
由导出引申了解http
缓存的过程:
(1)默认情况下,浏览器都会使用缓存数据,默认情况下服务器端以及前端都会使用缓存数据
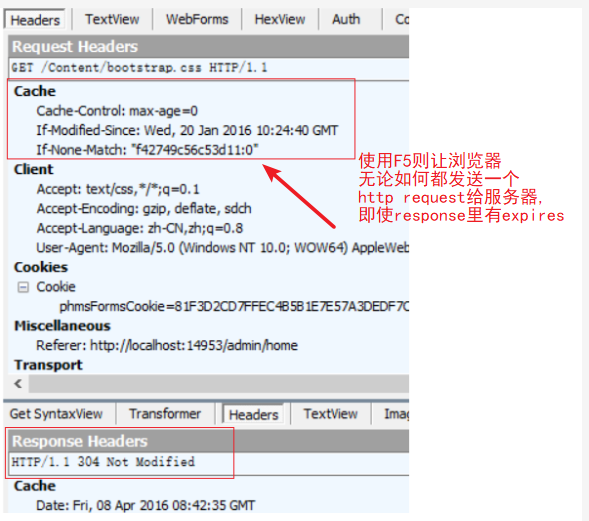
(F5的作用和直接在URI输入栏中输入然后回车是不一样的,F5会让浏览器无论如何都发一个HTTP Request给Server,即使先前的Response中有Expires Header;而浏览器直接回车则表示直接应用缓存不需要去服务器验证;一般我们考虑的都是F5的场景
那么Ctrl+F5呢? Ctrl+F5要的是彻底的从Server拿一份新的资源过来,所以不光要发送HTTP request给Server,而且这个请求里面连If-Modified-Since/If-None-Match都没有,这样就逼着Server不能返回304,而是把整个资源原原本本地返回一份。
参考:https://www.cnblogs.com/xiangcode/p/5369084.html)
(2)当第一次发送请求时,http返回状态码200并且当没有关闭缓存请求,则会返回包含last-modify和Etag和expires的字段,,然后将文件保存在Cache目录下;当后续请求该文件时候,先在本地查找该资源,如果在本地缓存找到对应的资源,但是不知道该资源是否过期或者已经过期, 则发一个http请求到服务器,然后服务器判断这个请求,
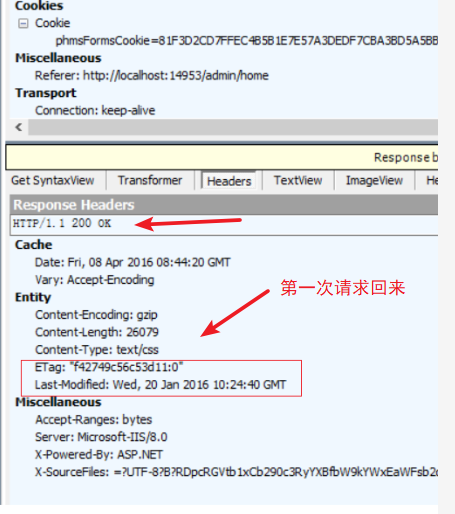
(3)再次请求时则会携带上If-modify-since和expires和Etag等(通过在URI输入栏直接敲字的方法访问http://localhost/home的时候,浏览器一看本地有个bootstrap.css,而且它还没过期呢,就不会发HTTP request给server,而是直接把本地cache中的bootstrap.css显示了。)
实际上,为了保证拿到的是从Server上最新的,Ctrl+F5不只是去掉了If-Modified-Since/If-None-Match,还需要添加一些HTTP Headers。按照HTTP/1.1协议,Cache不光只是存在Browser终端,从Browser到Server之间的中间节点(比如Proxy)也可能扮演Cache的作用,为了防止获得的只是这些中间节点的Cache,需要告诉他们,别用自己的Cache敷衍我,往Upstream的节点要一个最新的copy吧。
在IE6中,Ctrl+F5会添加一个Header
Pragma: no-cache
在Firefox 2.0中,Ctrl+F5会添加两个
Pragma: no-cache
Cache-Control: max-age=0
作用就是让中间的Cache对这个请求失效,这样返回的绝对是新鲜的资源

1.http中response缓存常用字段
expires:
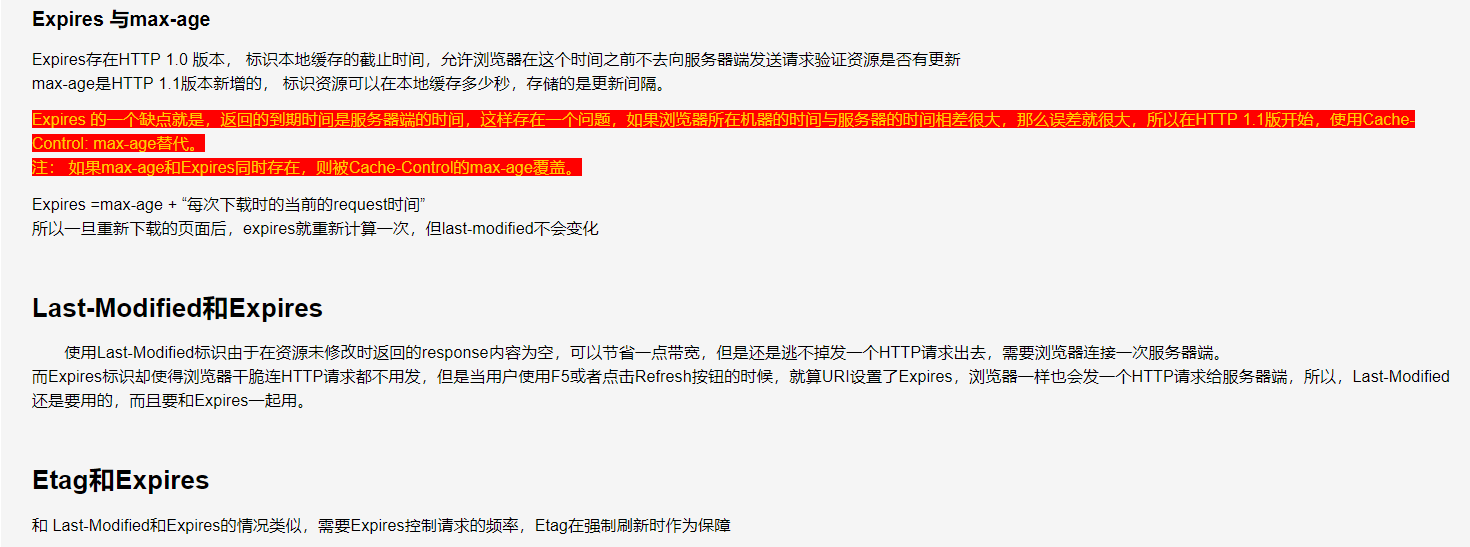
(1)是http1.0时定义的header,是最基础的缓存,它可以另该请求直接从浏览器的缓存中获取,不用向浏览器发送请求,
