
Spring Cloud Alibaba学习笔记
依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.9.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
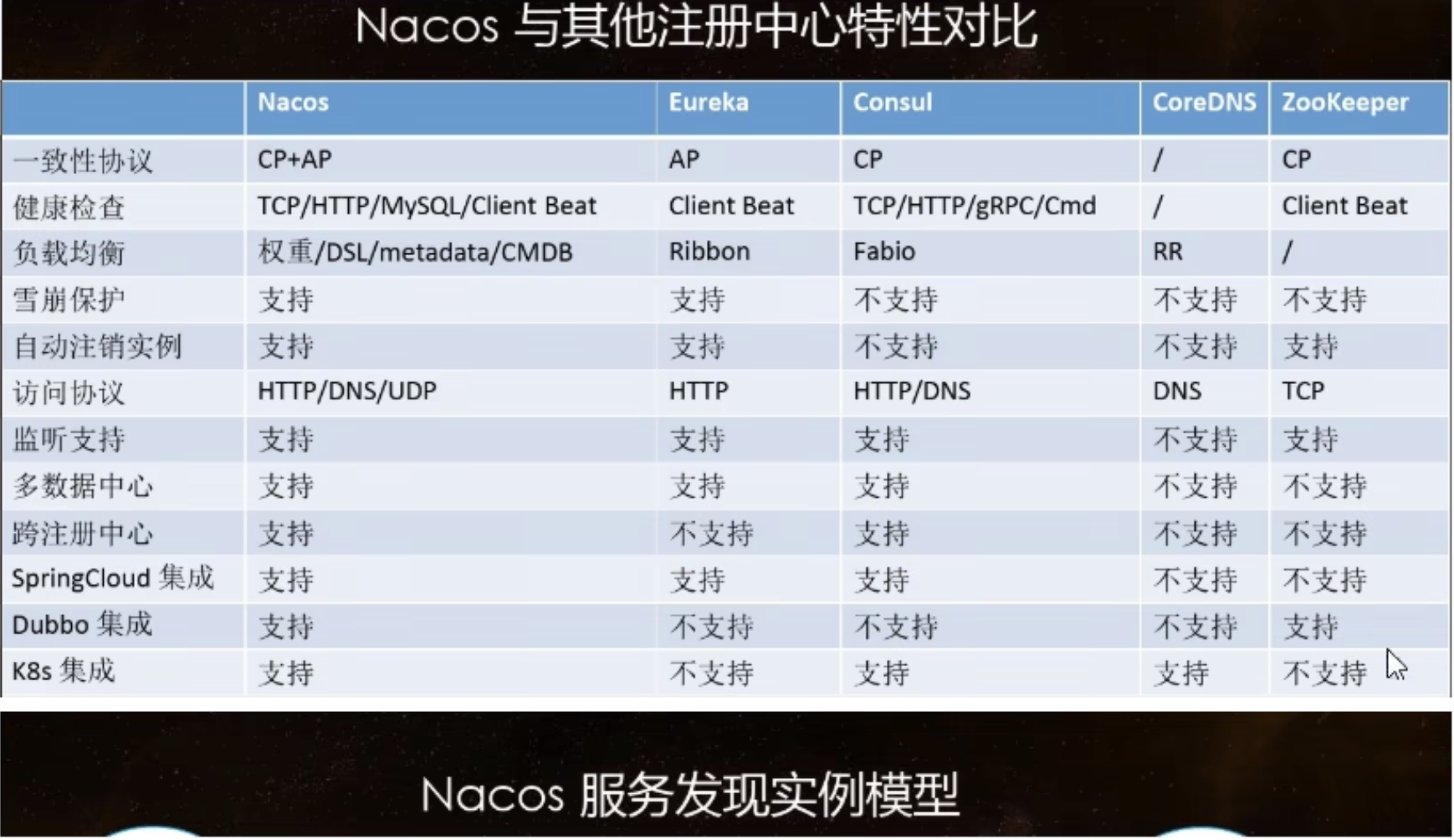
一、Nacos 服务注册中心
Nacos 支持AP和CP模式的切换
- 客户端
关键注解
@SpringBootApplication @EnableDiscoveryClient
依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.kk</groupId>
<artifactId>cloud-api-commons</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
配置
server:
port: 8080
spring:
application:
name: nacos-payment-service
cloud:
nacos:
discovery:
server-addr: 192.168.101.109:8848
management:
endpoints:
web:
exposure:
include: '*'
二、Nacos 作为配置中心
同spring-cloud-config一样,在项目初始化的时候,要保证先从配置中心进行配置拉取,完成后才能保证项目的正常启动。
基础配置
- pom
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.kk</groupId>
<artifactId>cloud-api-commons</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
需要两个yml配置文件: application.yml 、bootstrap.yml
- bootstrap.yml
server:
port: 3377
spring:
application:
name: nacos-config-client
cloud:
nacos:
discovery:
server-addr: 192.168.101.109:8848
config:
server-addr: 192.168.101.109:8848
file-extension: yaml
management:
endpoints:
web:
exposure:
include: '*'
- application.yml
spring:
profiles:
active: dev
三、Sentinel限流规则
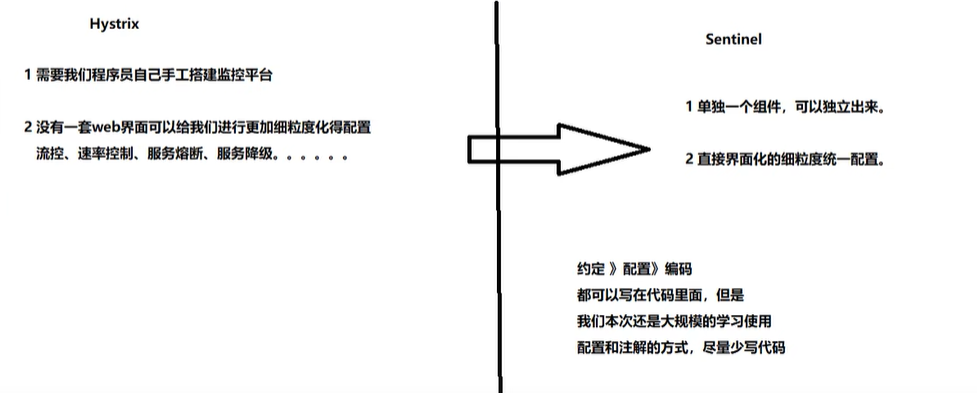
