pandas基本操作
1.导入包
import pandas as pd
2.创建dataFrame
#从文件创建 df_from_excel = pd.read_excel('D:\.......\测试.xlsx','Sheet1') #用字典创建 df1 = pd.DataFrame({'保单号':['AA0011','AA0011','AA0011','AA0011','AA0011','BB0022','BB0022','BB0022','BB0022','BB0099'], '伤情类型':['门诊',np.nan,'住院','住院','死亡','住院','住院','门诊','住院','死亡'], '邮箱地址':['aaa@163.com','aaa@163.com','aaa@163.com','aaa@163.com','aaa@163.com','bbbbb@163.com','bbbbb@163.com','bbbbb@163.com','bbbbb@163.com','cccccccc@163.com'], '赔款':[100,2000,600,400,np.nan,59211,6542,2006,6542,500000]})
3.空值处理
# 填充空值 # 单个字段空值填充 df1.伤情类型.fillna('门诊',inplace = True) df1.赔款.fillna(0,inplace = True) # 多个字段空值填充 df1.fillna({'伤情类型':'' ,'赔款':0},inplace = True) # 删除空值 # dropna函数:axis = 0 表示按行,axis = 1 表示按列 (默认情况下:axis = 0) # dropna函数:how = 'all' 表示全部为空,how = 'any'表示任意一个为空 (默认情况下:how = 'any') df1.dropna() # 表示只要有一个字段有空值(nan),则删除这一行 df1.dropna(axis = 1) # 表示只要这一列有空值,则删除这一列(一般不会这么做,这样会删掉一个特征) df1.dropna(how = 'all') # 删除整行都为空值(nan)的空行 df1.dropna(how = 'all',axis = 1) # 删除整列都为空值(nan)的空列 df1.dropna(subset = ['伤情类型', '赔款']) # 删除‘伤情类型’和‘赔款’这两列中有空值(nan)的行 df1.dropna(subset = ['伤情类型'],inplace=True) # 就地修改,不返回副本
4.选取数据
df1.保单号 # df.(点)的形式,仅限单个字段 df1['保单号'] df1[['保单号','赔款']] # 按条件选取 df1[df1.保单号 == 'AA0011'] df1[df1.保单号 == 'AA0011']['保单号'] df1[df1.保单号 == 'AA0011'].保单号 df1[df1.保单号 == 'AA0011'][['保单号','伤情类型']] # 多个条件必须加小括号(),&表示and |表示or df1[(df1.保单号 == 'AA0011') & (df1.伤情类型 == '住院')][['保单号','伤情类型']] df1[(df1.保单号 == 'AA0011') | (df1.保单号 == 'BB0022')][['保单号','伤情类型']] #### 用loc()函数选取数据 # loc()有两个参数,第一个是对行筛选,第二个是对列筛选 df1.loc[:,['保单号','赔款']] # 选择所有行,指定列。前面的冒号‘:’不能省略 df1.loc[0:3,['保单号','赔款']] # 选择0-3行,指定列 df1.loc[0:3,:] # 选择0-3行,所有列 df1.loc[0:3] # 选择0-3行,所有列,后面的冒号可省略不写,与df1.loc[0:3,:]效果一样 ############## 按条件选取 ############## df1.loc[df1.保单号 == 'AA0011'] df1.loc[df1.保单号 != 'AA0011',['保单号','伤情类型']] # 列可以写里面 df1.loc[df1.保单号 == 'AA0011'][['保单号','伤情类型']] # 也可以写外面 df1.loc[df1.保单号 == 'AA0011'].保单号 df1.loc[(df1.保单号 == 'AA0011') & (df1.伤情类型 == '住院'),['保单号','伤情类型']] # isin()函数 # (同SQL:where 保单号 in ('AA0011','BB0022')) df1[df1.保单号.isin(['AA0011','BB0022'])] # isna() # (同SQL:where 伤情类型 is null) df1[df1.伤情类型.isna()] # 波浪号~表示按条件取反 # (同SQL:not) df1[(~df1.伤情类型.isna()) & (~df1.保单号.isin(['AA0011']))] # startswith()、endswith()、contains() # (同SQL:where like '%xxx' 、 like 'xxx%' 、like '%xxx%') # 注意,使用前要先去除空值,否则报错 df1[df1.伤情类型.fillna('').str.startswith('住')] df1[df1.伤情类型.fillna('').str.endswith('院')] df1[df1.伤情类型.fillna('').str.contains('门')]
