nn.Embedding
nn.Embedding(vocab_size, embed_size)
vocab_size:表示一共有多少个字需要embedding,这里注意这个vocab_size的数量可以看成最后又多少类,也就是又多少个词,就又多少类
embed_size:表示我们希望一个字向量的维度是多少
它其实和one-hat的效果差不多
例如:当整个输入数据X只有一句话时
X(1, max_length, num_embeddings)
字典为(num_embeddings, embedding_dim)
则经过翻译之后,这句话变成(1,max_length,embedding_dim)
当输入数据X有多句话时,即Batch_size不等于1,有
X(batch_size, max_length, num_embeddings)
字典为(num_embeddings, embedding_dim)
则经过翻译之后,输入数据X变成(batch_size,max_length,embedding_dim)
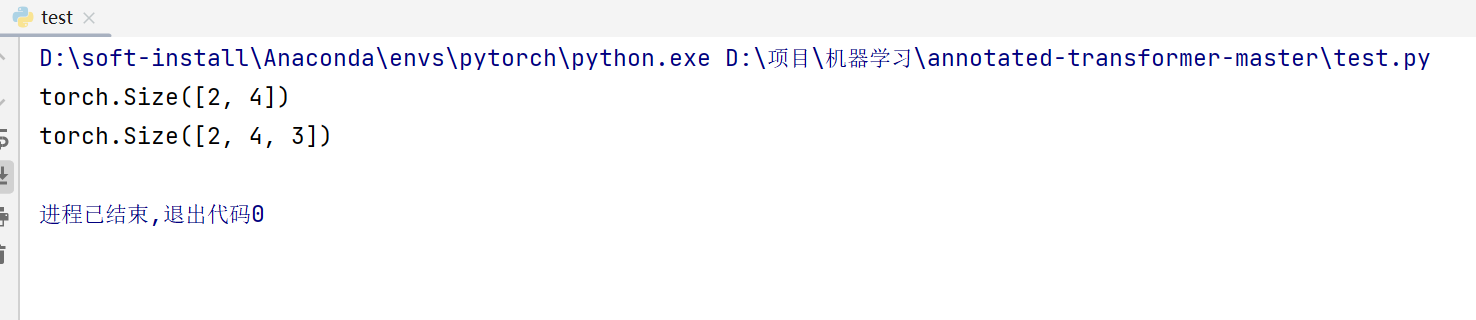
例如:
embedding = nn.Embedding(10, 3)
input = torch.LongTensor([[1,2,4,5],[4,3,2,9]])
print(input.shape)
print(embedding(input).shape)
这里就是每个词,一共有10个词[0-9],这里再实际操作中通常弄的大一点,然后每个词都用3个数字进行表示,所以输出为[2,4,3]。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号