优化算法-4.随机梯度下降
在深度学习中,目标函数通常是训练数据集中每个样本的损失函数的平均值。
我们在应用时通常使用的都是随机梯度下降而不用梯度下降,因为当我们有\(n\)个样本的时候,\(f(x)\)表示所有样本上损失的平均值,因为计算一个样本比较贵。梯度下降是在整个完整的样本上求导,比较贵,所以通常使用的都是随机梯度下降。
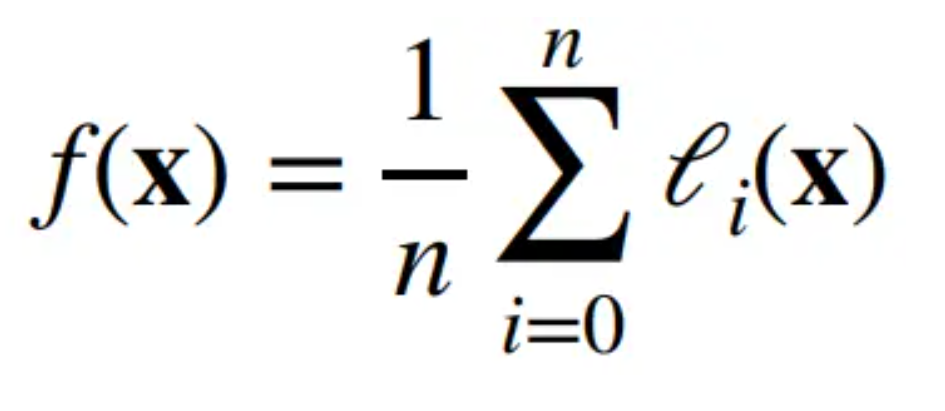
而随机梯度下降就是再时间\(t\)随机选择一个样本\(t_i\)上的梯度来近似\(f(x)\)的梯度。这么做是因为求导是线性可加的
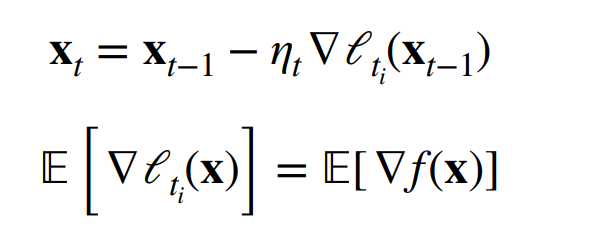
因为样本\(t_i\)是随机选择的,所以导数的期望就是所有样本的梯度的均值,而所有样本的梯度的均值和\(f(x)\)梯度的期望是差不多的,虽然有噪音,但是均值是近似相等的,也就是说大的方向是一致的。这样做的好处是每次只用算一个样本的梯度就可以了,而不用计算全部样本的梯度(可能会导致重复性的计算)
我们来对比一下梯度下降(上)和随机梯度下降(下)
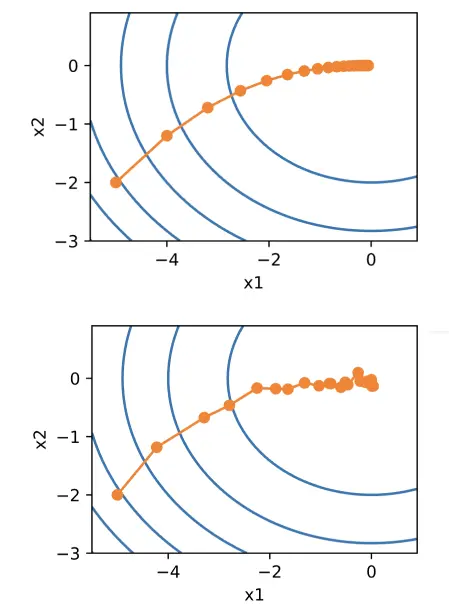
随机梯度下降整个过程不像梯度下降那么平滑,特别是在最后阶段比较曲折,但是整个大的方向和梯度下降是一致的(均值没有发生变化)。
因为每一次计算只需要计算一个样本的梯度,所以虽然可能会走一点弯路,但是整体来看还是比较划算的。
随机梯度更新
在深度学习中,目标函数通常是训练数据集中每个样本的损失函数的平均值。给定\(n\)个样本的训练数据集,我们假设\(f_i(\mathbf{x})\)是关于索引\(i\)的训练样本的损失函数,其中\(\mathbf{x}\)是参数向量。然后我们得到目标函数
\(\mathbf{x}\)的目标函数的梯度计算为
如果使用梯度下降法,则每个自变量迭代的计算代价为\(\mathcal{O}(n)\),它随线性增长。因此,当训练数据集较大时,每次迭代的梯度下降计算代价将较高。
随机梯度下降(SGD)可降低每次迭代时的计算代价。在随机梯度下降的每次迭代中,我们对数据样本随机均匀采样一个索引\(i\),其中\(i\in\{1,\ldots, n\}\),并计算梯度\(\nabla f_i(\mathbf{x})\)以更新\(x\):