3.1什么是 Sentinel ?
Sentinel是阿里开源的项目,提供了流量控制、熔断降级、系统负载保护等多个维度来保障服务之间的稳定性。
官网:https://github.com/alibaba/Sentinel/wiki
2012年,Sentinel诞生于阿里巴巴,其主要目标是流量控制。

3.2流控规则
阈值类型
-
QPS:每秒的请求数量,当调用该API的请求数达到阈值,进行限流。
-
线程:当调用该API的线程数达到阈值的时候,进行限流。
区别,QPS是拦截其他请求只允许n个请求通过进行处理,线程是所有请求放进来只处理n个其他的不处理。
流控模式
-
直接:API到达限流条件,直接限流。
-
关联:当关联的资源到达阈值时,就限流自己。
-
链路:只记录指定链路上的流量(指定资源从入口资源进来的流量,如果达到阈值,就进行限流)【API级别的针对来源】。
流控效果
-
快速失败:直接失败,抛异常。
-
warm up(预热):根据codeFactor(冷加载因子,默认3)的值,从阈值/codeFactor,经过预热时长,才会达到设定的QPS(每秒的请求数量)阈值。
-
排队等待:请求匀速通过,阈值类型必须设置为QPS,否则无效。对应的是漏桶算法
3.3降级规则
RT,平均响应时间,秒级
-
平均响应时间超出阈值且在时间窗口内通过的请求>=5,两个条件同时满足后触发降级
-
窗口期过后关闭断路器
-
RT最大4900(更大的需要通过 -Dcsp.sentinel.statistic.max.rt=XXX才能生效)
异常比例,秒级
- QPS >=5且异常比例超过阈值时,触发降级;时间窗口结束后,关闭降级。
异常数,分钟级
- 异常数超过阈值时,触发降级;时间窗口结束后,关闭降级。
3.4热点规则
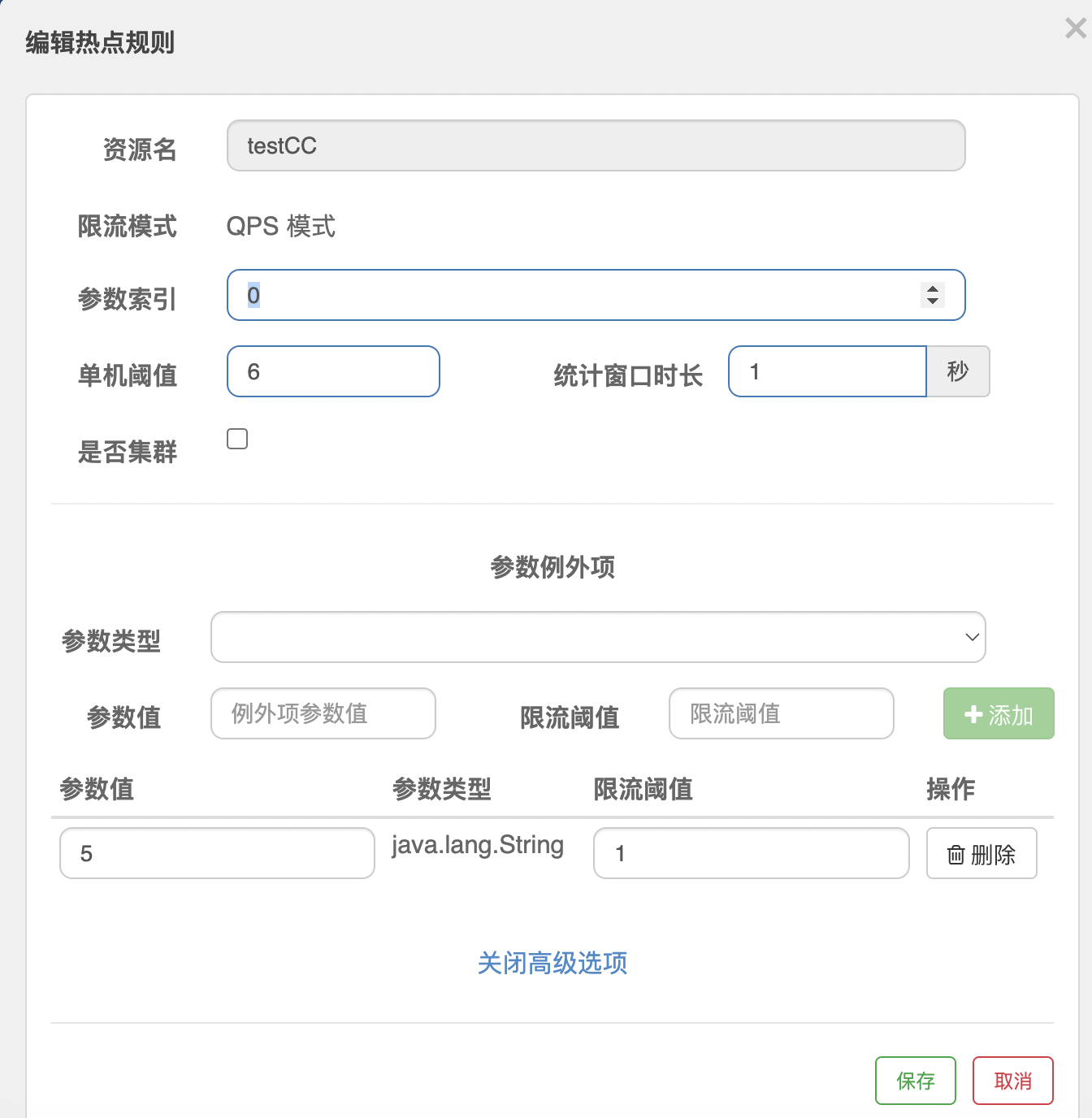
-
请求带了第一个参数,每秒请求超过6次限流
-
当第一个参数为5时,使用新的限流规则
热点即经常访问的数据,很多时候我们希望统计某个热点shu ju访问频次最高的Top K 数据,并对其访问进行限流。
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
Sentinel 利用 LRU 策略统计最近最经常访问的热点参数,结合令牌桶算法来进行参数级别的流控。热点参数限流支持集群模式。
3.5系统规则
系统自适应限流 · alibaba/Sentinel Wiki · GitHub
系统保护规则是从应用级别的入口流量进行控制,从单台机器的 load、CPU 使用率、平均 RT、入口 QPS 和并发线程数等几个维度监控应用指标,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
系统保护规则是应用整体维度的,而不是资源维度的,并且仅对入口流量生效。入口流量指的是进入应用的流量(EntryType.IN),比如 Web 服务或 Dubbo 服务端接收的请求,都属于入口流量。
