符串
get请求常用参数
url , params , headers 参数
url: 请求的链接地址
headers : 请求头携带的数据
params:get : 请求携带的数据
url = "https://www.baidu.com/s" # s 代表get请求携带的数据的占位符 response = requests.get( url=url, # 表示请求的路由 params={"wd":"美女"}, # get请求携带的数据 headers={"User-Agent":User_Agent}, # 请求头携带的数据
data={...} # 请求体携带数据
)
cookies参数
取Cookie
url = 'https://github.com/login' resp = requests.get(url=url, headers={"User-Agent": User_Agent}) # print(type(resp.cookies)) cookie = resp.cookies.get_dict() # 获取cookie
cookie携带方式一
login_url = 'https://github.com/session' response = requests.post( url=login_url, headers={ # 请求头携带数据 "User-Agent": User_Agent, # 识别请求是浏览器发送 # 携带cookie数据(手动改成字典的形式传入) "Cookie":"has_recent_activity=1; _ga=GA1.2.1969485734.1554949588; _octo=GH1.1.477478330.1554949588; tz=Asia%2FShanghai; _device_id=6e2ef5508aa3004b4fe2de6691015327; logged_in=no; _gh_sess=blMyUDk1ZVF2RnBvMDQzSExyZWVKa09WaUFiUVZ6TXJ # cookies={"has_recent_activity":1,"_ga":"GA1.2.1969485734.1554949588","_octo":"GH1.1.477478330.1554949588"......} }, )
cookie携带方式二,推荐使用
login_url = 'https://github.com/session' response = requests.post( url=login_url, headers={ # 请求头携带数据 "User-Agent": User_Agent, # 识别请求是浏览器发送 }, cookies=cookie # 携带cookie数据(requests模块封装了) ,推荐使用 )
session模拟发请求
session自动帮我们处理cookie,提交cookie
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36" # 创建一个会话 session = requests.session() # 以后用session来模拟发请求,自动帮我们提交cookie # 1.请求登录页面 res = session.get(
url="https://github.com/login", # 请求的地址
headers={ # 请求头携带数据 "Referer": "https://github.com/", "User-Agent": user_agent # 模拟浏览器发请求 }
)
post请求常用参数
data参数,请求体携带 账号/密码/token 等数据
# 获取token,(token只是隐藏了,html界面能够找到) url = 'https://github.com/login' User_Agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36' resp = requests.get(url=url, headers={"User-Agent": User_Agent}) token = re.search('name=".*?_token" value="(.*?)" />', resp.text).group(1) # 获取token login_url = 'https://github.com/session' response = requests.post( url=login_url, headers={ # 请求头携带数据 "User-Agent": User_Agent, }, data={ # 请求体携带数据 "authenticity_token": token, # 模拟携带token "login": "liu-huan-github", # 模拟携带账号 "password": "l.13327316050", # 模拟携带密码 },
)
验证请求是否成功
方法1:
print(resp.status_code) # 验证请求状态码是否符合
resp = requests.get(url=url) # requests模块模拟发get请求
if resp.status_code == 200: # 获取响应的状态码
方法2:
print("oldboyedujerry/testProject" in resp.text) # 首先登陆成功,查看用户名是否在我爬取的界面里,在表示登陆请求发送成功

 浙公网安备 33010602011771号
浙公网安备 33010602011771号