TensorFlow11.5 循环神经网络RNN-LSTM、LSTM实战
LSTM的产生
我们之前在求RNN的loss的时候很容易出现梯度弥散或者梯度爆炸。这个LSTM的出现很大程度上减少了梯度弥散的情况。
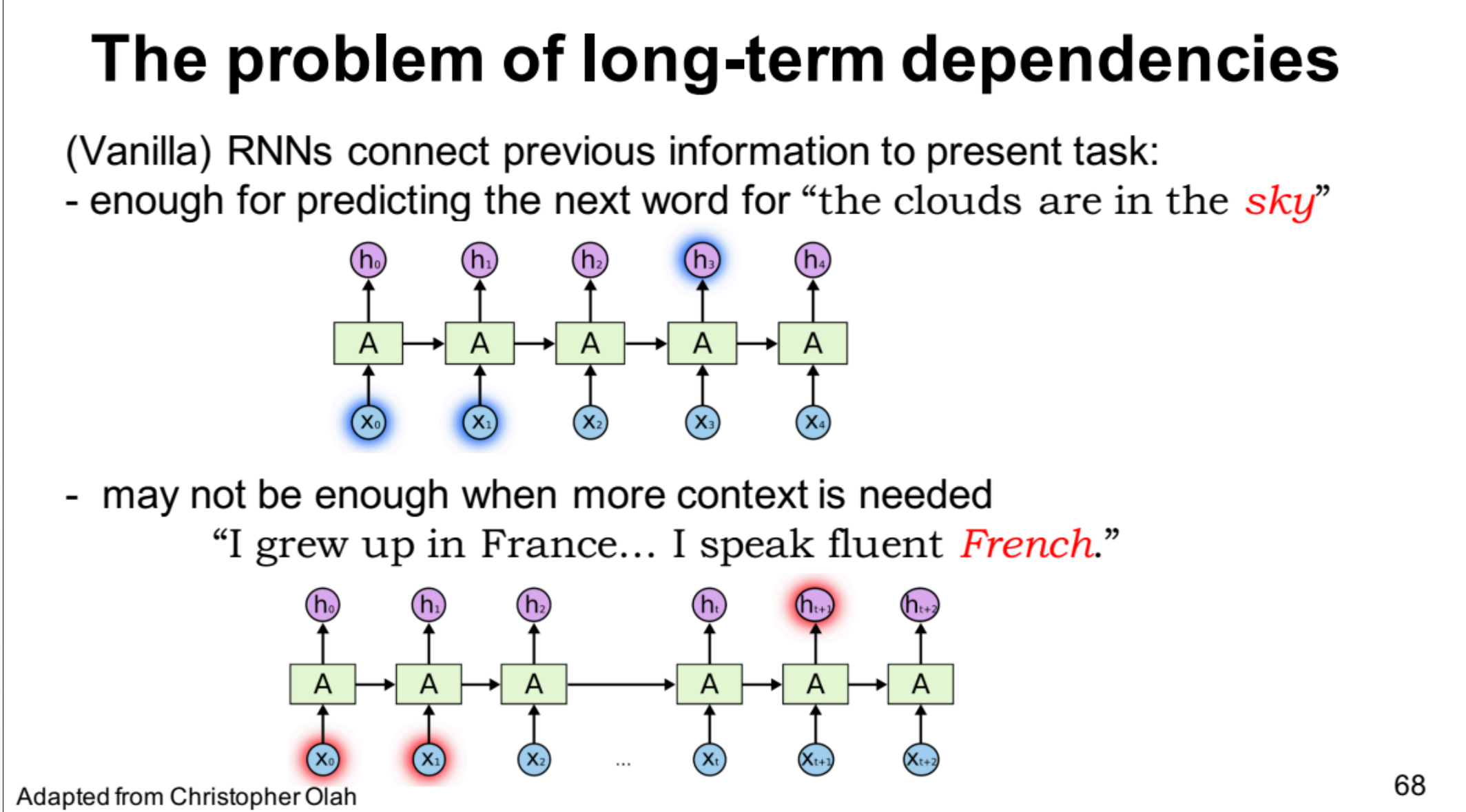
还有一个很重要的就是RNN只能够记住一个比较短的序列,如