Attention、Self-Attention与Mutil-Head Attention的区别以及位置编码的作用
1.Attention
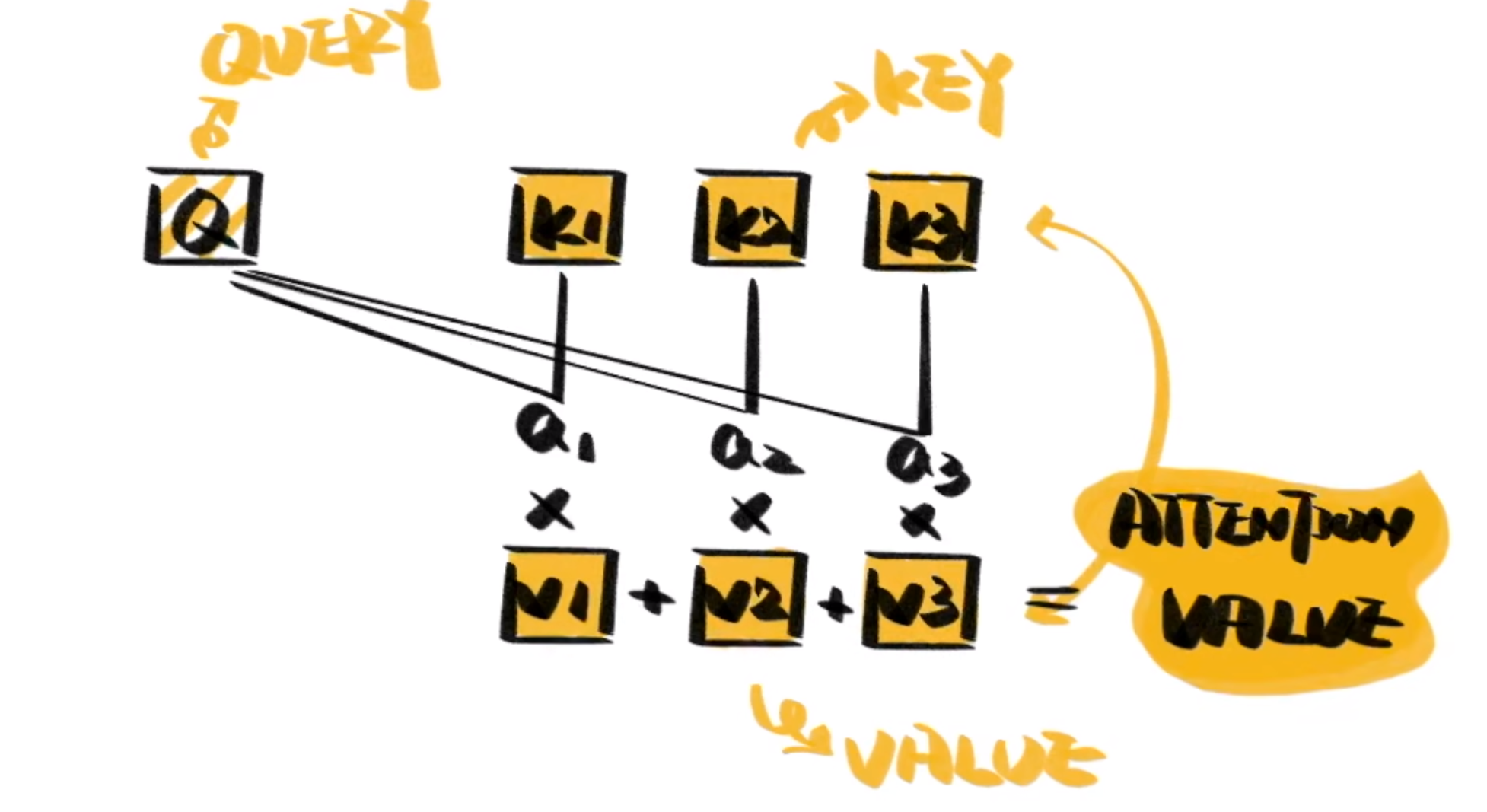
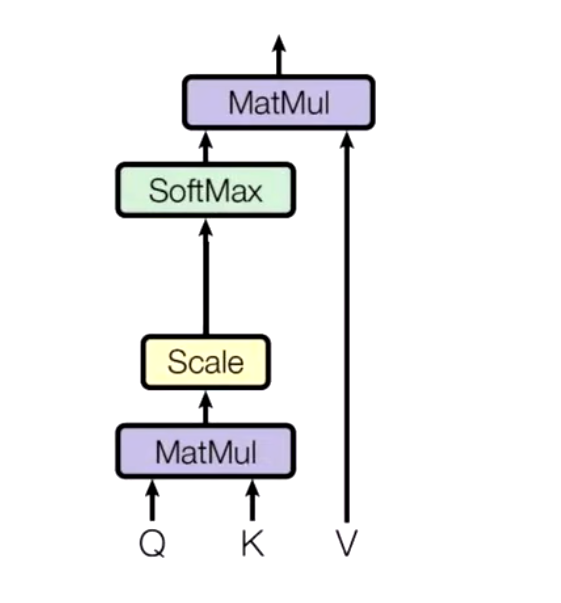
Attention可以从纷繁复杂的输入信息中,找出对当前输出最重要的部分。一个典型的Attention包括三部分\(Q,K,V\)。

\(Q\)是Query,是输入的信息。\(key\)和\(value\)成对出现,通常是源语言、原始文本等已有的信息。通过计算\(Q\)和\(K\)之间的相关性,得出不同的K对输出的重要程度。在于对应的V相乘求和就得到了\(Q\)的输出。
