自然语言处理:预训练-近似训练(解决softmax种类太多的问题)
跳元模型的主要思想是使⽤softmax运算来计算基于给定的中⼼词\(w_c\)⽣成
上下文字\(w_o\)的条件概率。
由于softmax操作的性质,上下文词可以是词表V中的任意项,也就是说可以是词表(通常有几十万或数百万个单词)中的所有词,包含与整个词表⼤⼩⼀样多的项的求和。因此,跳元模型的梯度计算和 的连续词袋模型的梯度计算都包含求和。不幸的是,在⼀个词典上(通常有⼏⼗万或数百万个单词)求和的梯度的计算成本是巨大的!
为了降低上述计算复杂度,本节将介绍两种近似训练⽅法:负采样和分softmax。
负采样
背景
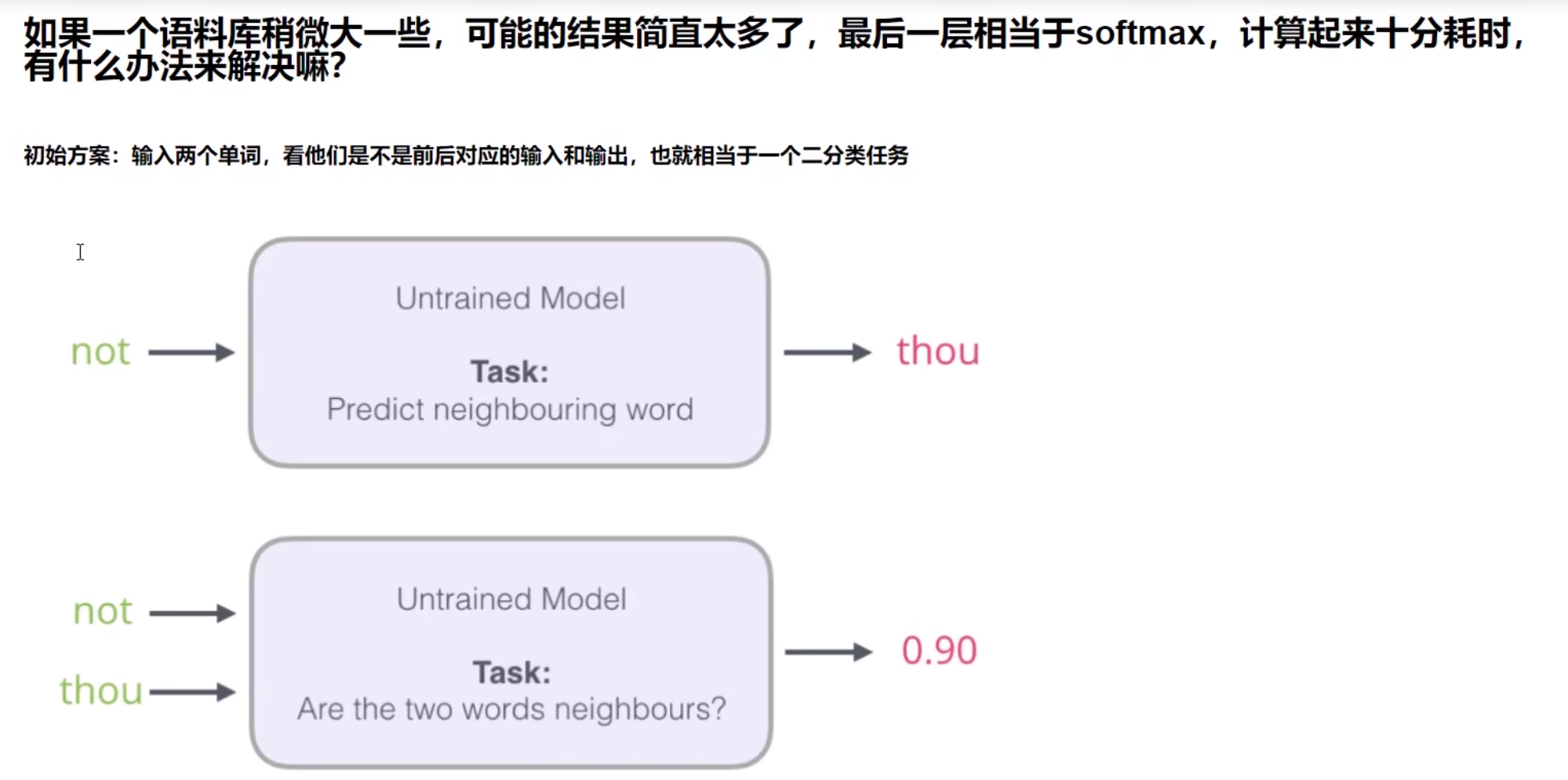