其中\(\eta\)是学习率。我们可以看到,每次迭代的计算代价从梯度下降的\(\mathcal{O}(n)\)降至常数\(\mathcal{O}(1)\)。此外,我们要强调,随机梯度\(\nabla f_i(\mathbf{x})\)是对完整梯度\(\nabla f(\mathbf{x})\)的无偏估计,因为
这意味着,平均而言,随机梯度是对梯度的良好估计。
现在,我们将把它与梯度下降进行比较,方法是向梯度添加均值为0、方差为1的随机噪声,以模拟随机梯度下降。
%matplotlib inline
import math
import torch
from d2l import torch as d2l
def f(x1, x2): # 目标函数
return x1 ** 2 + 2 * x2 ** 2
def f_grad(x1, x2): # 目标函数的梯度
return 2 * x1, 4 * x2
def sgd(x1, x2, s1, s2, f_grad):
g1, g2 = f_grad(x1, x2)
# 模拟有噪声的梯度
g1 += torch.normal(0.0, 1, (1,)).item()
g2 += torch.normal(0.0, 1, (1,)).item()
eta_t = eta * lr()
return (x1 - eta_t * g1, x2 - eta_t * g2, 0, 0)
def constant_lr():
return 1
eta = 0.1
lr = constant_lr # 常数学习速度
d2l.show_trace_2d(f, d2l.train_2d(sgd, steps=50, f_grad=f_grad))
epoch 50, x1: 0.020569, x2: 0.227895
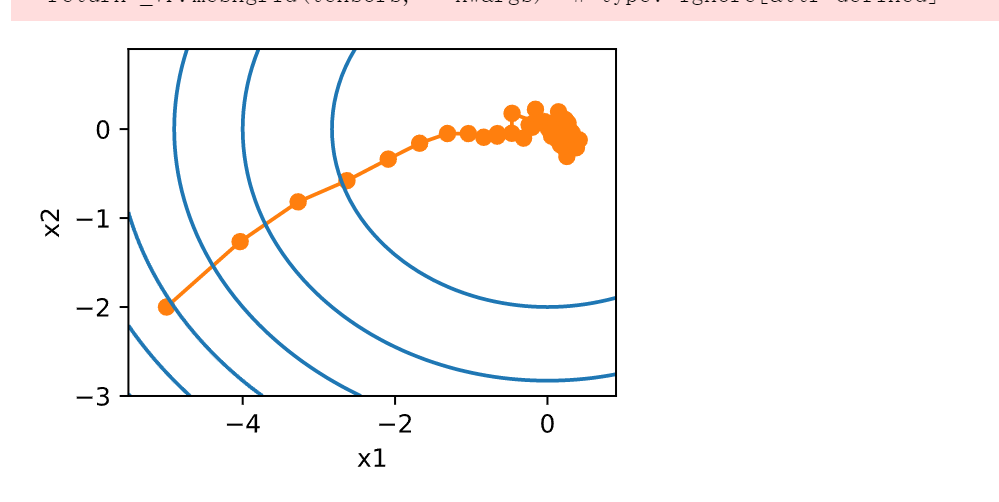
正如我们所看到的,随机梯度下降中变量的轨迹比我们在 11.3节中观察到的梯度下降中观察到的轨迹嘈杂得多。这是由于梯度的随机性质。也就是说,即使我们接近最小值,我们仍然受到通过\(\eta \nabla f_i(\mathbf{x})\)的瞬间梯度所注入的不确定性的影响。即使经过50次迭代,质量仍然不那么好。更糟糕的是,经过额外的步骤,它不会得到改善。这给我们留下了唯一的选择:改变学习率\(\eta\)。但是,如果我们选择的学习率太小,我们一开始就不会取得任何有意义的进展。另一方面,如果我们选择的学习率太大,我们将无法获得一个好的解决方案,如上所示。解决这些相互冲突的目标的唯一方法是在优化过程中动态降低学习率。
