BERT
BERT:公认的里程碑
BERT 模型可以作为公认的里程碑式的模型,但是它最大的优点不是创新,而是集大成者,并且这个集大成者有了各项突破,下面让我们看看 BERT 是怎么集大成者的。
BERT 的意义在于:从大量无标记数据集中训练得到的深度模型,可以显著提高各项自然语言处理任务的准确率。
近年来优秀预训练语言模型的集大成者:参考了 ELMO 模型的双向编码思想、借鉴了 GPT 用 Transformer 作为特征提取器的思路、采用了 word2vec 所使用的 CBOW 方法
BERT 和 GPT 之间的区别:
GPT:GPT 使用 Transformer Decoder 作为特征提取器、具有良好的文本生成能力,然而当前词的语义只能由其前序词决定,并且在语义理解上不足
BERT:使用了 Transformer Encoder 作为特征提取器,并使用了与其配套的掩码训练方法。虽然使用双向编码让 BERT 不再具有文本生成能力,但是 BERT 的语义信息提取能力更强
单向编码和双向编码的差异,以该句话举例 “今天天气很{ _ },我们不得不取消户外运动”,分别从单向编码和双向编码的角度去考虑 { _ } 中应该填什么词:单向编码:单向编码只会考虑 “今天天气很”,以人类的经验,大概率会从 “好”、“不错”、“差”、“糟糕” 这几个词中选择,这些词可以被划为截然不同的两类
双向编码:双向编码会同时考虑上下文的信息,即除了会考虑 “今天天气很” 这五个字,还会考虑 “我们不得不取消户外运动” 来帮助模型判断,则大概率会从 “差”、“糟糕” 这一类词中选择
BERT 的结构:强大的特征提取能力
如下图所示,我们来看看 ELMo、GPT 和 BERT 三者的区别
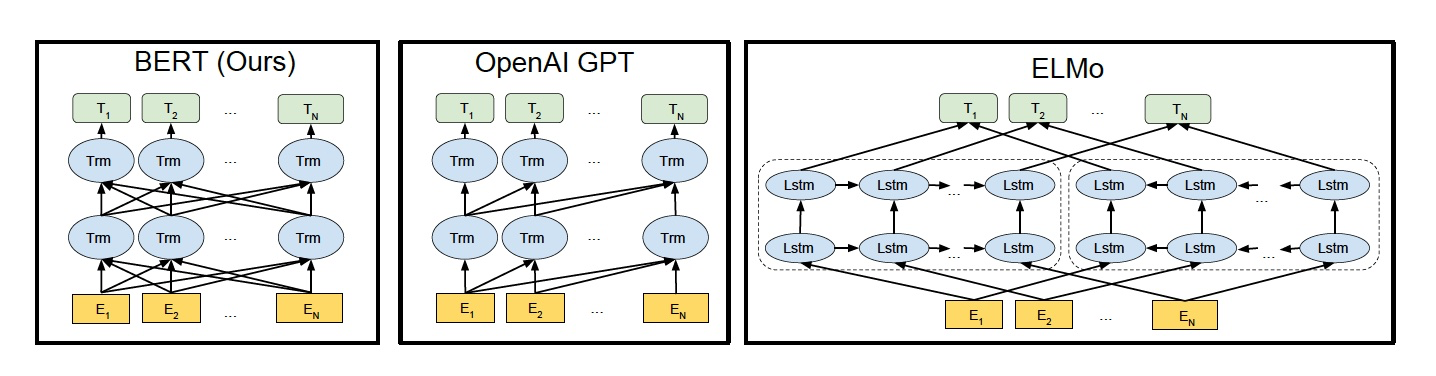
- ELMo 使用自左向右编码和自右向左编码的两个 LSTM 网络,分别以 \(P(w_i|w_1,\cdots,w_{i-1})\)和\(P(w_i|w_{i+1},\cdots,w_n)\)为目标函数独立训练,将训练得到的特征向量以拼接的形式实现双向编码,本质上还是单向编码,只不过是两个方向上的单向编码的拼接而成的双向编码。
- GPT 使用 Transformer Decoder 作为 Transformer Block,以\(P(w_i|w_1,\cdots,w_{i-1},w_{i+1},\cdots,w_n)\)为目标函数进行训练,用 Transformer Block 取代 LSTM 作为特征提取器,实现了单向编码,是一个标准的预训练语言模型,即使用 Fine-Tuning 模式解决下游任务。
- BERT 也是一个标准的预训练语言模型,它以\(P(w_i|w_1,\cdots,w_{i-1},w_{i+1},\cdots,w_n)\)为目标函数进行训练,BERT 使用的编码器属于双向编码器。
- BERT 和 ELMo 的区别在于使用 Transformer Block 作为特征提取器,加强了语义特征提取的能力;
- BERT 和 GPT 的区别在于使用 Transformer Encoder 作为Transformer Block,并且将 GPT 的单向编码改成双向编码,也就是说 BERT 舍弃了文本生成能力,换来了更强的语义理解能力。
BERT之无监督训练
和 GPT 一样,BERT 也采用二段式训练方法:
- 第一阶段:使用易获取的大规模无标签余料,来训练基础语言模型;
- 第二阶段:根据指定任务的少量带标签训练数据进行微调训练。
不同于 GPT 等标准语言模型使用\(P(w_i|w_1,\cdots,w_{i-1})\)为目标函数进行训练,能看到全局信息的 BERT 使用\(P(w_i|w_1,\cdots,w_{i-1},w_{i+1},\cdots,w_n)\)为目标函数进行训练。
并且 BERT 用语言掩码模型(MLM)方法训练词的语义理解能力;用下句预测(NSP)方法训练句子之间的理解能力,从而更好地支持下游任务。
BERT的整体了解
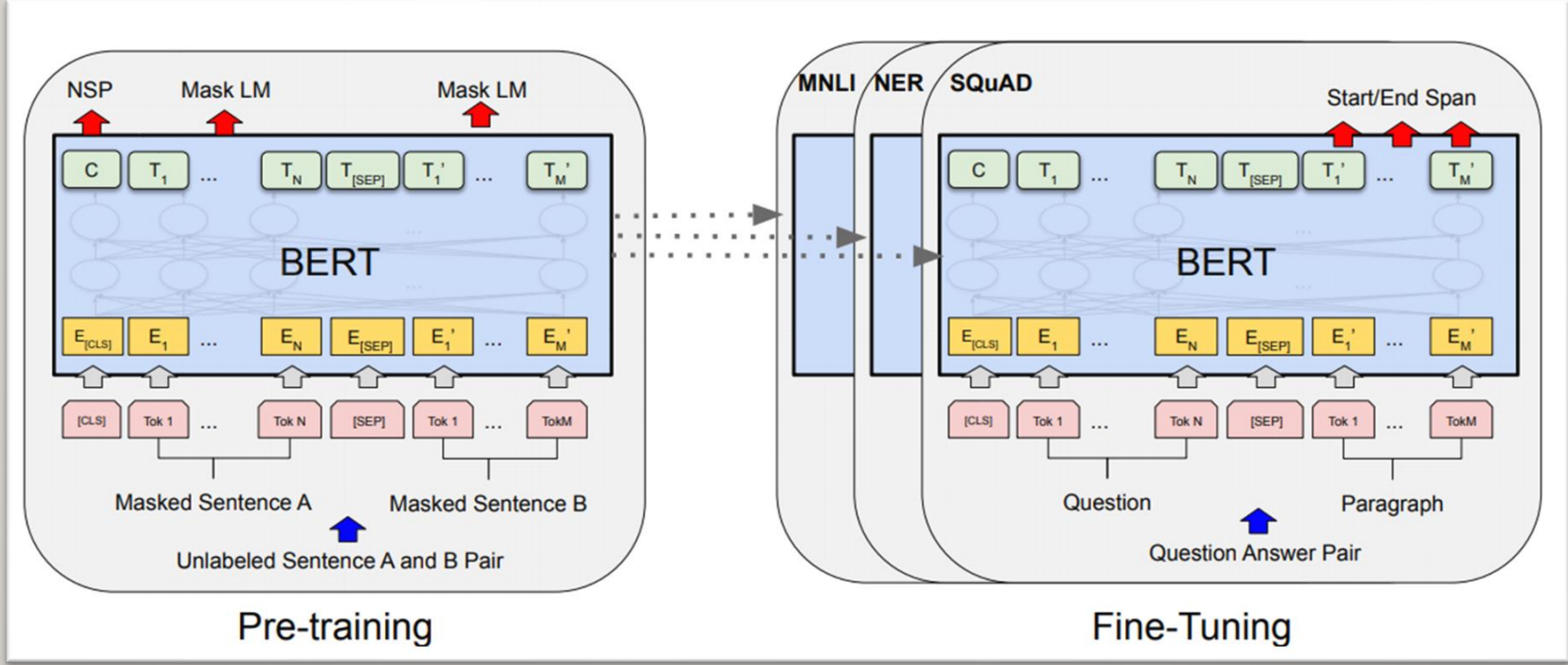
BERT可以分为预训练(Pre-Training)与微调(Fine-tune)。预训练简单来说就是通过两个任务联合训练得到Bert模型以及参数。而微调便是在预训练得到Bert模型基础上进行各种各样的NLP任务。
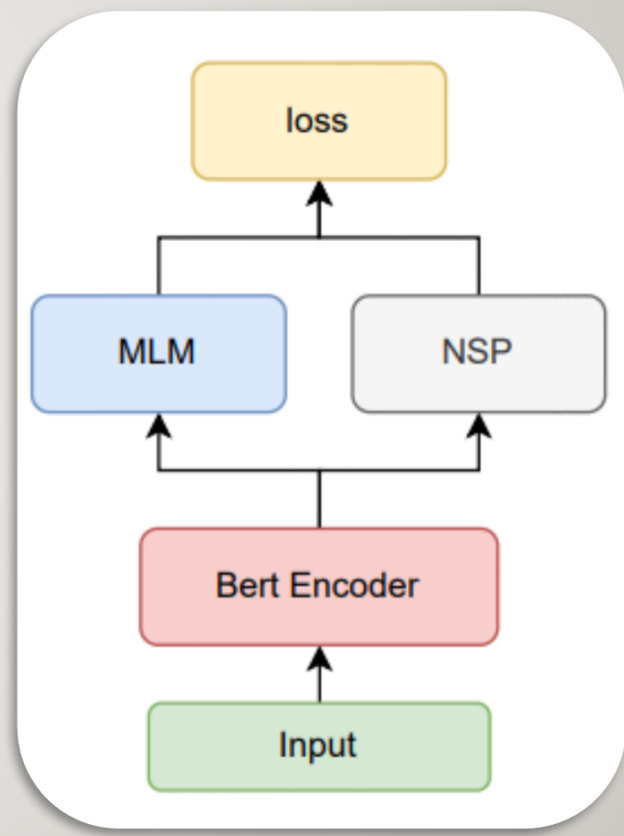
BERT预训练
预训练大致的过程如右图所示。输入经Bert Encoder层编码后,进行MLM与NSP的任务,产生一个联合训练的损失函数从而迭代更新整个模型中的参数。
-
BERT Encoder: 采取默认12层的Transformer Encoder Layer对输入进行编码。
-
MLM:掩蔽语言模型( Masked Language Modeling ),遮盖句子中若干个词通过周围词去预测被遮盖的词。
-
NSP:下一个句子预测( Next Sentence Prediction ),判断句子B在文章是否属于句子A的下一个句子。
BERT ENCODER
- 输入:
- 一对句子。例如
["my","dog","is","cute"], ["he","likes","play","##ing"] - 给句首添加
<CLS>符号,两句句子中间添加<SEP>符号,句末也添加<SEP>符号,组成一组输入。变为["<CLS>", "my","dog","is","cute","<SEP>","he","likes","play","##ing","<SEP>"] - 在Embedding层将输入组合成三种Embedding的相加,分别是Token级别、句子级别、位置级别的Embedding。具体如下图所示:
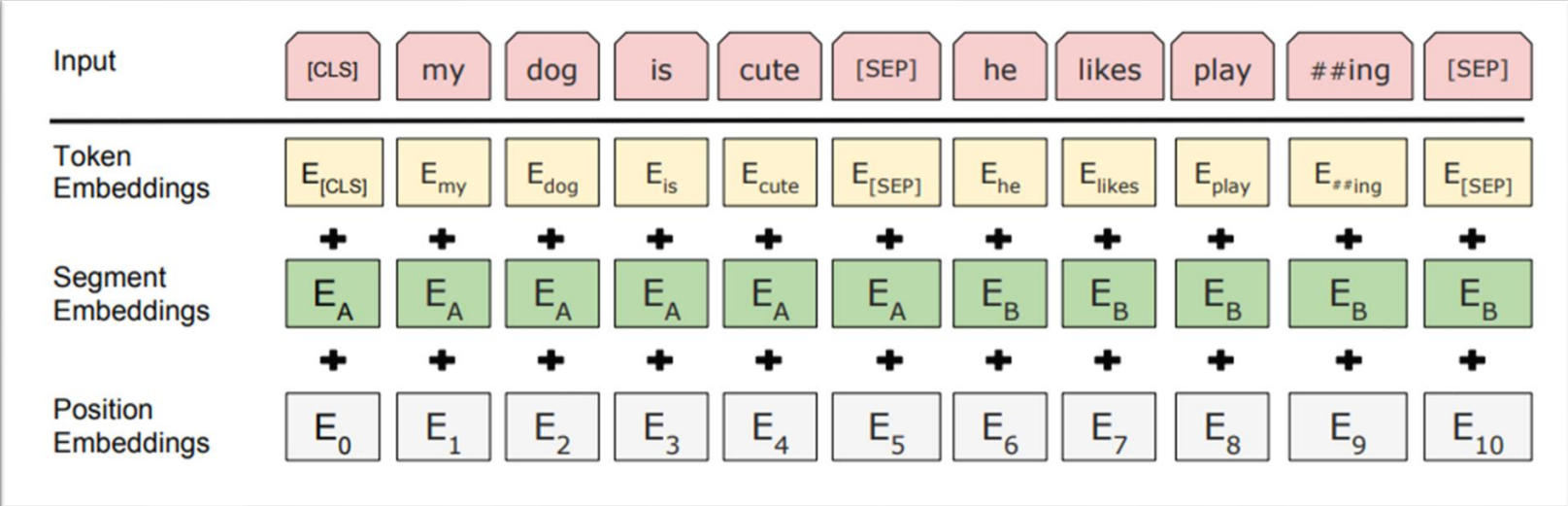
对于这个Segment Embeddings,我们可以认为它的前一个句子是\(E_A\),后一个句子是\(E_B\),比如说前一个句子的Segment Embeddings是0,后一个的是1。用于区别两个不同的句子。
-
中间:若干层的Transformer Encoder Layer, 默认为12。
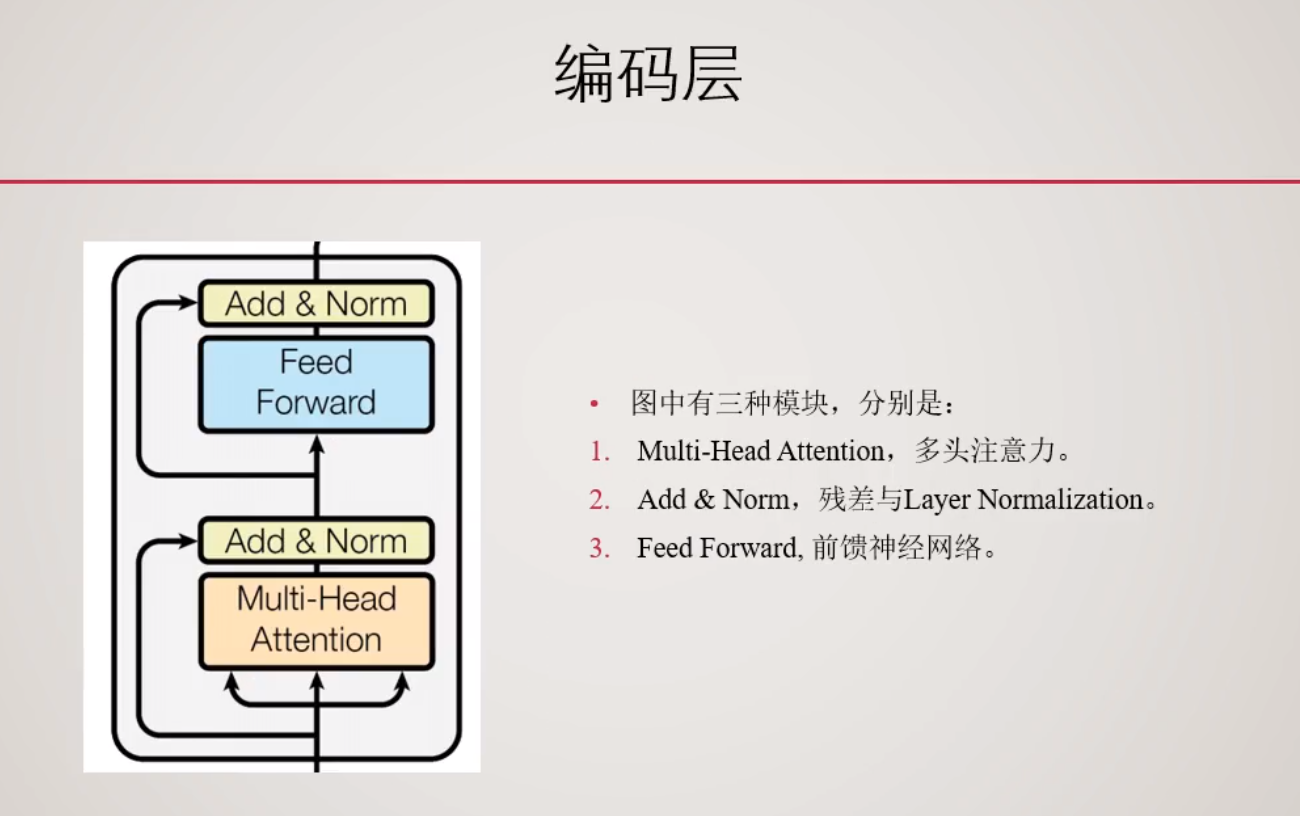
-
输出:编码好的张量。形状为
[Batch Size,Seq lens,Emb dim]
