自然语言处理:预处理-全局向量的词嵌入(GloVe)
词向量的表示可以分成两个大类
- 基于统计方法例如共现矩阵、奇异值分解SVD;
- 基于语言模型例如神经网络语言模型(NNLM)、word2vector(CBOW、skip-gram)、GloVe、ELMo。
word2vector中的skip-gram模型是利用类似于自动编码的器网络以中心词的one-hot表示作为输入来预测这个中心词环境中某一个词的one-hot表示,即先将中心词one-hot表示编码然后解码成环境中某个词的one-hot表示(多分类模型,损失函数用交叉熵)。CBOW是反过来的,分别用环境中的每一个词去预测中心词。尽管word2vector在学习词与词间的关系上有了大进步,但是它有很明显的缺点:只能利用一定窗长的上下文环境,即利用局部信息,没法利用整个语料库的全局信息。鉴于此,斯坦福的GloVe诞生了,它的全称是global vector,很明显它是要改进word2vector,成功利用语料库的全局信息。
共现概率
什么是共现概率
-
什么是共现?
单词\(i\)出现在单词\(j\)的环境中(论文给的环境是以\(j\)为中心的左右10个单词区间)叫共现。 -
什么是共现矩阵?
单词对共现次数的统计表。我们可以通过大量的语料文本来构建一个共现统计矩阵。
例如,有语料如下:
I like deep learning.
I like NLP.
I enjoy flying.
我以窗半径为1(前后都是1)来指定上下文环境,则共现矩阵就应该是:
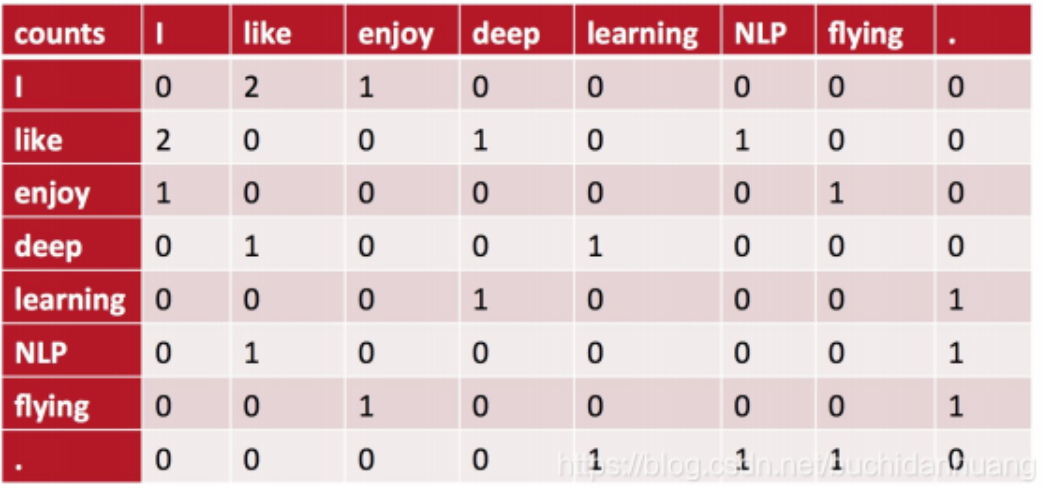
我们取\(x_{01}\)进行解释,它表示\(like\)出现在\(I\)的环境(I like区间)中的次数(在整个语料库中的总计次数),此处应当为2次(就是第一行的I like 和第二行的I like ),故第一行第二列应当填2。还应当发现,这个共现矩阵它是对称阵,因为\(like\)出现在\(I\)的环境中,那么必然\(I\)也会出现在\(like\)的环境中,所以\(x_{10}=2\)。
共现矩阵它有以下3个特点:
- 统计的是单词对在给定环境中的共现次数;所以它在一定程度上能表达词间的关系。
- 共现频次计数是针对整个语料库而不是一句或一段文档,具有全局统计特征。
- 共现矩阵它是对称的。
共现矩阵的生成步骤
- 首先构建一个空矩阵,大小为\(V \times V\),即词汇表×词汇表,值全为0。矩阵中的元素坐标记为\((i,j)\)。
- 确定一个滑动窗口的大小(例如取半径为\(m\))
- 从语料库的第一个单词开始,以1的步长滑动该窗口,因为是按照语料库的顺序开始的,所以中心词为到达的那个单词即\(i\)。
- 上下文环境是指在滑动窗口中并在中心单词\(i\)两边的单词(这里应有\(2m-1\)个\(j\))。
- 若窗口左右无单词,一般出现在语料库的首尾,则空着,不需要统计。
- 在窗口内,统计上下文环境中单词\(j\)出现的次数,并将该值累计到\((i,j)\)位置上。
- 不断滑动窗口进行统计即可得到共现矩阵。
什么是叫共现概率?