这也是在sgd步长函数中添加学习率函数lr的原因。在上面的示例中,学习率调度的任何功能都处于休眠状态,因为我们将相关的lr函数设置为常量。
动态学习率
用与时间相关的学习率\(\eta(t)\)取代增加了控制优化算法收敛的复杂性。特别是,我们需要弄清\(\eta\)的衰减速度。如果太快,我们将过早停止优化。如果减少的太慢,我们会在优化上浪费太多时间。以下是随着时间推移调整\(\eta\)时使用的一些基本策略(稍后我们将讨论更高级的策略):
在第一个分段常数(piecewise constant)场景中,我们会降低学习率,例如,每当优化进度停顿时。这是训练深度网络的常见策略。或者,我们可以通过指数衰减(exponential decay)来更积极地减低它。不幸的是,这往往会导致算法收敛之前过早停止。一个受欢迎的选择是\(\alpha = 0.5\)的多项式衰减(polynomial decay)。在凸优化的情况下,有许多证据表明这种速率表现良好。
让我们看看指数衰减在实践中是什么样子。
def exponential_lr():
# 在函数外部定义,而在内部更新的全局变量
global t
t += 1
return math.exp(-0.1 * t)
t = 1
lr = exponential_lr
d2l.show_trace_2d(f, d2l.train_2d(sgd, steps=1000, f_grad=f_grad))
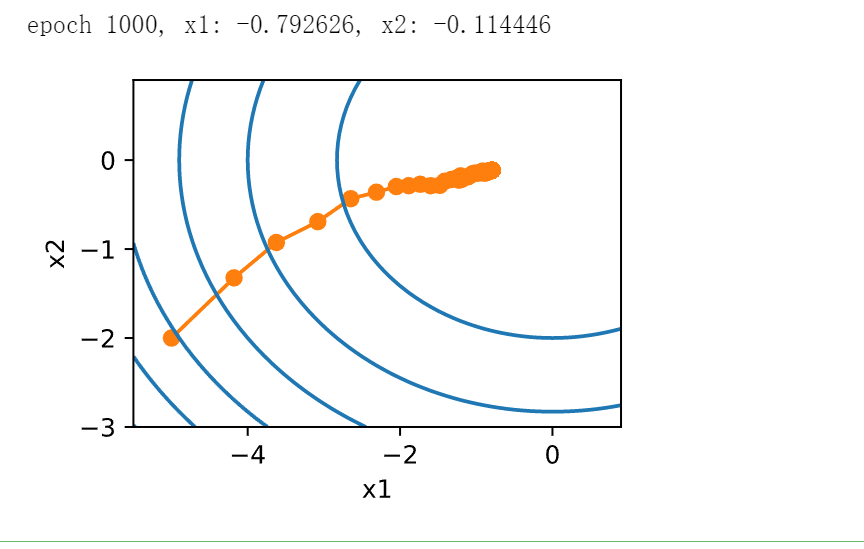
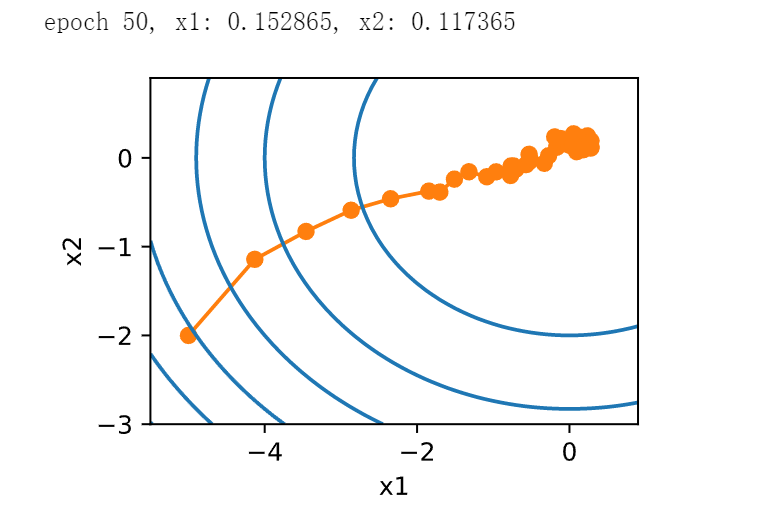
正如预期的那样,参数的方差大大减少。但是,这是以未能收敛到最优解\(\mathbf{x} = (0, 0)\)为代价的。即使经过1000个迭代步骤,我们仍然离最优解很远。事实上,该算法根本无法收敛。另一方面,如果我们使用多项式衰减,其中学习率随迭代次数的平方根倒数衰减,那么仅在50次迭代之后,收敛就会更好。