MLM(掩蔽语言模型)
为了双向编码上下文以表示每个词元,BERT随机掩蔽词元并使用来自双向上下文的词元以自监督的方式预测掩蔽词元。此任务称为掩蔽语言模型。
-
输入:Bert Encoder层的输出,需要预测的词元位置。
需要预测的词元位置指的是[Batch Size,词元位置数量]的一个张量。比如说\(0,1,4\)说明需要预测的是\(位置0,位置1,位置4\)。 -
中间:一个MLP的结构。默认的形式如下图所示。
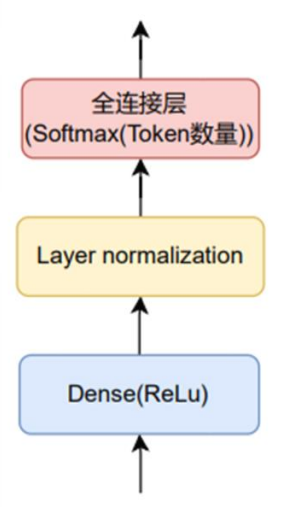
-
输出:序列类别分布张量。形状为
[Batch Size,需要预测的词元位置数量,总Token数量]。这个需要预测的词元位置数量就是前面说的需要预测的,然后总Token数量是一共词的数量,它类似与做多分类的任务,每个值就对应每个分类的概率。 -
采样:
➢ 每一对句子中随机选择15%位置的词语进行遮盖动作。
➢ 遮盖时80%替换为<mask>, 10%替换为随机词元, 10%不变。过程中<CLS>与<SEP>不会被替换。
➢ 例如["<CLS>","my","dog","is","cute","<SEP>","he","likes","play","##ing","<SEP>"]
变为:["<CLS>","my","<mask>","is","dog","<SEP>","he","likes","play", "<mask>","<SEP>"]
这是为什么呢?
MLM 方法也就是随机去掉句子中的部分 token(单词),然后模型来预测被去掉的 token 是什么。这样实际上已经不是传统的神经网络语言模型(类似于生成模型)了,而是单纯作为分类问题,根据这个时刻的 hidden state 来预测这个时刻的 token 应该是什么,而不是预测下一个时刻的词的概率分布了。
随机去掉的 token 被称作掩码词,在训练中,掩码词将以 15% 的概率被替换成 [MASK],也就是说随机 mask 语料中 15% 的 token,这个操作则称为掩码操作。注意:在CBOW 模型中,每个词都会被预测一遍。
但是这样设计 MLM 的训练方法会引入弊端:在模型微调训练阶段或模型推理(测试)阶段,输入的文本中将没有 [MASK],进而导致产生由训练和预测数据偏差导致的性能损失。
考虑到上述的弊端,BERT 并没有总用 [MASK] 替换掩码词,而是按照一定比例选取替换词。在选择 15% 的词作为掩码词后这些掩码词有三类替换选项:
80% 练样本中:将选中的词用 [MASK] 来代替,例如:
“地球是`[MASK]`八大行星之一”
10% 的训练样本中:选中的词不发生变化,该做法是为了缓解训练文本和预测文本的偏差带来的性能损失,例如:
“地球是太阳系八大行星之一”
10% 的训练样本中:将选中的词用任意的词来进行代替,该做法是为了让 BERT 学会根据上下文信息自动纠错,例如:
“地球是苹果八大行星之一”
作者在论文中提到这样做的好处是,编码器不知道哪些词需要预测的,哪些词是错误的,因此被迫需要学习每一个 token 的表示向量,另外作者也表示双向编码器比单项编码器训练要慢,进而导致BERT 的训练效率低了很多,但是实验也证明 MLM 训练方法可以让 BERT 获得超出同期所有预训练语言模型的语义理解能力,牺牲训练效率是值得的。
NSP(下一句预测)
尽管掩蔽语言建模能够编码双向上下文来表示单词,但它不能显式地建模文本对之间的逻辑关系。为了帮助理解两个文本序列之间的关系,BERT在预训练中考虑了一个二元分类任务——下一句预测。在为预训练生成句子对时,有一半的时间它们确实是标签为“真”的连续句子;在另一半的时间里,第二个句子是从语料库中随机抽取的,标记为“假”。
-
输入:Bert Encoder层输出
<CLS>位置的张量(也就是序列中的首位),形状为[Batch Size,Emd dim]。 -
中间:一个MLP的结构。默认是一个输出维度为2的,激活函数为Softmax的全连接层。
-
输出:类别分布张量。形状为
[Batch Size, 2]。 -
采样:采样时,50%的概率将第二句句子随机替换为段落中的任意一句句子。
50%概率选择相邻句子对<cls> this movie is great <sep> i like it <sep>
50%概率选择随机句子对<cls> this movie is great <sep> hello world <sep>
NSP 的具体做法是,BERT 输入的语句将由两个句子构成,其中,50% 的概率将语义连贯的两个连续句子作为训练文本(连续句对一般选自篇章级别的语料,以此确保前后语句的语义强相关),另外 50% 的概率将完全随机抽取两个句子作为训练文本。
连续句对:[CLS]今天天气很糟糕[SEP]下午的体育课取消了[SEP]
随机句对:[CLS]今天天气很糟糕[SEP]鱼快被烤焦啦[SEP]
其中[SEP]标签表示分隔符。[CLS]表示标签用于类别预测,结果为 1,表示输入为连续句对;结果为 0,表示输入为随机句对,这里为什么是[cls]表示标签呢,因为我们再self-attention中[cls]已经和后面的全部句子进行self-attention,所以这个[cls]已经掌握了全部句子的语义了。
通过训练[CLS]编码后的输出标签,BERT 可以学会捕捉两个输入句对的文本语义,在连续句对的预测任务中,BERT 的正确率可以达到 97%-98%。
训练过程
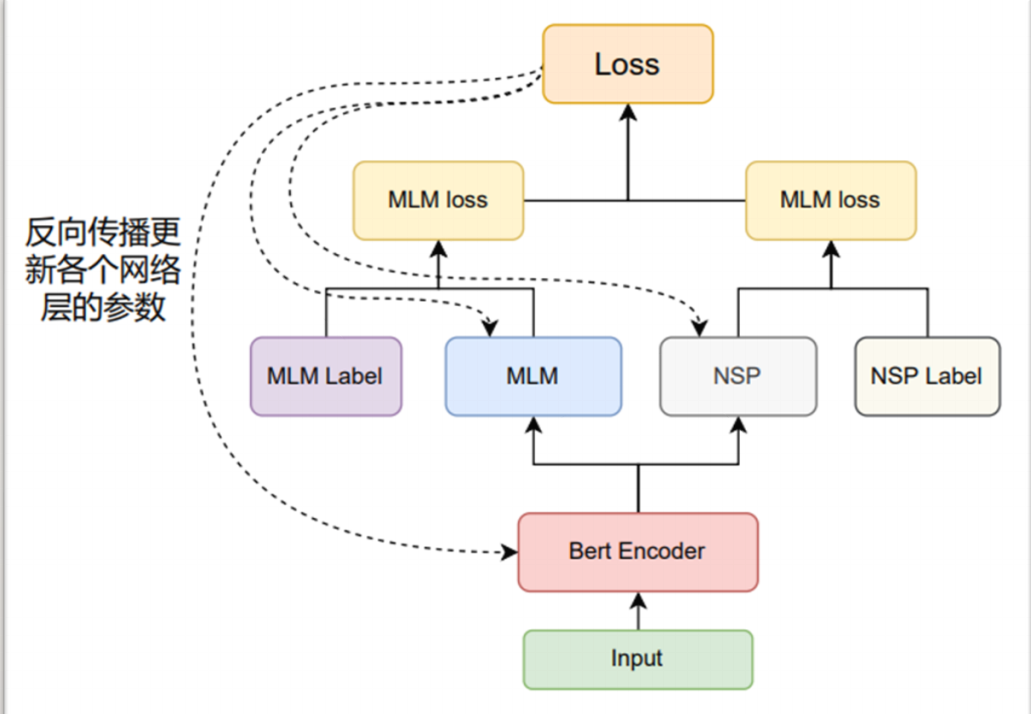
-
先通过文本数据整理出:( 没有考虑padding )
(1) 索引化的Tokens(已经随机选取了MLM与NSP任务数据)
(2) 索引化的Segments
(3) MLM任务要预测的位置
(4) MLM任务的真实标注
(5) NSP任务的真实标注 -
将(1)(2)输入Bert Encoder得到编码后的向量,以下称为(6)
-
将(6)与(3)输入MLM网络得到预测值与(4)计算交叉熵损失函数。
-
在(6)中取出
<CLS>对应位置的张量输入NSP网络得到值与(5)计算交叉熵损失函数。 -
将MLM的loss与NSP的loss相加得到总的loss,并反向传播更新所有模型参数。
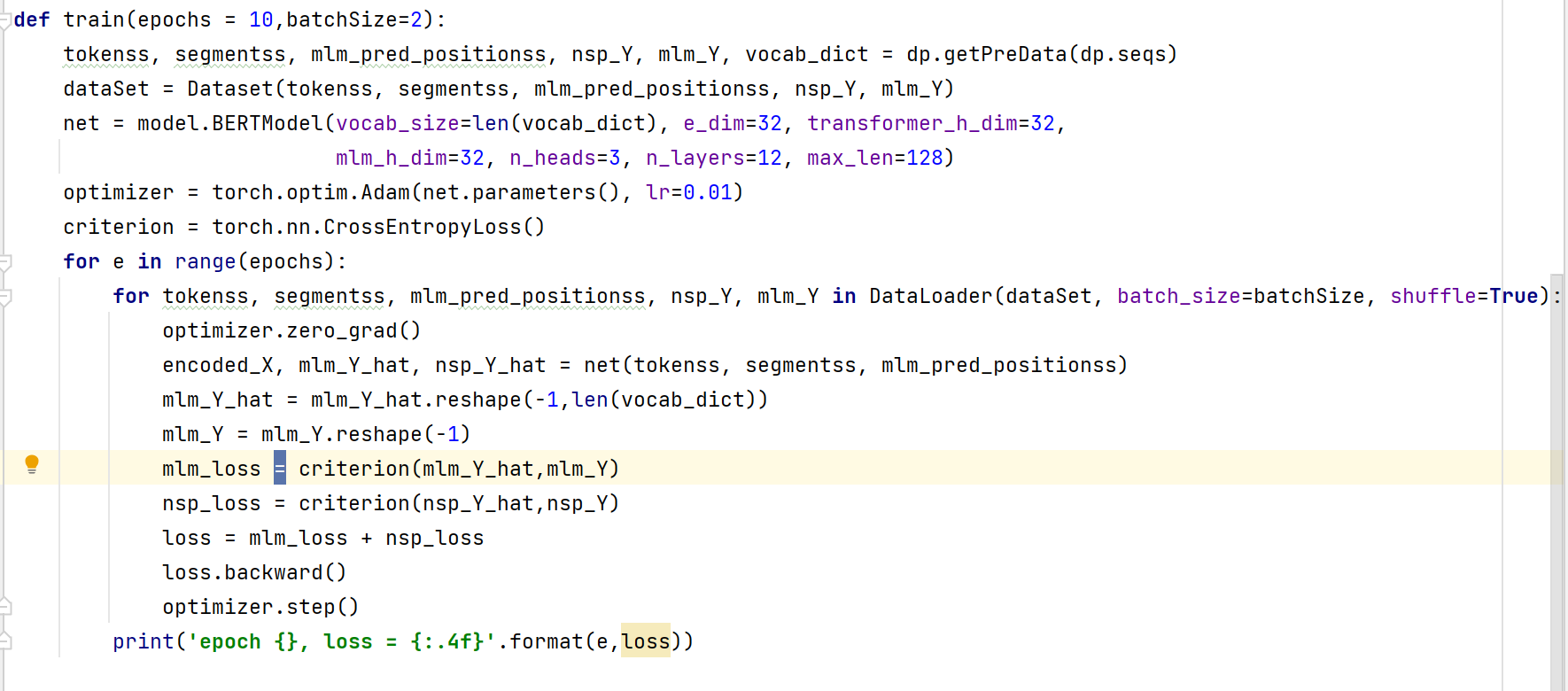
然后让我们通过代码来看看这这些数值的含义:
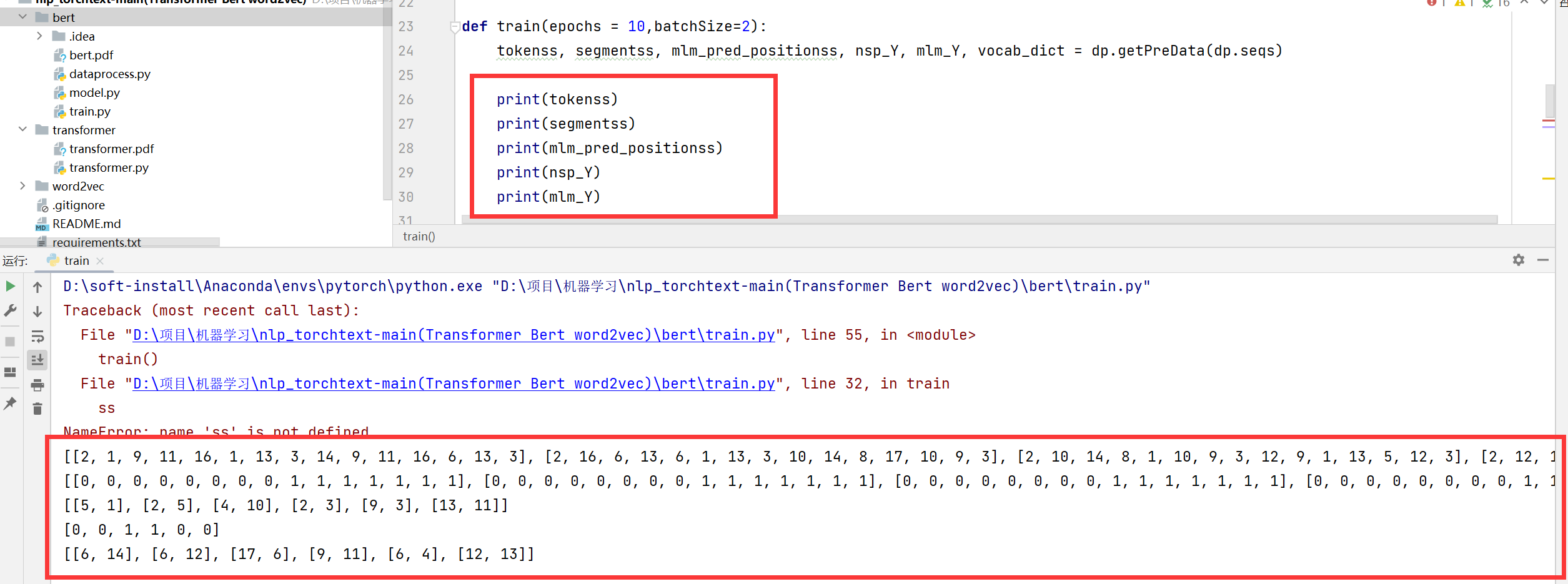
首先第一个是:tokenss。我们知道vacab_list=['<pad>', '<mask>', '<cls>', '<sep>'],所以这里的0就代表的是<pad>,1就代表这<mask>,2就代表这<cls>,3就代表这<sep>。
然后就是这个segmentss,这个就是前一个句子是0,后一个是1。
然后就是这个mlm_pred_positionss,这个就是每个句子需要预测的词的位置。
然后这个nsp_Y里面都是0和1,0代表这个不是下一个句子,1代表着是下一个句子。
然后就是mls_Y这个指的就是每个需要预测的词的答案。
微调(Fine-tune)
微调主要是指通过预训练得到的BERT Encoder网络接上各种各样的下游网络进行不同的任务。其实bret真正的作用就是训练出前面的那一块然后给后面做微调用。
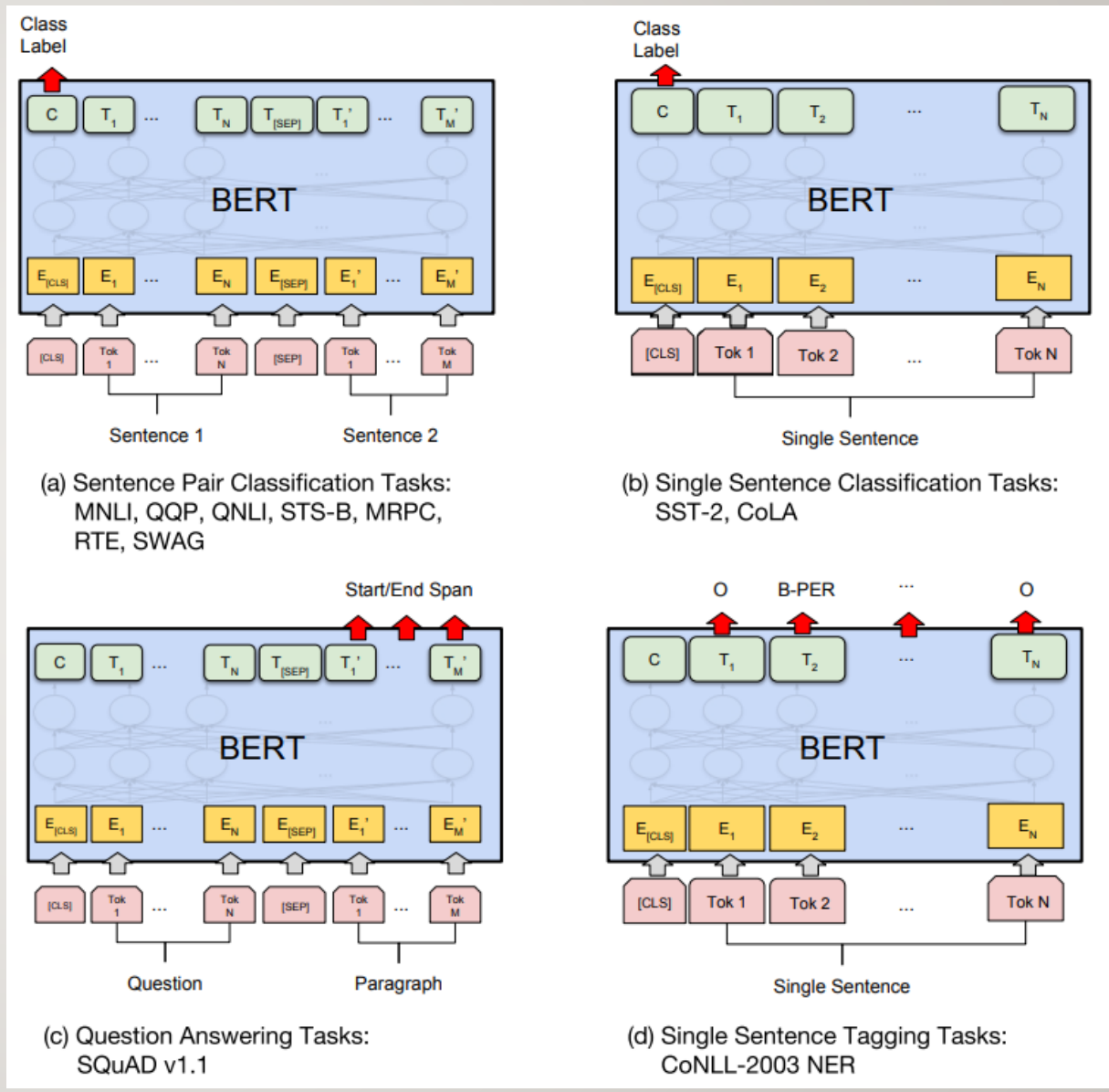
原论文中有4大类任务,如右图所示:
a) 句子对分类,将经过Encoder层编码后的<CLS>对应位置的向量输入进一个多分类的MLP网络中即可。
b) 单句分类,同上。
c) 根据问题得到答案,输入是一个问题与一段描述组成的句子对。将经过Encoder层编码后的每个词元对应位置的向量输入进3分类的MLP网络,而类别分别是Start(答案的首位),End(答案的末尾),Span(其他位置)。
d) 命名实体识别,将经过Encoder层编码后每个词元对应位置的向量输入进一个多分类的MLP网络中即可。
• 除原论文中给出的四大类任务,也可以结合实际场景设计更多的微调任务。
代码
dataprocess.py:
点击查看代码
import random
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
def getVocabs(data):
vacab_list=['<pad>', '<mask>', '<cls>', '<sep>']
vacab_set = set()
for ss in data:
for s in ss:
vacab_set|=set(s)
vacab_list.extend(list(vacab_set))
vacab_dict = {v:i for i,v in enumerate(vacab_list)}
return vacab_dict,vacab_set
def getTokensAndSegmentsSingle(tokens_a, tokens_b):
tokens = ['<cls>'] + tokens_a + ['<sep>']
segments = [0] * (len(tokens_a) + 2)
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments
def getTokensAndSegments(data):
tokens,segments = [],[]
for s in data:
token,seg = getTokensAndSegmentsSingle(*s)
tokens.append(token)
segments.append(seg)
return tokens,segments
def getParas(data):
paras = []
for d in data:
paras.append(d[0])
paras.append(d[1])
return paras
def getNspData(data):
paras = getParas(data)
nsp_data = []
nsp_Y = []
for d in data:
sentences = [d[0]]
if random.random() < 0.5:
sentences.append(d[1])
nsp_Y.append(1)
else:
sentences.append(random.choice(paras))
nsp_Y.append(0)
nsp_data.append(sentences)
return nsp_data,nsp_Y
def mapping(tokenss,mlm_true_wordss,vocab_dict):
n_tokenss,mlm_Y = [],[]
for tokens in tokenss:
n_tokenss.append([vocab_dict[token] for token in tokens])
for words in mlm_true_wordss:
mlm_Y.append([vocab_dict[word] for word in words])
return n_tokenss,mlm_Y
def maskMlmData(tokens,vocab_set):
num_pred = round(len(tokens) * 0.15) # 预测15%个随机词
mlm_true_words,mlm_pred_positions=[],[]
for i in range(num_pred):
while True: #如果要替换的位置是'<mask>', '<cls>', '<sep>',则继续选择
change_index = random.choice(range(len(tokens)))
if tokens[change_index] not in ['<mask>', '<cls>', '<sep>']:
break
mlm_pred_positions.append(change_index)
mlm_true_words.append(tokens[change_index])
if random.random() < 0.8: # 80%概率mask
tokens[change_index] = '<mask>'
else:
# 10%用随机词替换该词, 剩余10%保持不变
if random.random() < 0.5:
tokens[change_index] = random.choice(list(vocab_set))
return tokens,mlm_true_words,mlm_pred_positions
def getMlmData(tokenss,vocab_set):