我们定义\(X\)为共现矩阵,共现矩阵的元素\(x_{ij}\)为词\(j\)出现在词\(i\)环境的次数,令\(x_i=\sum_kx_{ik}\)为任意词出现在i ii的环境的次数(即共现矩阵行和),那么,
\(P_{ij}=P(j|i)={x_{ij}\over x_{i}}\)为词\(j\)出现在词\(i\)环境中的概率(这里以频率表概率),这一概率被称为词\(i\)和词\(j\)的共现概率。共现概率是指在给定的环境下出现(共现)某一个词的概率。注意:在给定语料库的情况下,我们是可以事先计算出任意一对单词的共现概率的。
共现概率比
接下来阐述为啥作者要提共现概率和共现概率比这一概念。下面是论文中给的一组数据:
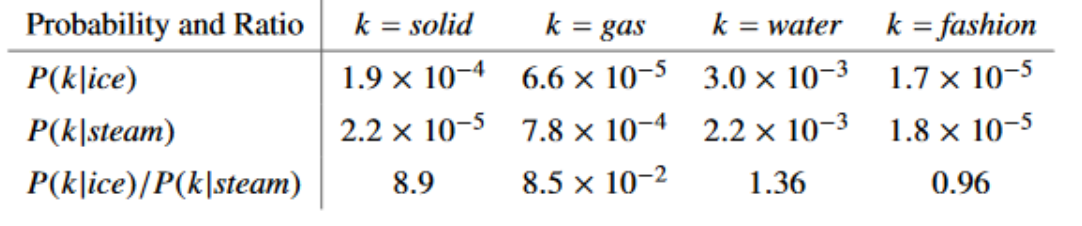
先看一下第一行数据,以\(ice(冰)\)为中心词的环境中出现\(solid(固体)\)的概率是大于\(gas(燃气)、fashion(时尚)\)的而且是小于\(water\)的,这是很合理的,对吧!因为有\(ice\)的句子中出现\(solid、water\)的概率确实应当比\(gas、fashion(时尚)\)大才对,实验数据也说明的确是如此。同理可以解释第二行数据。我们来重点考虑第三行数据:共现概率比。我们把共现概率进行一比,我们发现:
1.看第三行第一列:当\(ice\)的语境下共现\(solid\)的概率应该很大,当\(stream\)的语境下共现\(solid\)的概率应当很小,那么比值就>1。
2.看第三行第二列:当\(ice\)的语境下共现\(gas\)的概率应该很小,当\(stream\)的语境下共现\(gas\)的概率应当很大,那么比值就<1。
3.看第三行第三列:当\(ice\)的语境下共现\(water\)的概率应该很大,当\(stream\)的语境下共现\(water\)的概率也应当很大,那么比值就近似=1。
4.看第三行第四列:当\(ice\)的语境下共现\(fashion\)的概率应该很小,当\(stream\)的语境下共现\(fashion\)的概率也应当很小,那么比值也是近似=1。
因为作者发现用共现概率比也可以很好的体现3个单词间的关联(因为共现概率比符合常理),所以glove作者就大胆猜想,如果能将3个单词的词向量经过某种计算可以表达共现概率比就好了(glove思想)。如果可以的话,那么这样的词向量就与共现矩阵有着一致性,可以体现词间的关系。
设计词向量函数