系统规则支持以下的模式:
- Load 自适应(仅对 Linux/Unix-like 机器生效):系统的 load1 作为启发指标,进行自适应系统保护。当系统 load1 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR 阶段)。系统容量由系统的
maxQps * minRt估算得出。设定参考值一般是CPU cores * 2.5。 - CPU usage(1.5.0+ 版本):当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏。
- 平均 RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
- 并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
- 入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
3.6sentinel持久化配置
一旦我们重启应用,snetinel的配置规则将消失,所以生产环境需要将配置规则持久化。
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
server:
port: 8402
spring:
application:
name: nacos-service-provider
cloud:
nacos:
discovery:
# nacos服务注册中心地址
server-addr: 192.168.101.110:8848
sentinel:
transport:
# sentinel dashboard服务地址
dashboard: 192.168.101.110:8080
# 默认8719,加入被占用会自动+1依次扫描,直到扫描到未占用的端口为止
port: 8719
datasource:
ds1:
nacos:
server-addr: 192.168.101.110:8848
dataId: nacos-service-flow-rules
groupId: DEFAULT_GROUP
data-type: json
rule-type: flow
management:
endpoints:
web:
exposure:
include: '*'
[
{
"resource": "/getPaymentById/{id}",
"limitApp": "default",
"grade": 1,
"count": 1,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]

四、Seata
4.1分布式事务问题
什么是分布式事务?