n_tokenss,mlm_true_wordss, mlm_pred_positionss = [],[],[]
for tokens in tokenss:
tokens, mlm_true_words, mlm_pred_positions = maskMlmData(tokens,vocab_set)
n_tokenss.append(tokens)
mlm_true_wordss.append(mlm_true_words)
mlm_pred_positionss.append(mlm_pred_positions)
return n_tokenss,mlm_true_wordss, mlm_pred_positionss
def getPreData(data):
vocab_dict, vacab_set = getVocabs(seqs)
nsp_data, nsp_Y = getNspData(data) #生成nsp任务的文本数据
tokenss, segmentss = getTokensAndSegments(nsp_data) #生成bert encoder所需输入
tokenss, mlm_true_wordss, mlm_pred_positionss = getMlmData(tokenss,vacab_set) #生成mlm任务的文本数据
tokenss, mlm_Y = mapping(tokenss,mlm_true_wordss,vocab_dict) #映射成索引
return tokenss,segmentss,mlm_pred_positionss,nsp_Y,mlm_Y,vocab_dict
seqs = [[['i','b','c','d','e','f'],['a','m','c','f','j','g']],
[['d','e','f','e','a','f'],['a','b','c','d','e','d']],
[['h','i','j','k','h','b'],['a','b','e','f','g','a']],
[['a','b','c','d','e','f'],['a','b','c','e','m','g']],
[['b','l','n','e','f','h'],['e','e','m','d','j','f']],
[['b','g','d','m','f','g'],['e','e','c','d','e','f']]]
if __name__ == '__main__':
getPreData(seqs)
model.py
点击查看代码
from torch import nn
import torch
from torch.nn import functional as F
from transformer.transformer import EncoderLayer
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
class BERTEncoder(nn.Module):
def __init__(self, vocab_size, e_dim, h_dim, n_heads, n_layers, max_len=1024):
'''
:param vocab_size: 词汇数量
:param e_dim: 词向量维度
:param h_dim: Transformer编码层中间层的维度
:param n_heads: Transformer多头注意力的头数
:param n_layers: Transformer编码层的层数
:param max_len: 序列最长长度
'''
super(BERTEncoder, self).__init__()
self.token_embedding = nn.Embedding(vocab_size, e_dim)
self.segment_embedding = nn.Embedding(2, e_dim)
self.pos_embedding = nn.Parameter(torch.randn(1, max_len,e_dim))
self.encoder_layers = nn.ModuleList( [EncoderLayer( e_dim, h_dim, n_heads ) for _ in range( n_layers )] )
def forward(self, tokens, segments):
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X = X + self.pos_embedding.data[:, :X.shape[1], :]
for layer in self.encoder_layers:
X = layer(X)
return X
class MaskLM(nn.Module):
def __init__(self, vocab_size, h_dim, e_dim):
super(MaskLM, self).__init__()
self.mlp = nn.Sequential(nn.Linear(e_dim, h_dim),
nn.ReLU(),
nn.LayerNorm(h_dim),
nn.Linear(h_dim, vocab_size),
nn.Softmax())
def forward(self, X, pred_positions):
num_pred_positions = pred_positions.shape[1]
pred_positions = pred_positions.reshape(-1)
batch_size = X.shape[0]
batch_idx = torch.arange(0, batch_size)
batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions)
masked_X = X[batch_idx, pred_positions]
masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))
mlm_Y_hat = self.mlp(masked_X)
return mlm_Y_hat
class NextSentencePred(nn.Module):