果一个句子单词很多的话,它学到最后一个的时候可能它的前面的就忘记了。而这个LSTM能够改善这问题它能够学习一个比较长的序列。之前RNN是short-term-memory 加上这个long,就是long-short-term-memory就是这个LSTM。
之前的RNN:
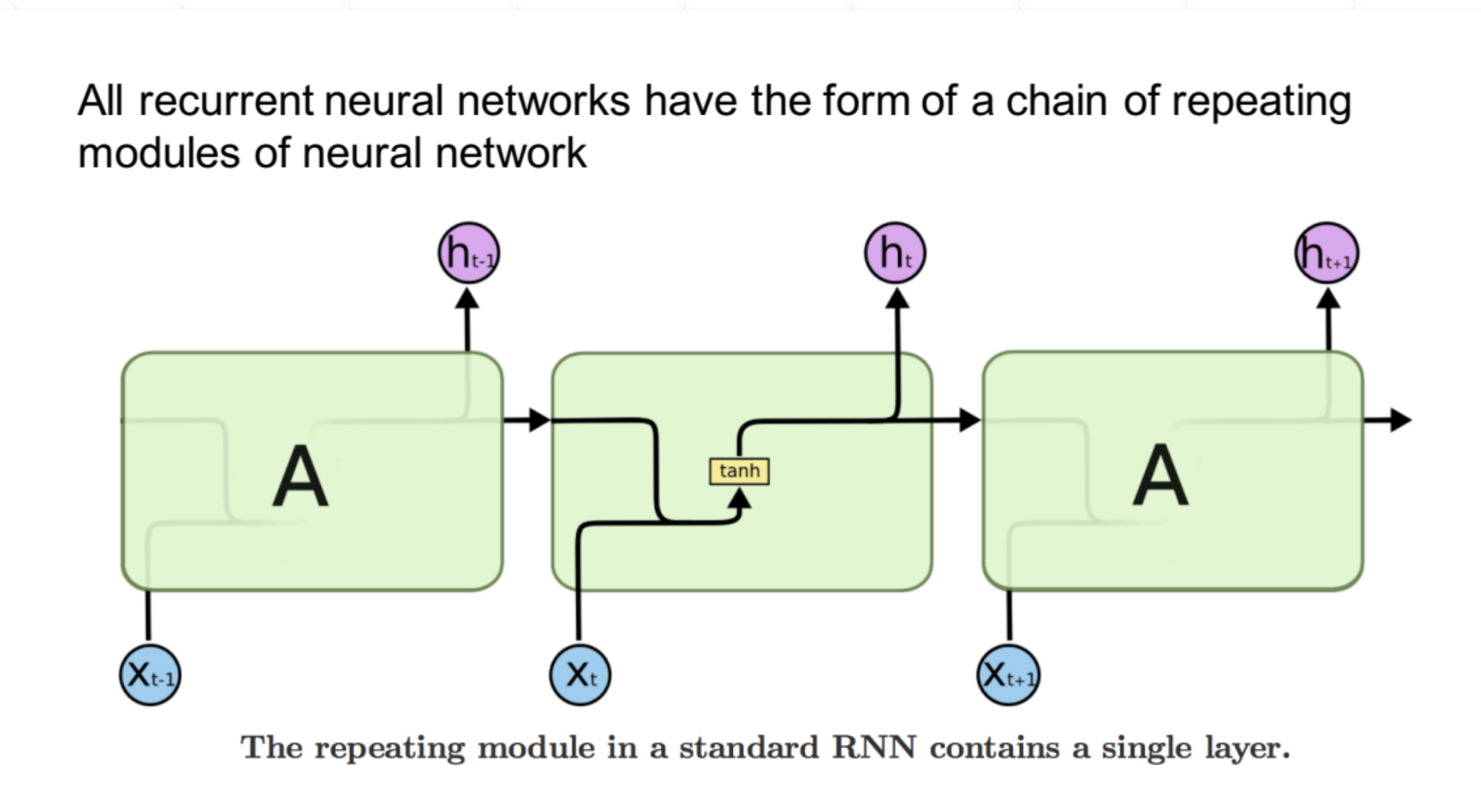