也就是说我们本来输入一个"not"需要预测的是"thou",我们可以将"not"和"thou"都弄成输入,然后这个输出就是一个概率,指的是"thou"是"not"的后面的一个词的概率,然后这就变成了二分类了。
出发点非常好,但是此时训练集构建出来的标签全为1,无法进行较好的训练。因为这样进行训练的话,机器就会无脑给1。
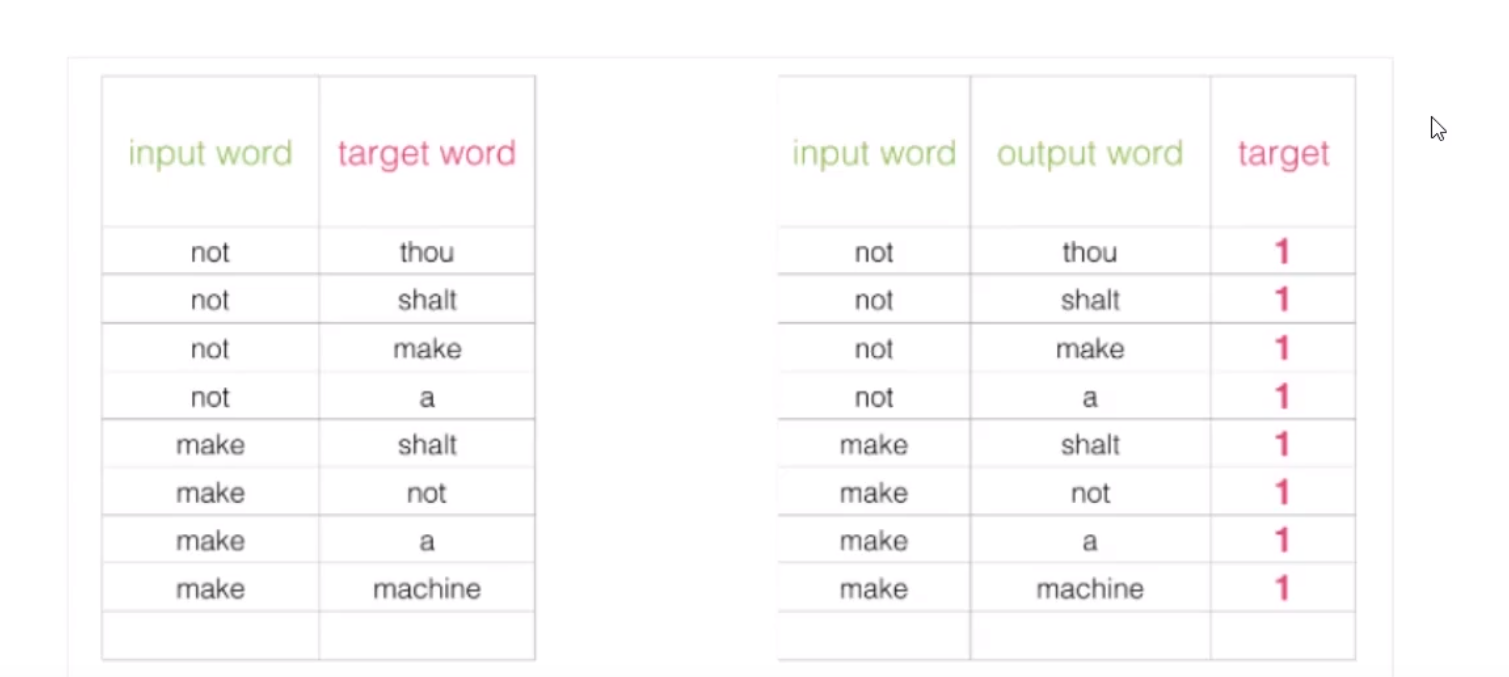
改进方案
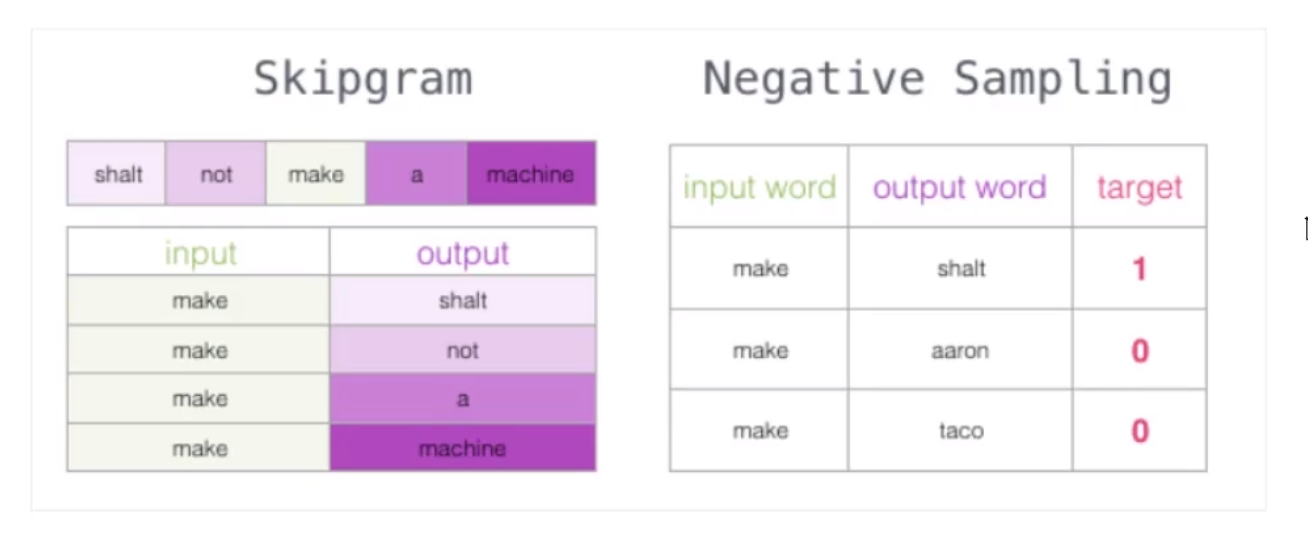
我们应该加一些负采样(负采样模型),就是加一些0标签。

层序Softmax