def __init__(self, e_dim):
super(NextSentencePred, self).__init__()
self.outputs = nn.Linear(e_dim, 2)
def forward(self, X):
return F.softmax(self.outputs(X))
class BERTModel(nn.Module):
def __init__( self, vocab_size, e_dim, transformer_h_dim, mlm_h_dim, n_heads, n_layers, max_len = 1024 ):
'''
:param vocab_size: 词汇数量
:param e_dim: 词向量维度
:param transformer_h_dim: transformer中间隐藏层的维度
:param mlm_h_dim: mlm网络中间隐藏层维度
:param n_heads: Transformer多头注意力的头数
:param n_layers: Transformer编码层的层数
:param max_len: 序列最长长度
'''
super(BERTModel, self).__init__()
self.encoder = BERTEncoder(vocab_size, e_dim, transformer_h_dim, n_heads, n_layers, max_len=max_len)
self.mlm = MaskLM(vocab_size, mlm_h_dim, e_dim)
self.nsp = NextSentencePred(e_dim)
def forward(self, tokens, segments, pred_positions=None):
encoded_X = self.encoder(tokens, segments)
mlm_Y_hat = self.mlm(encoded_X, pred_positions)
nsp_Y_hat = self.nsp(encoded_X[:, 0, :])
return encoded_X, mlm_Y_hat, nsp_Y_hat
if __name__ == '__main__':
net = BERTModel(vocab_size=100, e_dim=768, transformer_h_dim=768, mlm_h_dim=768, n_heads=3, n_layers=12, max_len = 1024)
batch_size = 24
tokens = torch.randint(0,100,(batch_size,12))
segments = torch.cat([torch.zeros(batch_size,7,dtype=int),torch.ones(batch_size,5,dtype=int)],dim=1)
pred_positions = torch.randint(0,12,(batch_size,3))
encoded_X, mlm_Y_hat, nsp_Y_hat = net(tokens,segments,pred_positions)
print(encoded_X.shape)
print(mlm_Y_hat.shape)
print(nsp_Y_hat.shape)
train.py:
点击查看代码
from bert import model
from bert import dataprocess as dp
import torch
from torch.utils.data import DataLoader
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
class Dataset(torch.utils.data.Dataset):
def __init__(self,tokenss, segmentss, mlm_pred_positionss, nsp_Y, mlm_Y):
self.tokenss = torch.LongTensor(tokenss)
self.segmentss = torch.LongTensor(segmentss)
self.mlm_pred_positionss= torch.LongTensor(mlm_pred_positionss)
self.nsp_Y = torch.LongTensor(nsp_Y)
self.mlm_Y = torch.LongTensor(mlm_Y)
def __getitem__(self, idx):
return (self.tokenss[idx], self.segmentss[idx],
self.mlm_pred_positionss[idx], self.nsp_Y[idx],
self.mlm_Y[idx])
def __len__(self):
return len(self.tokenss)
def train(epochs = 10,batchSize=2):
tokenss, segmentss, mlm_pred_positionss, nsp_Y, mlm_Y, vocab_dict = dp.getPreData(dp.seqs)
dataSet = Dataset(tokenss, segmentss, mlm_pred_positionss, nsp_Y, mlm_Y)
net = model.BERTModel(vocab_size=len(vocab_dict), e_dim=32, transformer_h_dim=32,
mlm_h_dim=32, n_heads=3, n_layers=12, max_len=128)
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
criterion = torch.nn.CrossEntropyLoss()
for e in range(epochs):
for tokenss, segmentss, mlm_pred_positionss, nsp_Y, mlm_Y in DataLoader(dataSet, batch_size=batchSize, shuffle=True):
