sqlmap Bool型&延时型 检测策略分析
sqlmap Bool型&延时型 检测策略分析
0x00 预备-queryPage()
首先先讲一个核心的函数:queryPage()。这个函数在以下分析中贯穿始终。其被用于请求页面, 同时具有多种返回值以适配多种检测策略,见下图:
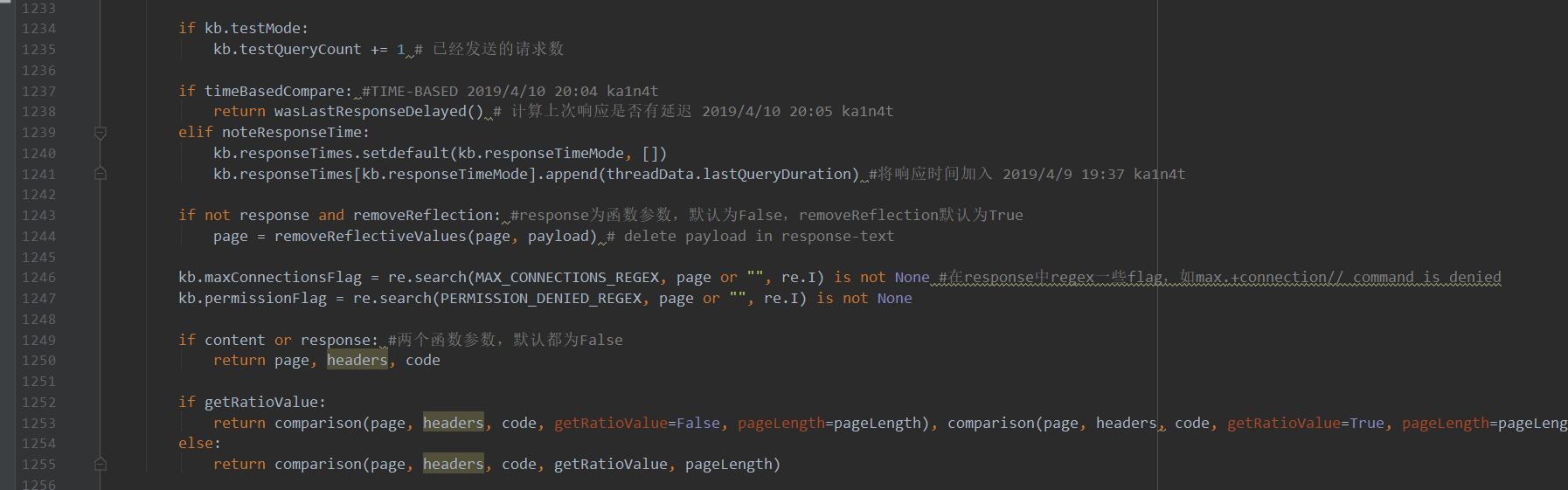
下面分析一下这几个return的情况。
第一个return:1237行,如果传入timeBasedCompare=True,则return wasLastResponseDelayed(),这个语句会在延时型注入中用到。函数wasLastResponseDelayed()的返回值为一个布尔值,如果上次请求有延迟则为True,反之为False。这个函数的具体的实现见延时型检测策略的判断依据部分。
第二个return:1249行,其中content和reponse都是函数参数传过来的,默认为False,如果为true则返回这次请求的响应体、响应头、响应码。
