
数据采集与融合技术第三次作业
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
Gitee文件夹链接:
单线程爬取代码:https://gitee.com/linyuars/2025_crawl_project/blob/master/作业3/1/1.py
多线程爬取代码:https://gitee.com/linyuars/2025_crawl_project/blob/master/作业3/1/2.py
1.核心代码
为获取到图片url和下一页url相关信息的所在位置,先检查页面,发现所有包含商品图片的url信息的img标签都在id='component_47'的ul标签下的各个li标签下;翻页的url信息在class='next'的li标签下a标签的href中。
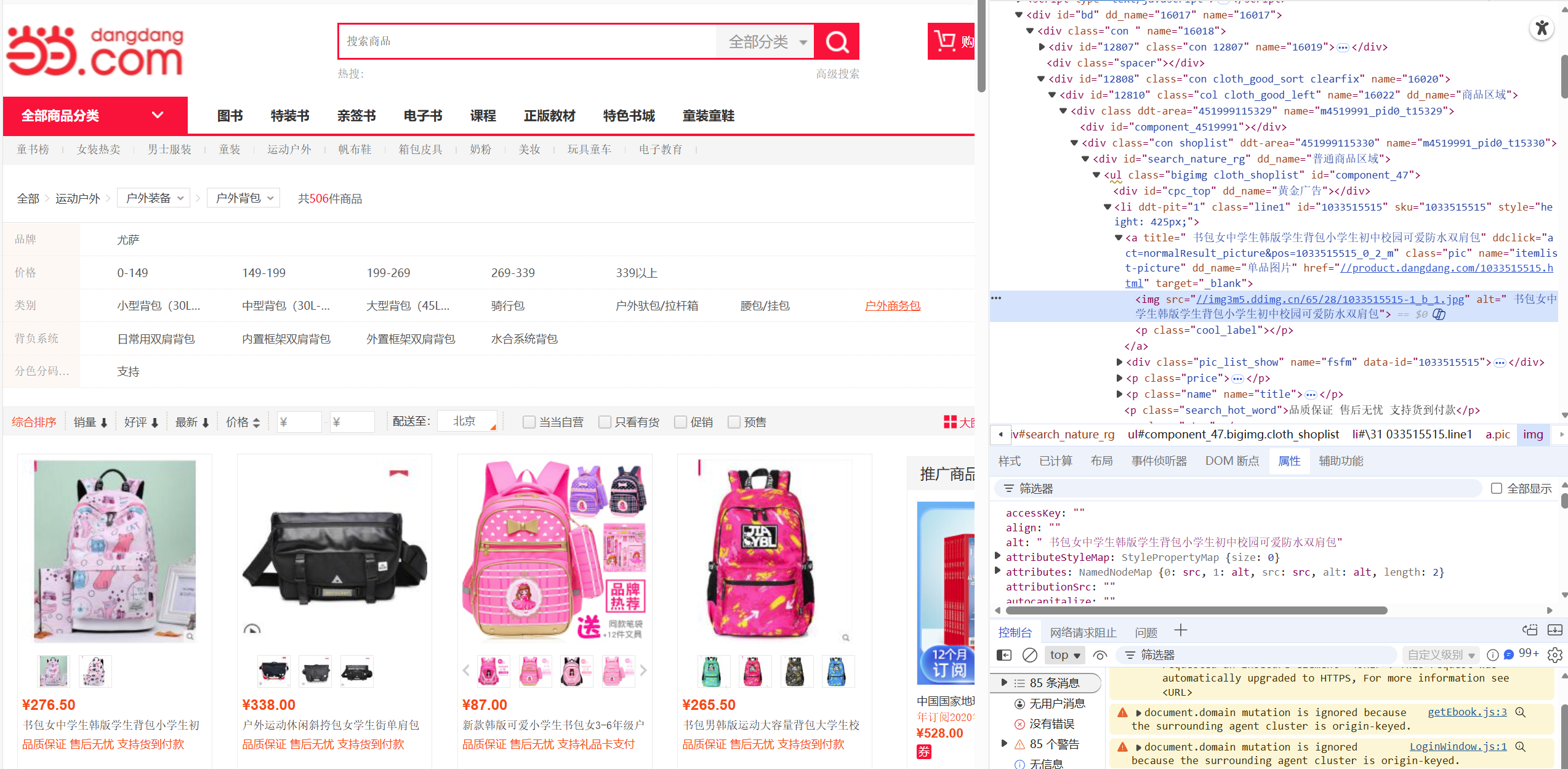
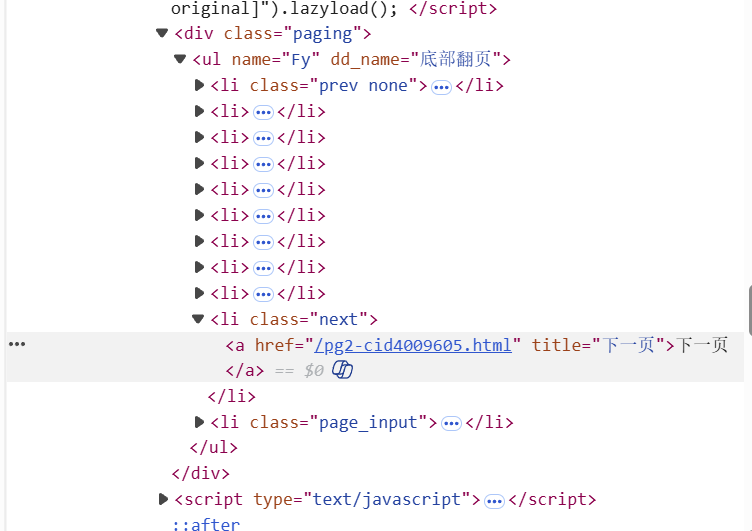
然后开始编写爬虫程序,首先定义单线程和多线程有关images文件夹初始化的函数,其内容是一致
def initialize():#对images文件夹进行初始化
if not os.path.exists('images'):
os.mkdir('images')#如果不存在images文件夹则创建一个
fs=os.listdir('images')
for f in fs:
os.remove('images\\'+f)#如果存在则删除其文件夹下的所有文件
接着编写下载图片的downloadImg函数,单线程和多线程的该函数内容也是一致的
def downloadImg(id,src,tExt):#进行图片的下载
try:
id="%06d"%(id)
imageName=id+'.'+tExt
