pytorch-入门(信用卡欺诈数据二分类模型)
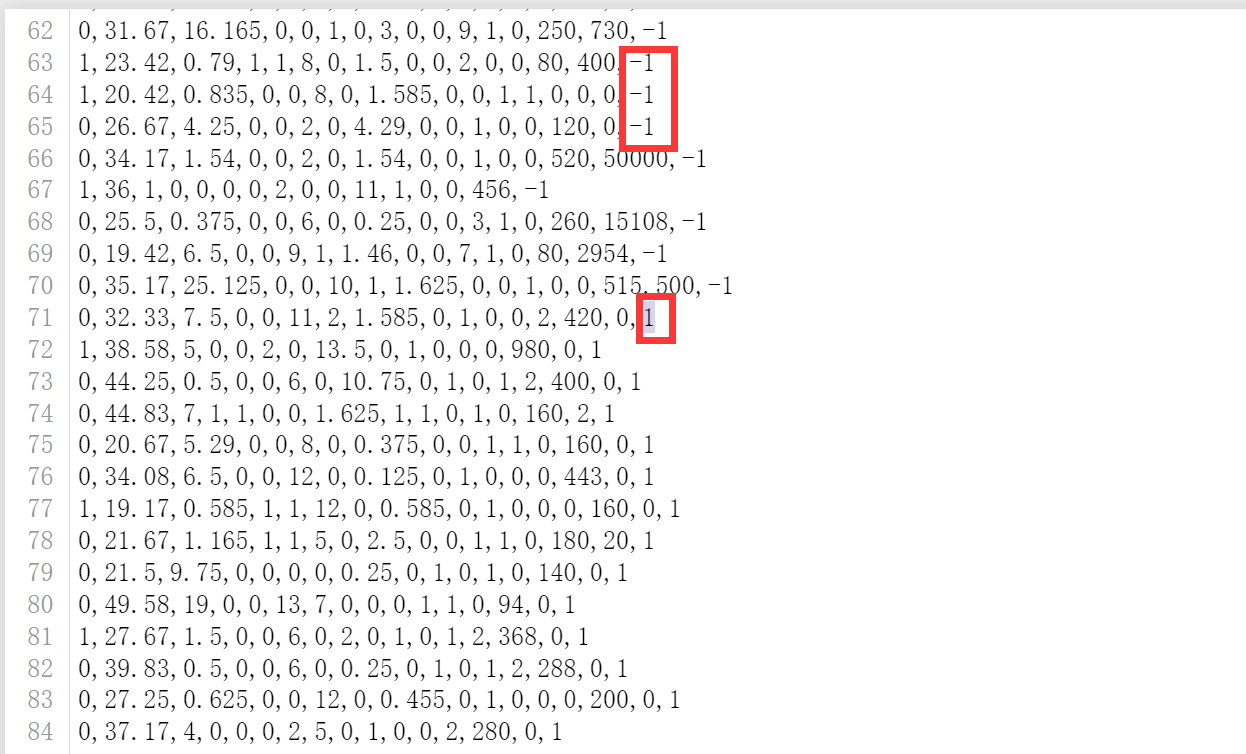
首先我们先看看这个数据集长什么样子:
首先这个数据集是没有表头的,最后一行是需要预测的结果-1和1代表欺诈和不欺诈。
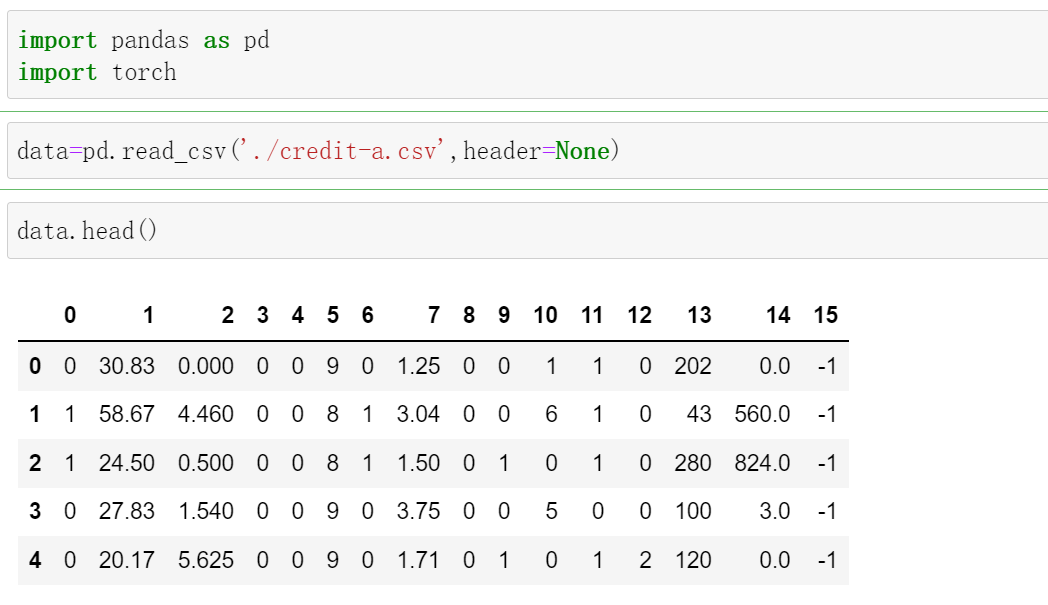