以阅读理解为例:\(Q\)可以看成问题,\(K\)和\(V\)是原始文本,计算与\(K\)的相关性,让我们找到文本中最需要注意的地方,利用\(V\)得到答案。
注意力机制是一个很宽泛(宏大)的一个概念,\(Q,K,V\)相乘就是注意力,但是他没有规定\(Q,K,V\)是怎么来的,通过一个查询变量\(Q\),去找到\(V\)里面比较重要的东西假设\(K==V\),然后\(Q,K\)相乘求相似度\(A\),然后\(A,V\)相乘得到注意力值\(Z\),这个\(Z\)就是\(V\)的另外一种形式的表示
\(Q\)可以是任何一个东西,\(V\)也是任何一个东西,\(K\)往往是等同于\(V\)的(同源)。
2.Self-Attention
Self-Attention只关注输入序列元素之间的关系,通过将输入序列直接转化为\(Q、K、V\)。对于self-attention,并不是\(Q=K=V\),而是\(Q,K,V\)都是根据\(X\)通过线性变化得到的,Self-Attention中的Self指的是\(Q,K,V\)同源。
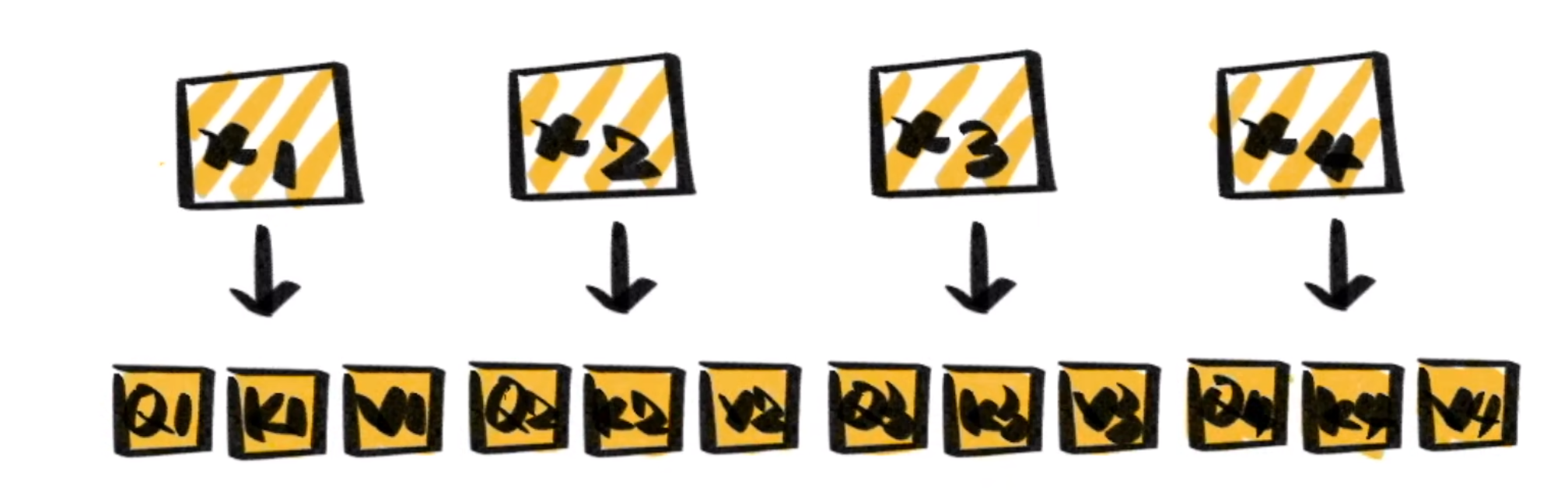
并在内部进行Attention计算,能很好的捕捉文本的内在联系,然后对其做出在表示。
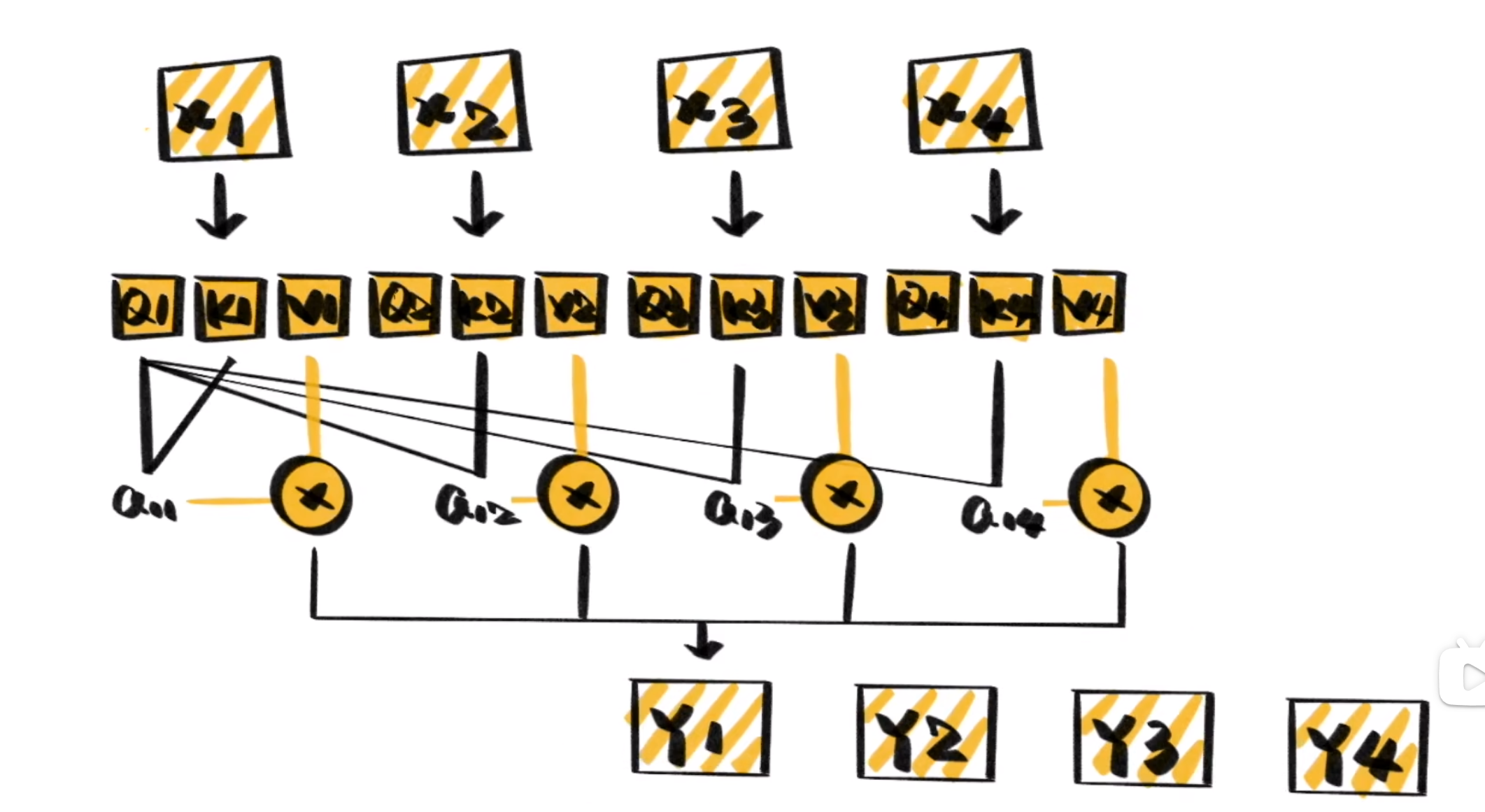
给定一个\(X\),通过自注意力模型,得到一个\(Z\),这个\(Z\)就是对\(X\)的新的表征(词向量),\(Z\)这个词向量相比较\(X\)拥有了句法特征和语义特征。
