计算机视觉-语义分割和数据集
语义分割(semantic segmentation )
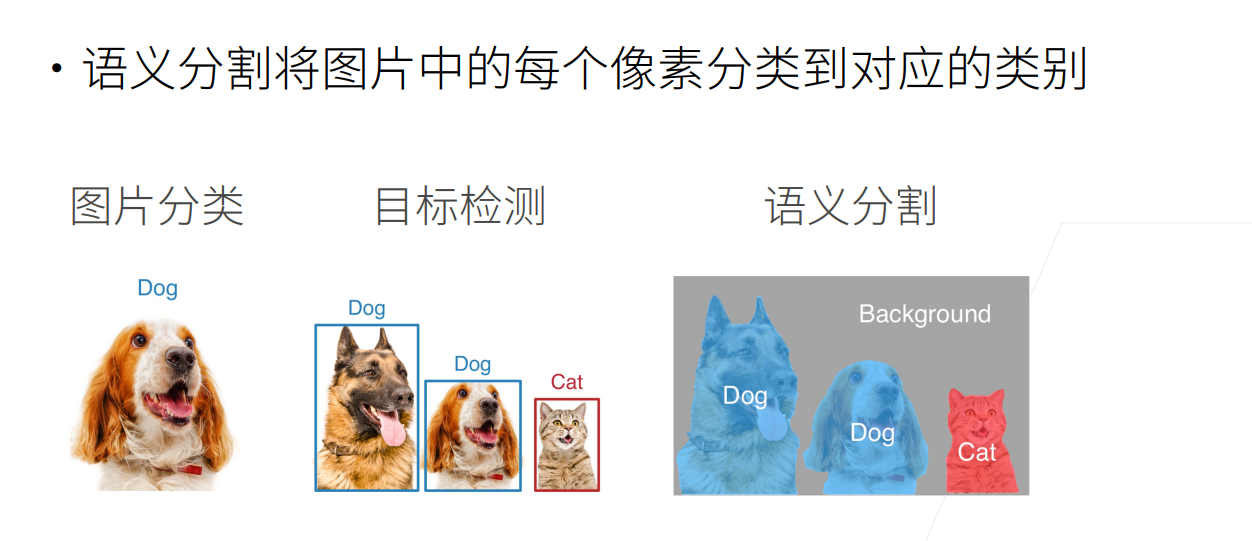
在图片分类中,其主要任务是给定一张图片,识别图片中主体物体
- 目标检测,也叫物体检测,其主要任务是找出图片中多个感兴趣的物体,并且找到每个物体的具体位置(使用方形边界框来标注和预测图像中的目标),问题是这些框很多时候比较粗糙,只能标注出大致的位置,但是无法标注出物体各部分的具体位置以及物体与背景之间的分割线(物体的具体轮廓)
- 语义分割可以识别并理解图像中每一个像素的内容(将图片中的每个像素分类到对应的类别),其语义区域的标注和预测是像素级的。
图像分割(image segmentation)与实例分割(instance segmentation)
-
图像分割
分割在计算机视觉中应用的时间比较长,最早是进行图片分割,给定一张图片,通过聚类或者其他方法,将语义上比较像的像素放在一起,可能不会明确某一块像素到底是什么,而只是像素在颜色或者像素上比较相似,然后进行聚类
图像分割将图像划分为若干组成区域,这类问题的方法通常利用图像中像素之间的相关性。它在训练时不需要有关图像像素的标签信息,在预测时也无法保证分割出的区域具有所希望得到的语义 -
实例分割
实例分割也叫同时检测并分割(simultaneous detection and segmentation ),它研究如何识别图像中各个目标实例的像素级区域
实例分割与语义分割的不同之处在于:实例分割不仅需要区分语义,还要区分不同的目标实例 -
语义分割
语义分割和一般分割的不同之处在于它就明确每一个像素的标号(label)到底是什么,它属于是有监督的学习,而一般的分割可以通过聚类来实现无监督的学习
相比于图片分类和目标检测,语义分割更加精细,因为需要对每一个像素的类别进行判断,对每一个像素生成一个标号
应用
-
背景虚化

