LLaVA-OneVision: Easy Visual Task Transfer论文阅读笔记
Motivation & Abs
LLaVA-OneVision 是一种整合数据、模型和视觉表征的开源多模态模型,首次在单图像、多图像和视频三大计算机视觉场景中实现性能突破。其设计支持跨模态/场景的强迁移学习,尤其通过图像任务迁移展现了强大的视频理解和跨场景能力。
Method
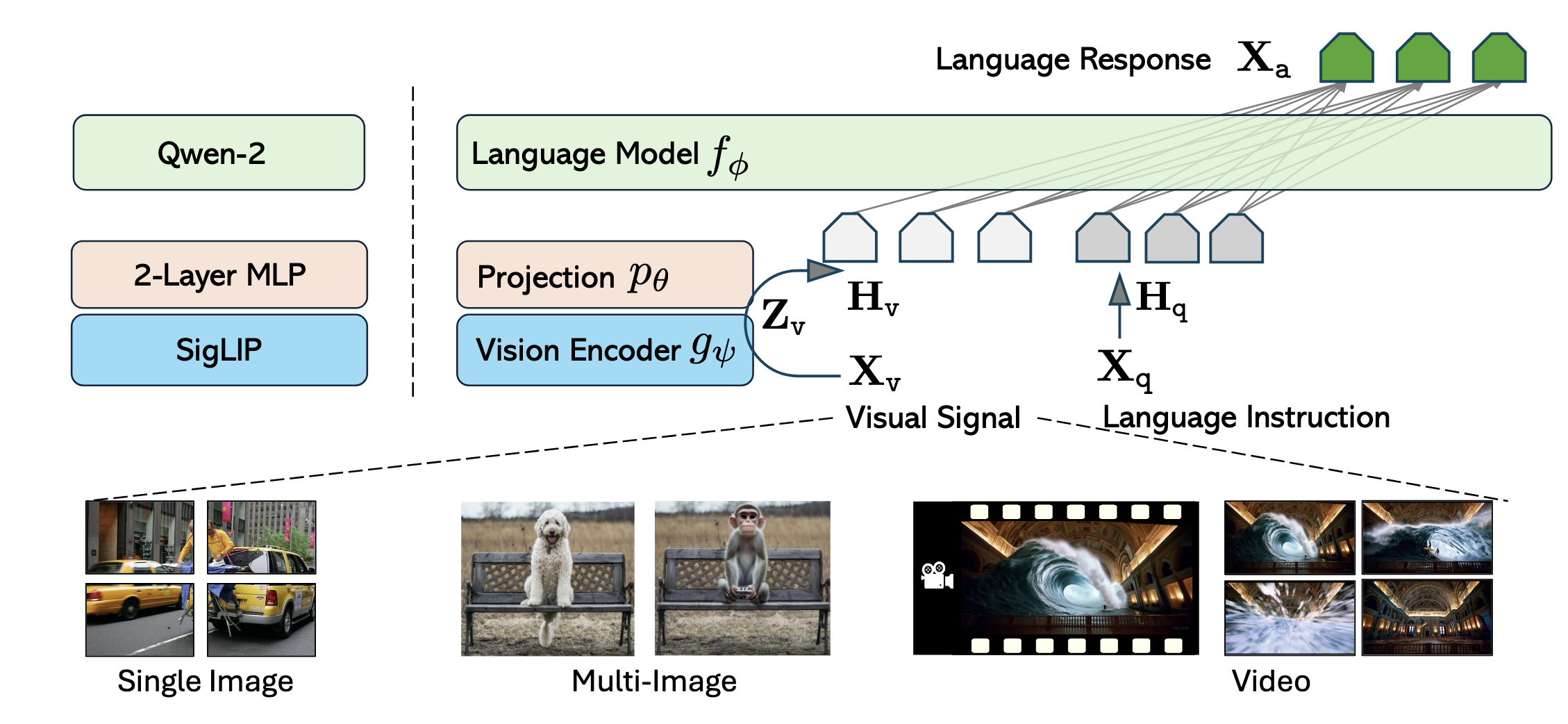
Network Architecture
LLM:Qwen-2(\(f_{\phi}\))
Vision Encoder:SigLIP(\(g_{ψ}\))
Projector:两层MLP(\(p_{\theta}\))
Visual Representation
两个影响视觉编码的关键因素:原始像素空间的分辨率以及特征空间的token数量。为了在性能和计算开销之间取得平衡,作者发现提升分辨率带来的收益更大,同时建议使用带有pooling的AnyRes策略:
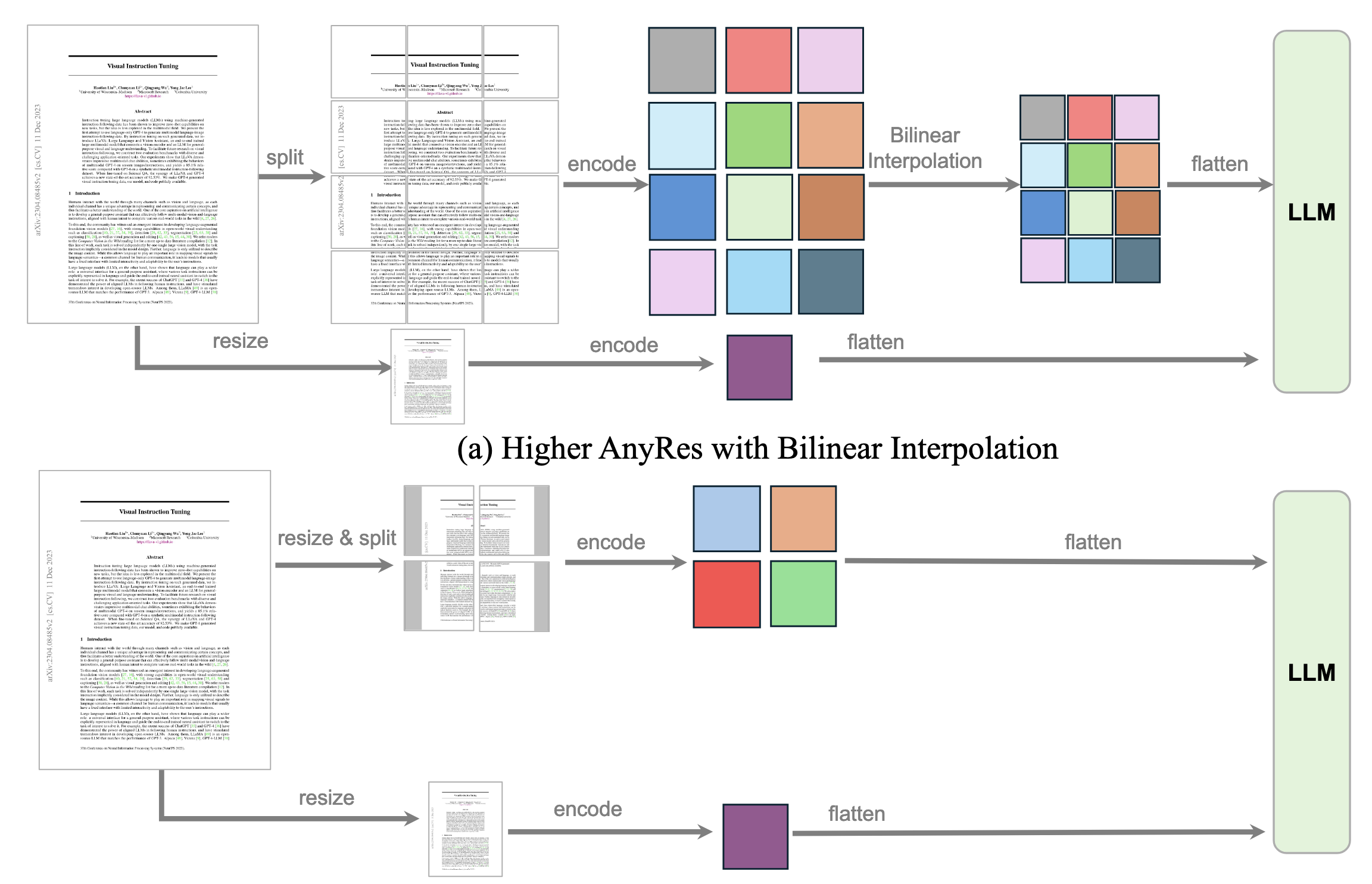