是涉及到操作多个数据库的事务,可以理解为将对同一个库事务的概念扩大到了对多个库的事务,目的是为了保证分布式系统中的数据一致性。
通俗来讲,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
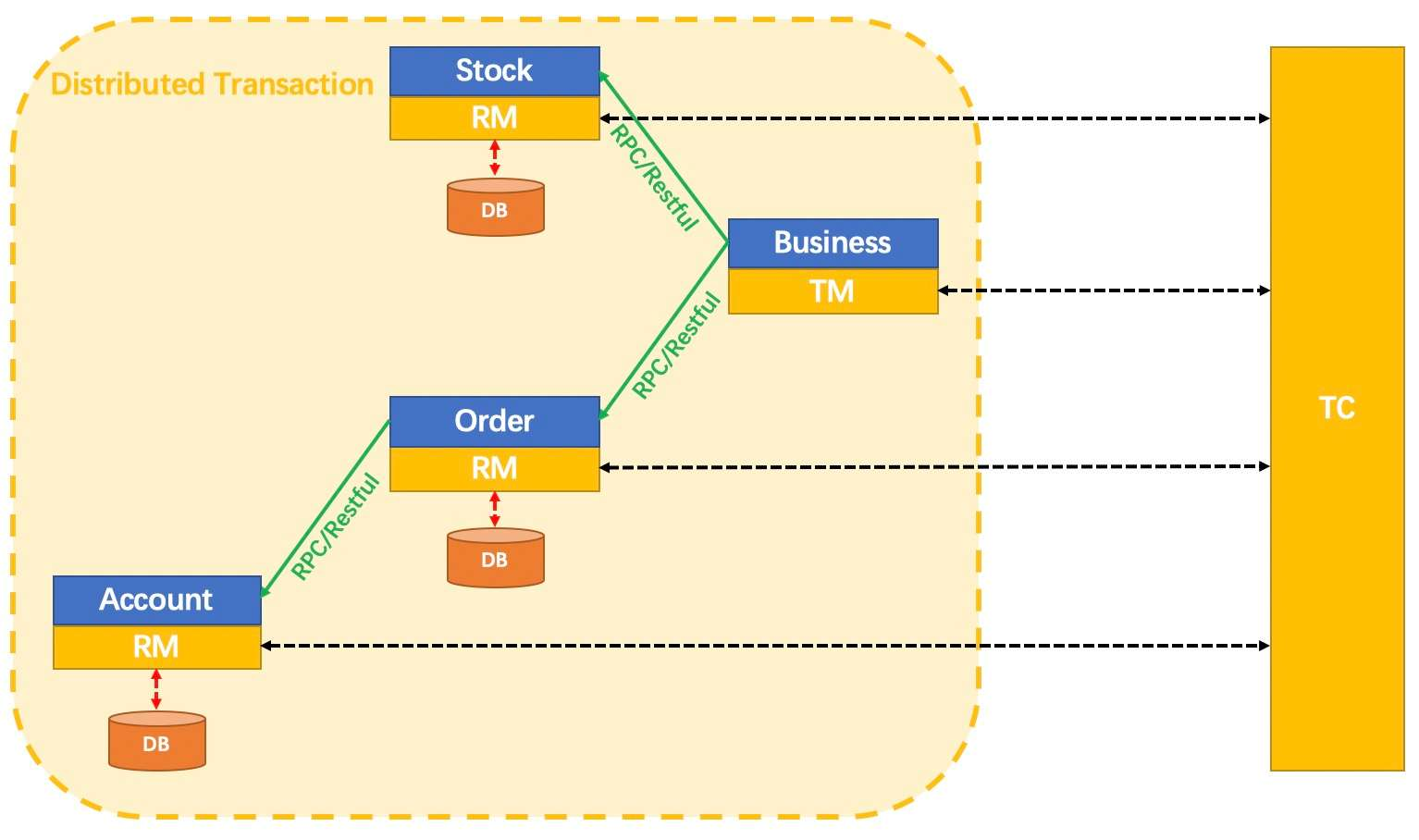
分布式事务处理过程
1ID(全局唯一的事务ID---XID) + 3组件(TC、TM、RM).