-
路面分割

语义分割VS实例分割
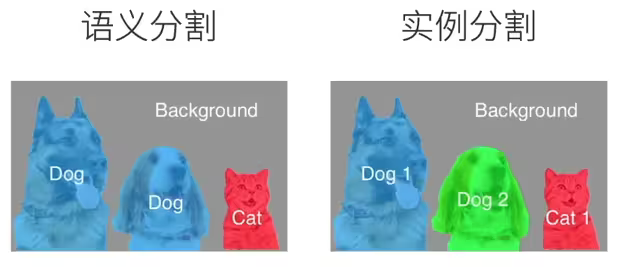
实例分割与语义分割最大的不同在于:语义分割只关心像素所属的类别,实例分割会将类别中具体的实例进行区分(实例分割可以认为是真正意义上的目标检测的进化版本,实例分割不仅能够将感兴趣的物体检测出来,还能将物体的边缘描绘出来)
图像分割和实例分割
计算机视觉领域还有2个与语义分割相似的重要问题,即图像分割(image segmentation)和实例分割(instance segmentation)。 我们在这里将它们同语义分割简单区分一下。
图像分割将图像划分为若干组成区域,这类问题的方法通常利用图像中像素之间的相关性。它在训练时不需要有关图像像素的标签信息,在预测时也无法保证分割出的区域具有我们希望得到的语义。以下图中的图像作为输入,图像分割可能会将狗分为两个区域:一个覆盖以黑色为主的嘴和眼睛,另一个覆盖以黄色为主的其余部分身体。
实例分割也叫同时检测并分割(simultaneous detection and segmentation),它研究如何识别图像中各个目标实例的像素级区域。与语义分割不同,实例分割不仅需要区分语义,还要区分不同的目标实例。例如,如果图像中有两条狗,则实例分割需要区分像素属于的两条狗中的哪一条。

Pascal VOC2012 语义分割数据集
最重要的语义分割数据集之一是Pascal VOC2012。 下面我们深入了解一下这个数据集。
%matplotlib inline
import os
import torch
import torchvision
from d2l import torch as d2l
数据集的tar文件大约为2GB,所以下载可能需要一段时间。 提取出的数据集位于../data/VOCdevkit/VOC2012。
#@save
d2l.DATA_HUB['voc2012'] = (d2l.DATA_URL + 'VOCtrainval_11-May-2012.tar',
'4e443f8a2eca6b1dac8a6c57641b67dd40621a49')
voc_dir = d2l.download_extract('voc2012', 'VOCdevkit/VOC2012')
Downloading ../data/VOCtrainval_11-May-2012.tar from http://d2l-data.s3-accelerate.amazonaws.com/VOCtrainval_11-May-2012.tar...
进入路径../data/VOCdevkit/VOC2012之后,我们可以看到数据集的不同组件。 ImageSets/Segmentation路径包含用于训练和测试样本的文本文件,而JPEGImages和SegmentationClass路径分别存储着每个示例的输入图像和标签。 此处的标签也采用图像格式,其尺寸和它所标注的输入图像的尺寸相同。 此外,标签中颜色相同的像素属于同一个语义类别。 下面将read_voc_images函数定义为将所有输入的图像和标签读入内存。
#@save
def read_voc_images(voc_dir, is_train=True):
"""读取所有VOC图像并标注"""
txt_fname = os.path.join(voc_dir, 'ImageSets', 'Segmentation',
'train.txt' if is_train else 'val.txt')
mode = torchvision.io.image.ImageReadMode.RGB
with open(txt_fname, 'r') as f:
images = f.read().split()
features, labels = [], []
for i, fname in enumerate(images):
features.append(torchvision.io.read_image(os.path.join(
voc_dir, 'JPEGImages', f'{fname}.jpg')))
labels.append(torchvision.io.read_image(os.path.join(
voc_dir, 'SegmentationClass' ,f'{fname}.png'), mode))
return features, labels
train_features, train_labels = read_voc_images(voc_dir, True)
下面我们绘制前5个输入图像及其标签。 在标签图像中,白色和黑色分别表示边框和背景,而其他颜色则对应不同的类别。
n = 5
imgs = train_features[0:n] + train_labels[0:n]
imgs = [img.permute(1,2,0) for img in imgs]
d2l.show_images(imgs, 2, n);

接下来,我们列举RGB颜色值和类名。
#@save
VOC_COLORMAP = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],
[0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],
[64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],
[64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],
[0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],
[0, 64, 128]]
#@save
VOC_CLASSES = ['background', 'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair', 'cow',
'diningtable', 'dog', 'horse', 'motorbike', 'person',
'potted plant', 'sheep', 'sofa', 'train', 'tv/monitor']
也就是说我们将这个背景颜色RGB为[0,0,0]=>'background',[128,0,0]=>'aeroplane'....[128, 192, 0]=>tv/monitor
通过上面定义的两个常量,我们可以方便地查找标签中每个像素的类索引。 我们定义了voc_colormap2label函数来构建从上述RGB颜色值到类别索引的映射,而voc_label_indices函数将RGB值映射到在Pascal VOC2012数据集中的类别索引。
#@save
def voc_colormap2label():
"""构建从RGB到VOC类别索引的映射"""
colormap2label = torch.zeros(256 ** 3, dtype=torch.long)
for i, colormap in enumerate(VOC_COLORMAP):
colormap2label[
(colormap[0] * 256 + colormap[1]) * 256 + colormap[2]] = i
return colormap2label
#@save
def voc_label_indices(colormap, colormap2label):
"""将VOC标签中的RGB值映射到它们的类别索引"""
colormap = colormap.permute(1, 2, 0).numpy().astype('int32')
idx = ((colormap[:, :, 0] * 256 + colormap[:, :, 1]) * 256
+ colormap[:, :, 2])# 哈希
return colormap2label[idx]
例如,在第一张样本图像中,飞机头部区域的类别索引为1,而背景索引为0。
y = voc_label_indices(train_labels[0], voc_colormap2label())
y[105:115, 130:140], VOC_CLASSES[1]
(tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1]]),
'aeroplane')
预处理数据
在之前的实验,我们通过再缩放图像使其符合模型的输入形状。 然而在语义分割中,这样做需要将预测的像素类别重新映射回原始尺寸的输入图像。 这样的映射可能不够精确,尤其在不同语义的分割区域。 为了避免这个问题,我们将图像裁剪为固定尺寸,而不是再缩放。 具体来说,我们使用图像增广中的随机裁剪,裁剪输入图像和标签的相同区域。
#@save
def voc_rand_crop(feature, label, height, width):
"""随机裁剪特征和标签图像"""
rect = torchvision.transforms.RandomCrop.get_params(
feature, (height, width))
feature = torchvision.transforms.functional.crop(feature, *rect)
label = torchvision.transforms.functional.crop(label, *rect)
return feature, label
imgs = []
for _ in range(n):
imgs += voc_rand_crop(train_features[0], train_labels[0], 200, 300)
imgs = [img.permute(1, 2, 0) for img in imgs]
d2l.show_images(imgs[::2] + imgs[1::2], 2, n);
因为是对应关系所以需要同时缩减