urllib.request.urlretrieve(src,"images\\"+imageName)#通过urlretrieve函数将url为src的图片下载到images文件夹中,且命名为imageName
except Exception as err:
print(err)
以下是单线程的爬取函数(spider):
def spider(url):#对该页的图片进行爬取
global count,page#定义全局变量count和page做为爬虫是否执行的判定条件
if count<137 and page<7:#满足限定条件爬虫才会继续执行,否则会终止
page+=1
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req).read().decode('gbk')#发起请求并爬取源数据(即网页的HTML数据)
soup=BeautifulSoup(data,'lxml')#用lxml解析器对解析数据
lis=soup.select("ul[id='component_47']>li")#根据刚才检查的发现,先爬取包含所需要的a标签所在的li标签
for li in lis:
if count>=137:#这里同样也是判定条件,爬取到足够数量的图片就终止
break
count+=1
tag=li.select_one("a")#找到包含url信息的a标签
if tag.select_one('img').get('data-original'):#找到a标签下的img标签,如果有data-original属性则优先爬取其内容,当中也包括有关图片url的信息
href=tag.select_one('img')['data-original']
else:
href=tag.select_one('img')['src']#否则爬取a标签下的img标签中的src属性的内容
src=urllib.request.urljoin(url,href)#组成完整的图片url
p=src.rfind('.')