3.Multi-Head Attention
\(Z\)相比较\(X\)有了提升,通过Multi-Head Self-Attention,得到的\(Z'\)相比较\(Z\)又有了进一步提升。
多头自注意力,问题来了,多头是什么,多头的个数用h表示,一般\(h=8\),我们通常使用的是8头自注意力。
-
对于X,我们不是说,直接拿\(X\)去得到\(Z\),而是把\(X\)分成了8块(8头),得到\(Z_0-Z_7\)
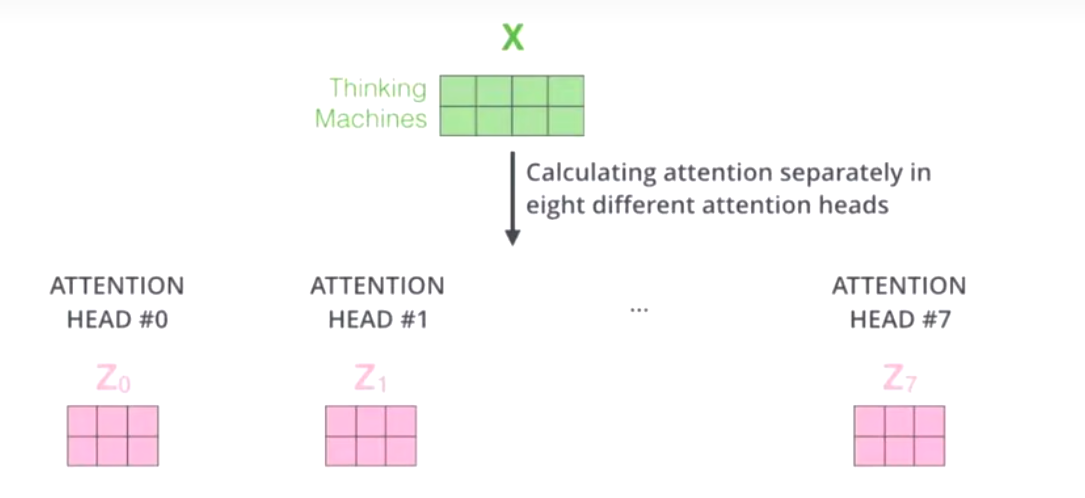
-
然后把\(Z_0-Z_7\)拼接起来,再做一次线性变换(改变维度)得到\(Z\)。

有什么作用?