想要表达共现概率比,这里涉及到的有三个词即\(i,j,k\),它们对应的词向量我用\(v_i、v_j、\widetilde{v}_k\)表示,那么我们需要找到一个映射f ff,使得\(f(v_i,v_j,\widetilde{v}_k)={P_{ik}\over P_{jk}}(1)\)。前面我说过,任意两个词的共现概率可以用语料库事先统计计算得到,那这里的给定三个词,是不是也可以确定共现概率比啊。这个比值可以作为标签,我们可以设计一个模型通过训练的方式让映射值逼近这个确定的共现概率比。很明显这是个回归问题,我们可以用均方误差作为\(loss\)。明显地,设计这个函数或者这个模型当然有很多途径,我们来看看作者是怎么设计的。
我们可以发现公式(1)等号右侧结果是个标量,左边是个关于向量的函数,如何将函数变成标量。于是作者这么设计:\(f((v_i-v_j)^T\widetilde{v}_k)={P_{ik}\over P_{jk}}(2)\)即向量做差再点积再映射到目标。再次强调,这只是一种设计,它可能不是那么严谨,合理就行。于是乎:

于是,glove模型的学习策略就是通过将词对儿的词向量经过内积操作和平移变换去趋于词对儿共现次数的对数值,这是一个回归问题。于是作者这样设计损失函数:
这里用的是误差平方和作为损失值,其中N表示语料库词典单词数。它这里在误差平方前给了一个权重函数\(f(x_{ij})\),这个权重是用来控制不同大小的共现次数\(x_{ij}\)对结果的影响的。作者是这么设计这个权重函数的:
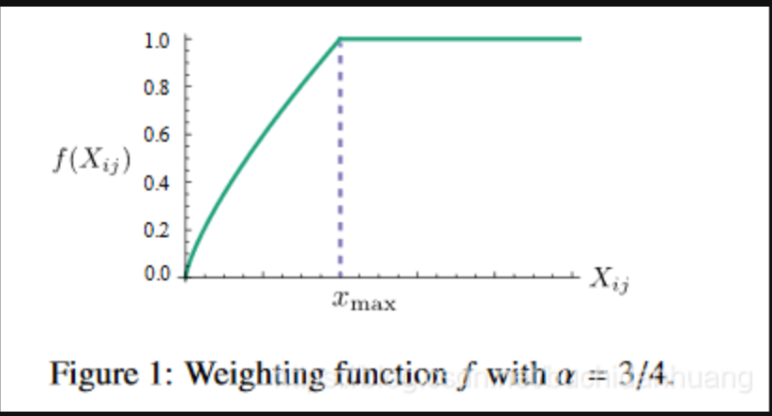
也就是说词对儿共现次数越多的它有更大的权重将被惩罚得更厉害些,次数少的有更小的权重,这样就可以使得不常共现的词对儿对结果的贡献不会太小,而不会过分偏向于常共现的词对儿。此外,当\(x_{ij}\)时,加入了这个权重函数此时该训练样本的损失直接为0,从而避免了\(log(x_{ij})\)为无穷小导致损失值无穷大的问题。
glove使用以及词表文件详解
glove是用来生成词向量的 ,在网上下载之后,会有一个txt格式的文件。截图如下:
glove.6B.XXXd.txt(例如 glove.6B.50d.txt,XXX是多少 ,就代表多少维 300d,那就是300维,也就是一个词用300维代表)文件里面装了什么。
它的每一行的格式如下:
词名字 + 数字
具体截图如下
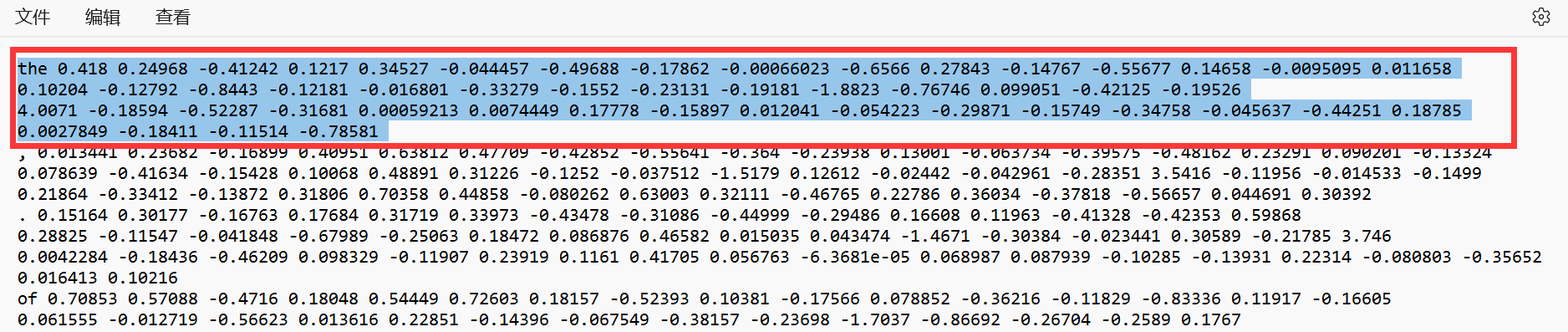
第一行 是由英语单词 the 和 50个数字组成 具体是多少个数字 ? 要看词表? 多少个数字也就代表了是多少维 50个数字也就是50维。
什么叫做词表??? 大家看到的 glove.6B.XXXd.txt 这个文件 也就是所谓的词表。
现在问题来了 我们如何将这个词表应用在NLP中呢?