在response的header中的格式为:Expires: Thu, 01 Dec 1994 16:00:00 GMT (必须是GMT格式)
应用:1)可以在html页面中添加<meta http-equiv="Expires" content="Thu, 01 Dec 1994 16:00:00"/> 来给页面设置缓存时间。
2)对于图片、css等文件则需要在IIS或者apache等运行容器中进行规则配置来让容器在请求资源的时候添加在responese的header中。
缺点是:1)返回的是服务器的时间,比对的是本地和服务器时间,这样当本地时间有误差,那就会存在很大误差 2)当使用F5或者Ctrl+F5强制刷新时,就算URI设置了Expires,浏览器一样也会发一个HTTP请求给服务器端,所以,Last-Modified还是要用的,而且要和Expires一起用。
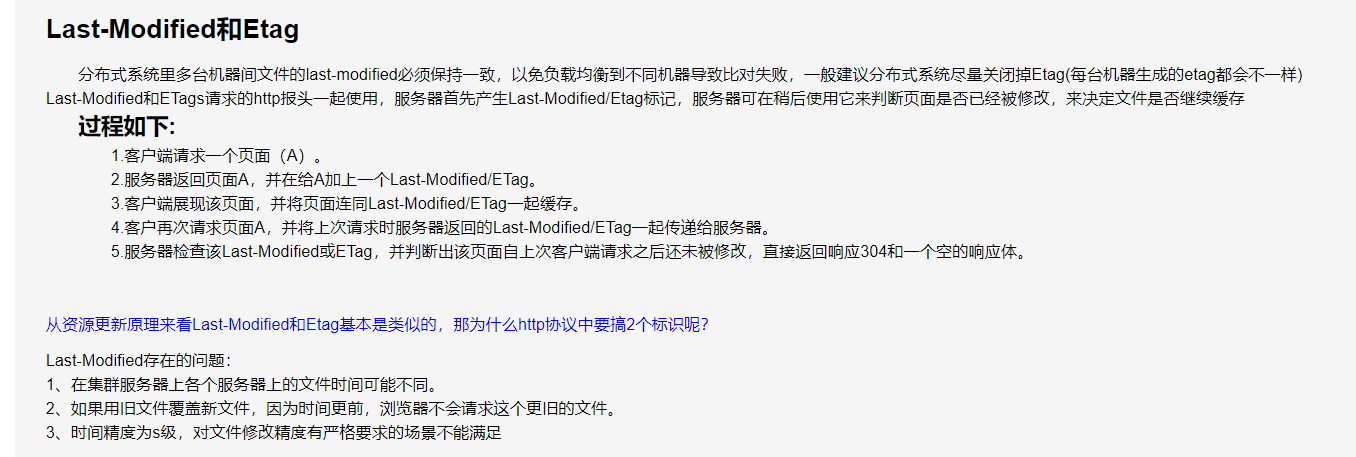
last-modify:
(1)当请求某个静态资源时,服务器返回状态码200,返回的内容是请求的资源,并且response header里添加上一个Last-Modified的属性标记,标识此文件在服务期端最后被修改的时间,格式:Last-Modified:Tue, 24 Feb 2009 08:01:04 GMT
(2)下次再请求该资源时浏览器会自动添加If-modify-since的属性标记到request header,格式为:If-Modified-Since:Tue, 24 Feb 2009 08:01:04 GMT
(3)如果服务器端的资源没有变化,则服务器返回304状态码(Not Modified),内容为空,这样就节省了传输数据量。当服务器端代码发生改变,则服务器返回200状态码(ok),内容为请求的资源,和第一次请求资源时类似。从而保证在资源没有修改时不向客户端重复发出资源,也保证当服务器有变化时,客户端能够及时得到最新的资源。
注:如果If-Modified-Since的时间比服务器当前时间(当前的请求时间request_time)还晚,会认为是个非法请求
Etag:
http/1.1 中增加的header,HTTP协议规格说明定义ETag为“被请求变量的实体值” 。可以类似的认为当资源内容不变时则生成的Etag是不变的
1)当浏览器首次请求资源的时候,服务器会返回200的状态码(ok),内容为请求的资源,同时response header会有一个ETag标记,该标记是服务器端根据容器(IIS或者Apache等等)中配置的ETag生成策略生成的一串唯一标识资源的字符串,ETag格式为 ETag:"856247206"
2)当浏览器第2次请求该资源时,浏览器会在传递给服务器的request中添加If-None-Match报头,询问服务器改文件在上次获取后是否修改了,报头格式:If-None-Match:"856246825"
3)服务器在获取到浏览器的请求后,会根据请求的资源查找对应的ETag,将当前服务器端指定资源对应的Etag与request中的If-None-Match进行对比,如果相同,说明资源没有修改,服务器返回304状态码(Not Modified),内容为空;如果对比发现不相同,则返回200状态码,同时将新的Etag添加到返回浏览器的response中。