层次softmax的思想是基于二叉树对模型的输出进行改进如图所示
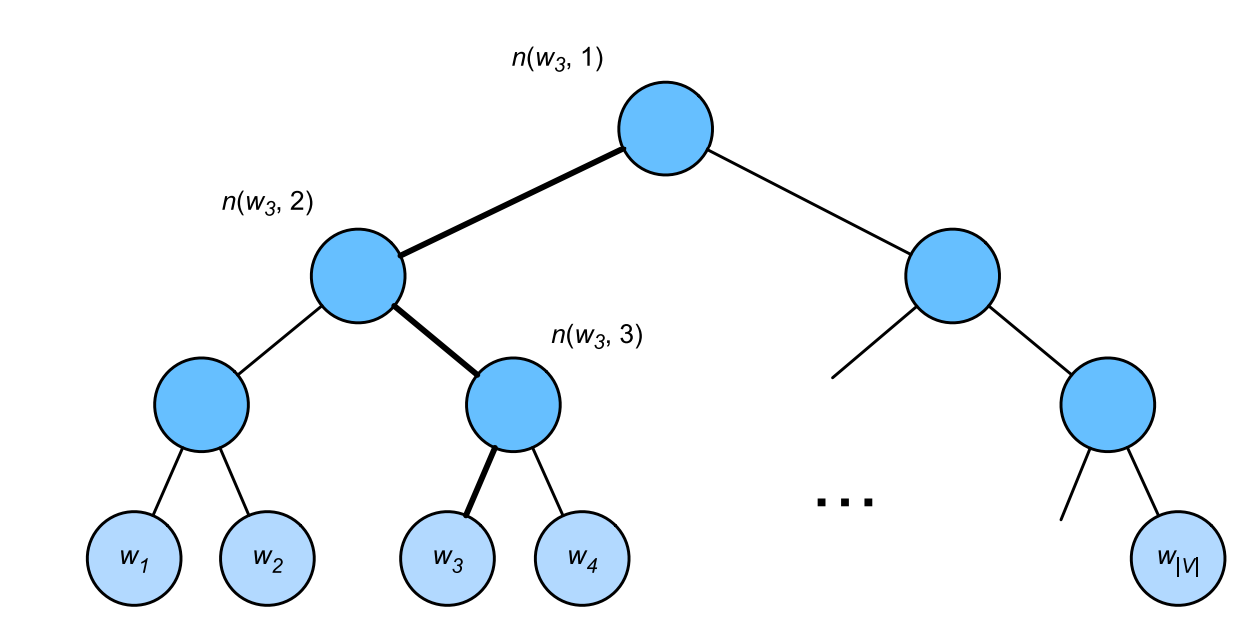
其中树的每个叶节点表示词表\(V\)中的⼀个词。
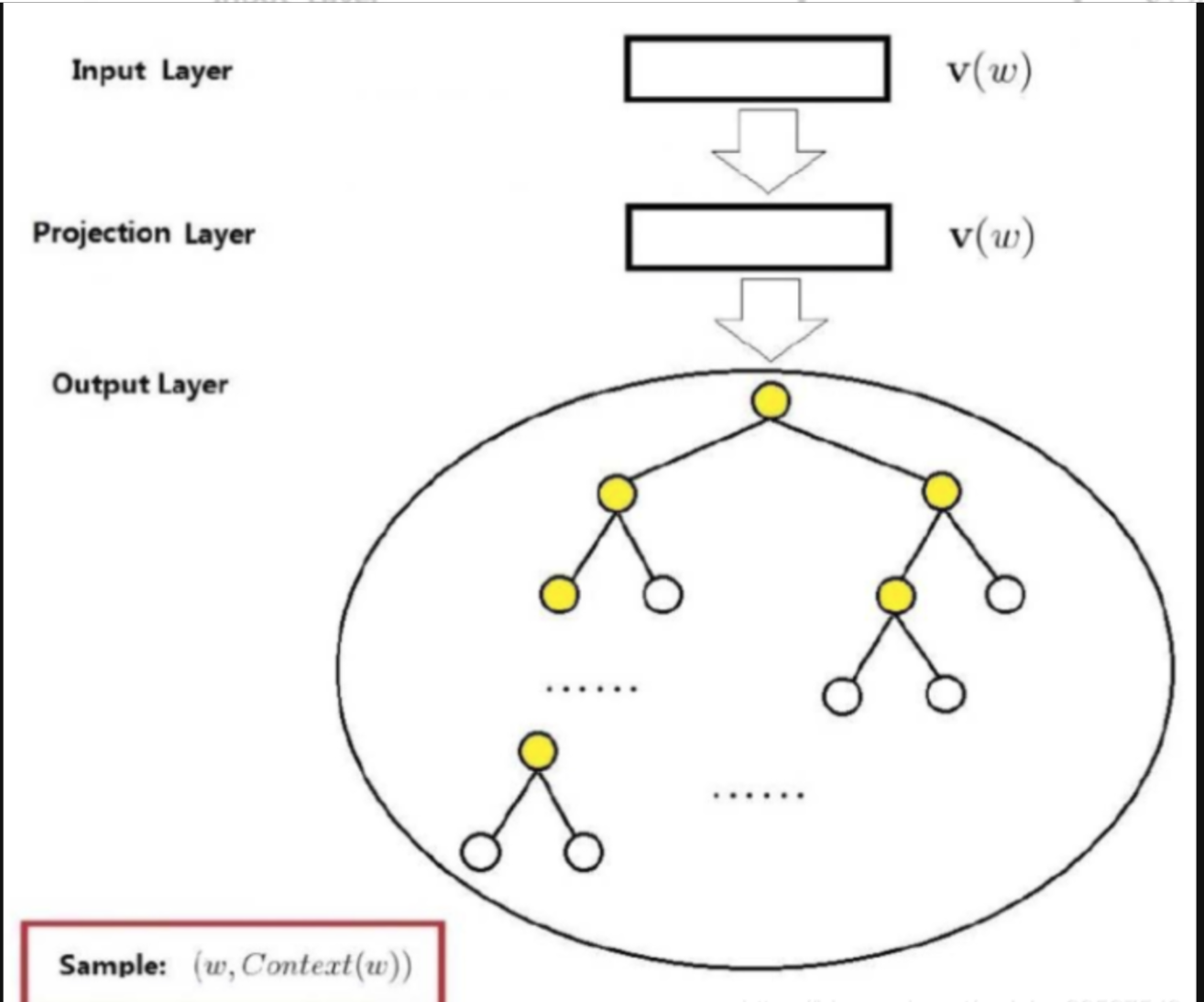
这样就能将\(O(N)\)的复杂度降到\(O(lg(N))\)。
用\(L(w)\)表示二叉树中表示字\(w\)的从根节点到叶节点的路径上的节点数(包括两端)。设\(n(w, j)\)为该路径上的\(j^{th}\)节点,其上下文字向量为\(u_{n(w,j)}\)。例如,图14.2.1中的L(w3) = 4。分层softmax的条件概率
近似为:
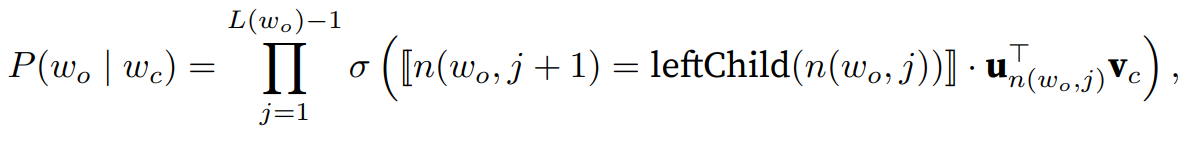
其中\(leftChild(n)\)是节点\(n\)的左⼦节点:如果\(x\)为真,\([x] = 1\);否则\([x] = −1\)。
为了说明,让我们计算给定词\(w_c\)⽣成词\(w_3\)的条件概率。这需要\(w_c\)的词向量\(v_c\)和从根到\(w_3\)的路径上的非叶节点向量之间的点积,该路径依次向左、向右和向左遍历:
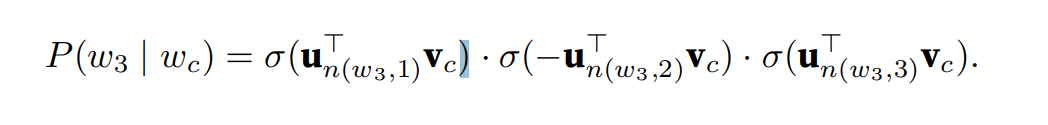
由\(\sigma(x) + \sigma(−x) = 1\),它认为基于任意词\(w_c\)⽣成词表\(V\)中所有词的条件概率总和为1:
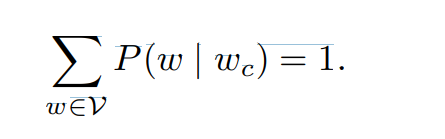
幸运的是,由于⼆叉树结构,\(L(w_o) − 1\)⼤约与\(O(log_2|V|)\)是⼀个数量级。当词表⼤⼩V很⼤时,与没有近似训练的相⽐,使⽤分层softmax的每个训练步的计算代价显著降低。
总结
- 负采样通过考虑相互独⽴的事件来构造损失函数,这些事件同时涉及正例和负例。训练的计算量与每⼀步的噪声词数成线性关系。
- 分层softmax使⽤⼆叉树中从根节点到叶节点的路径构造损失函数。训练的计算成本取决于词表⼤⼩的对数。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号