原论文说的比较让人迷惑,看了论文后个人理解这里是将原图拆成\(a\times b\)块,每块通过双线性插值等技术处理为vision encoder能够接受的输入大小,此外再把原图整个resize后送入vision encoder,得到的特征拼在一起送到LLM。假设SigLIP输出的token数量为T,则总共有\((a\times b + 1)\times T\)个token。考虑到计算开销,为了减小token的数量,作者设计了一个阈值\(\tau\),使用双线性插值控制每个crop的token数量:
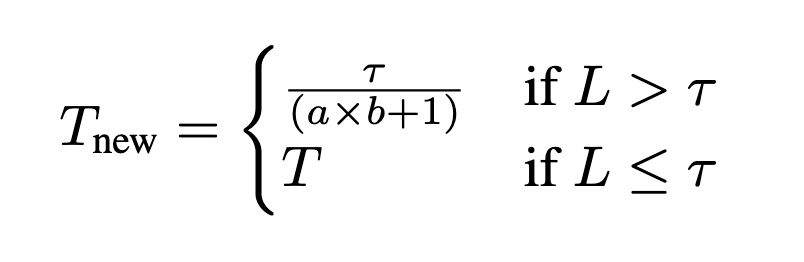
作者预定义了一系列的\((a,b)\)配置,从而适应不同分辨率和纵横比的图像,最终选取的是需要最少crop的配置。
看了一遍代码以后发现,其实就是预设了一系列的分辨率,长宽都是384的整数倍,将图像通过双线性插值调整为最合适的分辨率(插值前后浪费面积最少)。
对于单图像,作者为其设计了一个较大的最大空间配置 (a, b),以保持原始图像分辨率而无需调整大小;此外还为每张图像分配了大量视觉标记,从而形成一个较长的序列,以有效地表示视觉信号(与视频相比,图像具有更多高质量且带有多样化指令的训练样本。通过使用模仿视频表示的长序列来表示图像,我们促进了从图像理解到视频理解的能力平滑迁移)。对于多图像或者视频,仅采用基础图像分辨率。此外对于视频,作者还使用双线性插值以进一步减少token的数量。
数据
在基于LLM训练MLLM的时候,数据的质量往往比数量更重要,因为预训练的过程中模型实际上已经学习并存储了大量知识。然而,在新的高质量数据可用时,持续让模型接触这些数据以进一步获取知识也非常重要。
High-Quality Knowledge
互联网级别的图文数据,质量往往非常低,导致在扩大数据规模进行多模态训练时是非常低效的。为此作者希望通过精心准备的数据去优化、增强预训练学到的知识。
通过如下三种类别的数据进行高质量知识学习:
Re-Captioned Detailed Description Data. 通过LLaVA-NeXT-34B(生成详细caption的能力很强)为COCO118K/BLIP558K/CC3M重新生成新的caption,可以被视为self-improvement AI。
Document / OCR Data.
Chinese and Language Data.
值得注意的是,99.8%的数据都是合成数据,用大规模、高质量的合成数据训练模型是未来的一种趋势。
Visual Instruction Tuning Data
Data Collection and Curation.