optimizer.zero_grad()
encoded_X, mlm_Y_hat, nsp_Y_hat = net(tokenss, segmentss, mlm_pred_positionss)
mlm_Y_hat = mlm_Y_hat.reshape(-1,len(vocab_dict))
mlm_Y = mlm_Y.reshape(-1)
mlm_loss = criterion(mlm_Y_hat,mlm_Y)
nsp_loss = criterion(nsp_Y_hat,nsp_Y)
loss = mlm_loss + nsp_loss
loss.backward()
optimizer.step()
print('epoch {}, loss = {:.4f}'.format(e,loss))
if __name__ == '__main__':
'''
该示例代码未考虑padding,如要考虑padding则用<pad>填充,并记录valid_lens(实际长度)方便并行计算。
'''
train()
transformer.py:
点击查看代码
import torch
from torch import nn
from torch.autograd import Variable
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
#多头注意力层
class MultiHeadAttentionLayer( nn.Module ):
def __init__( self, e_dim, h_dim, n_heads ):
'''
:param e_dim: 输入的向量维度
:param h_dim: 每个单头注意力层输出的向量维度
:param n_heads: 头数
'''
super().__init__()
self.atte_layers = nn.ModuleList([ OneHeadAttention( e_dim, h_dim ) for _ in range( n_heads ) ] )
self.l = nn.Linear( h_dim * n_heads, e_dim)
def forward( self, seq_inputs, querys = None, mask = None ):
outs = []
for one in self.atte_layers:
out = one( seq_inputs, querys, mask )
outs.append( out )
# [ batch, seq_lens, h_dim * n_heads ]
outs = torch.cat( outs, dim=-1 )
# [ batch, seq_lens, e_dim ]
outs = self.l( outs )
return outs
#单头注意力层
class OneHeadAttention( nn.Module ):
def __init__( self, e_dim, h_dim ):
'''
:param e_dim: 输入向量维度
:param h_dim: 输出向量维度
'''
super().__init__()
self.h_dim = h_dim
# 初始化Q,K,V的映射线性层
self.lQ = nn.Linear( e_dim, h_dim )
self.lK = nn.Linear( e_dim, h_dim )
self.lV = nn.Linear( e_dim, h_dim )
def forward( self, seq_inputs , querys = None, mask = None ):
'''
:param seq_inputs: #[ batch, seq_lens, e_dim ]
:param querys: #[ batch, seq_lens, e_dim ]
:param mask: #[ 1, seq_lens, seq_lens ]
:return:
'''
# 如果有encoder的输出, 则映射该张量,否则还是就是自注意力的逻辑
if querys is not None:
Q = self.lQ( querys ) #[ batch, seq_lens, h_dim ]
else:
Q = self.lQ( seq_inputs ) #[ batch, seq_lens, h_dim ]
K = self.lK( seq_inputs ) #[ batch, seq_lens, h_dim ]
V = self.lV( seq_inputs ) #[ batch, seq_lens, h_dim ]
# [ batch, seq_lens, seq_lens ]
QK = torch.matmul( Q,K.permute( 0, 2, 1 ) )
# [ batch, seq_lens, seq_lens ]
QK /= ( self.h_dim ** 0.5 )
# 将对应Mask序列中0的位置变为-1e9,意为遮盖掉此处的值
if mask is not None:
QK = QK.masked_fill( mask == 0, -1e9 )
# [ batch, seq_lens, seq_lens ]
a = torch.softmax( QK, dim = -1 )
# [ batch, seq_lens, h_dim ]
outs = torch.matmul( a, V )
return outs
#前馈神经网络
class FeedForward(nn.Module):
def __init__( self, e_dim, ff_dim, drop_rate = 0.1 ):
super().__init__()
self.l1 = nn.Linear( e_dim, ff_dim )
self.l2 = nn.Linear( ff_dim, e_dim )
self.drop_out = nn.Dropout( drop_rate )
def forward( self, x ):
outs = self.l1( x )
outs = self.l2( self.drop_out( torch.relu( outs ) ) )
return outs
#位置编码
class PositionalEncoding( nn.Module ):
