NLP经典模型入门-Attention
前言:笔者之前是cv方向,因为工作原因需要学习NLP相关的模型,因此特意梳理一下关于NLP的几个经典模型,由于有基础,这一系列不会关注基础内容或者公式推导,而是更侧重对整体原理的理解。顺便推荐两个很不错的github项目——开箱即用的中文教程以及算法更全但是有些跑不通的英文教程。
一. RNN与RCNN的异同
无论是RNN模型还是RCNN模型,数据如果不考虑bs维度的话,其实都只有两个维度。
一个维度是seq_len维度,代表着模型有多少个不同的状态。比如seq_len=32,那么模型就有32个不同的状态,也可以理解为\(L_1\)有32个A,这个数字在一些任务中一般选择和输入等长,比如输入是一个长度为32的句子(多截少补)。各个状态是共享权重的。
另一个维度是特征维度,类似cv中的通道,代表每个状态有多少个不同的特征。最开始输入是一个整数,只有1,然后经过embedding层变成指定长度的向量例如300,然后经过RNN单元的时候,RNN内部也会有一个hidden_size的超参对应它。
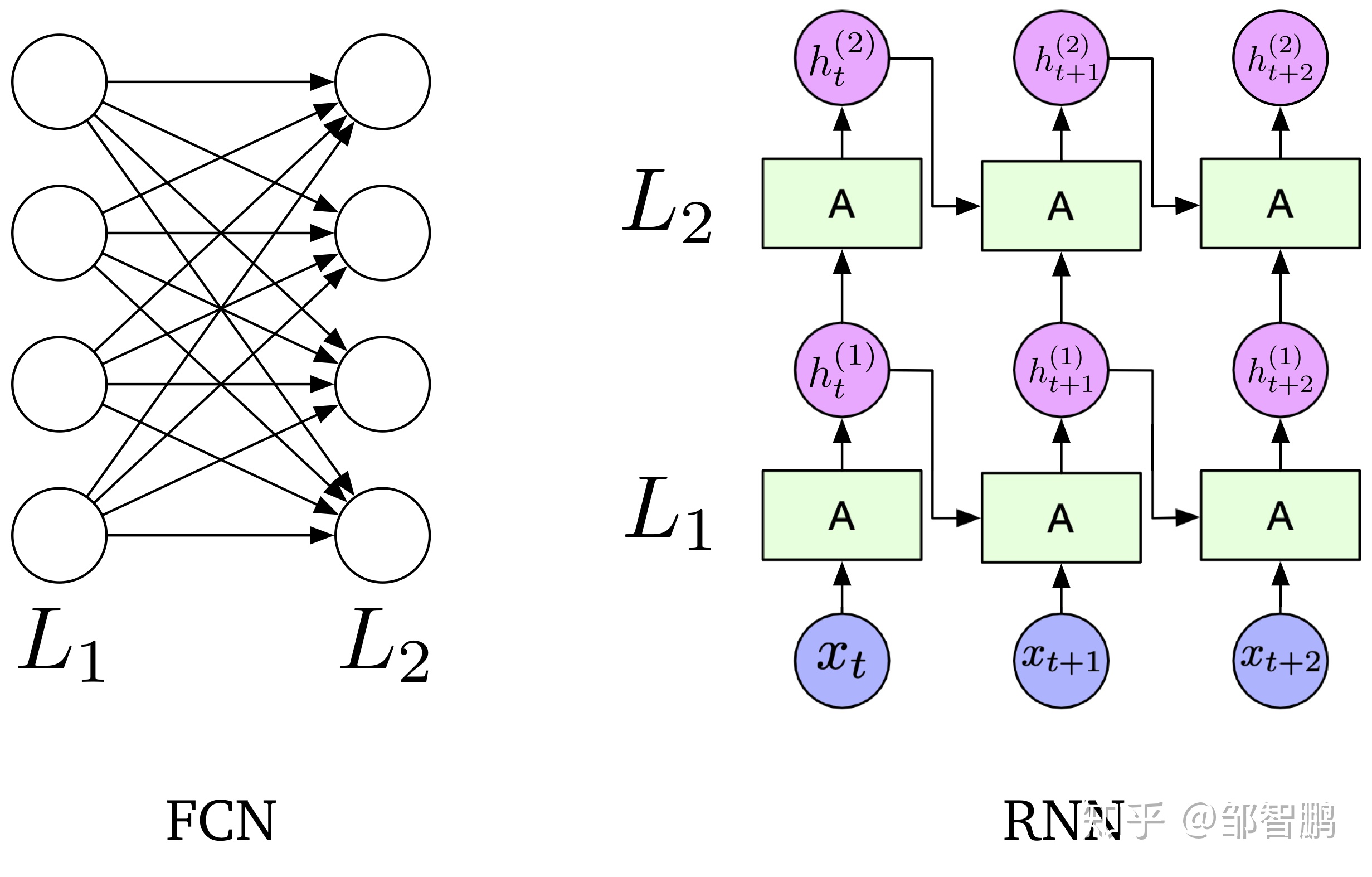
之前到的模型其实都不是seq2seq模型,最后输出只要一个就够了。对此,RNN的思路是选择最后一个(就是上图中的\(h_{t+2}^{(2)}\))来送入分类器:
def forward(self, x):
x, _ = x
out = self.embedding(x)
out, _ = self.lstm(out)
out = self.fc(out[:, -1, :]) # 句子最后时刻的 hidden state
return out
而RCNN如果不考虑特征连缀,本质上是在32个状态中进行pooling,取最大值(maxpool)或者平均值(avgpool):
def forward(self, x):
x, _ = x
embed = self.embedding(x)
out, _ = self.lstm(embed)
out = torch.cat((embed, out), 2)
out = F.relu(out)
out = out.permute(0, 2, 1)