第一,我们需要先把自然语言 ,也就是我们说的汉语,或者外国语(例如 英语 西班牙语 俄语等等)。先把这些语言转换成计算机可以识别认识的东西,也就是词向量。
重点是我们把 一句话变成计算机可以认识的东西是关键,怎么操作呢? 那就是把每一个词转换成词向量。
所以就有了上面的截图 要大家知道glove词表,以及词表里面具体有什么东西。每一行代表了什么。50个数字就是 每一行最开始那个单词对应的 词向量。
这些词向量都是大公司 谷歌 微软 百度公司 他们在大规模的语料上训练生成得到的。
假如咋们选取了50维度的词向量或者300维度的词向量,这些数字都有意义的,所以咋们就要用它。固定某一维度后,所有的字都用这个维度下的词向量表示,也就是有个标准。
用统一的词向量来表示和解决后面具体的问题。
关于如何使用词表,正式开始!
为了讲解的方便 我直接自己新建了一个文件test.txt 这个里面只有三行数据 ,原理是一样的,具体操作也是一样的。
首先读取文件,直接用open
然后通过一个for 循环 这里面的每一个line 里面装的都是 词语 和 词向量
embeddings_dict 代表了一个字典 然后向字典里面添加数据。
import numpy as np # 导入numpy包
embeddings_dict = {} # 新建一个字典 里面装键值对
with open("test.txt", 'r', encoding="utf-8") as f:
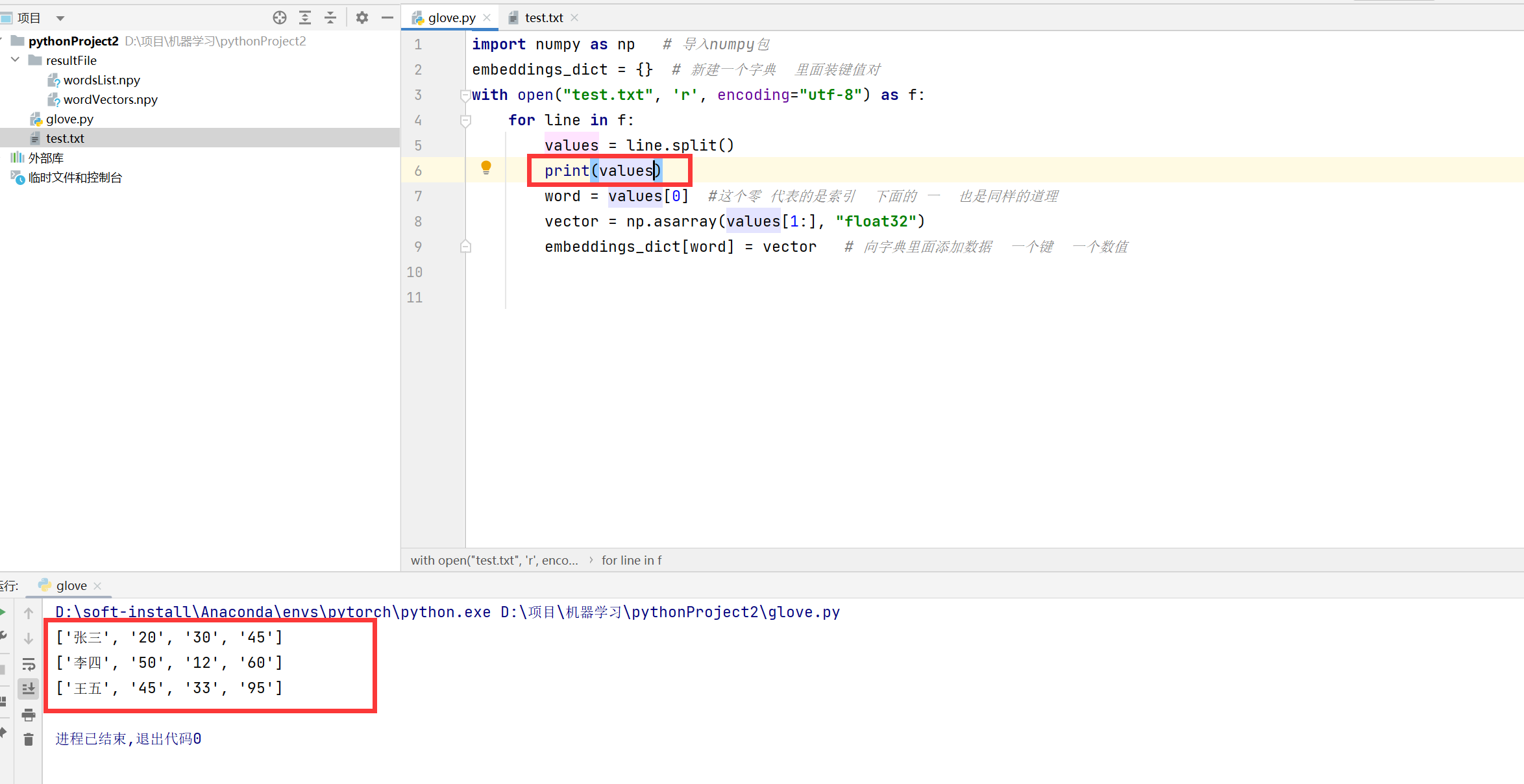
for line in f:
values = line.split()
word = values[0] #这个零 代表的是索引 下面的 一 也是同样的道理
vector = np.asarray(values[1:], "float32")
embeddings_dict[word] = vector # 向字典里面添加数据 一个键 一个数值
我们打印看看。
然后分别获取字典里面的 键 和 值,进一步进行存储,代码如下:
np.save('resultFile/wordsList', np.array(list(embeddings_dict.keys())))
np.save('resultFile/wordVectors', np.array(list(embeddings_dict.values())))
# resultFile/wordsList 这个东西这样理解。resultFile是一个文件目录 我们将东西存入到wordsList里面,wordsList 是自动生成的 这个一个npy格式文件的名字 ,想取什么名字都行
为什么要干这么一件事情呢?因为我们说的每一话 那个词语都是随机组成的 不是固定的,我们必须准确无误的查询到每一个词或者词语的具体词向量表示是什么。
这个词表都给出来了 ,我们把对应词的词向量准确的找到即可。这就是目的。
假如现在有一个词 我要找它的词向量,怎么做?请看下面