tExt=src[p+1:]#找到图片的命名格式
downloadImg(count,src,tExt)#执行下载图片函数
print(url)#打印出该页的url
nextUrl=''
href=soup.select_one("li[class='next'] a")['href']#爬取与下一页相关的url信息
if href:#如果存在下一页则继续爬取
nextUrl=urllib.request.urljoin(url,href)#获取完整的下一页的url
spider(nextUrl)#递归进行爬取
以下是多线程的爬取函数:
def spider(url):#对该页的图片进行爬取
global count,page,threads#定义全局变量count和page做为爬虫是否执行的判定条件,并定义全局threads列表存储线程
if count<137 and page<7:#满足限定条件爬虫才会继续执行,否则会终止
page+=1
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req).read().decode('gbk')#发起请求并爬取源数据(即网页的HTML数据)
soup=BeautifulSoup(data,'lxml')#用lxml解析器对解析数据
lis=soup.select("ul[id='component_47']>li")#根据刚才检查的发现,先爬取包含所需要的a标签所在的li标签
for li in lis:
if count>=137:#这里同样也是判定条件,爬取到足够数量的图片就终止
break
count+=1
tag=li.select_one("a")#找到包含url信息的a标签
if tag.select_one('img').get('data-original'):#找到a标签下的img标签,如果有data-original属性则优先爬取其内容,当中也包括有关图片url的信息
href=tag.select_one('img')['data-original']
else:
href=tag.select_one('img')['src']#否则爬取a标签下的img标签中的src属性的内容
src=urllib.request.urljoin(url,href)#组成完整的图片url
p=src.rfind('.')
tExt=src[p+1:]#找到图片的命名格式
T=threading.Thread(target=downloadImg,args=[count,src,tExt])
T.start()#启动一个线程下载图像
threads.append(T)#把各个线程记录在threads列表
print(url)#打印出该页的url
nextUrl=''
href=soup.select_one("li[class='next'] a")['href']#爬取与下一页相关的url信息
if href:#如果存在下一页则继续爬取
nextUrl=urllib.request.urljoin(url,href)#获取完整的下一页的url
spider(nextUrl)#递归进行爬取
这里在爬取的时候需要注意的是有的图片所在img标签中的src是无效的,这时候发现img标签下的data-original中的信息才是我们需要的有关url的信息,所以在爬取过程中先优先爬取img标签下的data-original中的信息,如果没有就爬取其src的信息

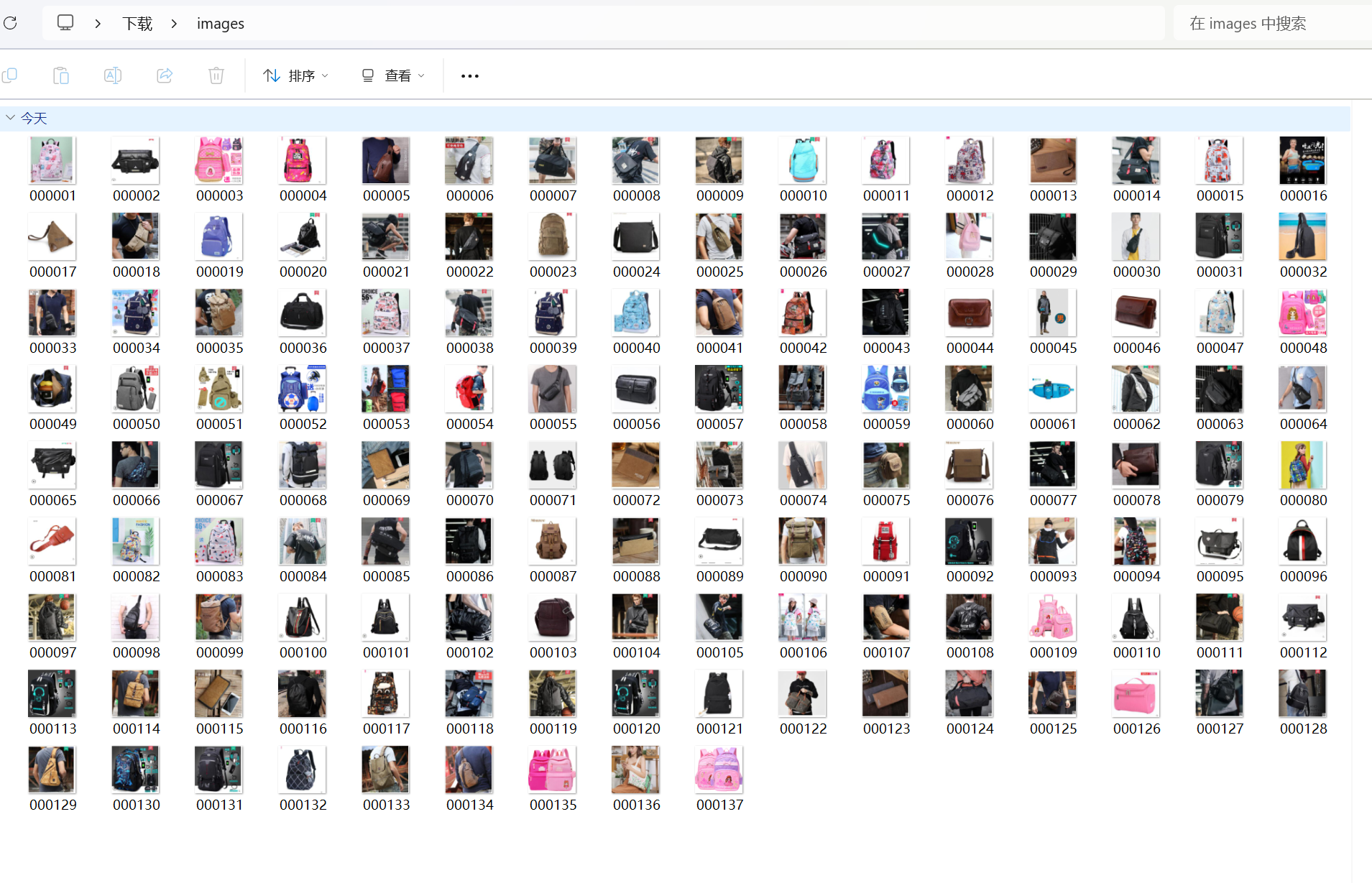