5.赋值
# 直接赋值 df1['赔款'] = df1['赔款'] + 100 df1['伤情类型'] = ['门诊' if each == '' else each for each in df1['伤情类型']] # apply函数赋值 # 其中:lambda为匿名函数 df1['伤情类型'] = df1['伤情类型'].apply(lambda x : '门诊' if x == '' else x) # Series.apply(),df1['伤情类型']为Series对象 df1['伤情类型'] = df1.apply(lambda x : '门诊' if x['伤情类型'] == '' else x['伤情类型'] , axis=1) # DataFrame.apply(),df1为DataFrame对象 # 自定义函数 def get_new_paid(x): if x['伤情类型'] == '住院': return x['赔款'] * 0.8 else: return x['赔款'] df1['赔款'] = df1.apply(get_new_paid, axis=1) # 调用函数
6.去重
# 判断重复 # duplicated() # keep :‘first’,‘last’,False 默认first # 'first':将第一次出现重复值标记为False,后面的重复项都是True # 'last':将最后一次出现重复值标记为False,前面的重复项都是True # False:将所有重复项标记为True df1.duplicated() # 判断整行是否重复 df1.duplicated(['保单号','伤情类型'],keep = 'last') # 判断指定字段是否重复 # 去重 # drop_duplicates() df1.drop_duplicates() # 删除整行重复值,保留第一个值,返回副本,默认keep='first' df1.drop_duplicates(keep='last') # 删除整行重复值,保留最后一个值,返回副本 df1.drop_duplicates(keep=False) # 删除整行重复值,删除所有重复值,返回副本 df1[['itemid','policyno']].drop_duplicates() # 先选取列,再去重 df1.drop_duplicates(inplace=True) # 就地修改,不返回副本 # 按照指定列删除重复数据,返回副本 # 按index取第一条记录 # (同sql:select *,row_number over(partition by 保单号,伤情类型 order by index) as rn from df1 where rn = 1) df1.drop_duplicates(['保单号','伤情类型']) # 按index取最后一条记录 # (同sql:select *,row_number over(partition by 保单号,伤情类型 order by index desc) as rn from df1 where rn = 1) df1.drop_duplicates(['保单号','伤情类型'],keep='last')
7.删除行、列
drop方法的用法:drop(labels, axis=0, level=None, inplace=False, errors='raise')
常用参数如下:

df1 = pd.DataFrame([['Snow','M',22],['Tyrion','M',32],['Sansa','F',18],['Arya','F',14]], columns=['name','gender','age']) print(df1) print('---------删除行或列:DataFrame.drop()--------') # drop默认对原表不生效,如果要对原表生效,需要加参数:inplace=True print("----删除单行----") df2=df1.drop(labels=0) # axis默认等于0,即按行删除,这里表示按行删除第0行 print(df2) print("------删除多行------") # 通过labels来控制删除行或列的个数,如果是删多行/多列,需写成labels=[1,3],不能写成labels=[1:2],用:号会报错 # 删除指定的某几行(非连续的) df21=df1.drop(labels=[1,3],axis=0) # axis=0 表示按行删除,删除第1行和第3行 print(df21) # 要删除连续的多行可以用range(),删除连续的多列不能用此方法 df22=df1.drop(labels=range(1,4),axis=0) # axis=0 表示按行删除,删除索引值是第1行至第3行的正行数据 print(df22) print("----删除单列----") df3=df1.drop(labels='gender',axis=1) # axis=1 表示按列删除,删除gender列 print(df3) print("----删除多列----") # 删除指定的某几列 df4=df1.drop(labels=['gender',"age"],axis=1) # axis=1 表示按列删除,删除gender、age列 print(df4)
8.排序