我们在时间这个维度上展开就是这样的。
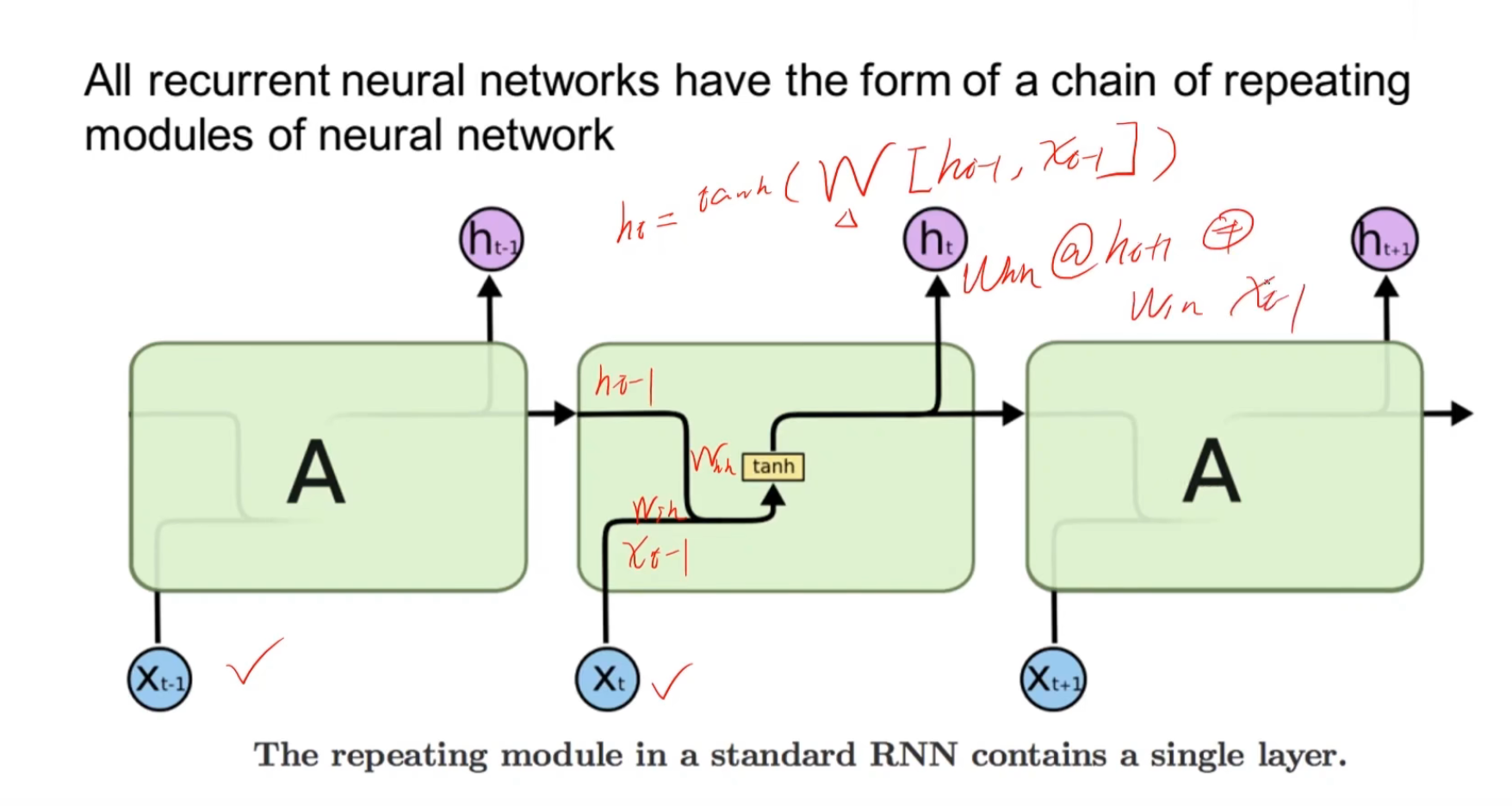
LSTM原理
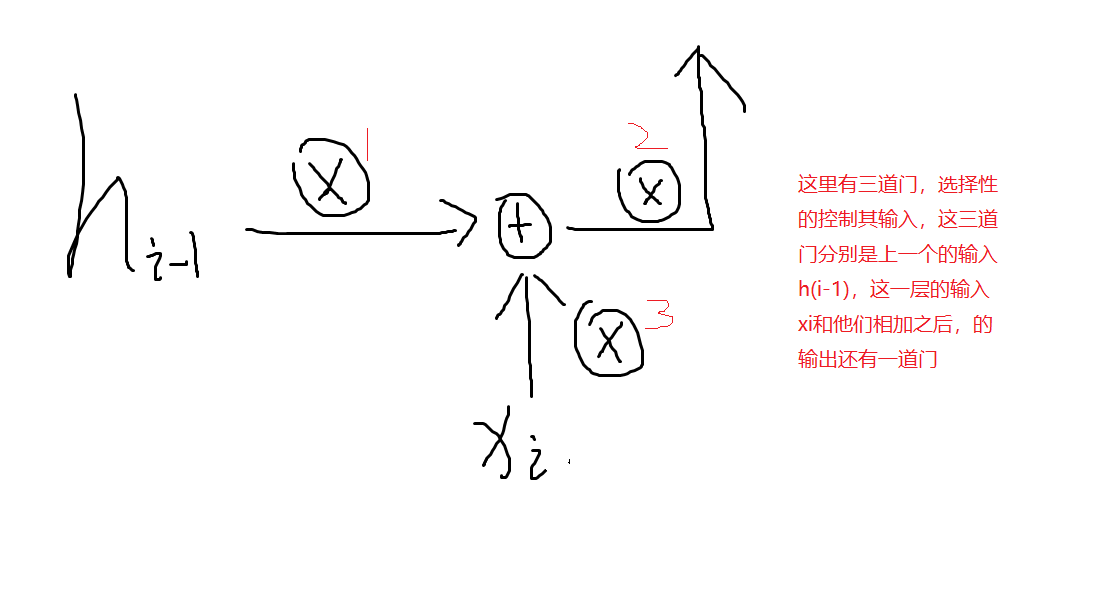
这个门只是一个比喻。
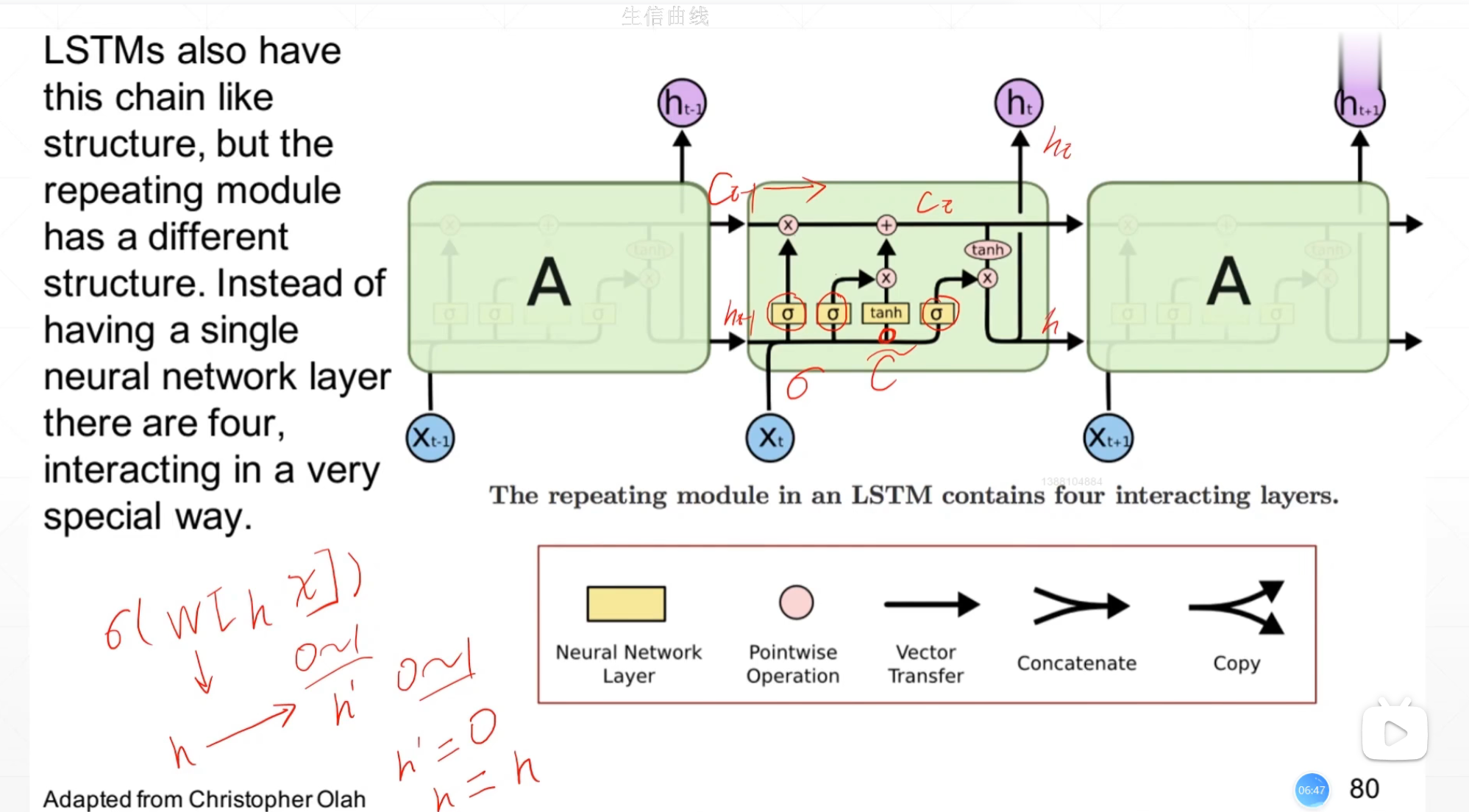 :
:
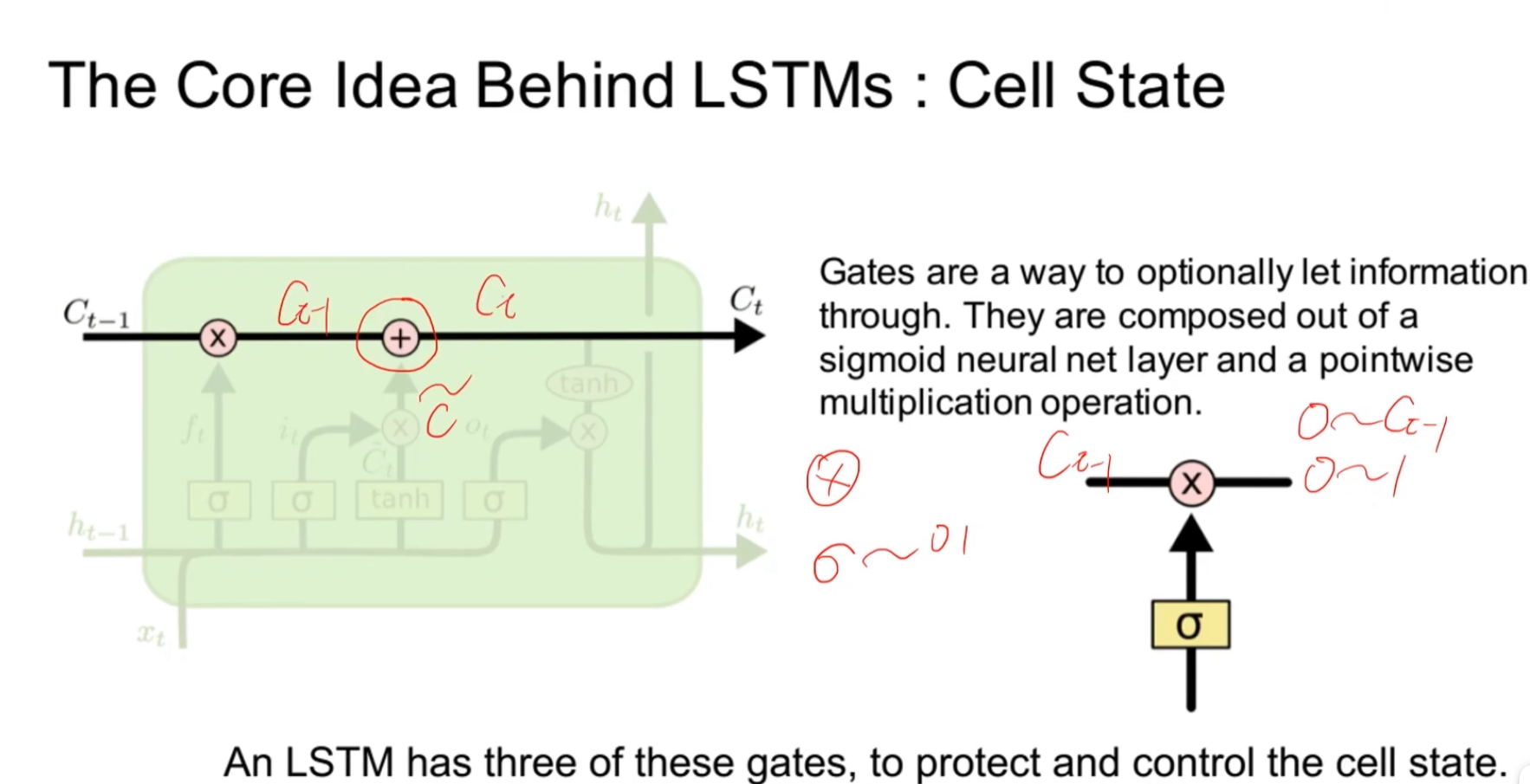
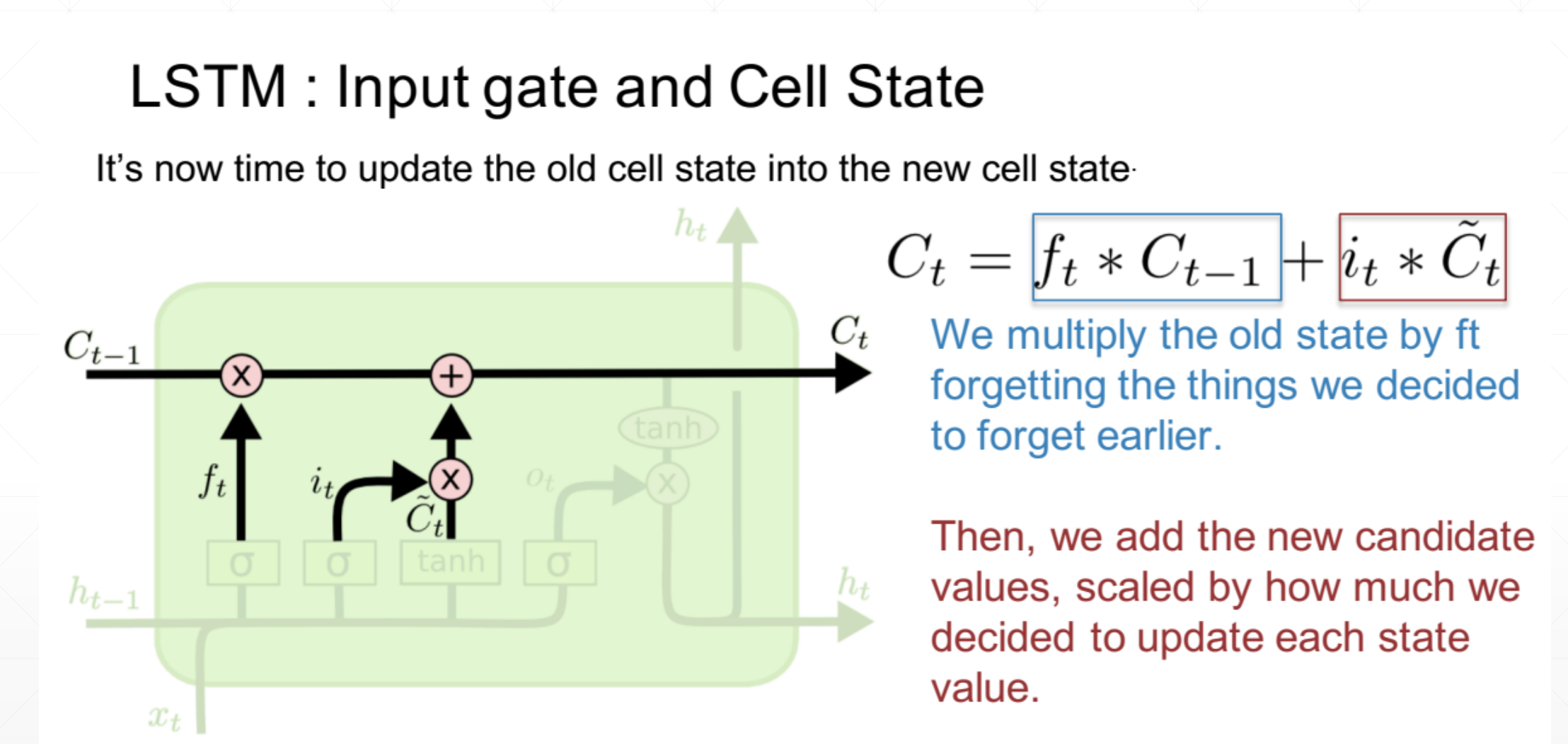
这里相乘的符号就是一个信息的过滤,然后相加的符号就是一个信息的融合。
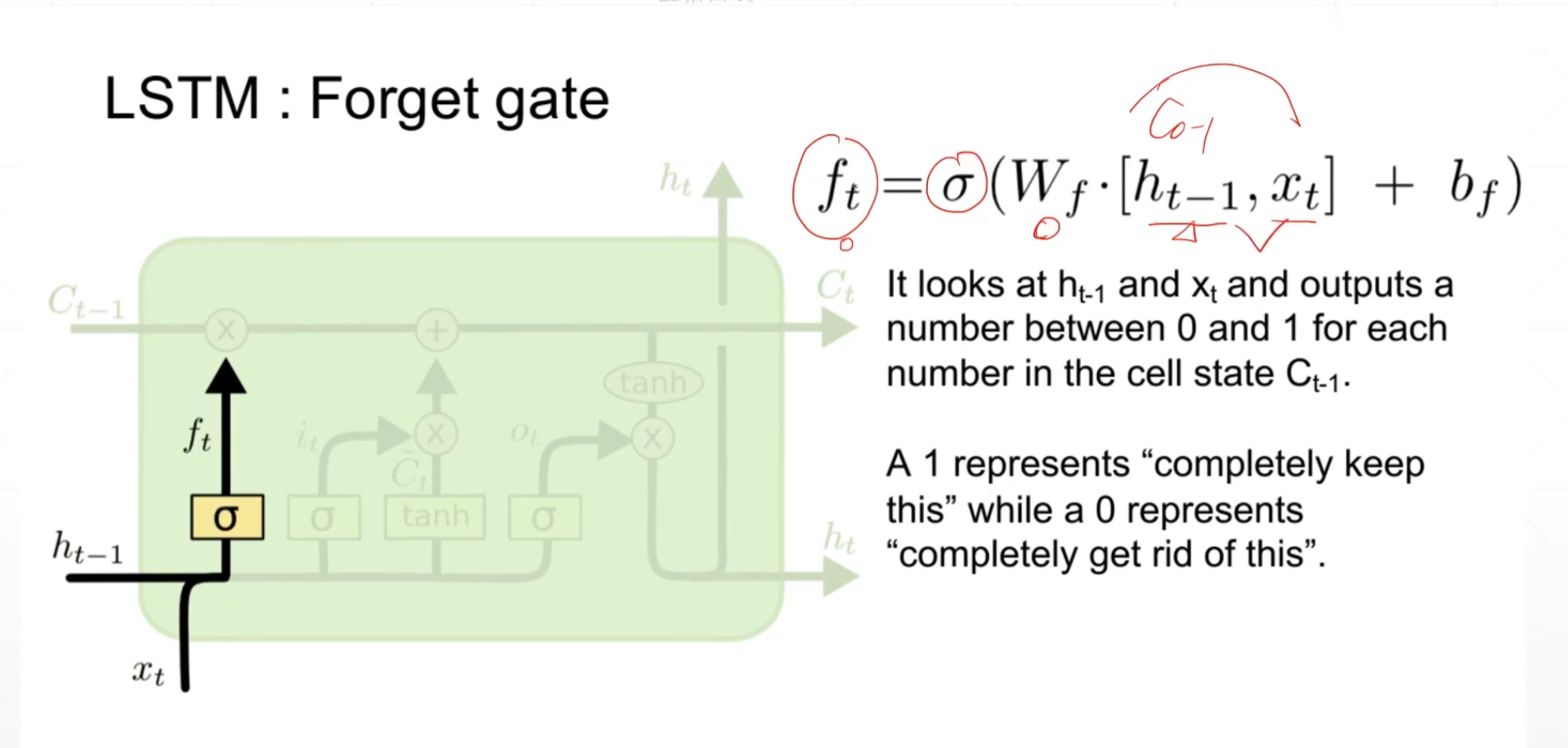
第一道门:忘记门
第二道门:输入门