三层分级:
Vision Input. 单图/多图/视频。
Language Instruction. General QA, General OCR, Doc/Chart/Screen, Math Reasoning, Language. 这些指令定义了一个经过训练的LMM可以涵盖的技能范围。作者通过任务分类来帮助维持和平衡技能的分布。
Language Response. 答案不仅用于响应用户请求,还用于定义模型的行为。答案大致可以分为自由形式(free-form)和固定形式(fixed-form)。
Single-Image Data.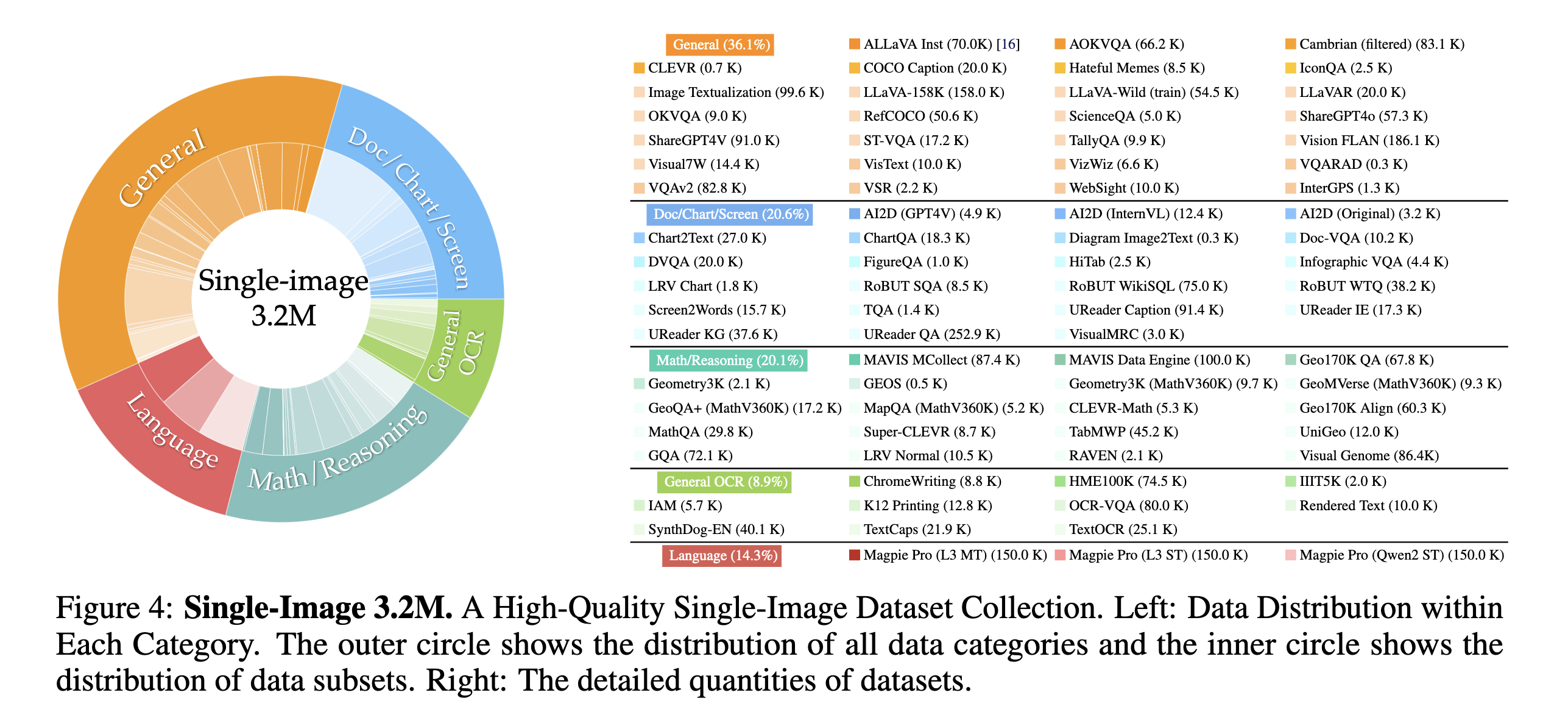
OneVision Data.

训练策略
三个阶段:
1: Language-Image Alignment.
1.5: High-Quality Knowledge Learning.
2: Visual Instruction Tuning.