关于如何设置学习率,还有更多的选择。例如,我们可以从较小的学习率开始,然后使其迅速上涨,再让它降低,尽管这会更慢。我们甚至可以在较小和较大的学习率之间切换。现在,让我们专注于可以进行全面理论分析的学习率计划,即凸环境下的学习率。对一般的非凸问题,很难获得有意义的收敛保证,因为总的来说,最大限度地减少非线性非凸问题是NP困难的。
随机梯度和有限样本
到目前为止,在谈论随机梯度下降时,我们进行得有点快而松散。我们假设从分布\(p(x, y)\)中采样得到样本\(x_i\)(通常带有标签),并且用它来以某种方式更新模型参数。特别是,对于有限的样本数量,我们仅仅讨论了由某些允许我们在其上执行随机梯度下降的函数\(\delta_{x_i}\)和\(\delta_{y_i}\)组成的离散分布
\(p(x, y) = \frac{1}{n} \sum_{i=1}^n \delta_{x_i}(x) \delta_{y_i}(y)\)。
但是,这不是我们真正做的。在本节的简单示例中,我们只是将噪声添加到其他非随机梯度上,也就是说,我们假装有成对的\((x_i, y_i)\)。事实证明,这种做法在这里是合理的(有关详细讨论,请参阅练习)。更麻烦的是,在以前的所有讨论中,我们显然没有这样做。相反,我们遍历了所有实例恰好一次。要了解为什么这更可取,可以反向考虑一下,即我们有替换地从离散分布中采样\(n\)个观测值。随机选择一个元素\(i\)的概率是\(\frac{1}{n}\)。因
类似的推理表明,挑选一些样本(即训练示例)恰好一次的概率是
这导致与无替换采样相比,方差增加并且数据效率降低。因此,在实践中我们执行后者(这是本书中的默认选择)。最后一点注意,重复采用训练数据集的时候,会以不同的随机顺序遍历它。
小结
-
对于凸问题,我们可以证明,对于广泛的学习率选择,随机梯度下降将收敛到最优解。
-
对于深度学习而言,情况通常并非如此。但是,对凸问题的分析使我们能够深入了解如何进行优化,即逐步降低学习率,尽管不是太快。
-
如果学习率太小或太大,就会出现问题。实际上,通常只有经过多次实验后才能找到合适的学习率。
-
当训练数据集中有更多样本时,计算梯度下降的每次迭代的代价更高,因此在这些情况下,首选随机梯度下降。
-
随机梯度下降的最优性保证在非凸情况下一般不可用,因为需要检查的局部最小值的数量可能是指数级的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号