Bert(李宏毅)
Self-supervised Learning
首先我们看一下什么是Supervised Learning呢?

其实就是我们输入一个\(x\),经过一个model,然后我们输出一个\(y\)。但是我们需要label标签。比如说我们来判断一篇文章是正面的还是负面的。我们需要先找一大堆文章来,然后标注上文章是正面的还是负面的,这个就是label。
而Self-supervised,就是我们对于一篇没有标注(label)的文章。首先我们将这个一篇文章复制成两份,一份作为model的输入\(x'\)然后一份作为标注\(x''\)。然后我们要这个这个model输出的\(y\)和\(x''\)越接近越好。也就是说在没有办法做supervised的时候自己想办法做supervised。
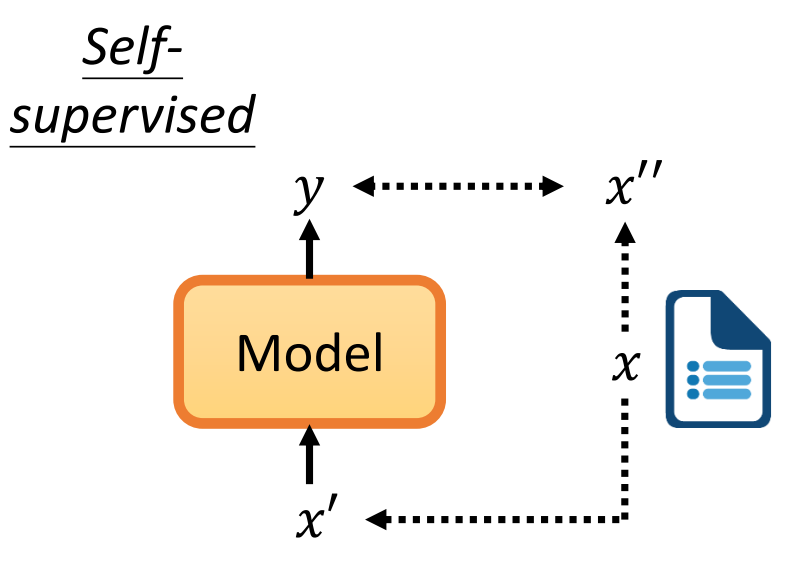
上面我们说的非常抽象,下面用BERT这个模型来说明一下。
Masking Input
对于Bert,它的输入是一些文字:
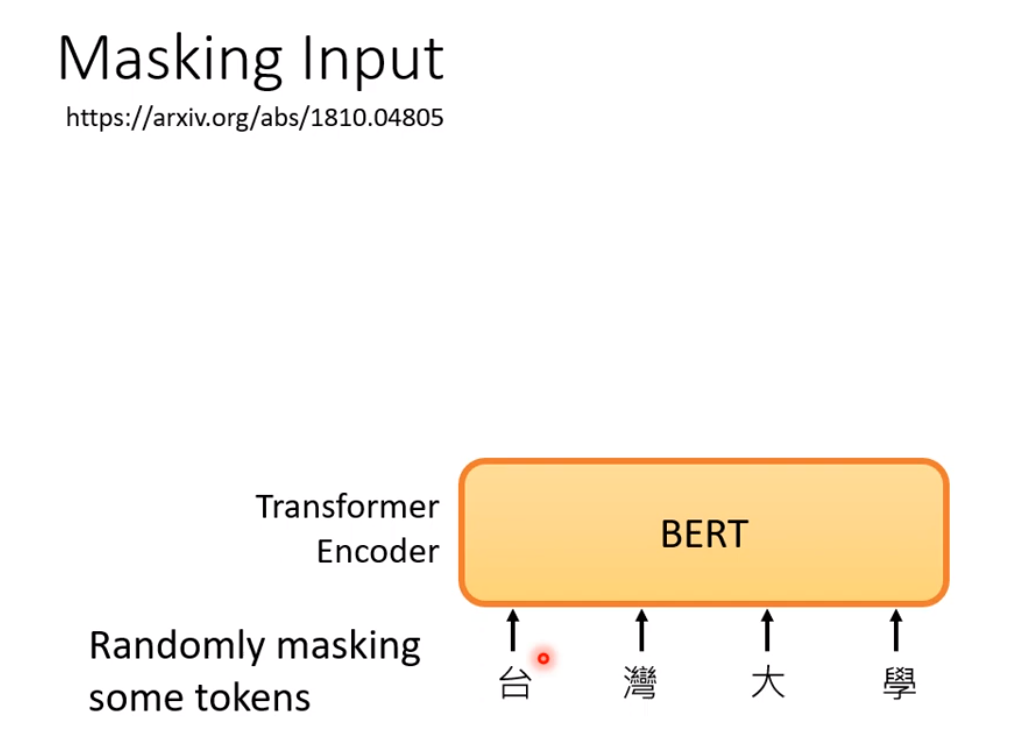
然后我们将输入的文字给他随机的盖住。所谓盖住有两种做法:
- 我们把句子中的某个字换成一个特殊的符号例如
<mask>。 - 随机把某个字换成另外一个字。