读取文件
import pandas as pd
import torch
data=pd.read_csv('./credit-a.csv',header=None)
data.head()
数据处理
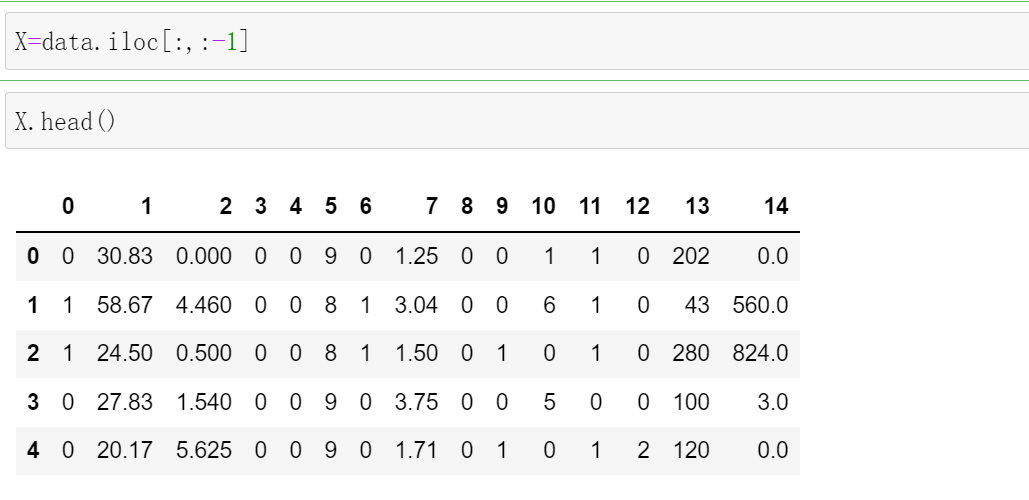
我们先取出X.
