pytorch中TensorDataset
对于这个TensorDataset,里面的元素的size要相同。例如:
x=torch.tensor([0,1,2,3])
y=torch.tensor([1,0,3,2])
z=torch.tensor([[0,0,0,1,0],
[0,0,0,0,1],
[1,0,0,0,0],
[0,0,0,1,0]])
print(x.shape,y.shape,z.shape)
# torch.Size([4]) torch.Size([4]) torch.Size([4, 5])
然后我们调用data_set = TensorDataset(x,y,z)
然后我们输出一下:
for x,y,z in data_set:
print(x)
print(y)
print(z)
tensor(0)
tensor(1)
tensor([0, 0, 0, 1, 0])
tensor(1)
tensor(0)
tensor([0, 0, 0, 0, 1])
tensor(2)
tensor(3)
tensor([1, 0, 0, 0, 0])
tensor(3)
tensor(2)
tensor([0, 0, 0, 1, 0])
然后我们看看输出:
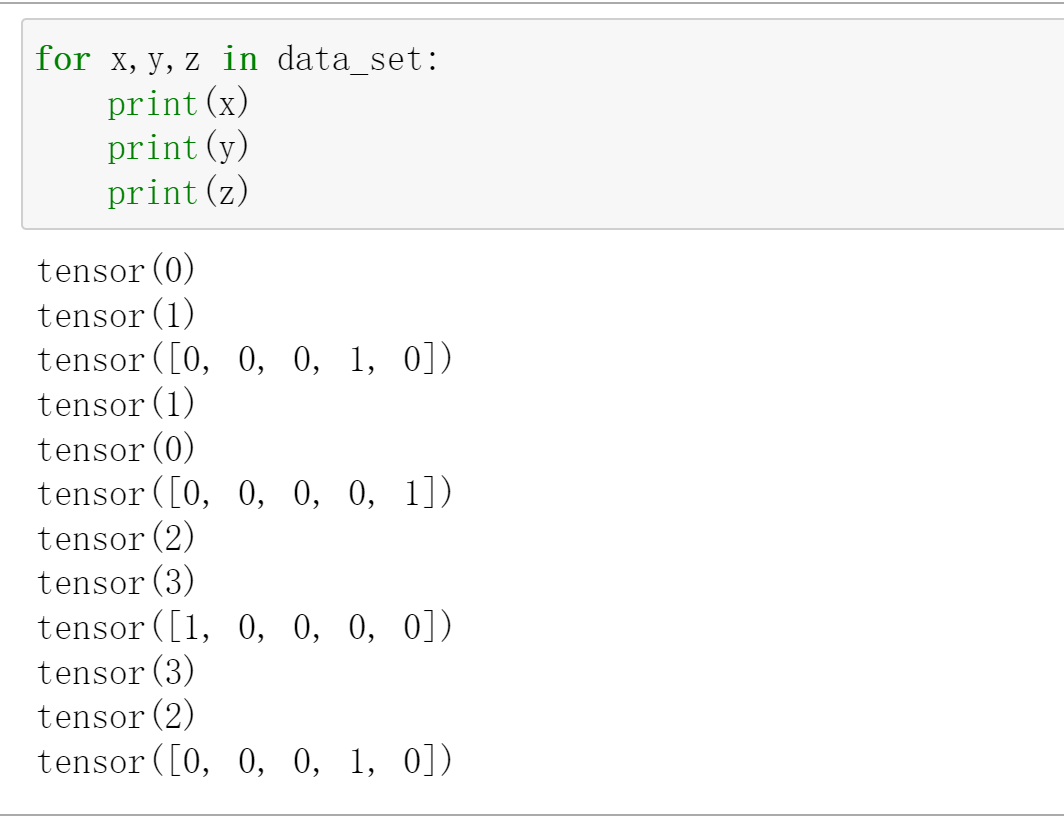
很明显,这个二维数组,这个y是多少,然后这个对于的z就是z[y]。比如说第三个x=2,y=3,然后对应的z就是第三行。
再举个例子:
比如说这里有两个文件:一个字段是学生字段,习题字段,得分。然后两个文件是习题字段,每个习题对用知识点。
然后我们将每个习题进行onehots,然后就变成了一个二维数组。
再进行TensorDataset,我们会发现,我们每个tensordataset中包含学生字段,习题字段,对应该习题的知识点
我们直接上传上去就行,我们来看一下:
def transform(user,item,item2knowledge,score,batch_size):