机器学习的本质是什么?
\(y=\sigma (wx+b)\),在做一件什么事情,非线性变换(把一个看起来不合理的东西,通过某个手段(训练模型),让这个东西变得合理,就是我们通过某种非线性变化用\(y\)来代替这个\(x\)。
非线性变换的本质又是什么?
改变空间上的位置坐标,任何一个点都可以在维度空间上找到,通过某个手段,让一个不合理的点(位置不合理),变得合理。这就是词向量的本质,比如说:不合理的one-hot编码。
one-hot编码:(0101010)
word2vec:(11,222,33)
emlo:(15,3,2)
attention:(124,2,32)
multi-head attention:(1231,23,3),把\(X\)切分成8块,这样一个原先在一个位置上的\(X\),去了空间上8个位置,通过对8个点进行寻找,找到更合适的位置.
多头注意力的流程
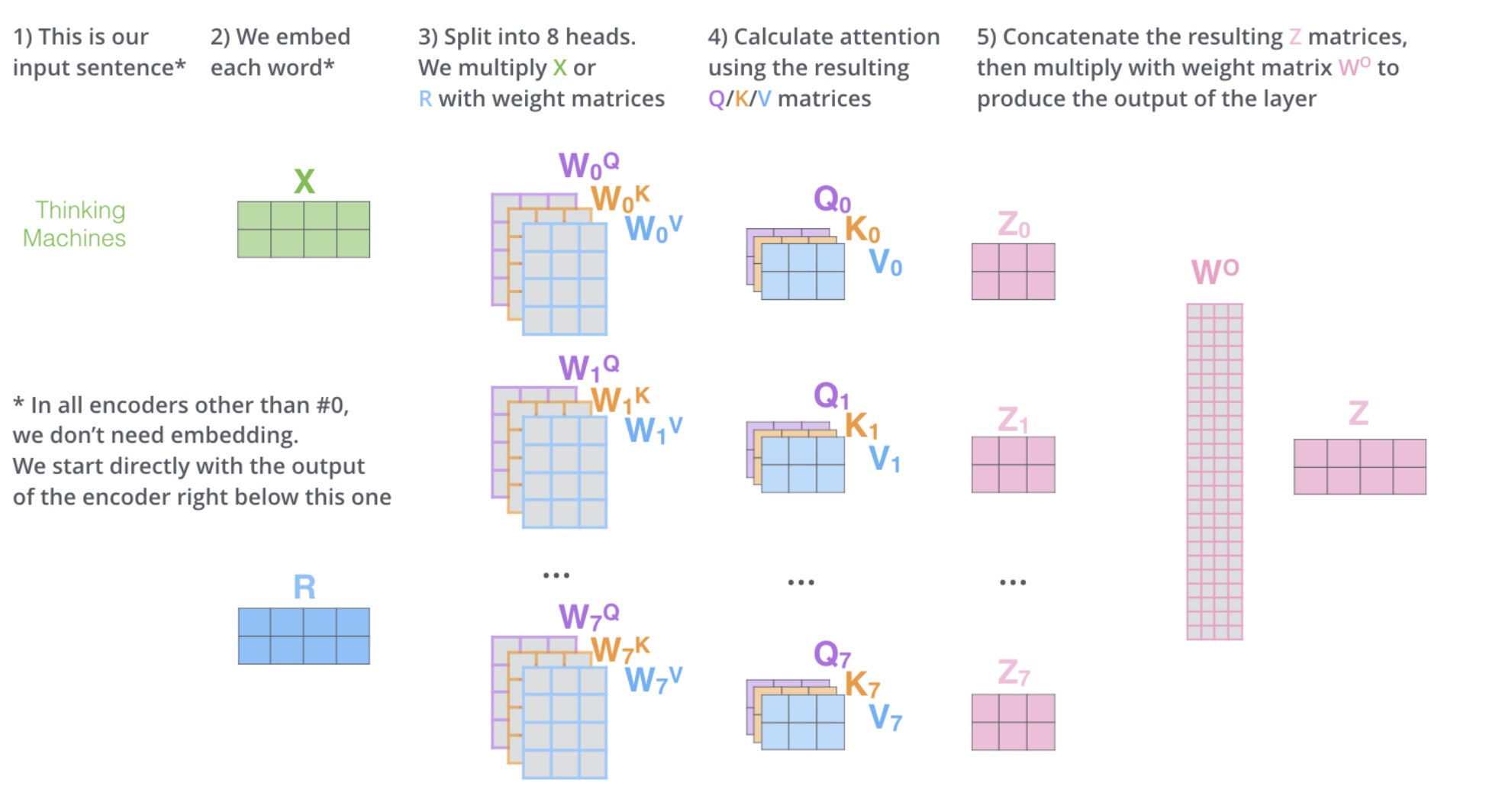