自定义语义分割数据集类
我们通过继承高级API提供的Dataset类,自定义了一个语义分割数据集类VOCSegDataset。 通过实现__getitem__函数,我们可以任意访问数据集中索引为idx的输入图像及其每个像素的类别索引。 由于数据集中有些图像的尺寸可能小于随机裁剪所指定的输出尺寸,这些样本可以通过自定义的filter函数移除掉。 此外,我们还定义了normalize_image函数,从而对输入图像的RGB三个通道的值分别做标准化。
#@save
class VOCSegDataset(torch.utils.data.Dataset):
"""一个用于加载VOC数据集的自定义数据集"""
def __init__(self, is_train, crop_size, voc_dir):
self.transform = torchvision.transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
self.crop_size = crop_size
features, labels = read_voc_images(voc_dir, is_train=is_train)
self.features = [self.normalize_image(feature)
for feature in self.filter(features)]
self.labels = self.filter(labels)
self.colormap2label = voc_colormap2label()
print('read ' + str(len(self.features)) + ' examples')
def normalize_image(self, img):
return self.transform(img.float() / 255)
def filter(self, imgs):
return [img for img in imgs if (
img.shape[1] >= self.crop_size[0] and
img.shape[2] >= self.crop_size[1])]
def __getitem__(self, idx):
feature, label = voc_rand_crop(self.features[idx], self.labels[idx],
*self.crop_size)
return (feature, voc_label_indices(label, self.colormap2label))
def __len__(self):
return len(self.features)
读取数据集
我们通过自定义的VOCSegDataset类来分别创建训练集和测试集的实例。 假设我们指定随机裁剪的输出图像的形状为, 下面我们可以查看训练集和测试集所保留的样本个数。
crop_size = (320, 480)
voc_train = VOCSegDataset(True, crop_size, voc_dir)
voc_test = VOCSegDataset(False, crop_size, voc_dir)
read 1114 examples
read 1078 examples
设批量大小为64,我们定义训练集的迭代器。 打印第一个小批量的形状会发现:与图像分类或目标检测不同,这里的标签是一个三维数组。
batch_size = 64
train_iter = torch.utils.data.DataLoader(voc_train, batch_size, shuffle=True,drop_last=True)
for X, Y in train_iter:
print(X.shape)
print(Y.shape)
break
torch.Size([64, 3, 320, 480])
torch.Size([64, 320, 480])
整合所有组件
最后,我们定义以下load_data_voc函数来下载并读取Pascal VOC2012语义分割数据集。 它返回训练集和测试集的数据迭代器。
#@save
def load_data_voc(batch_size, crop_size):
"""加载VOC语义分割数据集"""
voc_dir = d2l.download_extract('voc2012', os.path.join(
'VOCdevkit', 'VOC2012'))
num_workers = d2l.get_dataloader_workers()
train_iter = torch.utils.data.DataLoader(
VOCSegDataset(True, crop_size, voc_dir), batch_size,
shuffle=True, drop_last=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(
VOCSegDataset(False, crop_size, voc_dir), batch_size,
drop_last=True, num_workers=num_workers)
return train_iter, test_iter
小结
语义分割通过将图像划分为属于不同语义类别的区域,来识别并理解图像中像素级别的内容。
语义分割的一个重要的数据集叫做Pascal VOC2012。
由于语义分割的输入图像和标签在像素上一一对应,输入图像会被随机裁剪为固定尺寸而不是缩放

 浙公网安备 33010602011771号
浙公网安备 33010602011771号