102302141_易敏亮第一次数据采集作业
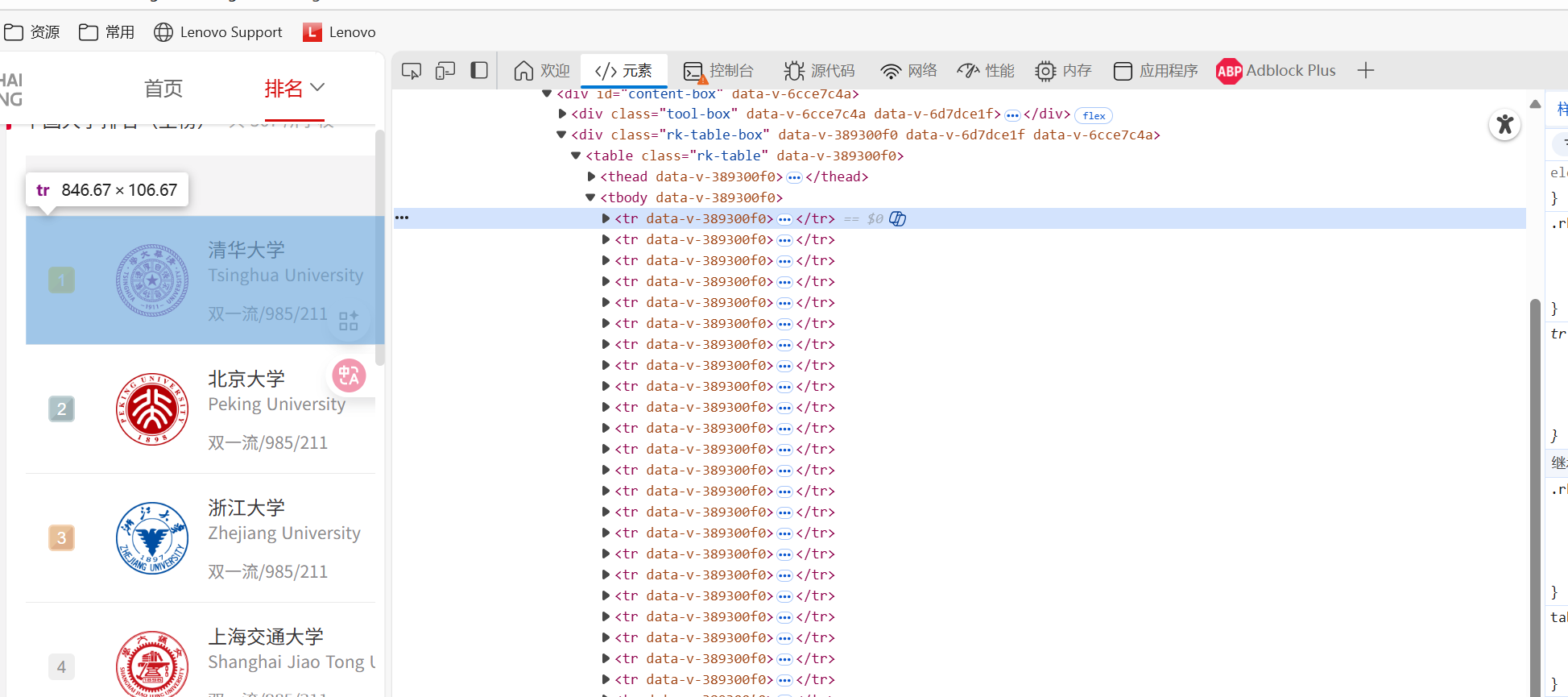
问题一、定向爬取软科2020年中国大学排名(本科)数据('http://www.shanghairanking.cn/rankings/bcur/2020'),将爬取到的排名信息在屏幕上以表格形式打印出来
简介:request请求html,用bs4解析,根据'rk-table'属性下单table标签,找到记录数据的td和span标签
心得:找到内容所属上级标签,再用for能更快找到
`import requests
import re
from bs4 import BeautifulSoup
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36"
}
list = [] #排名 学校名称 省市 学校类型 总分
response = requests.get(url, headers=headers)
response.encoding = 'utf-8' # 防止乱码
html = response.text
soup = BeautifulSoup(html, 'lxml')
tag1 = soup.find('table', class_='rk-table').find('tbody')
list0=[] #排名
list1=[] #学校名称
list2=[] #省市
list3=[] #学校类型
list4=[] #总分
for tag in tag1.find_all('tr'):
id = tag.find('td').find('div').get_text().strip()
list0.append(id)
name = tag.find('span', class_='name-cn').get_text().strip()
list1.append(name)
ss = tag.find_all('td')[2].get_text().strip()
list2.append(ss)
lx = tag.find_all('td')[3].get_text().strip()
list3.append(lx)
zf = tag.find_all('td')[4].get_text().strip()
list4.append(zf)
list.append(list0)
list.append(list1)
list.append(list2)
list.append(list3)
list.append(list4)
for i in range(len(list0)):
print(f"{list0[i]}\t{list1[i]}\t{list2[i]}\t{list3[i]}\t{list4[i]}")
`
问题二、在指定的商城中,以“书包”作为关键词搜索商品,将结果在屏幕上以表格形式打印出来
简介:选择了小米商城作为对象,用re正则匹配所需数据,翻页较为简单修改url中page参数即可。 一个选择原因:商城书包商品很少,界面简洁。
心得: 小米商城搜索数据时,是异步加载,需要在网络工具种找到正确的url(因为不熟悉工具,找了很久,应该根据数据查找目标的响应即url)。所得是jsonp文件,bs4就无法解析了
`import requests
import re
from bs4 import BeautifulSoup
keyword = "书包"
keyword= requests.utils.quote(keyword)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0",
"Referer": "https://www.mi.com/shop/",
"Accept-Encoding": "gzip, deflate, br",
}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8' # 防止乱码
html = response.text
pattern = r'"name":"(["]+)","price":"(["]+)"'
matches = re.findall(pattern, html)
for match in matches:
name, price = match
print(f"商品名称: {name}, 价格: {price}")
print("--------------------------------")
with open("1/afterclass/shubao_xm.txt", 'w', encoding='utf-8') as f:
f.write("序号\t价格\t商品名\n")
for i, product in enumerate(matches, 1):
f.write(f"{i}\t{product[1]}\t{product[0]}\n")
print(f"\n总计: {len(matches)} 个商品\n")
print(f"数据已成功写入到 shubao_xm.txt 文件中")
`
数据:

问题三、https://news.fzu.edu.cn/yxfd.htm静态网页获取数据
简介:本网页是静态加载数据,都在html文件中,很善良。 一个很有意思: 图形界面中page和url中page参数相反 ---“反爬”
心得: 需要下载的图片是一个个url,用request.get下载即可
`import requests
from bs4 import BeautifulSoup
import os
imag_path = os.path.join(os.path.dirname(file), "image")
url = "https://news.fzu.edu.cn/yxfd.htm"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36"
}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8' # 防止乱码
html = response.text
soup = BeautifulSoup(html, 'lxml')
tags = soup.find_all('ul', attrs={"class": "clearfix"})
for tag in tags:
links = tag.find_all('li')
for link in links:
a_tag = link.find('a')
if a_tag and 'href' in a_tag.attrs:
title = a_tag.get_text(strip=True)
href = a_tag['href']
# full_url = href if href.startswith('http') else f"https://news.fzu.edu.cn/{href}"
#
# print(f"标题: {title}")
# print(f"链接: {full_url}")
# print()
tag_img = a_tag.find('img')
if tag_img and 'src' in tag_img.attrs:
img_url = tag_img['src']
img_full_url = img_url if img_url.startswith('http') else f"https://news.fzu.edu.cn{img_url}"
print(f"图片链接: {img_full_url}")
if os.path.exists(imag_path):
with open(os.path.join(imag_path, img_full_url.split('/')[-1]), 'wb') as f:
img_data = requests.get(img_full_url, headers=headers).content
f.write(img_data)
else:
os.makedirs(imag_path)
with open(os.path.join(imag_path, img_full_url.split('/')[-1]), 'wb') as f:
img_data = requests.get(img_full_url, headers=headers).content
f.write(img_data)
`

 浙公网安备 33010602011771号
浙公网安备 33010602011771号