X=data.iloc[:,:-1]
X.head()
然后再取出Y:
注意这里由于标签只含有-1和1,所以我们要将-1变为0,我们使用replace函数。
.repalce(old,new,[,count])
old : 要被替换的旧字符串。
new : 用于替换的新字符串。
count : 可选参数,指定 count 后,只有 str 中前 count 个旧字符串old被替换。
Y = data.iloc[:, -1].replace(-1, 0)
X,Y转化成Tensor
X=torch.from_numpy(X.values).type(torch.FloatTensor)
Y = torch.from_numpy(Y.values.reshape(-1, 1)).type(torch.FloatTensor)
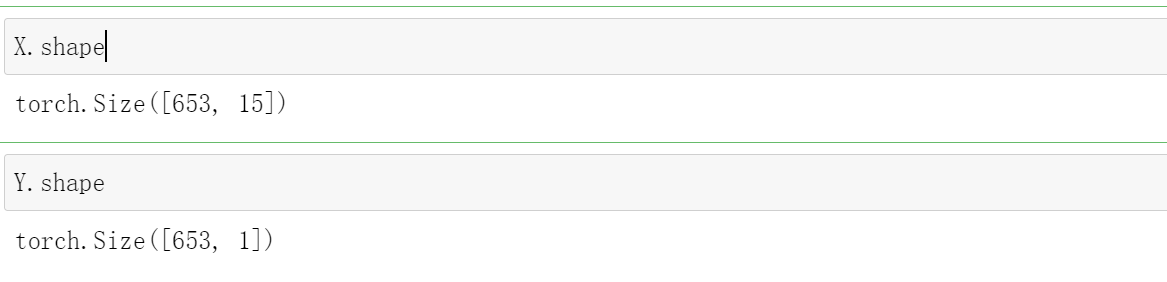
X.shape
Y.shape
但是要注意的是这个Y需要.reshape(-1, 1)操作,因为它只有一行,转化后的Y.shape=[653,1],如果没有转化的话,它的Y.shape=[653]。
所以这里是需要注意的
模型
from torch import nn
model = nn.Sequential(
nn.Linear(15, 1),
nn.Sigmoid()
)
model
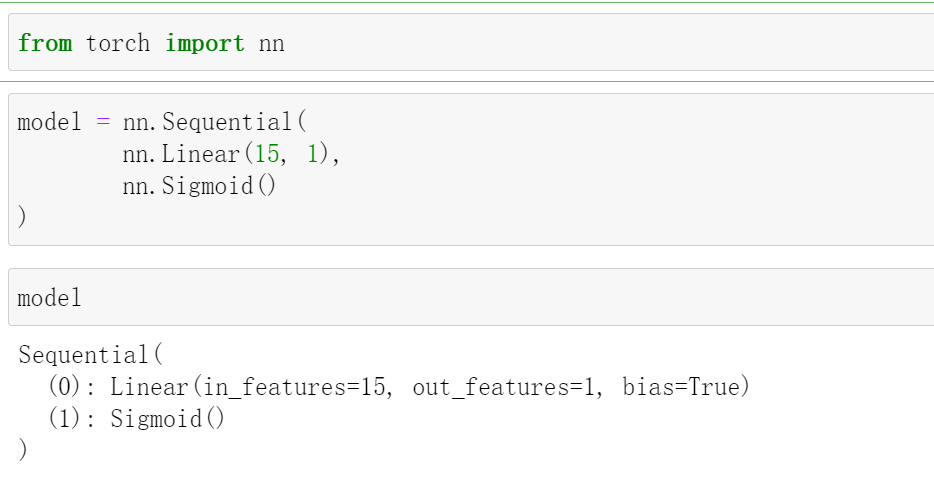
这里只有一层线形层
损失函数和优化器
pytorch中的优化器位于torch.optim包内,作用是根据反向传播算法更新神经网络中的参数,以达到降低损失值loss的目的。
loss_fn = nn.BCELoss()
opt=torch.optim.SGD(model.parameters(),lr=0.00001)
训练
batches = 16
no_of_batches = 653//16
我们这里手动实现的这个batch
for epoch in range(1000):
for batch in range(no_of_batches):
start = batch*batches
end = start + batches
x = X[start: end]
y = Y[start: end]
y_pred = model(x)
loss = loss_fn(y_pred, y)
opt.zero_grad()
loss.backward()
opt.step()
核心分为三步
- opt.zero_grad()函数:梯度归零。Pytorch不会自动进行梯度归零,如果不手动清零,则下一次迭代时计算得到的梯度值会与之前留下的梯度值进行叠加。
- l.backward()函数:计算梯度
- opt.step()函数:执行梯度下降,对学习的参数进行一次更新。
model.state_dict()

计算准确率
((model(X).data.numpy() > 0.5).astype('int') == Y.numpy()).mean()
0.7243491577335375

 浙公网安备 33010602011771号
浙公网安备 33010602011771号