wordsList = np.load('resultFile/wordsList.npy')
# 这一行代码就是要加载之前生产的.npy文件 因为里面装了所有的词
wordsList = wordsList.tolist()
# 我们要把这个文件转换成 list 列表格式 便于后面我们找索引。
#为什么找索引 index ?因为 词 和词向量是一一对应的 我们之前存储的时候就是按照顺序存储的
#比如wordsList第一行是 the 这个单词。 然后wordVectors 这个文件第一行就是它的词向量
# 这就是 查找索引的意义 也就是说 两个文件分别存储 键 和 值 。索引是个桥梁 就是这么个意思
刚刚这是准备工作 比如找 "王五" 的词向量 请看下面代码
# 下面这一行代码是要找 陈六
baseballIndex = wordsList.index('王五')
print(baseballIndex) # 找到了桥梁 索引 咋们把这个索引号打出来
wordVectors = np.load('resultFile/wordVectors.npy') # 加载单独存储的那个词向量文件
print(wordVectors.shape) # 输出维度 比如(25,50) 这个25代表多少个词 50表示每一个词是用多少维向量表示
print(wordVectors[baseballIndex])# 顺利的输出 词向量
下面请看运行成功的截图 准确无误的找到了词向量是什么
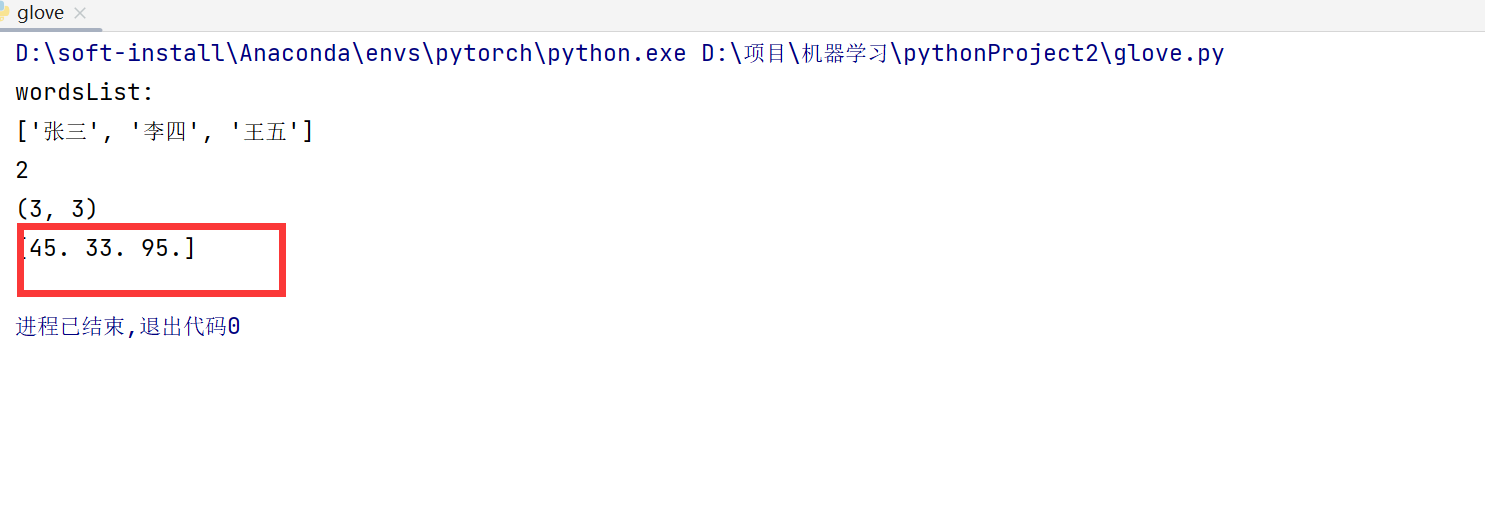
这个[45,33,95]是那个test.txt文件里面我随便编的 ,意思就是可以顺利找到那个所谓的词向量。
全部代码
import numpy as np # 导入numpy包
embeddings_dict = {} # 新建一个字典 里面装键值对
with open("test.txt", 'r', encoding="utf-8") as f:
for line in f:
values = line.split()
word = values[0] #这个零 代表的是索引 下面的 一 也是同样的道理
vector = np.asarray(values[1:], "float32")
embeddings_dict[word] = vector # 向字典里面添加数据 一个键 一个数值
np.save('resultFile/wordsList', np.array(list(embeddings_dict.keys())))
np.save('resultFile/wordVectors', np.array(list(embeddings_dict.values())))
# resultFile/wordsList 这个东西这样理解。resultFile是一个文件目录 我们将东西存入到wordsList里面,wordsList 是自动生成的 这个一个npy格式文件的名字 ,想取什么名字都行
wordsList = np.load('resultFile/wordsList.npy')