2.运行结果
以下展示的是单线程爬取程序的结果,实际上多线程结果也一样,但效率更高

3.心得体会
通过本次实践让我深刻明白了多线程爬取信息的高效率,掌握了部分多线程爬取信息的技巧和方法,也巩固了用BeautifulSoup提取信息的能力,提高了个人的爬虫编程和解决实际问题的能力
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1688093 | N世华 | 28.47 | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.20 | 17.55 |
Gitee文件夹链接:
mySprider.py:https://gitee.com/linyuars/2025_crawl_project/blob/master/作业3/2/1.py
middlewares.py: https://gitee.com/linyuars/2025_crawl_project/blob/master/作业3/2/4.py
items.py: https://gitee.com/linyuars/2025_crawl_project/blob/master/作业3/2/2.py
Pipelines.py: https://gitee.com/linyuars/2025_crawl_project/blob/master/作业3/2/3.py
settings.py: https://gitee.com/linyuars/2025_crawl_project/blob/master/作业3/2/5.py
1.核心代码:
由于股票网站的信息是动态渲染的,用普通的request爬取方法获取不到信息,这里采用selenium与scrapy框架相结合的方法来爬取数据,在编写代码爬取数据之前先观察所要爬取股票信息的具体位置在哪里,通过检查网页得知具体的股票信息在class='quotetable'的div标签下的table标签下的tbody标签下的一个个tr标签中,每一个tr标签包含了一个股票的信息,其中有多个td标签,其中包含了对应股票的不同信息,其中tr下的第一个td包含的文本就是该股票的序号,第二个是代码,以此类推就很容易知道我们要爬取的信息具体在第几个tr的第几个td中了。
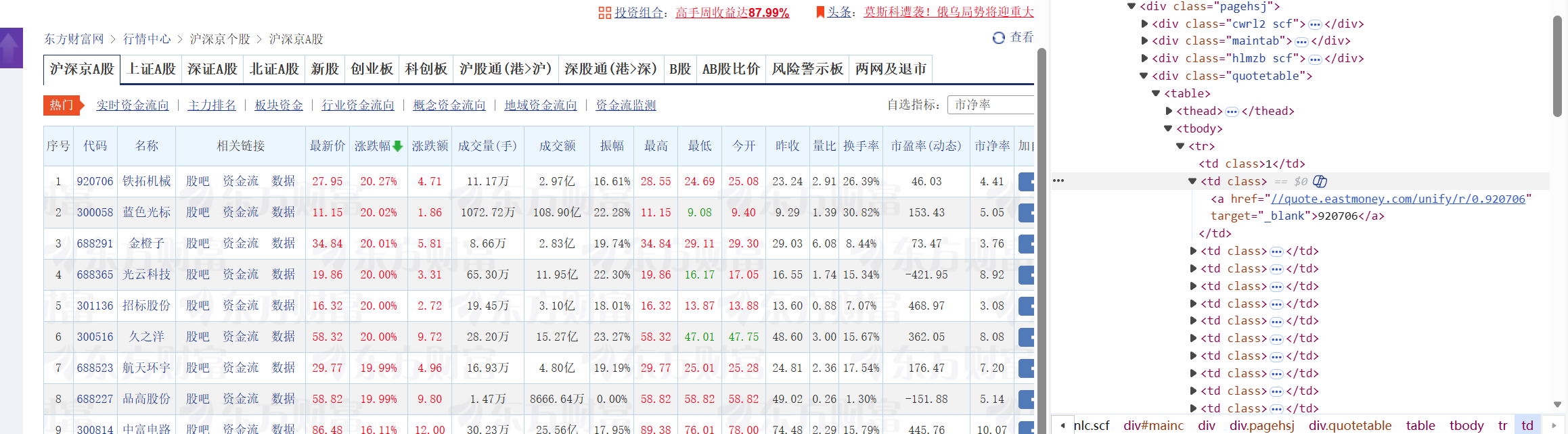
首先比较重要的是编写middlewares.py文件,将selenium与scrapy框架相结合,在其中增加以下代码
from scrapy import signals
from scrapy.http import HtmlResponse
from selenium import webdriver
from selenium.webdriver.edge.options import Options
import time
class SeleniumMiddleware:#新建SeleniumMiddleware类
def __init__(self):
options = Options()
options.add_argument('--headless') # 无头模式
options.add_argument('--disable-gpu')
# 初始化浏览器驱动
self.driver = webdriver.Edge(options=options)
@classmethod
def from_crawler(cls, crawler):