第三个return:1252行,getRatioValue也为函数参数传来的,如果为True,则返回一个元组,两个元素分别为两个comparison函数的返回值,此元组为(布尔值, ratio)(注:ratio为两次请求的响应内容的重合率,被用作判断页面是否变化的依据)。comparison函数被应用在Bool型盲注中,其具体实现逻辑见bool型检测策略的判断依据部分。
第四个return:1254行,为上一个return的else条件,直接返回ratio值。
0x01 bool型检测策略
首先bool型检测之前,程序会提前检测页面是否稳定(checkStability()),即测试两个参数相同的请求的响应是否相同,如果不同则说明页面中有可能存在类似于时间戳的东西。如果动态内容对页面改动较大(ratio<0.98,ratio为调用quick_ratio的值,此函数原理下方说明),则调用findDynamicContent函数,去定位页面中动态内容的位置,并将其定位存在kb中。
然后到了bool型检测代码段,先上图
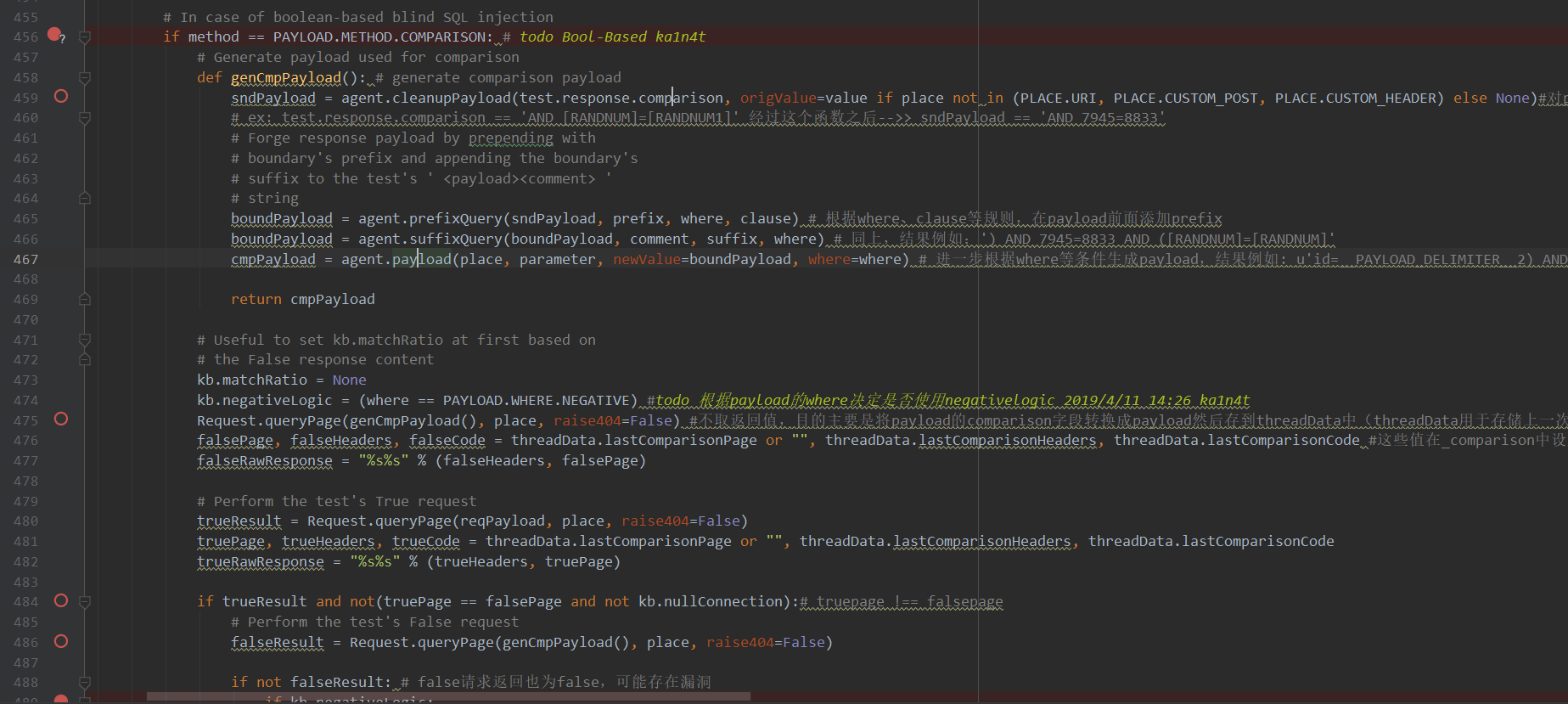
首先看到475行调用了queryPage函数,其payload参数位置传入了getCmpPayload(),getCmpPayload这个函数主要是根据每个payload对应的comparison标签构造CmpPayload(用于与payload标签进行比较,比如payload为1=1,那么CmpPaload就是类似为1=2)。