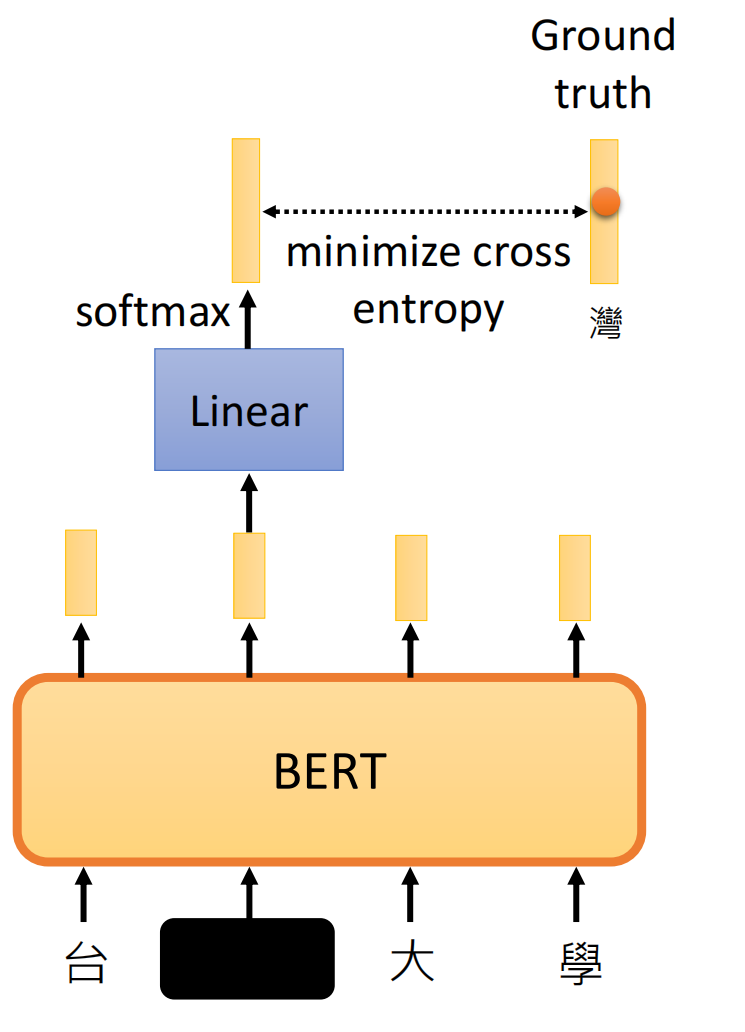
就是我们先在句子中选择那个字要被盖住,然后再随机的选择一种方法给他盖住。然后我们将盖住的部分进行预测。相当于一个多分类任务。我们类别的数目就跟词的数目一样多。