def __init__( self, e_dim, dropout = 0.1, max_len = 512 ):
super().__init__()
self.dropout = nn.Dropout( p = dropout )
pe = torch.zeros( max_len, e_dim )
position = torch.arange( 0, max_len ).unsqueeze( 1 )
div_term = 10000.0 ** ( torch.arange( 0, e_dim, 2 ) / e_dim )
#偶数位计算sin, 奇数位计算cos
pe[ :, 0::2 ] = torch.sin( position / div_term )
pe[ :, 1::2 ] = torch.cos( position / div_term )
pe = pe.unsqueeze(0)
self.pe = pe
def forward( self, x ):
x = x + Variable( self.pe[:, : x.size( 1 ) ], requires_grad = False )
return self.dropout( x )
#编码层
class EncoderLayer(nn.Module):
def __init__( self, e_dim, h_dim, n_heads, drop_rate = 0.1 ):
'''
:param e_dim: 输入向量的维度
:param h_dim: 注意力层中间隐含层的维度
:param n_heads: 多头注意力的头目数量
:param drop_rate: drop out的比例
'''
super().__init__()
# 初始化多头注意力层
self.attention = MultiHeadAttentionLayer( e_dim, h_dim, n_heads )
# 初始化注意力层之后的LN
self.a_LN = nn.LayerNorm( e_dim )
# 初始化前馈神经网络层
self.ff_layer = FeedForward( e_dim, e_dim//2 )
# 初始化前馈网络之后的LN
self.ff_LN = nn.LayerNorm( e_dim )
self.drop_out = nn.Dropout( drop_rate )
def forward(self, seq_inputs ):
# seq_inputs = [batch, seqs_len, e_dim]
# 多头注意力, 输出维度[ batch, seq_lens, e_dim ]
outs_ = self.attention( seq_inputs )
# 残差连接与LN, 输出维度[ batch, seq_lens, e_dim ]
outs = self.a_LN( seq_inputs + self.drop_out( outs_ ) )
# 前馈神经网络, 输出维度[ batch, seq_lens, e_dim ]
outs_ = self.ff_layer( outs )
# 残差与LN, 输出维度[ batch, seq_lens, e_dim ]
outs = self.ff_LN( outs + self.drop_out( outs_) )
return outs
class TransformerEncoder(nn.Module):
def __init__(self, e_dim, h_dim, n_heads, n_layers, drop_rate = 0.1 ):
'''
:param e_dim: 输入向量的维度
:param h_dim: 注意力层中间隐含层的维度
:param n_heads: 多头注意力的头目数量
:param n_layers: 编码层的数量
:param drop_rate: drop out的比例
'''
super().__init__()
#初始化位置编码层
self.position_encoding = PositionalEncoding( e_dim )
#初始化N个“编码层”
self.encoder_layers = nn.ModuleList( [EncoderLayer( e_dim, h_dim, n_heads, drop_rate )
for _ in range( n_layers )] )
def forward( self, seq_inputs ):
'''
:param seq_inputs: 已经经过Embedding层的张量,维度是[ batch, seq_lens, dim ]
:return: 与输入张量维度一样的张量,维度是[ batch, seq_lens, dim ]
'''
#先进行位置编码
seq_inputs = self.position_encoding( seq_inputs )
#输入进N个“编码层”中开始传播
for layer in self.encoder_layers:
seq_inputs = layer( seq_inputs )
return seq_inputs
#生成mask序列
def subsequent_mask( size ):
subsequent_mask = torch.triu( torch.ones( (1, size, size) ) ) == 0
return subsequent_mask
#解码层
class DecoderLayer(nn.Module):
def __init__( self, e_dim, h_dim, n_heads, drop_rate = 0.1 ):
'''
:param e_dim: 输入向量的维度
:param h_dim: 注意力层中间隐含层的维度
:param n_heads: 多头注意力的头目数量
:param drop_rate: drop out的比例
'''
super().__init__()
# 初始化自注意力层
self.self_attention = MultiHeadAttentionLayer( e_dim, h_dim, n_heads )
# 初始化自注意力层之后的LN
self.sa_LN = nn.LayerNorm( e_dim )