可以看到这一步程序没有取queryPage的返回值,因为其主要作用是设置threadData中的lastPage之类的值,用于下一次True请求与之比较。紧接着就会发现476行直接把threadData的几个last变量传给了falsePage\falseHeaders\falseCode,方便下面比较。
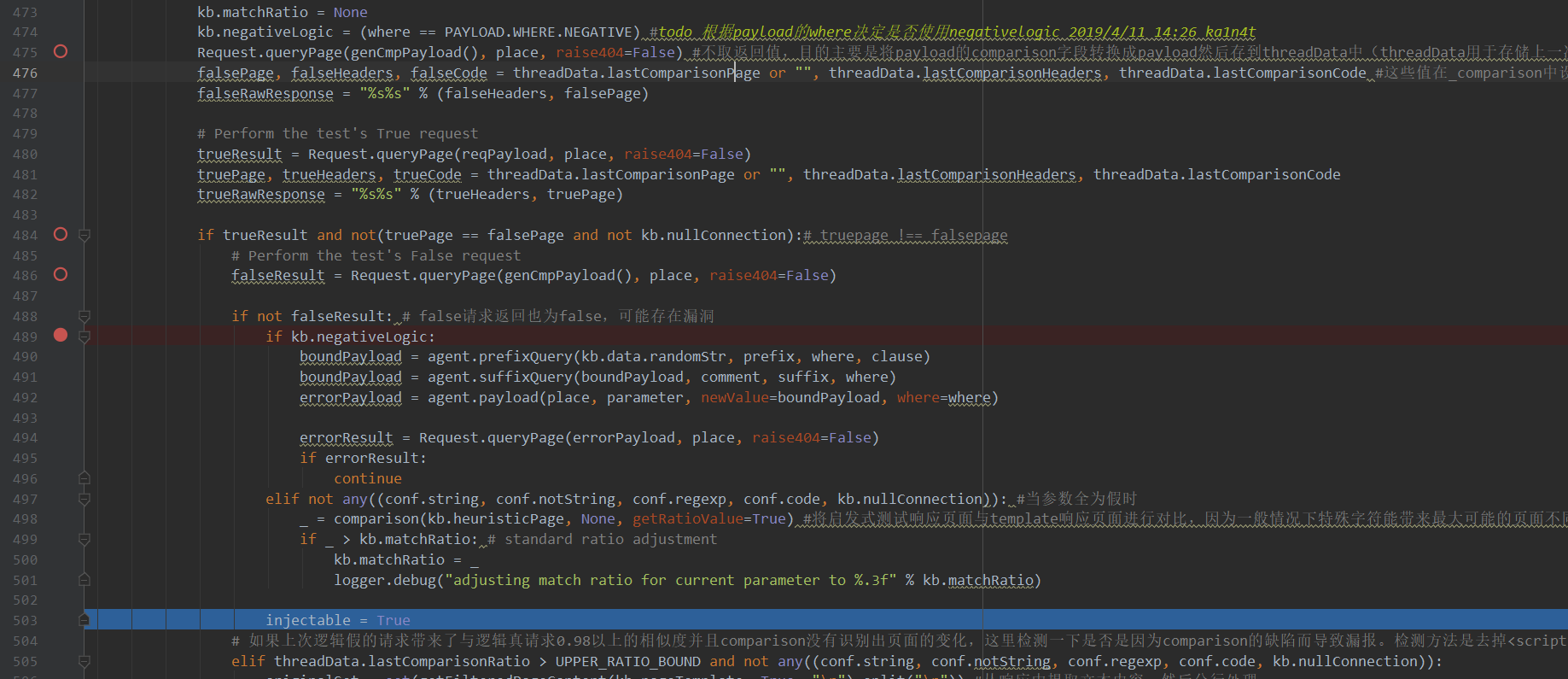
接着看到480-482行发送了True逻辑的请求,并将其响应也赋值给对应的truePage\trueHeaders\trueCode。这里queryPage的返回值赋值给了trueResult,这个函数的返回值已经在第0部分中说了,由于这里没有传入什么多余的参数,因此进入的是第四个return,即一个布尔值,代表较ori_page,这个界面是否发生了变化。
然后在484行进行if判断,当true与false响应不同时进入(bool注入可能存在的基础)。进来后再次进行一次false判断用于防止误报,如果comparison返回的还是false,那就基本上确定为存在漏洞。反之,如果这次返回了True,与第一次的结果不同,那么还要进行下一次防止误报,尝试了解为什么会结果不同。