out = self.maxpool(out).squeeze() // 在seq_len长度上做最大值池化
out = self.fc(out)
return out
二. 注意力机制
了解了前面这些再看注意力机制其实就简单了。说白了,我想用各个状态共同来求一个更精准的值用于分类,它既不是只取最后一个状态,也不是所有状态简单地选择所有状态中的最大值或者取平均值,而是所有状态的加权和。这样那些对任务有重要的作用的状态可以更加突出,同时也不至于完全抵消其它状态的作用和影响,而决定每个状态重要性的加权系数的计算方法如下:
def forward(self, x):
x, _ = x
emb = self.embedding(x)
H, _ = self.lstm(emb) # [batch_size, seq_len, hidden_size]
M = self.tanh1(H)
# self.w是一个256x1的矩阵,相乘后变成[batch_size, seq_len],标识着每个状态的权重,要用softmax做一下归一化
# self.w是可学习的,会自适应变化
alpha = F.softmax(torch.matmul(M, self.w), dim=1).unsqueeze(-1)
# 计算加权和
out = H * alpha # [128, 32, 256]
out = torch.sum(out, 1) # [128, 256]
# 分类
out = F.relu(out)
out = self.fc1(out)
out = self.fc(out) # [128, 64]
return out
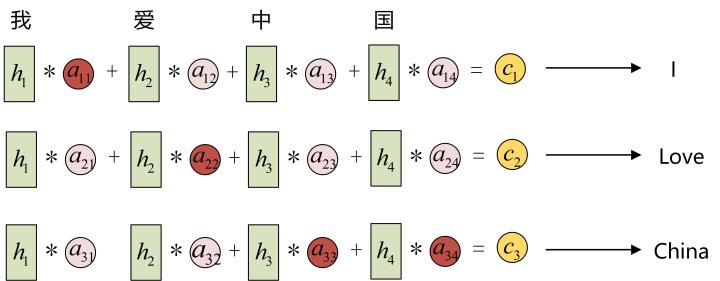
具体的理解可以看下https://www.zhihu.com/people/zhou-yang-zhi-84这里的图,虽然使用场景是seq2seq任务,本质上是一样的。如图所示,在翻译不同位置的词汇的时候,不同状态起到了不同的作用。想象一下,这里假如是一个分类任务判断情绪积极还是消极,用h1、h2、h3和h4共同计算一个状态c,那么很可能爱这个状态的权重会比其它没有感情情绪的名词起到更大的作用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号