4.2什么是Seata?
一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。
seata四种模式:Seata四种模式_seata模式_wuyongde0922的博客-CSDN博客
Seata术语
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。

食用方式
业务方法上加 @GlobalTransactional
4.3集群高并发情况下如何保证分布式全局唯一ID生成?
使用SnowFlake (雪花算法,Twitter分布式自增 id 算法)。
-
每秒大概能产生 26 万个自增 ID,能按时间有序生成;
-
生成结果是一个 64bit 大小的整数,为一个 Long 型;
-
分布式系统内不会产生 ID 碰撞(datacenter 和 workerId)并且效率较高;

第1位:占用1bit,第一位为符号位,不使用。
第1部分:41位的时间戳,41-bit位可表示241个数,每个数代表毫秒,那么雪花算法可用的时间年限是(241)/(1000606024365)=69 年的时间。
第2部分:10-bit位可表示机器数,即2^10 = 1024台机器,通常不会部署这么多台机器,(细分两部分5-bit(数据),5-bit(2^5)=32台机器)也可划分多个部分。
第3部分:12-bit位是自增序列,可表示2^12 = 4096个数。觉得一毫秒个数不够用也可以调大点。
41位时间戳是固定的,时间戳转二进制的长度是41位,后面两个部分都可以灵活调正,只要注意后面位运算的位数就行.
优点:雪花算法生成的 ID 是趋势递增,不依赖数据库等第三方系统,生成 ID 的性能也是非常高的,而且可以根据自身业务特性分配 bit 位,非常灵活。
缺点:雪花算法强依赖机器时钟,如果机器上时钟回拨,会导致发号重复。解决方案:可以参考 1⃣️百度的分布式唯一 id 生成器 UidGenerator,2⃣️美团点评分布式 id 生成系统 Leaf
为什么需要生成全局唯一ID?
在简单的单机版应用,使用全局不重复的 ID 就能满足需求。
在复杂的分布式系统中,需要对大量的数据和信息进行唯一标识,来解决分布式事务问题。
分布式全局唯一ID生成的硬性要求
-
全局唯一 -
趋势递增——MySQL 的 InnoDB 引擎使用的是聚簇索引,由于多数的 RDMS 使用的是 BTree 存储索引数据,在主键选择上应该尽量选择有序的 id,保证写入性能。 -
单调递增 -
信息安全——如果 id 连续,恶意爬取数据就会很容易。 -
含时间戳——可以在开发中快速了解 id 的生成时间,利于问题排查。
系统的可用性要求
-
高可用——发 1个获取 id 的请求,服务器要保证 99.99% 的情况下创建 1个分布式 id。 -
低延迟——发 1个获取 id 的请求,服务器响应要快、极速,毫秒级完成响应。 -
高QPS——一次收到 10万个请求,服务器要顶得住且成功创建 10万个分布式 id。
为什么不使用
UUID、数据库自增auto_increment、redis生成全局唯一ID?
-
uuid,标准形式包含 32 个16进制数和连字号
-,形如8-4-4-4-12。本地生成没有网络消耗 ,性能非常高。 满足全局唯一,但是无序且长,入库会导致系统性能变差。MySQL官方推荐主键尽量越短越好,无序的 uuid 每一次插入都会对主键底层的 B+Tree 进行很大的修改,导致 B+Tree 中间节点分裂创造出很多不饱和的节点,大大降低系统性能。 -
数据库自增,由数据库自增 id 和数据库的
replace into实现。replace into和insert into类似,不同在于 replace into 会首先尝试插入数据库列表中,如果发现表中已经有此行数据则先删除原数据,再插入新数据。 满足全局唯一、递增,可以作为分布式全局 id 但是不太合适,如果 10万个请求一下全打在MySQL数据库,数据库是扛不住的。还有每次获取 id 都会操作数据库,不满足低延迟。 -
redis,是单线程的所以天生保证原子性,可以使用原子操作 INCR 和 INCRBY来实现。分布式集群环境下,和MySQL一样要设置步长,key还要设置过期时间。可以使用rerdis 集群来获取更高的吞吐量,但是搭建很复杂。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号