这就来到了505行:
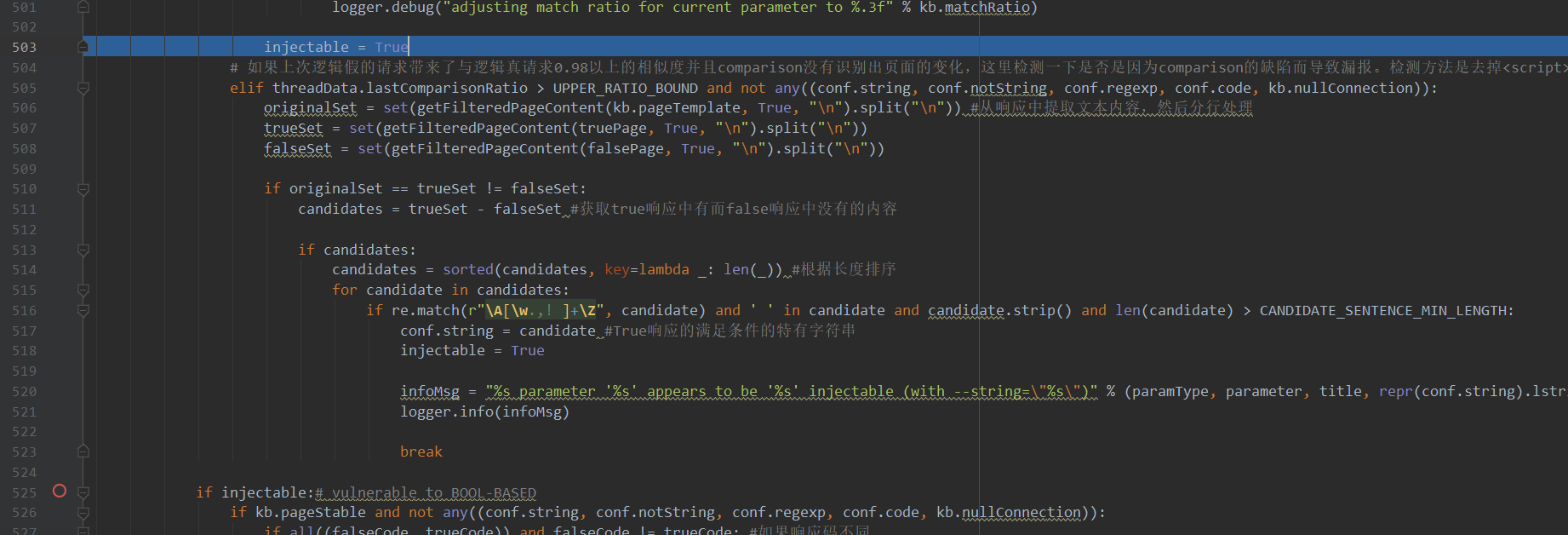
这里的防误报原理主要是提取响应中的文本内容,然后将响应内容中的纯文本内容拿出来进行单独对比(即去掉script、css、注释、html等标签),同理,如果有True响应中有而False中没有的字符串,则确认为有漏洞。
然后剩下的525行之后,如果确认存在漏洞需要进行的内容,就是输出一些bool型注入的判断依据字符之类的东西,这里就不在跟进了。如下图:

判断依据
comparison()函数原理:

经查看代码可以发现,其主要调用的是_comparison(),因此下面对这个函数进行详细的分析。
首先以kb.pageTamplate作为与本次请求对比的响应,这个变量是程序在初始化阶段调用checkConnection()设置的,其请求中不包含payload。
然后在根据上面的动态内容位置,去掉kb.pageTamplate和本次请求响应中的动态内容。见89-90行
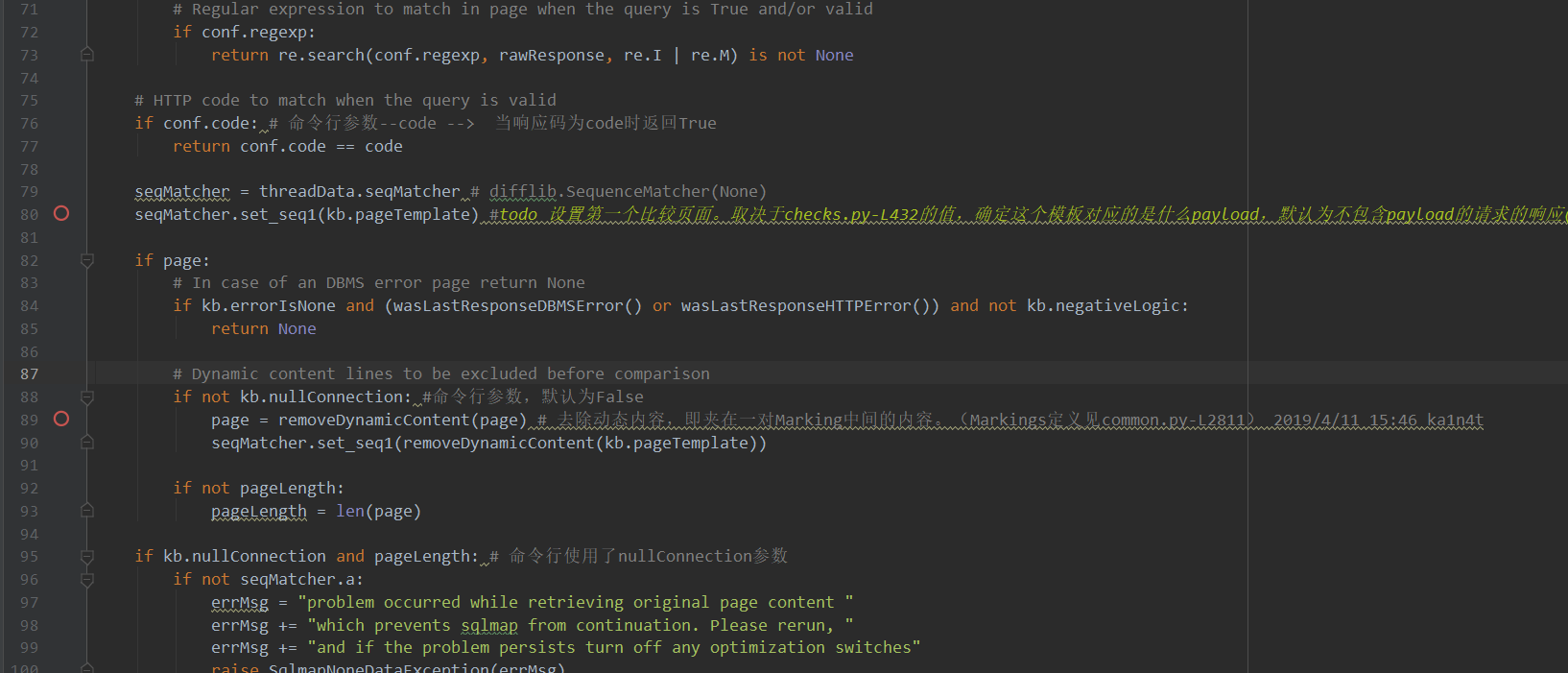