# 这一行代码就是要加载之前生产的.npy文件 因为里面装了所有的词
wordsList = wordsList.tolist()
print('wordsList:')
print(wordsList)
# 我们要把这个文件转换成 list 列表格式 便于后面我们找索引。
#为什么找索引 index ?因为 词 和词向量是一一对应的 我们之前存储的时候就是按照顺序存储的
#比如wordsList第一行是 the 这个单词。 然后wordVectors 这个文件第一行就是它的词向量
# 这就是 查找索引的意义 也就是说 两个文件分别存储 键 和 值 。索引是个桥梁 就是这么个意思
# 下面这一行代码是要找 陈六
baseballIndex = wordsList.index('王五')
print(baseballIndex) # 找到了桥梁 索引 咋们把这个索引号打出来
wordVectors = np.load('resultFile/wordVectors.npy') # 加载单独存储的那个词向量文件
print(wordVectors.shape) # 输出维度 比如(25,50) 这个25代表多少个词 50表示每一个词是用多少维向量表示
print(wordVectors[baseballIndex])# 顺利的输出 词向量
参考文献:
https://blog.csdn.net/buchidanhuang/article/details/98471741
词的相似性和类比任务
import os
import torch
from torch import nn
from d2l import torch as d2l
加载预训练词向量
#@save
d2l.DATA_HUB['glove.6b.50d'] = (d2l.DATA_URL + 'glove.6B.50d.zip',
'0b8703943ccdb6eb788e6f091b8946e82231bc4d')
#@save
d2l.DATA_HUB['glove.6b.100d'] = (d2l.DATA_URL + 'glove.6B.100d.zip',
'cd43bfb07e44e6f27cbcc7bc9ae3d80284fdaf5a')
#@save
d2l.DATA_HUB['glove.42b.300d'] = (d2l.DATA_URL + 'glove.42B.300d.zip',
'b5116e234e9eb9076672cfeabf5469f3eec904fa')
#@save
d2l.DATA_HUB['wiki.en'] = (d2l.DATA_URL + 'wiki.en.zip',
'c1816da3821ae9f43899be655002f6c723e91b88')
为了加载这些预训练的GloVe和fastText嵌入,我们定义了以下TokenEmbedding类。
