资源调度和任务调度
文字:
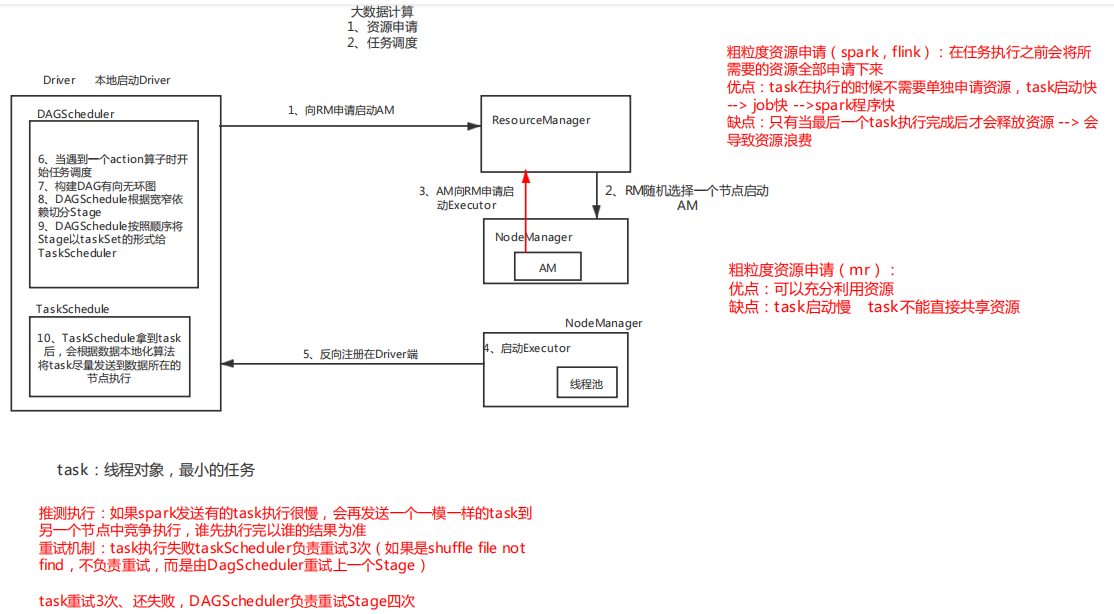
大数据计算分两步
1、资源调度 yarn-client
1、通过spark-submit提交任务
2、在本地启动Driver val sc = new SparkContext(conf)
3、Driver发请求给RM 启动AM
4、RM分配资源启动AM
5、AM向RM申请资源启动Excutor
6、Excutor反响注册给Driver
7、开始任务调度(action算子触发)
粗粒度资源调度 spark
一次性将所需要的资源(executor数量,executor内存,executor core)全部申请下来,task执行不需要再申请资源,执行速度变快
当最后一个task执行完成之后才会释放资源
缺点:浪费资源,导致资源不能充分利用
细粒度资源调度 mr
每一个task执行都需要单独申请资源,每次申请资源需要时间,导致task执行变慢--->job变慢---->application变慢
充分利用资源
Application(spark程序)--->Job(一个action算子触发的任务)--->stage(一组并行计算的task)--->task(执行任务的最小单元)
2、任务调度
1、当遇到一个action算子,触发一个任务,开始任务调度
2、构建DAG有向无环图
3、DAGscheduler根据宽窄依赖切分stage
4、DAGscheduler将stage以taskSet的形式发送给taskScheduler
5、taskscheduler根据本地化算法将task发送到Execuotr中执行
6、taskscheduler接收task执行情况
如果task失败taskscheduler负责重试,默认重试3次 如果是因为shuffle file not found taskscheduler不再重试task,而是由DAGscheduler重试上一个stage
DAGscheduler默认重试stage4次
DAGscheduler 负责切分stage
taskscheduler 负责发送task到Exsecutor中执行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号