因为我们知道这个真实的词,所以我们要最小化这两个词:
Next Sentence Prediction
首先我们先收集很多的句子对,然后我们将两个句子的中间和最前面加上两个特殊的符号<sep>和<cls>。
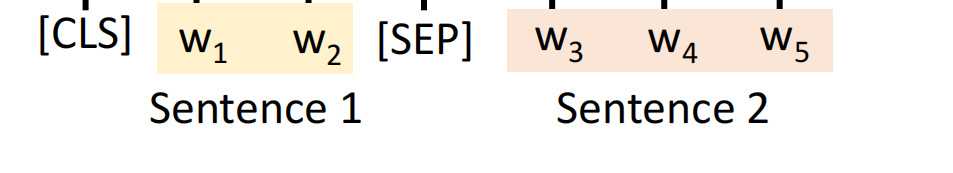
然后我们将其一股脑的放在Bert中:

我们只看第一个<cls>的输出,输出Yes或者No。指的是这两个句子是不是相接的,Yes就代表是相接的,No就代表不是相接的。这里为什么只看第一个<cls>来表示标签呢,因为我们再self-attention中<cls>已经和后面的全部句子进行self-attention,所以这个<cls>已经掌握了全部句子的语义了。
然后我们发现这个BERT有什么用呢?我们发现它只会做masked token prediction和next sentence prediction。我们发现它只会做填空题。但是我们发现我们将训练好的BERT用在其他不是填空题的地方效果也很好。总之,BERT它只学会做选择题,然后接下来可以拿来用再各式各样的下游的任务。然后前面的self-supervised Learning就叫做Pre-train,然后这些下行任务就叫做Fine-tune。

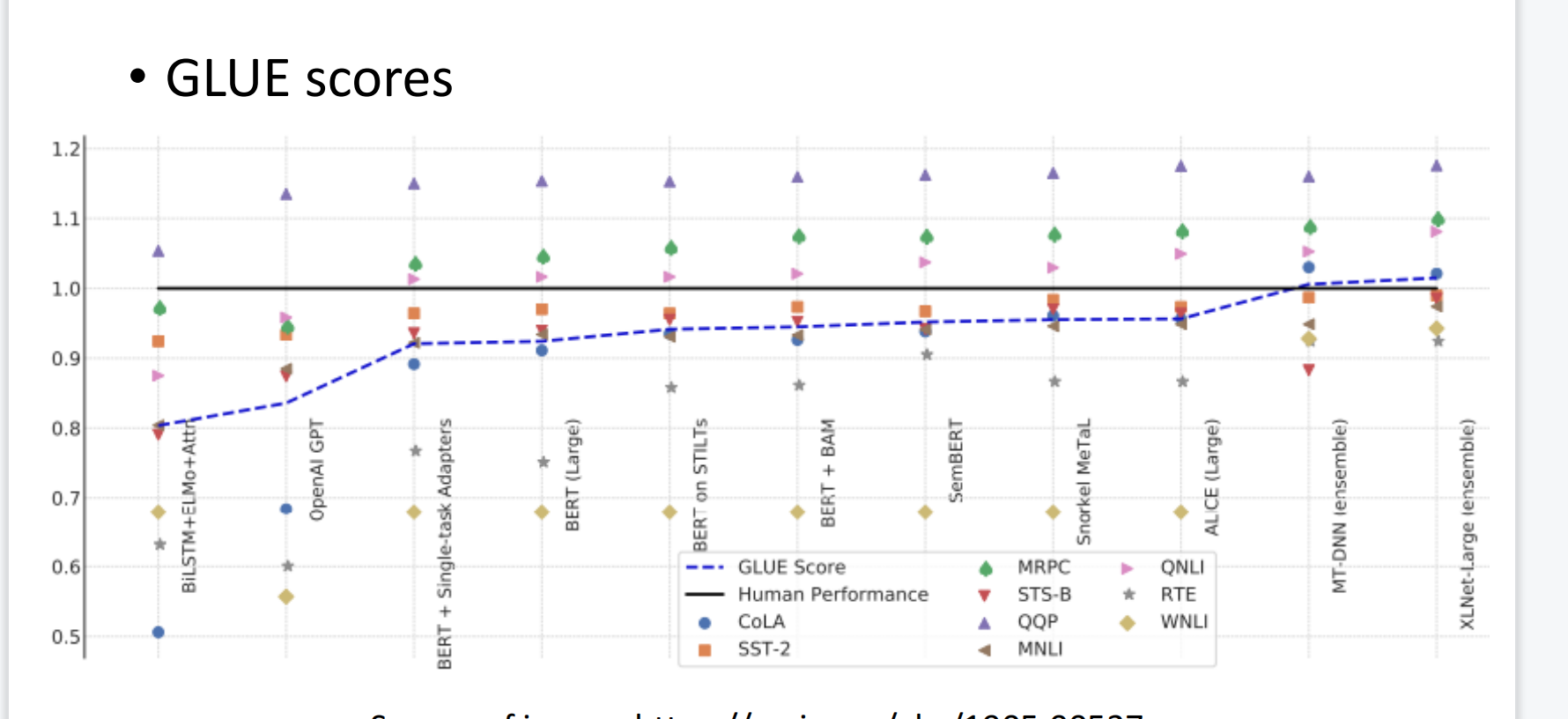
GLUE
我们有了一个BERT我们怎么知道这个模型的好坏呢?然后这里有9个任务,可以用来评价BERT模型的好坏。