#@save
class TokenEmbedding:
"""GloVe嵌入"""
def __init__(self, embedding_name):
self.idx_to_token, self.idx_to_vec = self._load_embedding(
embedding_name)
self.unknown_idx = 0
self.token_to_idx = {token: idx for idx, token in
enumerate(self.idx_to_token)}
def _load_embedding(self, embedding_name):
idx_to_token, idx_to_vec = ['<unk>'], []
data_dir = d2l.download_extract(embedding_name)
# GloVe网站:https://nlp.stanford.edu/projects/glove/
# fastText网站:https://fasttext.cc/
with open(os.path.join(data_dir, 'vec.txt'), 'r') as f:
for line in f:
elems = line.rstrip().split(' ')
token, elems = elems[0], [float(elem) for elem in elems[1:]]
# 跳过标题信息,例如fastText中的首行
if len(elems) > 1:
idx_to_token.append(token)
idx_to_vec.append(elems)
idx_to_vec = [[0] * len(idx_to_vec[0])] + idx_to_vec
return idx_to_token, torch.tensor(idx_to_vec)
def __getitem__(self, tokens):
indices = [self.token_to_idx.get(token, self.unknown_idx)
for token in tokens]
vecs = self.idx_to_vec[torch.tensor(indices)]
return vecs
def __len__(self):
return len(self.idx_to_token)
下面我们加载50维GloVe嵌入(在维基百科的子集上预训练)。创建TokenEmbedding实例时,如果尚未下载指定的嵌入文件,则必须下载该文件。
glove_6b50d = TokenEmbedding('glove.6b.50d')
Downloading ../data/glove.6B.50d.zip from http://d2l-data.s3-accelerate.amazonaws.com/glove.6B.50d.zip...