middleware = cls()
crawler.signals.connect(middleware.spider_closed, signal=signals.spider_closed)
return middleware
def process_request(self, request, spider):
try:
# 使用Selenium加载页面
self.driver.get(request.url)
time.sleep(10)
# 等待页面加载完成后获取页面源码
page_source = self.driver.page_source
# 返回HtmlResponse对象
return HtmlResponse(
url=request.url,
body=page_source,
encoding='utf-8',
request=request
)
except Exception as e:
spider.logger.error(f"Selenium error: {e}")
return None
def spider_closed(self, spider):
# 爬虫关闭时退出浏览器
self.driver.quit()
然后编写数据项目类,在items.py下编写如下代码,建立一个股票类
import scrapy
#建立一个股票类,定义13个项目字段,对应要爬取的股票的不同信息
class StockItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
id=scrapy.Field()
code=scrapy.Field()
name=scrapy.Field()
price=scrapy.Field()
change_percent=scrapy.Field()
change_amount = scrapy.Field()
volume = scrapy.Field()
turnover =scrapy.Field()
amp = scrapy.Field()
m=scrapy.Field()
n=scrapy.Field()
today=scrapy.Field()
yesterday=scrapy.Field()
pass
接着编写爬虫程序mySprider.py
from demo.items import StockItem#引入刚刚编写的股票类的定义
import scrapy
class MyScrapy(scrapy.Spider):
name="mySpider"
start_urls = ['https://quote.eastmoney.com/center/gridlist.html#hs_a_board']
def parse(self,response):
try:
data = response.body.decode()#解码网站数据得到对应的html源码
selector = scrapy.Selector(text=data)#建立selector对象,用于搜索具体标签下的信息
trs = selector.xpath("//div[@class='quotetable']/table/tbody/tr")#找到该页下每个股票对应的tr标签
for tr in trs:#用xpath方法提取每个股票的相应信息,并构成StockItem对象推送给相应的管道处理对象
item=StockItem()
item["id"]=tr.xpath("./td[position()=1]/text()").extract_first()