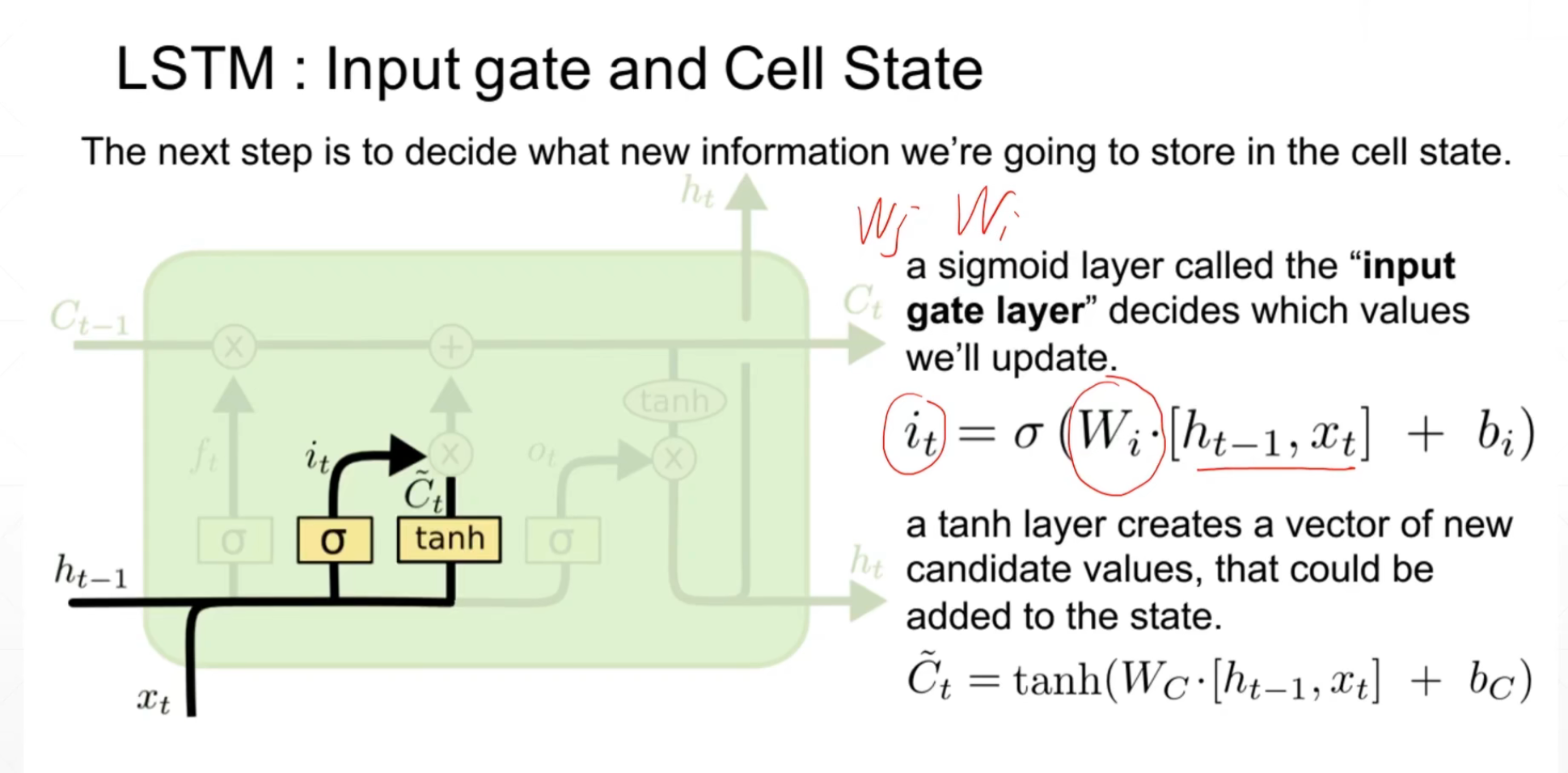
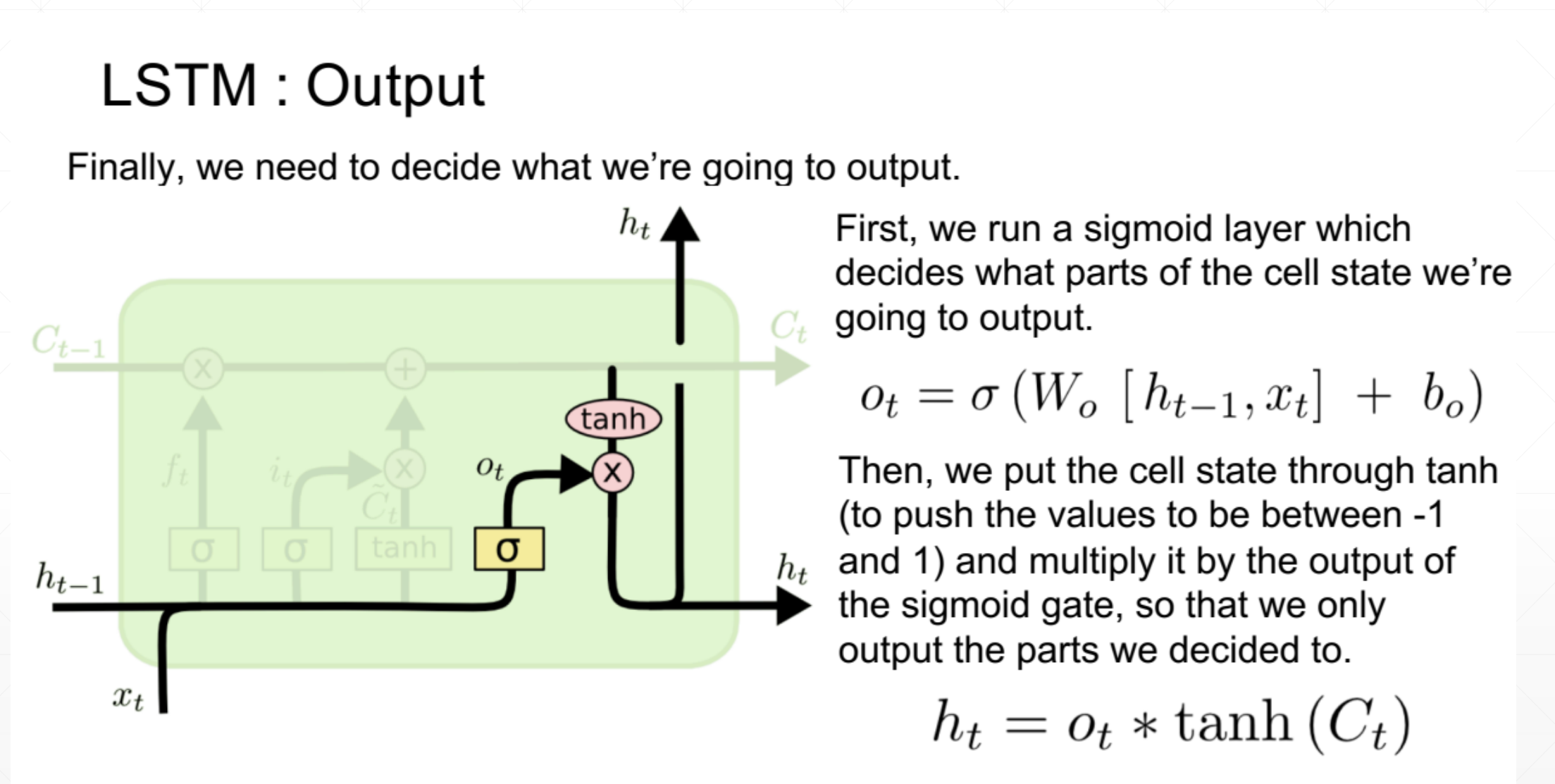
第三道门:输出门
总的:
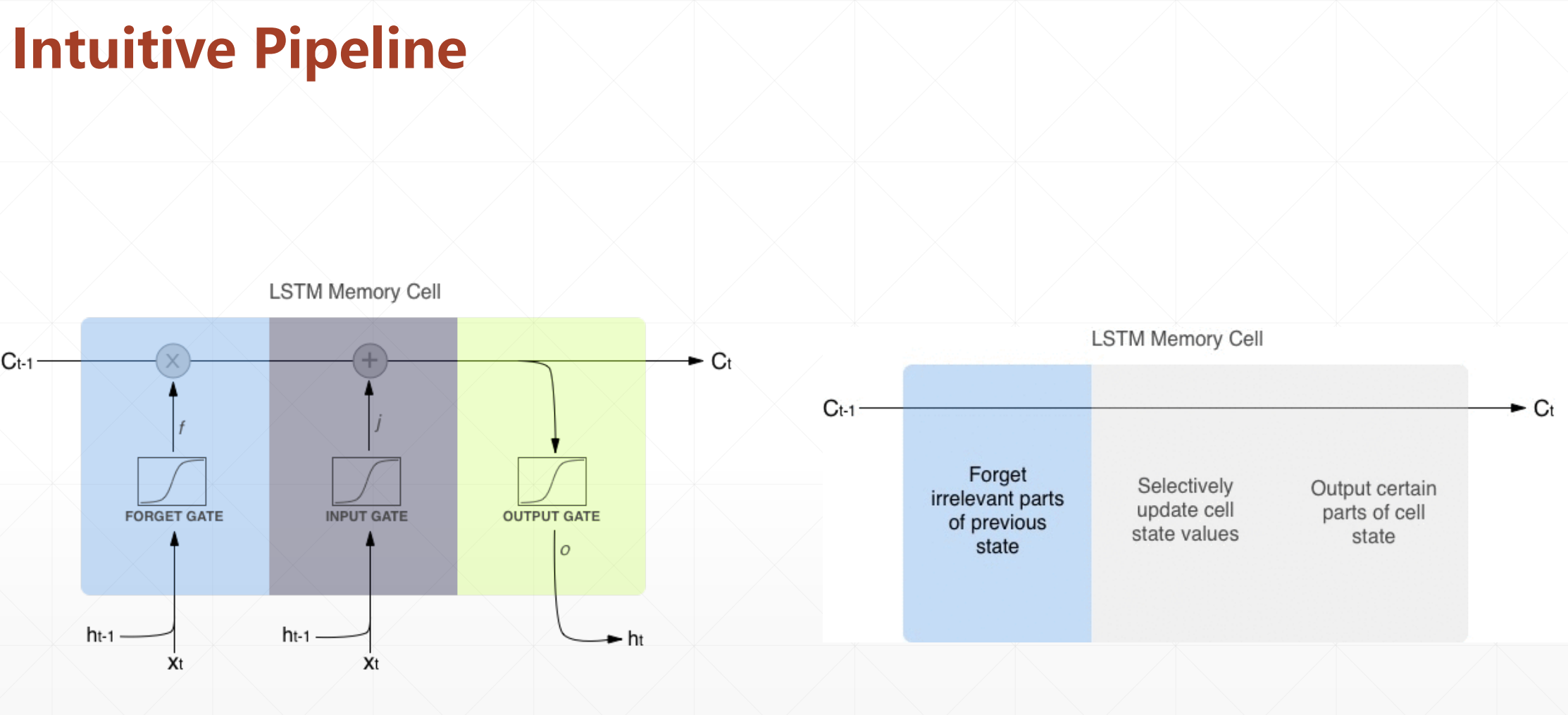
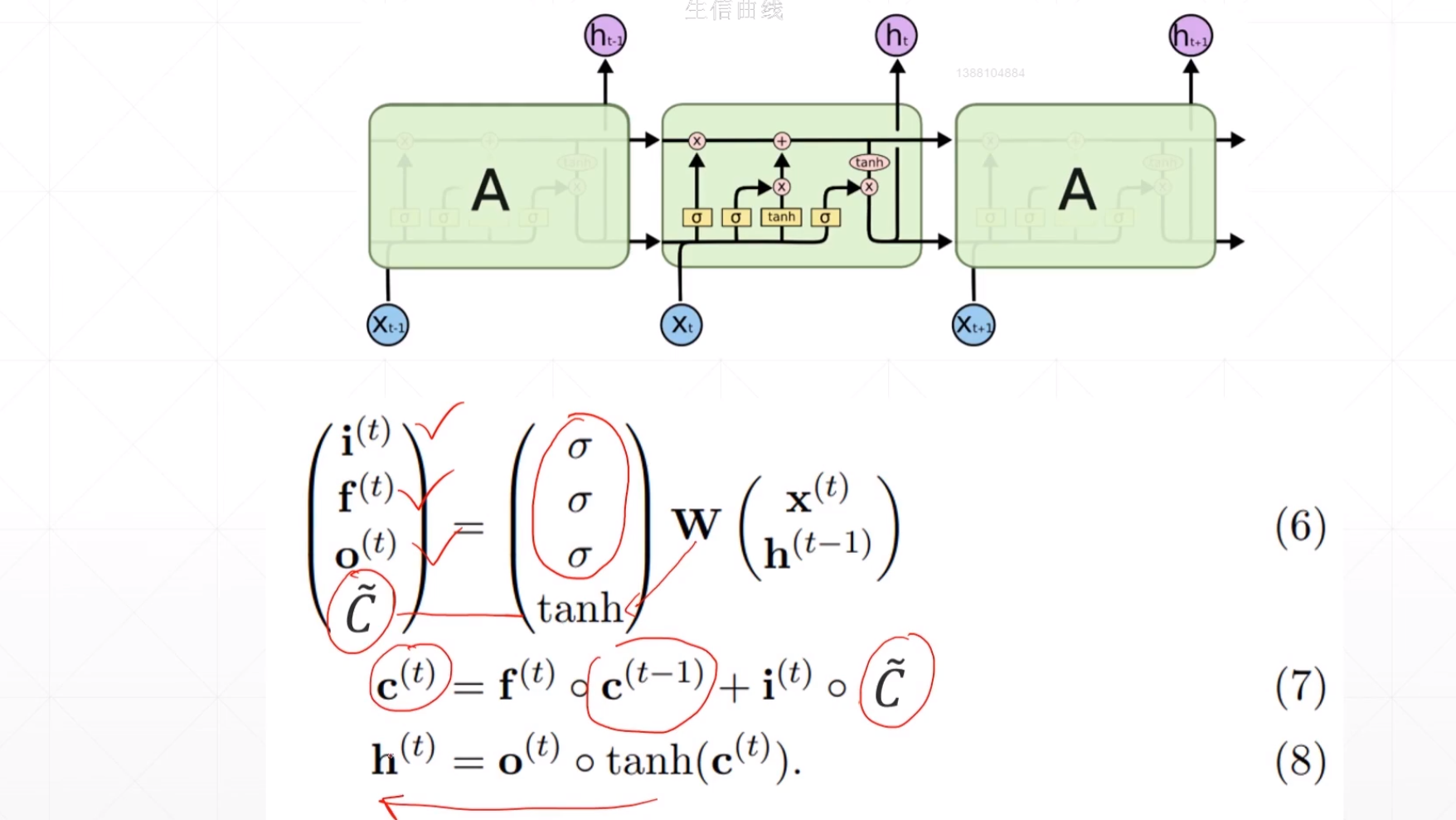