输出词表大小。词表包含400000个词(词元)和一个特殊的未知词元。
len(glove_6b50d)
400001
我们可以得到词表中一个单词的索引,反之亦然。
glove_6b50d.token_to_idx['beautiful'], glove_6b50d.idx_to_token[3367]
(3367, 'beautiful')
可以看看这个词的词向量
glove_6b50d.idx_to_vec[3367],glove_6b50d.idx_to_vec[3367].shape
(tensor([ 0.5462, 1.2042, -1.1288, -0.1325, 0.9553, 0.0405, -0.4786, -0.3397,
-0.2806, 0.7176, -0.5369, -0.0046, 0.7322, 0.1210, 0.2809, -0.0881,
0.5973, 0.5526, 0.0566, -0.5025, -0.6320, 1.1439, -0.3105, 0.1263,
1.3155, -0.5244, -1.5041, 1.1580, 0.6880, -0.8505, 2.3236, -0.4179,
0.4452, -0.0192, 0.2897, 0.5326, -0.0230, 0.5896, -0.7240, -0.8522,
-0.1776, 0.1443, 0.4066, -0.5200, 0.0908, 0.0830, -0.0220, -1.6214,
0.3458, -0.0109]),
torch.Size([50]))
应用预训练词向量
使用加载的GloVe向量,我们将通过下面的词相似性和类比任务中来展示词向量的语义。
词相似度
为了根据词向量之间的余弦相似性为输入词查找语义相似的词,我们实现了以下knn(近邻)函数。
def knn(W, x, k):
# 增加1e-9以获得数值稳定性
cos = torch.mv(W, x.reshape(-1,)) / (
torch.sqrt(torch.sum(W * W, axis=1) + 1e-9) *
torch.sqrt((x * x).sum()))
_, topk = torch.topk(cos, k=k)
return topk, [cos[int(i)] for i in topk]
然后,我们使用TokenEmbedding的实例embed中预训练好的词向量来搜索相似的词。
def get_similar_tokens(query_token, k, embed):
topk, cos = knn(embed.idx_to_vec, embed[[query_token]], k + 1)
for i, c in zip(topk[1:], cos[1:]): # 排除输入词
print(f'{embed.idx_to_token[int(i)]}:cosine相似度={float(c):.3f}')
glove_6b50d中预训练词向量的词表包含400000个词和一个特殊的未知词元。排除输入词和未知词元后,我们在词表中找到与“chip”一词语义最相似的三个词。
get_similar_tokens('chip', 3, glove_6b50d)
chips:cosine相似度=0.856
intel:cosine相似度=0.749
electronics:cosine相似度=0.749
下面输出与“baby”和“beautiful”相似的词。
get_similar_tokens('baby', 3, glove_6b50d)
babies:cosine相似度=0.839
boy:cosine相似度=0.800
girl:cosine相似度=0.792
get_similar_tokens('beautiful', 3, glove_6b50d)
lovely:cosine相似度=0.921
gorgeous:cosine相似度=0.893
wonderful:cosine相似度=0.830
词类比
除了找到相似的词,我们还可以将词向量应⽤到词类比任务中。例如,“man”:“woman”::“son”:“daughter”是⼀个词的类比。“man”是对“woman”的类比,“son”是对“daughter”的类⽐。具体来说,词类比任务可以定义为:对于单词类比a : b :: c : d,给出前三个词a、b和c,找到d。⽤vec(w)表⽰词w的向量,为了完成这个类比,我们将找到⼀个词,其向量与vec(c) + vec(b) − vec(a)的结果最相似。
def get_analogy(token_a, token_b, token_c, embed):
vecs = embed[[token_a, token_b, token_c]]
x = vecs[1] - vecs[0] + vecs[2]
topk, cos = knn(embed.idx_to_vec, x, 1)
return embed.idx_to_token[int(topk[0])] # 删除未知词
get_analogy('man', 'woman', 'son', glove_6b50d)
# 'daughter'
get_analogy('beijing', 'china', 'tokyo', glove_6b50d)
# 'japan'
get_analogy('bad', 'worst', 'big', glove_6b50d)
# 'biggest'
get_analogy('do', 'did', 'go', glove_6b50d)
# 'went'
小结
在实践中,在大型语料库上预先练的词向量可以应用于下游的自然语言处理任务。
预训练的词向量可以应用于词的相似性和类比任务。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号