knowledge_emb=torch.zeros((len(item),knowledge_n))
for idx in range(len(item)):
knowledge_emb[idx][np.array(item2knowledge[item[idx]])-1]=1.0
data_set = TensorDataset(
torch.tensor(user, dtype=torch.int64) - 1, # (1, user_n) to (0, user_n-1)
torch.tensor(item, dtype=torch.int64) - 1, # (1, item_n) to (0, item_n-1)
knowledge_emb,
torch.tensor(score, dtype=torch.float32)
)
return DataLoader(data_set, batch_size=batch_size, shuffle=True)
train_set, valid_set, test_set = [
transform(data["user_id"], data["item_id"], item2knowledge, data["score"], batch_size)
for data in [train_data, valid_data, test_data]
]
train_set, valid_set, test_set
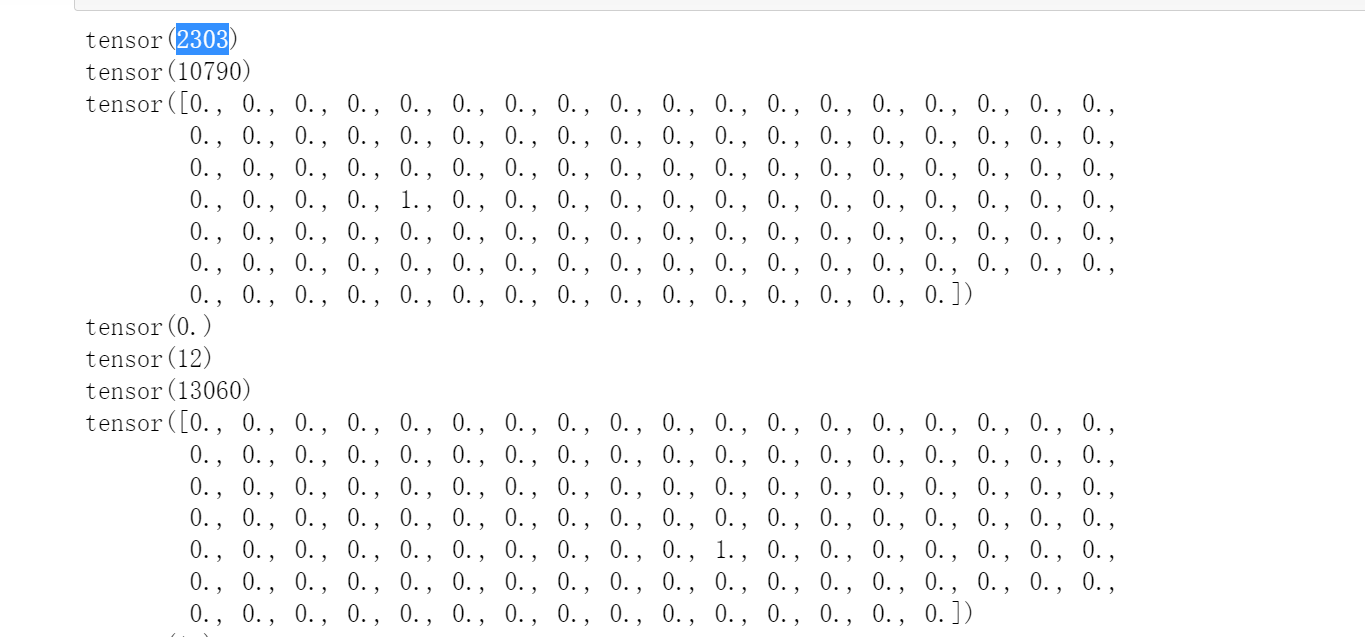
for x,y,z,p in train_set:
for i in range(32):
print(x[i])
print(y[i])
print(z[i])
#print(torch.nonzero(z))
print(p[i])
然后我们看看效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号