LSTM设计的核心就是这三道门,这有点像一个逻辑单元。
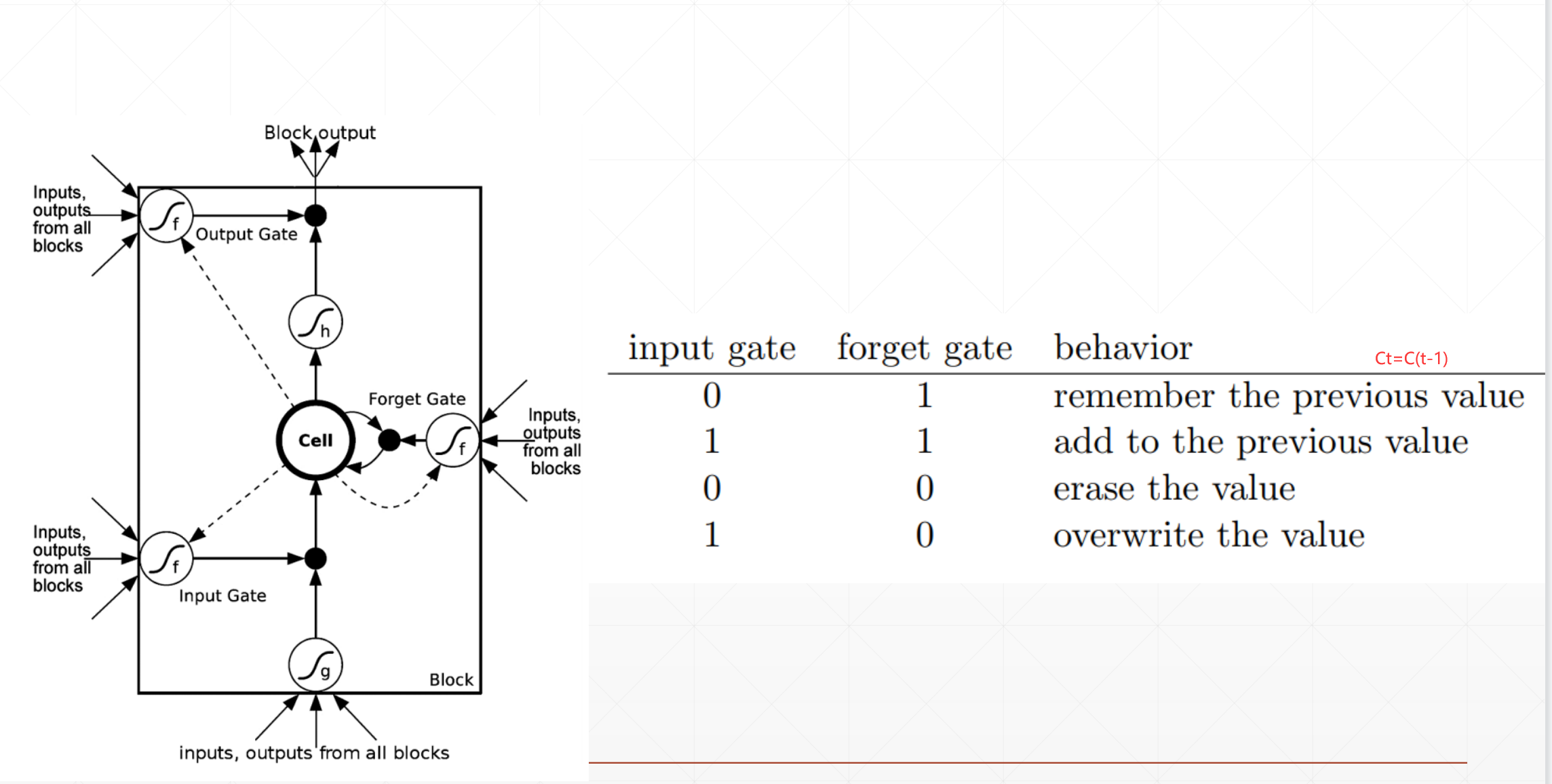
在这里我们会发现
1.如果输入门=0(关上),忘记门=1(打开)的话,这里会记住这个先前的,忘记现在的,也就是\(C_t\)==\(C_{t-1}\)。
2.如果我们的输入门=1(打开),忘记门=1(打开)的话。他会添加上先前的值
3.如果我们的输入门=0(关闭),忘记门=0(关闭)的话。这个\(C_t\)=0+0,它就会清除掉这个value。
4.如果我们的输入门=1(打开),忘记门=0(关闭)的话。他就会用这个新建完全覆盖掉这个解。
然后这个输出门就是他也可以有选择的输出,不一定全部输出。
为什么LSTM可以解决这个梯度弥散的现象?