其中visual instruction tuning也包含两个阶段,分别为单图像训练以及OneVision 训练。
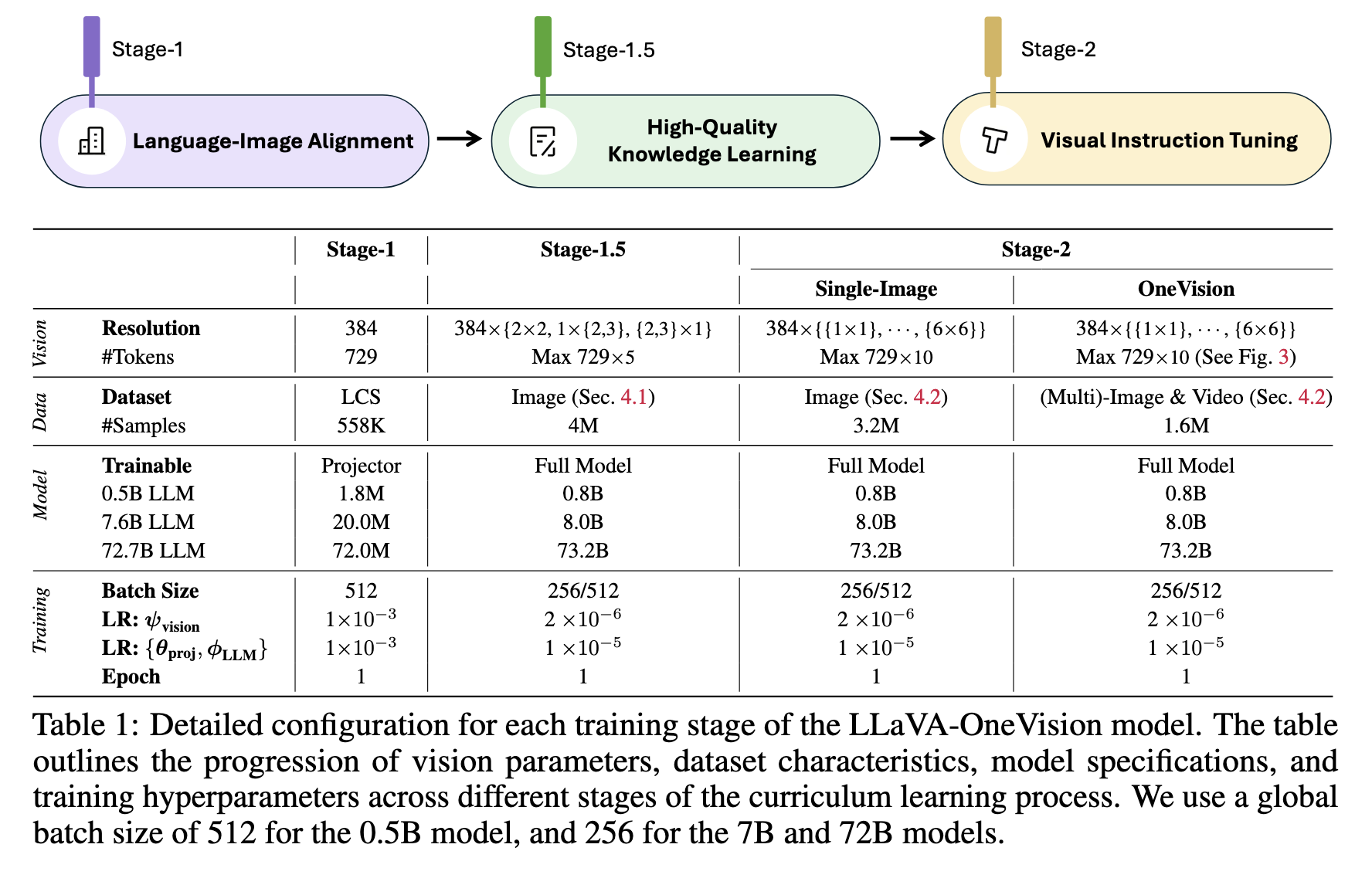
作者通过逐步的方式训练模型以适应长序列训练。随着训练的进行,最大图像分辨率和视觉标记的数量逐渐增加。在阶段1中,考虑基础图像表示,使用729个标记。在阶段1.5和阶段2中,采用AnyRes方法,分别使用多达5倍和10倍的视觉标记。关于可训练模块,阶段1仅更新投影模块,而后续阶段则更新整个模型。此外,需要注意的是,视觉编码器的学习率比LLM的学习率小5倍。
实验结果




 浙公网安备 33010602011771号
浙公网安备 33010602011771号