# 初始化交互注意力层
self.interactive_attention = MultiHeadAttentionLayer( e_dim, h_dim, n_heads )
# 初始化交互注意力层之后的LN
self.ia_LN = nn.LayerNorm (e_dim )
# 初始化前馈神经网络层
self.ff_layer = FeedForward( e_dim, e_dim//2 )
# 初始化前馈网络之后的LN
self.ff_LN = nn.LayerNorm( e_dim )
self.drop_out = nn.Dropout( drop_rate )
def forward( self, seq_inputs , querys, mask ):
'''
:param seq_inputs: [ batch, seqs_len, e_dim ]
:param querys: encoder的输出
:param mask: 遮盖位置的标注序列 [ 1, seqs_len, seqs_len ]
'''
# 自注意力层, 输出维度[ batch, seq_lens, e_dim ]
outs_ = self.self_attention( seq_inputs , mask=mask )
# 残差连与LN, 输出维度[ batch, seq_lens, e_dim ]
outs = self.sa_LN( seq_inputs + self.drop_out( outs_ ) )
# 交互注意力层, 输出维度[ batch, seq_lens, e_dim ]
outs_ = self.interactive_attention( outs, querys )
# 残差连与LN, 输出维度[ batch, seq_lens, e_dim
outs = self.ia_LN( outs + self.drop_out(outs_) )
# 前馈神经网络, 输出维度[ batch, seq_lens, e_dim ]
outs_ = self.ff_layer( outs )
# 残差与LN, 输出维度[ batch, seq_lens, e_dim ]
outs = self.ff_LN( outs + self.drop_out( outs_) )
return outs
class TransformerDecoder(nn.Module):
def __init__(self, e_dim, h_dim, n_heads, n_layers, n_classes,drop_rate = 0.1 ):
'''
:param e_dim: 输入向量的维度
:param h_dim: 注意力层中间隐含层的维度
:param n_heads: 多头注意力的头目数量
:param n_layers: 解码层的数量
:param n_classes: 类别数
:param drop_rate: drop out的比例
'''
super().__init__()
# 初始化位置编码层
self.position_encoding = PositionalEncoding( e_dim )
# 初始化N个“解码层”
self.decoder_layers = nn.ModuleList( [DecoderLayer( e_dim, h_dim, n_heads, drop_rate )
for _ in range( n_layers )] )
# 线性层
self.linear = nn.Linear(e_dim,n_classes)
# softmax激活函数
self.softmax = nn.Softmax()
def forward( self, seq_inputs, querys ):
'''
:param seq_inputs: 已经经过Embedding层的张量,维度是[ batch, seq_lens, dim ]
:param querys: encoder的输出,维度是[ batch, seq_lens, dim ]
:return: 与输入张量维度一样的张量,维度是[ batch, seq_lens, dim ]
'''
# 先进行位置编码
seq_inputs = self.position_encoding( seq_inputs )
# 得到mask序列
mask = subsequent_mask( seq_inputs.shape[1] )
# 输入进N个“解码层”中开始传播
for layer in self.decoder_layers:
seq_inputs = layer( seq_inputs, querys, mask )
# 最终线性变化后Softmax归一化
seq_outputs = self.softmax(self.linear(seq_inputs))
return seq_outputs
class Transformer(nn.Module):
def __init__(self,e_dim, h_dim, n_heads, n_layers, n_classes,drop_rate=0.1):
super().__init__()
self.encoder = TransformerEncoder(e_dim, h_dim, n_heads, n_layers, drop_rate)
self.decoder = TransformerDecoder(e_dim, h_dim, n_heads, n_layers, n_classes,drop_rate)
def forward(self,input,output):
querys = self.encoder(input)
pred_seqs = self.decoder(output,querys)
return pred_seqs
if __name__ == '__main__':
input = torch.randn( 5, 3, 12 )
net = Transformer(12, 8, 3, 6, 20)
output = torch.randn( 5, 3, 12)
pred_seqs = net(input,output)
print(pred_seqs.shape)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号