df1.sort_values('保单号') # 按照列'保单号'排序数据,默认升序排列 df1.sort_values('伤情类型', ascending=False) # 按照列'伤情类型'降序排列数据 df1.sort_values(['保单号','伤情类型'], ascending=[True,False]) # 先按列'保单号'升序排列,后按'伤情类型'降序排列数据 # 分组排序,生成序号 # (同SQL: row_number() over(partition by 保单号 order by 赔款 desc) as rn ) df1['rn'] = df1.groupby(df1['保单号'])['赔款'].rank(method='first',ascending=False) #默认情况:ascending = True ,表示升序 ,False表示降序 # rank函数中method参数用法如下: ## average :组的平均等级; (默认method='average') ## min :组中最低的排名; ## max :组中最高等级; ## first : 按排列顺序排列,依次排列; ## dense :类似于 ‘min’,但组之间的排名始终提高1 ## 举例: ## 赔款 average min max first dense ## 100 1.5 1 2 1 1 ## 100 1.5 1 2 2 1 ## 200 3.5 3 4 3 2 ## 200 3.5 3 4 4 2 ## 300 5.5 5 2 5 3 pd.Series([100,100,200,200,300]).rank(method='average') pd.Series([100,100,200,200,300]).rank(method='min') pd.Series([100,100,200,200,300]).rank(method='max') pd.Series([100,100,200,200,300]).rank(method='first') pd.Series([100,100,200,200,300]).rank(method='dense')
9.聚合
9.1聚合计算
df1.赔款.describe() #字段概要描述 # groupby(同SQL:group by) df1.groupby('伤情类型').agg('sum') df1.groupby('伤情类型').agg(['sum','min','max','mean','median','std','var','count']) # 'sum' : 求和 # 'min' :最小值 # 'max' :最大值 # 'mean' :平均值 # 'median' :中位数 # 'std' :标准差 # 'var' :方差 # 'count' :计数 df1.groupby('伤情类型').agg({'赔款':['sum','max'],'保单号': 'max'}) df2 = df1.groupby('伤情类型')[['保单号','赔款']].agg(['sum','max']) # 结果的字段名为多级表头:('保单号','sum'),('保单号','max'),('赔款','sum'),('赔款','max') df2.columns = ["_".join(x) for x in df2.columns.ravel()] # 将多级表头合并为一级表头,用下划线链接:保单号_sum,保单号_max,赔款_sum,赔款_max # 字段重命名 df2.rename(columns = {'赔款_sum':'医疗费_sum','赔款_max':'医疗费_max'},inplace=True) # 重置索引 df2.reset_index(drop=False,inplace=True)
9.2多行字符串合并
解决问题:多行合并一行,逗号分隔

import pandas as pd import numpy as np import os os.chdir(r'C:/Users/young/Desktop') #读入数据 df=pd.read_excel('多行合并.xlsx') #定义拼接函数,并对字段进行去重 def concat_func(x): return pd.Series({ '爱好':','.join(x['爱好'].unique()), '性别':','.join(x['性别'].unique()) } ) #分组聚合+拼接 result=df.groupby(df['姓名']).apply(concat_func).reset_index() #结果展示 result
10.透视表pivot_table
df2 = pd.pivot_table(df1,index='保单号',columns='伤情类型',values='赔款',aggfunc=['sum','max']).fillna(0) # sum sum sum max max max # 伤情类型 住院 死亡 门诊 住院 死亡 门诊 # 保单号 # AA0011 1000.0 0.0 2100.0 600.0 0.0 2000.0 # BB0022 72295.0 0.0 2006.0 59211.0 0.0 2006.0 # BB0099 0.0 500000.0 0.0 0.0 500000.0 0.0 df2.columns = ["_".join(x) for x in df2.columns.ravel()] # 将多级表头合并为一级表头,用下划线链接 df2.reset_index(inplace=True) # 重置索引,将保单号变成普通字段 # index 保单号 sum_住院 sum_死亡 sum_门诊 max_住院 max_死亡 max_门诊 # 0 AA0011 1000.0 0.0 2100.0 600.0 0.0 2000.0 # 1 BB0022 72295.0 0.0 2006.0 59211.0 0.0 2006.0 # 2 BB0099 0.0 500000.0 0.0 0.0 500000.0 0.0