2.http中request缓存常用字段
(1)cache-control:
其缓存指令对于前段常用的有如下no-cache、no-store、max-age这几个值;分别来说一下
no-cache:
表面意为“数据内容不被缓存”,而实际数据是被缓存到本地的,只是每次请求时候直接绕过缓存这一环节直接向服务器请求最新资源,由于浏览器解释不一样,
例如ie中我们设置了no-cache之后,请求虽然不会直接使用缓存,但是还会用缓存数据与服务器数据进行一致性检测(也就是说还是有几率会用到缓存的),
firefox中则完全无视no-cache存在,详细解释见no-store;
no-store:
指示缓存不存储此次请求的响应部分。与no-cache比较来说,一个是不用缓存,一个是不存储缓存;按理来说这个设置更加粗暴直接禁用缓存,
但是具体实现起来 浏览器之间差异却特别大,一般不会直接用该字段进行设置,不过no-store是为了防止缓存被恶意修改存储路径导致信息被泄露而设置的,
毕竟有它的用处,在firefox中实现缓存是通过文件另存为将缓存副本保存到本地,直接利用no-cache对其是无效的,如果加上no-store设置的话 则可以起到与no-cache一样的效果;
即:cache-control:no-cache,no-store;可以确保在支持http1.1版本中各大浏览器回车后退刷新无缓存;
再加上Pragma: no-cache设置兼容版本1.0即可(不过为了防止一致性检测时候的万一我们还是最好加上一致性检测的内容,如下所示几种方式);
max-age:
例如Cache-control: max-age=3;表示此次请求成功后3秒之内发送同样请求不会去服务器重新请求,而是使用本地缓存;同样我们如果设置max-age=0表示立即抛弃缓存直接发送请求到服务器
一致性检测分为两种方式:1.检测日期是否过期,检测资源是否更新;
(2)if-none-match:
该字段与响应中的eTag一起使用,表示检查实体是否有更新改变;客户端第一次发送请求时候响应报文会包含字段Etag,表示资源状态,当资源改变后该值也会改变(客户端不必关心该值怎么生成)
然后缓存保存下该字段,第二次已经有该缓存时候在浏览本地缓存时候会将该值赋给if-none-match字段发送给服务器,服务器将发送的值与当前的状态进行对比,
如果值一样的话则答复304去使用缓存数据,如果值改变了则发送最新数据给客户端替代现有缓存数据,并且返回状态200;
(3)if-modified-since:
该字段与last-modified配合使用,跟上述原理差不多,都是响应端先返回一个last-modified时间字段,再次请求时候 request头部会将缓存中的last-modified字段拿出来赋给if-modified-since,
发送给服务器,服务器去判断时间是否过期,如未过期则返回304,告诉客户使用缓存数据,如果过期则重新返回一个last-modified并且返回200;
几者之间的关系:
3.禁用缓存.使用缓存:
使用缓存:
实际中大部分不需要我们手动去实现,而有些我们不确定是否使用缓存的情况下我们可以手动加以干涉强制使用缓存数据:
例如某个静态文件包括html或者图片我们需要使用缓存来提高处理速度,
(1)设置一个很长的expires或者catch-control:max-age=xxxx;css.js.图片的静态资源设置一个协商缓存(last-modify和Etag),防止强制刷新或者F5等发起请求;不过这样用回车输入网址时浏览器就无法主动的得知服务器上的静态资源是否变化了(被强缓存了)
(2)一般静态资源都是嵌入html中,所以一般将html禁用强缓存(给html设置响应头cache-control:no-cache 还是可以协商缓存,别用no-stroe这个直接不协商缓存),让浏览器每次都能拿到最新的html资源;而html里面的静态资源css.js.图片等可以通过加hash值命名或者加版本号等方法,这样就是一个新的请求就没有缓存问题了
禁用缓存:
方法一:
可以在meta标签标明<meta http-equiv="pragma" content="no-cache">
<meta http-equiv="cache-control" content="no-cache">
<meta http-equiv="expires" content="0">
方法二:
也可以动态去setRequestHeader,强制不用缓存设置组合如下:
cache-control='no-cache,no-store'
pragma='no-cache'
if-modified-since=0;
方法三:
请求端设置if-modified-since为已经过期的某个时间,可以是几年前或者几十年前。
方法四:
服务端设置Expires为过期某个时间,例如php中header("Expires: Mon, 26 Jul 1997 05:00:00 GMT");
实际开发中如果需要一致性检测则尽量去配合Etag以及last-Modified去进行比较然后返回使用缓存还是新数据;这个有点偏服务器端了,不再赘述
方法五:
url后面加随机数或者时间戳url += “&random=” + Math.random()这个方法js以及php经常用,原理就是每个请求的url都不一样这样一来缓存中找不到对应数据,就自动去服务器寻找最新资源;
最后回到上篇开始提到一个问题;请求服务器时间,由于缓存导致时间返回问题:
问题回顾:由于没有设置缓存,默认浏览器是读取缓存数据的,导致我没清缓存情况下一直使用缓存数据,这样一来我就取不到真正的当前服务器时间了。
解决方式:利用上述方法二+方法四,动态在请求时候修改header以及根据随机数去请求最新数据,问题解决!!!
参考:https://blog.csdn.net/u012545279/article/details/17679061
https://blog.csdn.net/u012545279/article/details/17579155
https://www.cnblogs.com/guojiao1600/p/5110971.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号