上述操作有什么好处呢?多头相当于把原始信息 Source 放入了多个子空间中,也就是捕捉了多个信息,对于使用 multi-head(多头) attention 的简单回答就是,多头保证了 attention 可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。其实本质上是论文原作者发现这样效果确实好。
则是在自注意力机制的基础上。使用多种变换生成的\(Q,K,V\)进行计算。
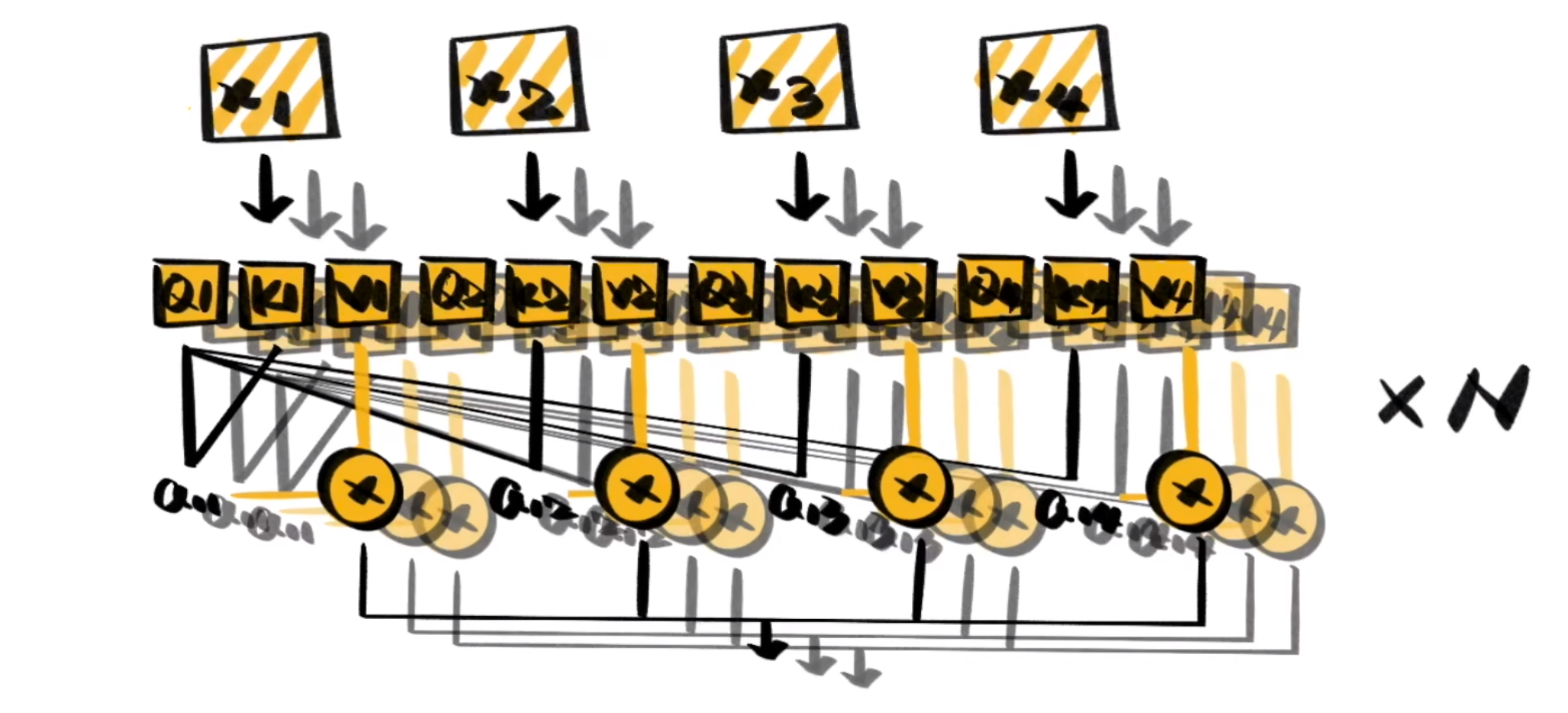
再将它们对相关性的结论综合起来,进—步增强Self-Attention的效果。

Masked Self-Attention
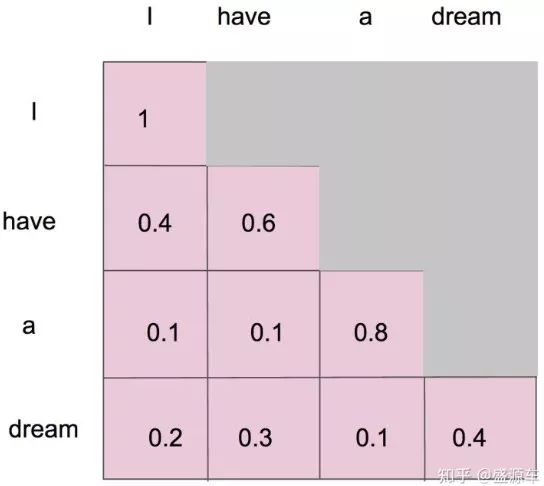
当我们做生成任务的时候,我们也想对生成的这个单词做注意力计算,但是,生成的句子是一个一个单词生成的。
比如说我们要生成"I have a dream."
1.生成成"I"。
2.我们将"I"当成输入,生成"have"。