item["code"] = tr.xpath("./td[position()=2]/a/text()").extract_first()
item["name"] = tr.xpath("./td[position()=3]/a/text()").extract_first()
item["price"] = tr.xpath("./td[position()=5]/span/text()").extract_first()
item["change_percent"] = tr.xpath("./td[position()=6]/span/text()").extract_first()
item["change_amount"] = tr.xpath("./td[position()=7]/span/text()").extract_first()
item["volume"] = tr.xpath("./td[position()=8]/span/text()").extract_first()
item["turnover"] = tr.xpath("./td[position()=9]/span/text()").extract_first()
item["amp"] = tr.xpath("./td[position()=10]/span/text()").extract_first()
item["m"] = tr.xpath("./td[position()=11]/span/text()").extract_first()
item["n"] = tr.xpath("./td[position()=12]/span/text()").extract_first()
item["today"] = tr.xpath("./td[position()=13]/span/text()").extract_first()
item["yesterday"] = tr.xpath("./td[position()=14]/span/text()").extract_first()
yield item
except Exception as err:
print(err)
然后编写管道处理类对象
import sqlite3
class StockPipeline:
def open_spider(self, spider):#首先连接stocks数据库并创建stock表存储股票的相关信息
self.con = sqlite3.connect("stocks.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute(
"create table stock (id varchar(16),code varchar(16),name varchar(16),price varchar(16),change_percent varchar(16),change_amount varchar(16),volume varchar(16),turnover varchar(16),amp varchar(16),m varchar(16),n varchar(16),today varchar(16),yesterday varchar(16))")
except:
self.cursor.execute("drop table if exists stock")
self.cursor.execute(