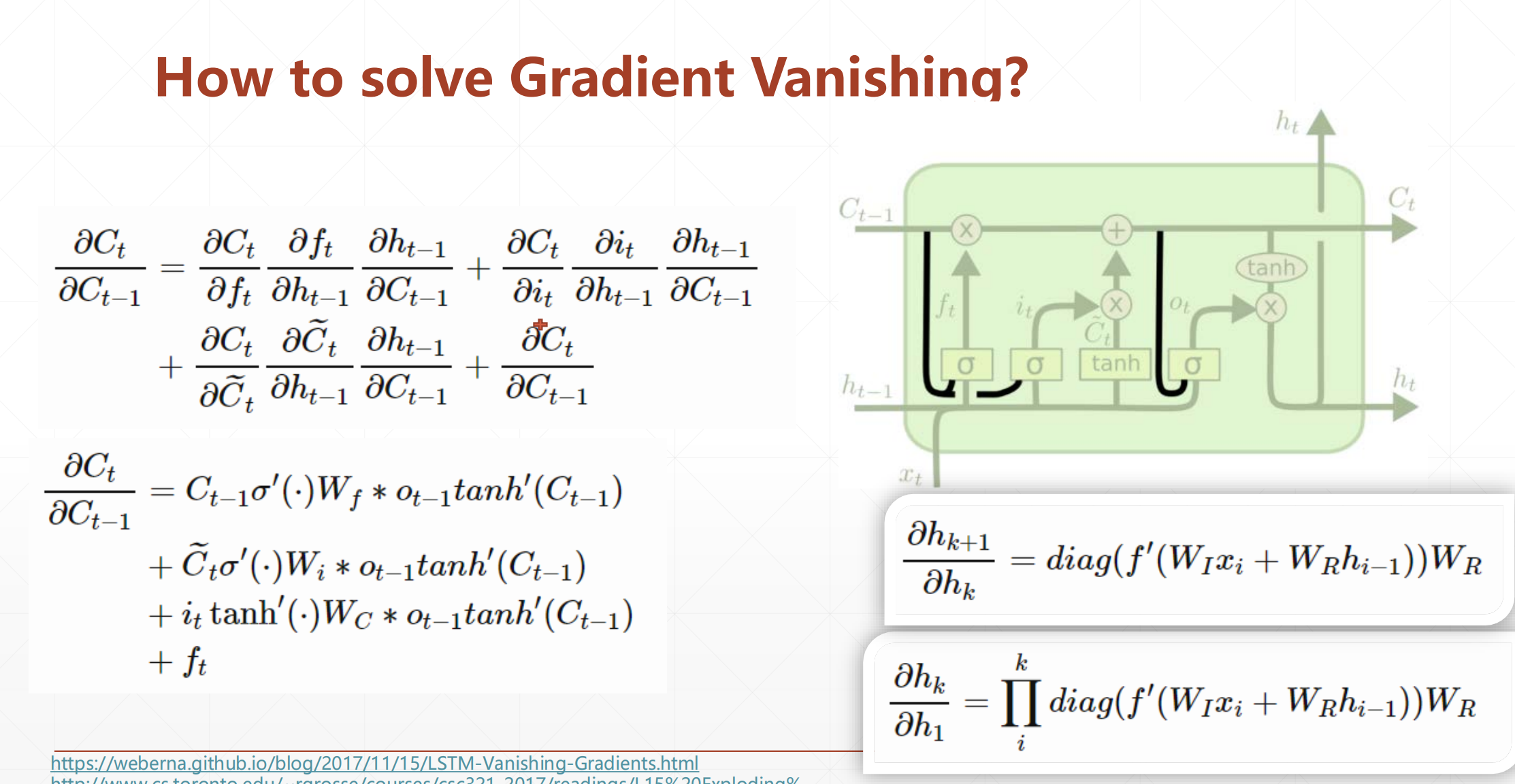
这个LSTM它没有\(W_{hh}^k\)他没有这个K次方出现,而他的梯度是一些因子相加,相互之间有制约性。最主要的就是它没有这个\(W_{hh}^k\)。
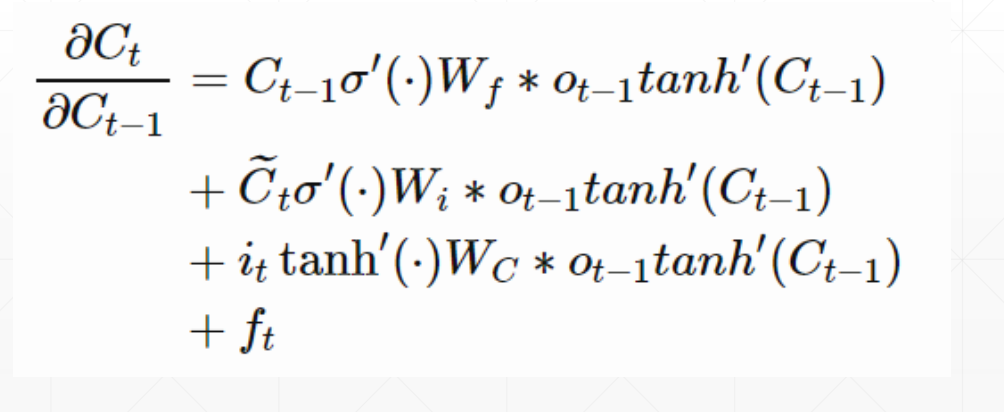
LSTM实战
LSTM
在之前的RNN情感问题分类的基础上改变的。
GRU
- simpler
- lower computation cost
自定义网络
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
tf.random.set_seed(22)
np.random.seed(22)
assert tf.__version__.startswith('2.')
batchsz = 128
# the most frequest words
total_words = 10000
max_review_len = 80
embedding_len = 100
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# x_train:[b, 80]
# x_test: [b, 80]
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print('x_test shape:', x_test.shape)
class MyRNN(keras.Model):
def __init__(self, units):
super(MyRNN, self).__init__()
# transform text to embedding representation
# [b, 80] => [b, 80, 100]
self.embedding = layers.Embedding(total_words, embedding_len,
input_length=max_review_len)
# [b, 80, 100] , h_dim: 64
self.rnn = keras.Sequential([
# layers.SimpleRNN(units, dropout=0.5, return_sequences=True, unroll=True),
# layers.SimpleRNN(units, dropout=0.5, unroll=True)
layers.LSTM(units, dropout=0.5, return_sequences=True, unroll=True),
layers.LSTM(units, dropout=0.5, unroll=True)
])
# fc, [b, 80, 100] => [b, 64] => [b, 1]
self.outlayer = layers.Dense(1)
def call(self, inputs, training=None):
"""
net(x) net(x, training=True) :train mode
net(x, training=False): test
:param inputs: [b, 80]
:param training:
:return:
"""
# [b, 80]
x = inputs
# embedding: [b, 80] => [b, 80, 100]
x = self.embedding(x)
# rnn cell compute
# x: [b, 80, 100] => [b, 64]
x = self.rnn(x,training=training)
# out: [b, 64] => [b, 1]
x = self.outlayer(x)
# p(y is pos|x)
prob = tf.sigmoid(x)
return prob
def main():
units = 64
epochs = 4
import time
t0 = time.time()
model = MyRNN(units)
model.compile(optimizer = keras.optimizers.Adam(0.001),
loss = tf.losses.BinaryCrossentropy(),
metrics=['accuracy'])
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
t1 = time.time()
# 69.3 secnods, 83%
print('total time cost:', t1-t0)
if __name__ == '__main__':
main()
用kears中的API
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers,Sequential
tf.random.set_seed(22)
np.random.seed(22)
assert tf.__version__.startswith('2.')
batchsz = 128
total_words = 10000
max_review_len = 80
embedding_len = 100
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# x_train:[b, 80]
# x_test: [b, 80]
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print('y_train shape:', y_train.shape)
print('x_test shape:', x_test.shape)
model = Sequential([
layers.Embedding(input_dim=total_words, output_dim=embedding_len, input_length=max_review_len),
#layers.LSTM(64, dropout=0.5, return_sequences=True, unroll=True),
layers.LSTM(64, dropout=0.5, return_sequences=True, unroll=True),
layers.LSTM(64, dropout=0.5, unroll=True),
layers.Dense(1,activation='sigmoid')
])
model.build()
model.summary()
model.compile(optimizer="Adamax",
loss=keras.losses.BinaryCrossentropy(), metrics=["accuracy"])
epochs = 4
batch_size = 64
history = model.fit(x_train, y_train, epochs=epochs, batch_size=batchsz,
validation_data=(x_test, y_test))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号