3.我们将"I have"当成输入,生成"a"。
4.我们将"I have a"当成输入,生成"dream"。
5.我们将"I have a dream"当成输入,生成结束符"<eos>"。
为什么需要掩码呢?
我们发现我第一次注意力计算的时候,只有"I",剩下的没有。掩码自注意力机制应运而生
掩码后 1
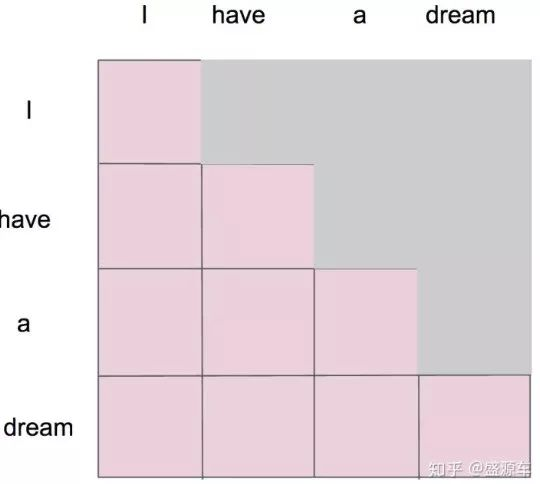
掩码后2
位置编码
对于我们之前提到的Attention,解决了长序列依赖问题,可以并行,但是缺点确实开销变大了。还有一个缺点就是,既然可以并行,也就是说,词与词之间不存在顺序关系。也就是说我们每一个词就是和其他词单独进行计算的,即使这个词的位置变了,一个词也是和每一个词计算,打乱一句话,这句话中的每个词的词向量依然不会变。既然无位置关系,我们就加一个,通过位置编码的形式加。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号