最后调用difflib库的quick_ratio方法,计算两者的页面相似比率,将之赋值给ratio。见139行

程序事先定义了两个常量:
LOWER_RATIO_BOUND==0.02
UPPER_RATIO_BOUND==0.98
然后设置kb.matchRatio,当ratio在两者中间时,程序会将ratio赋值给kb.matchRatio。见143-146行
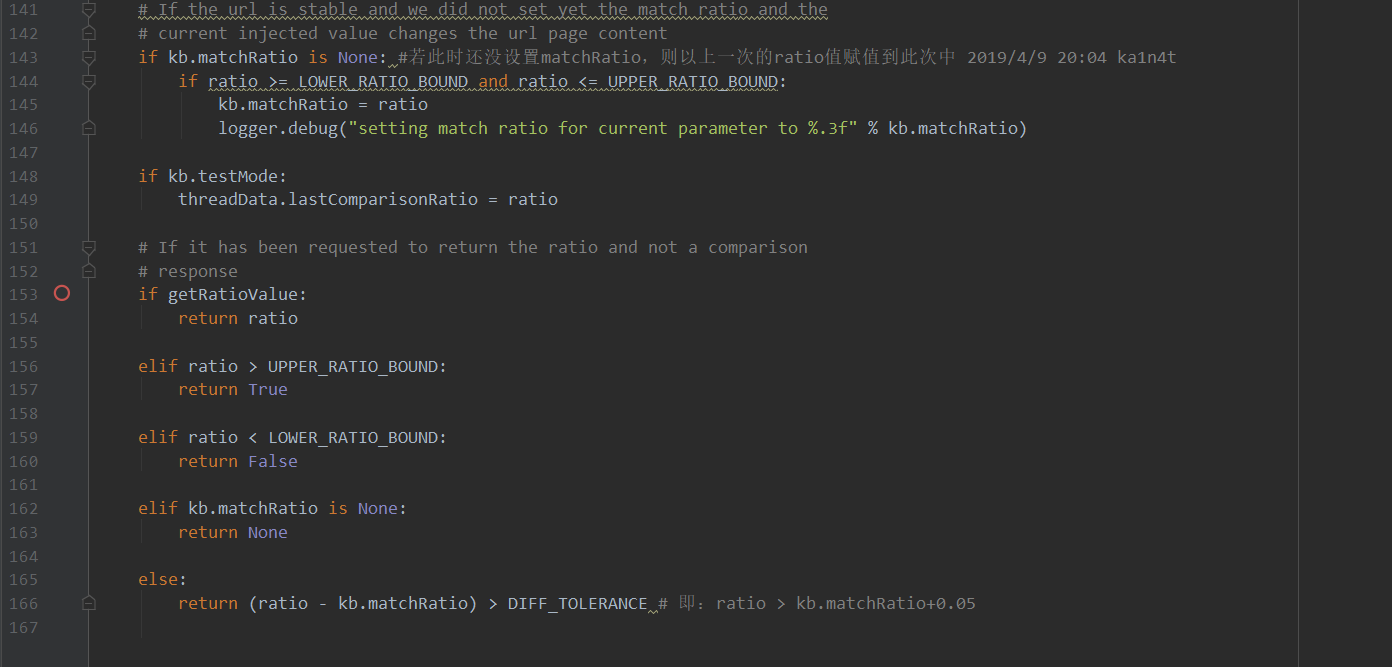
最后return时,此函数分为了以下几种情况:
1.当ratio>0.98时返回True,即判断为页面相同;
2.ratio<0.02时判断为页面不同;
3.return (ratio - kb.matchRatio) > DIFF_TOLERANCE(0.05),kb.matchRatio是一个在0.02与0.98之间的值,在上面已经说了,是在一次请求中使用ratio赋值的。这个return的判断可以转换成ratio>kb.matchRatio+0.05,也就是说ratio必须大于之前的一次ratio至少0.05才行,同时如果ratio>0.98也是直接返回True的(第一次的条件)。
quick_ratio()
统计字符的个数(比如字母a有29个等等),然后拿匹配的字母数*2/两个对比字符串的字符总数