11.逆透视表melt
其实就是pivot_table的逆向操作
df3 = pd.melt(df2,id_vars='保单号',var_name='伤情类型',value_name='赔款') # 保单号 伤情类型 赔款 # 0 AA0011 sum_住院 1000.0 # 1 BB0022 sum_住院 72295.0 # 2 BB0099 sum_住院 0.0 # 3 AA0011 sum_死亡 0.0 # 4 BB0022 sum_死亡 0.0 # 5 BB0099 sum_死亡 500000.0 # 6 AA0011 sum_门诊 2100.0 # 7 BB0022 sum_门诊 2006.0 # 8 BB0099 sum_门诊 0.0 # 9 AA0011 max_住院 600.0 # 10 BB0022 max_住院 59211.0 # 11 BB0099 max_住院 0.0 # 12 AA0011 max_死亡 0.0 # 13 BB0022 max_死亡 0.0 # 14 BB0099 max_死亡 500000.0 # 15 AA0011 max_门诊 2000.0 # 16 BB0022 max_门诊 2006.0 # 17 BB0099 max_门诊 0.0
12.表关联
#### merge函数 ####
# 常用参数:
# how:连接方式,有inner、left、right、outer,默认为inner
# on:用于连接的列名,必须是左、右两个表中的同名字段。 默认是以两个表的所有同名字段。
# left_on:左表用于连接的字段名, 在两表关联字段不同名时使用
# right_on:右表用于连接的字段名, 在两表关联字段不同名时使用
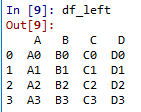
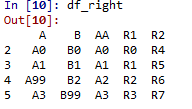
#左表 df_left = pd.DataFrame({'A':['A0','A1','A2','A3'], 'B':['B0','B1','B2','B3'], 'C':['C0','C1','C2','C3'], 'D':['D0','D1','D2','D3']}, index=[0,1,2,3]) #右表 df_right = pd.DataFrame({'A':['A0','A1','A99','A3'], 'B':['B0','B1','B2','B99'], 'AA':['A0','A1','A2','A3'], 'R1':['R0','R1','R2','R3'], 'R2':['R4','R5','R6','R7']}, index=[2,3,4,5])
pd.merge(df_left, df_right) # 没有任何参数的情况下, how默认为inner(内联),关联字段为两个表所有同名字段('A','B'两列) # 等价于 pd.merge(df_left, df_right, how='inner',on=['A','B']) # 类似sql # select * # from df_left # join df_right # on df_left.A = df_right.A # and df_left.B = df_right.B

pd.merge(df_left,df_right,how = 'left',left_on='A',right_on='AA') # 两个表关联字段不同名,可以分别指定关联字段 # 类似sql # select * # from df_left # join df_right # on df_left.A = df_right.AA

13.表拼接
#### concat函数 ####
# 常用参数:
# axis:0表示行拼接,1表示列拼接,默认为0
# join:指明连接方式 , {‘inner’(交集), ‘outer(并集)’},默认为outer
# ignore_index: True:重建索引,False:不重建索引, 默认False
# 行拼接类似SQL中的union all pd.concat([df_left,df_right]) # 默认axis=0行拼接,join='outer'并集, 没有的列补nan

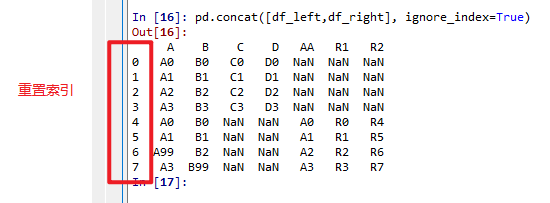
pd.concat([df_left,df_right], ignore_index=True) # 重建索引
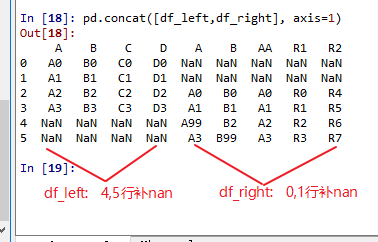
#列拼接有点类似表关联,只不过关联字段为index pd.concat([df_left,df_right], axis=1) # 列拼接,按索引拼接
# 交集 pd.concat([df_left,df_right], join='inner') # 行拼接,取交集, 保留列名相同的列 ('A','B') pd.concat([df_left,df_right], axis=1, join='inner') # 列拼接,取交集,保留索引相同的行 (2,3)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号