这一条黑色的线是人类的分数。
How to use BERT
Case 1
就是输入一个句子,然后输出一个类别。例如:情感分析。
这个Linear中的参数是随机初始化的,而这个BERT的参数是学会了做填空题的参数直接填在BERT里面来初始化pre-train,因为它好过随机初始。

我们可以看一下:用填空题做初始化的参数比随机化的好。

Case 2
输入一个sequence输出也是一个sequence。输入输出的长度是一样的。例如:pos tagging(词性标注)。就是将BERT的输出做一个Linear,然后再做一个softmax。

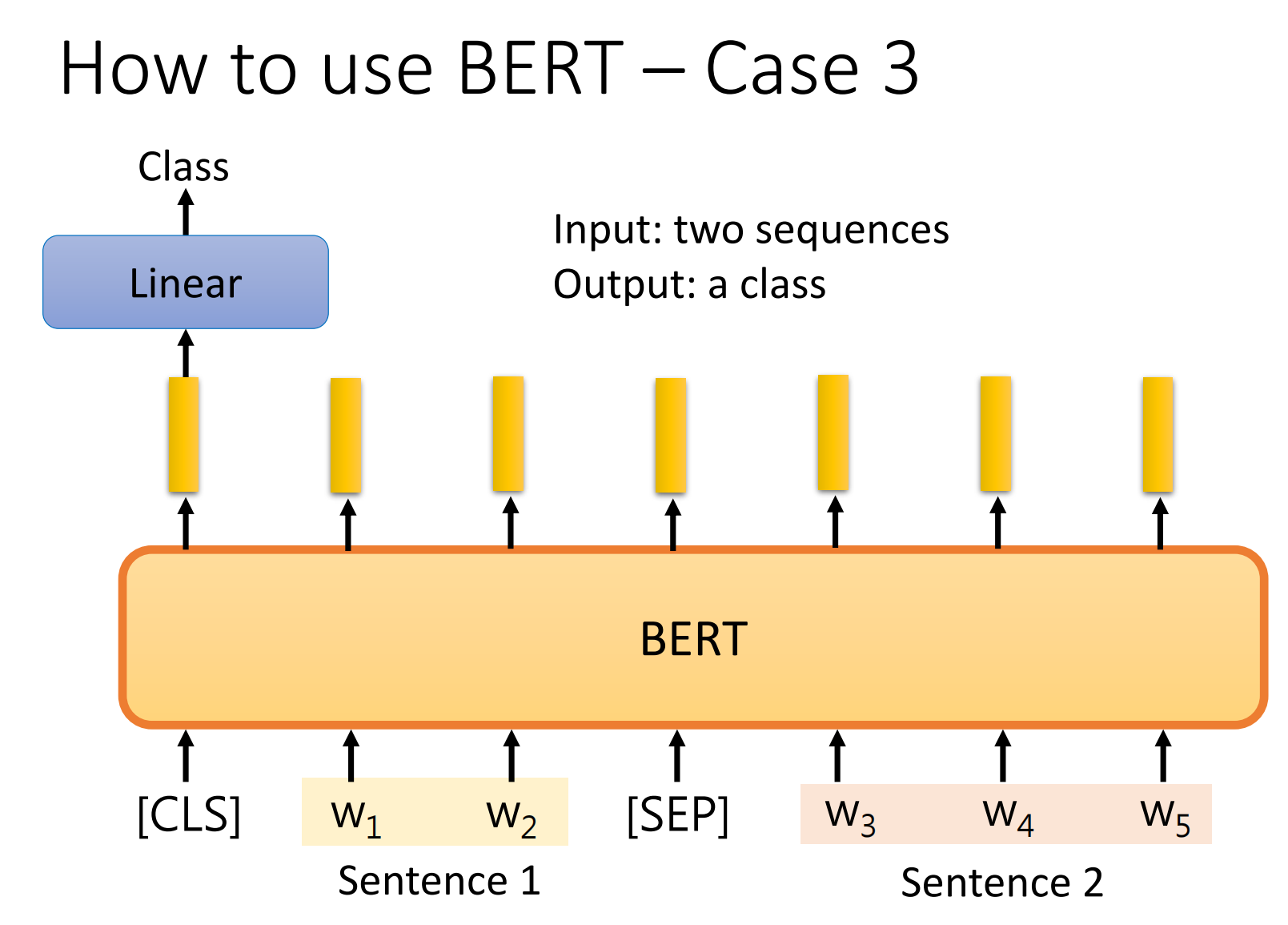
Case 3
输入是两个句子。然后输出一个类别,例如:Natural Language Inferencee(NLI)。就是给你一个前提然后再给你一个假设,看看这个假设是否符合这个前提。
例如:前提是:一个人骑着一匹马跳过了一架破损的飞机.
假设: 一个人再吃完晚饭.
很显然这个假设是错误的,这个前提和假设是矛盾的.

BERT是怎么做这个问题的呢?
Case 4
就是给你一个问题,然后它会给你一个答案,但是这个答案是文章中的一个片段.
其实就是我们将一个句子输入到模型中,然后这模型输出两个数字\(s\)和\(e\).代表这个答案的起始和末尾.
例如:

这里的输入是一篇文章,然后文章和问题之间有一个特殊的符号:


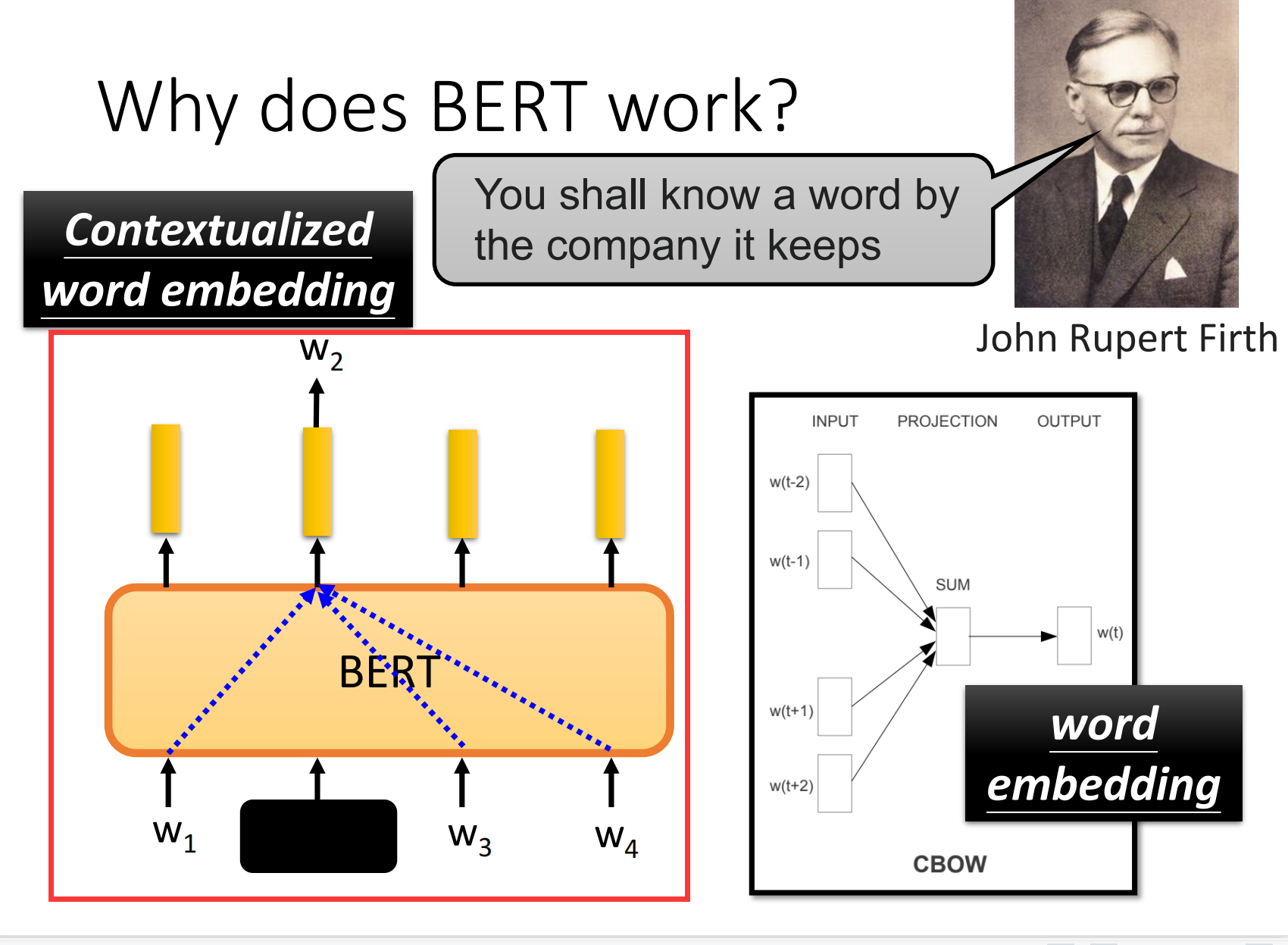
why does BERT work?

我们输入一个字,然后输出这个字的embedding,然后这个embedding就代表了他输入字的意思。什么叫代表意思呢?也就是说我们将这些字算他们之间的距离,然后意思越相近的词的向量就越相近。例如这个"果"和"草","鸟"和"鱼".

但是有时候相同的但是,它的涵义也不同。比如说苹果手机的果和吃苹果的果,这两个果虽然单词一样,但是意思一点都不一样。
接下来,我们将"喝苹果汁"和"苹果手机"丢到BERT中,然后我们计算它的相似度。

上面5个是吃的苹果,下面5个是用的苹果电子产品,我们会发现上面五个相似,下面5个相似,然后上面5个和下面5个人一点都不相似。所以BERT输出的那个词就代表了他这个词的意思。
那么BERT是怎么知道它的意思的呢?实际上BERT是通过他的上下文来学习到他的意思的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号