案例
下面看一下在使用正确的boundary突破边界之后,True请求和False请求的最终对比界面是什么。
首先是一个正常请求的响应(www.test.com/index.php?id=2):
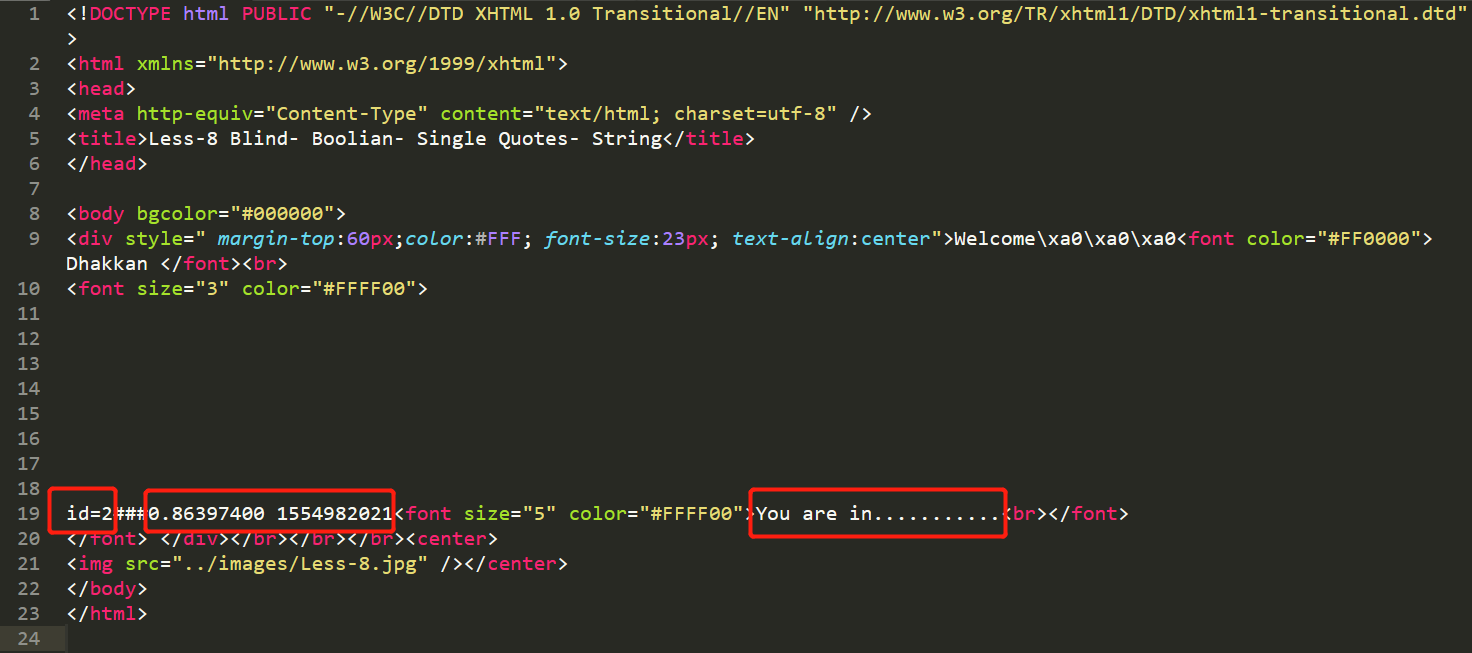
第一个框是直接返回url中的参数值,即id=2。
第二个框是时间戳,即保证在每次响应这一部分都是变化的。
第三个框是“you are in”,表示可以在数据库中找到数据,看一下源码:
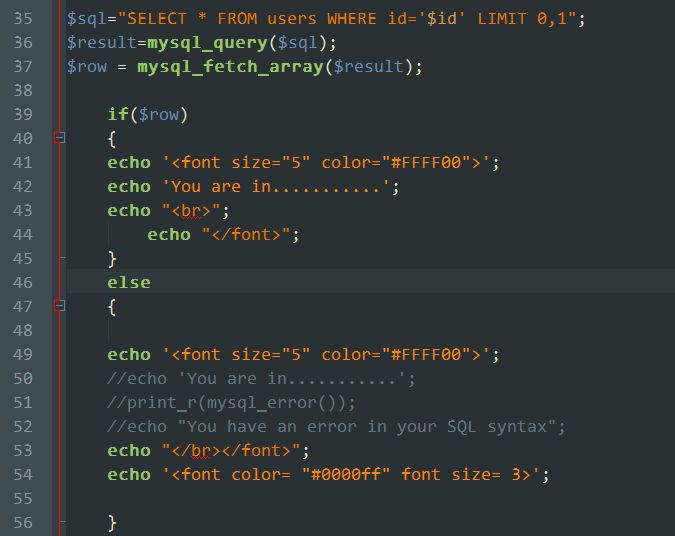
下面先看一下True请求的响应。
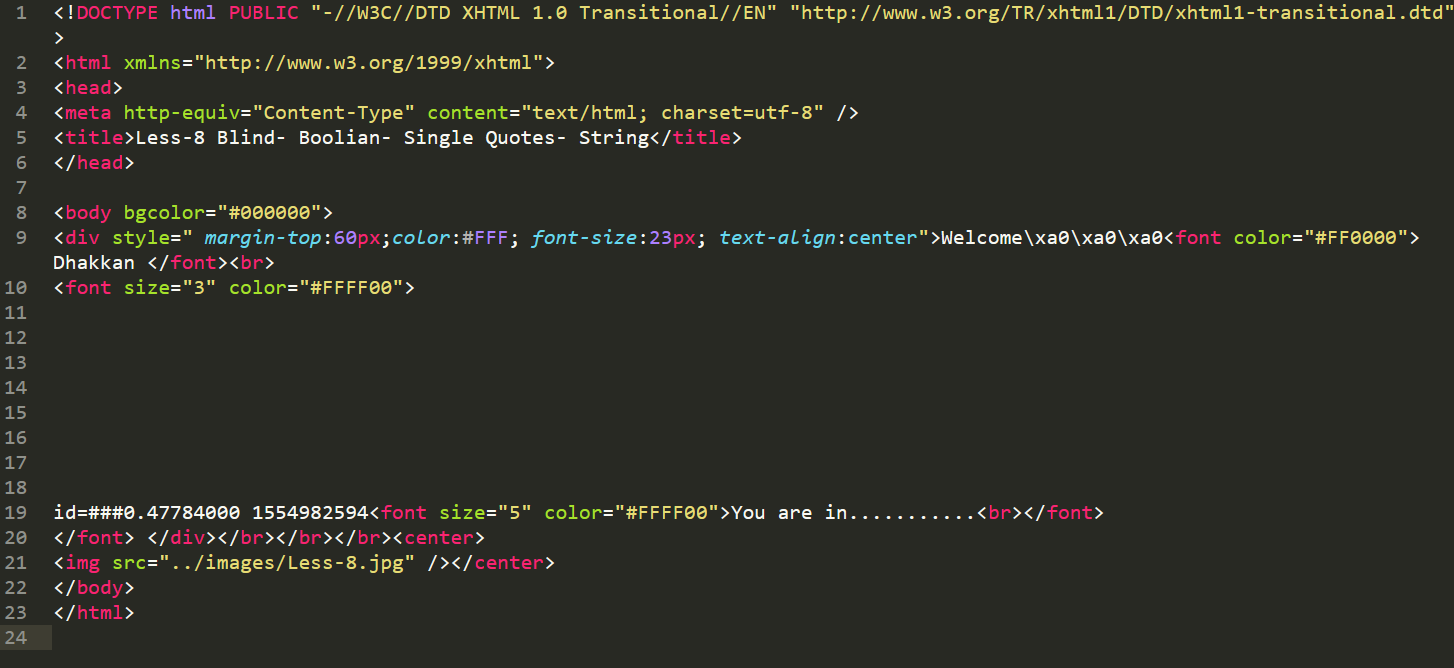
可以看到,第一个框处只有id=,没有id的值,这是因为在进行对比之前,为了避免“payload本身就是不同的”这种影响,实现就已经去掉了这些反射型的参数(类似于xss,即页面直接返回了用户可控的参数)。
再False的响应。
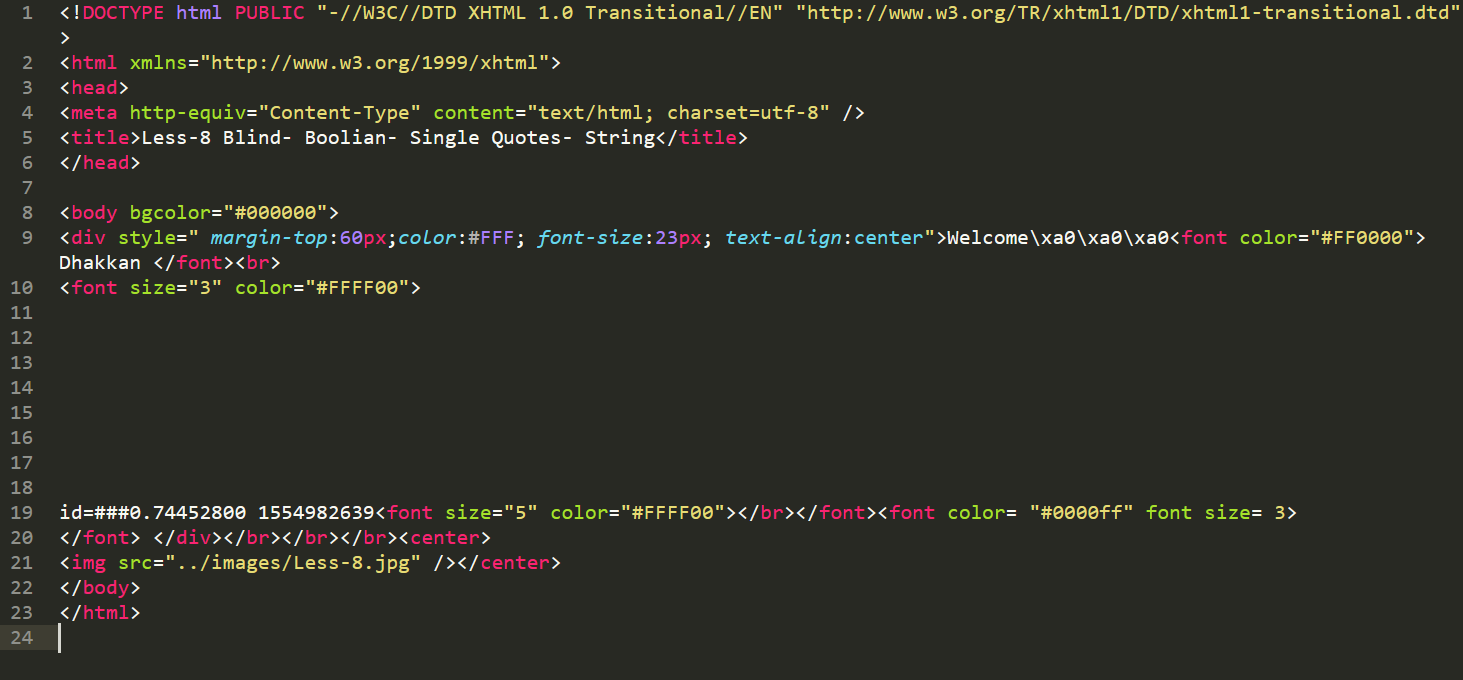
这里也没有第一个框,跟True响应的情况相同。同时这里也没有第三个框,因为这个False语句构建了一个逻辑假的SQL语句,直接导致程序无法在数据库中找到数据。
0x02 延时型

598行开始进行延时型判断,600行调用queryPage函数,返回值为一个布尔值,True表示这次请求产生了延迟(见‘判断依据’部分),code为http响应码。
接着进入603行的if语句,如果上次存在延时则进入(由于payload中使用了[SLEEPTIME],在queryPage中将之替换成了一个值,所以如果存在漏洞则一定会有延时)。
如果进入了这个语句块则再次进行一次时延时间为0的请求,如果还是产生时延则说明为误报。如果没有时延则在611行再进行一次有时延时间的请求,结果如果还是True(与603行结果一致),则确定为存在漏洞。
判断依据
判断本次请求是否产生延迟调用的是wasLastResponseDelayed函数,先放个图:
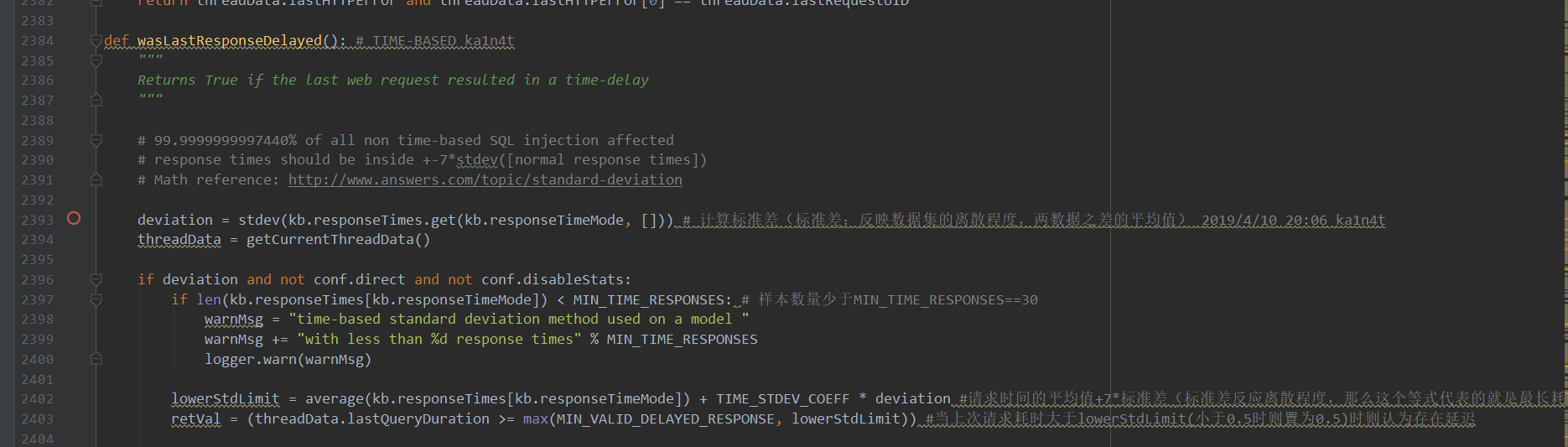

可以看到,首先计算标准差:deviation。然后在2402行计算lowerStdLimit,值为平均数+7*标准差,以这个值看做一个阈值,作为最大延迟时间(小于0.5时看做0.5)。大于这个数的请求都看做是发生延时的请求。+-7*标准差能保证99.9999999997440%的未延时请求能落在这个区间里。
使用标准差的原因
为什么不是平均值呢,因为标准差更能反映一组数据的离散程度。比如熊的平均体重是140kg,标准差为5kg,那么一只熊的重量可能在135-145kg(根据标准差计算)之间,也有可能在120-160kg(根据平均数猜测)之间。因此仅仅查看所有熊的平均重量就不可能知道单个熊的重量,但是标准差可以告诉你单个熊的可靠重量范围。这就是这里使用标准差的意义。
参考:
1.How Self-Tuning Threshold Baseline is Computed
2.标准差的意义
0xFF参考:
sqlmap 检测剖析 -- 凤雏
Python:SQLMap源码精读—基于时间的盲注(time-based blind) -- 曾是土木人
sqlmap time-based inject 分析 -- 美丽联合SRC
sqlmap基于时间盲注判断原理 -- think_ycx
Sqlmap如何检测Boolean型注入 -- lufei
sqlmap中文手册 -- werner-wiki
超详细SQLMap使用攻略及技巧分享

 浙公网安备 33010602011771号
浙公网安备 33010602011771号