"create table stock (id varchar(16),code varchar(16),name varchar(16),price varchar(16),change_percent varchar(16),change_amount varchar(16),volume varchar(16),turnover varchar(16),amp varchar(16),m varchar(16),n varchar(16),today varchar(16),yesterday varchar(16))")
def close_spider(self, spider):#在爬取结束后查询数据库中的信息并打印出来,最后关闭数据库
self.cursor.execute("select * from stock")
rows = self.cursor.fetchall()
print("%-16s%-16s%-18s%-16s%-16s%-16s%-16s%-18s%-16s%-16s%-16s%-13s%-16s" % ("id","code","name","price","change_percent","change_amount","volume","turnover","amp","m","n","today","yesterday"))
for row in rows:
print("%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s" % (row[0], row[1], row[2], row[3], row[4], row[5] ,row[6], row[7], row[8], row[9], row[10], row[11] ,row[12]))
self.con.commit()
self.con.close()
def process_item(self, item, spider):#对于每一个推送来的StockItem对象,提取其中的股票信息并将其插入到stock表的相应位置
try:
self.cursor.execute("insert into stock (id,code,name,price,change_percent,change_amount,volume,turnover,amp,n,m,today,yesterday) values(?,?,?,?,?,?,?,?,?,?,?,?,?)",
(item['id'], item['code'], item['name'], item['price'], item['change_percent'], item['change_amount'],item['volume'],item['turnover'],item['amp'],item['m'],item['n'],item['today'],item['yesterday']))
except Exception as err:
print(err)
return item
最后修改一下scrapy的配置文件,使得在爬取页面源码的时候采用我们编写的SeleniumMiddleware类,并在该配置文件中设置我们编写的StockPipeline类
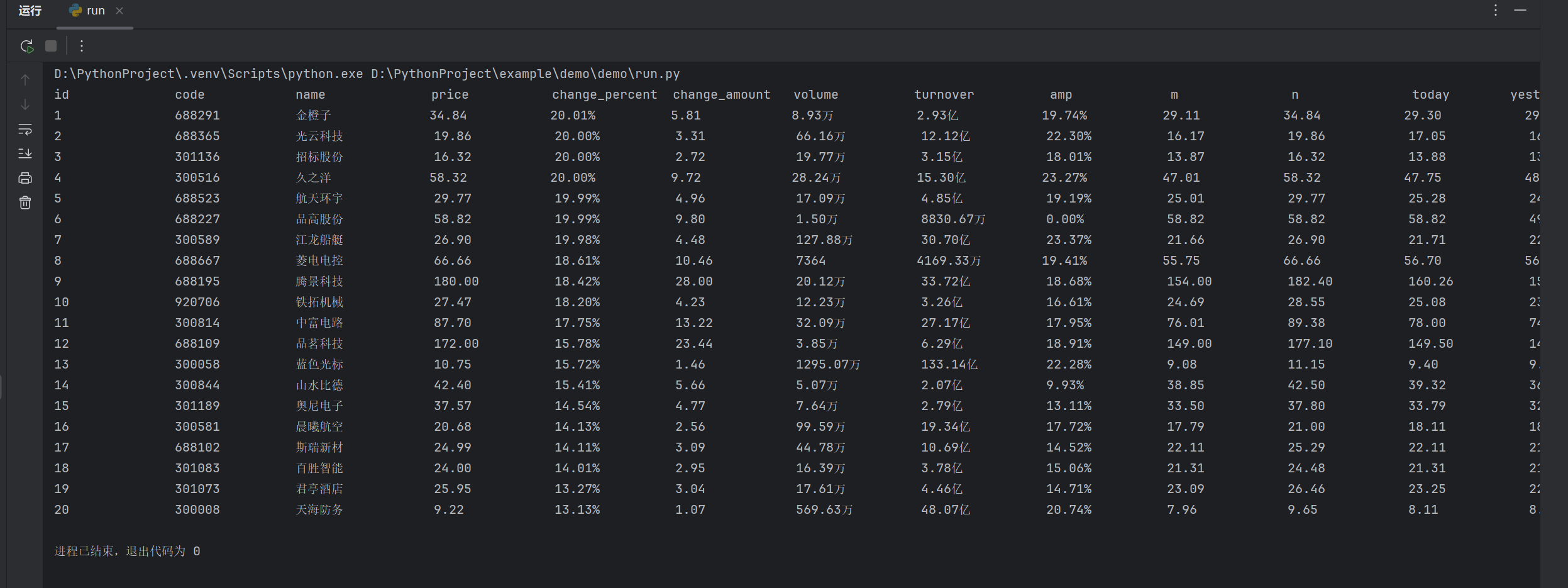
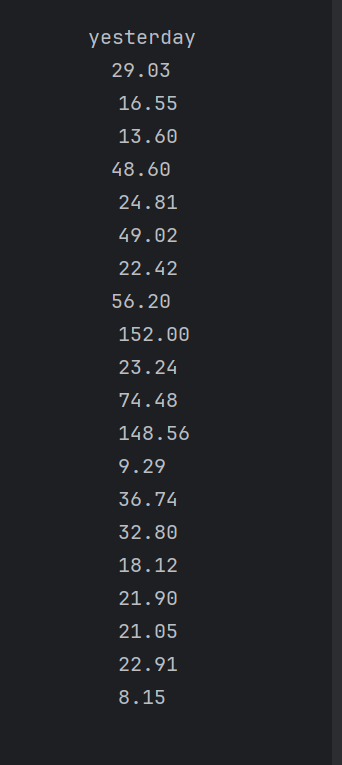
2.运行结果
3.心得体会
通过本次实践我学习到了可以将selenium与scrapy相结合爬取页面html源码的方法,丰富了爬虫编程的相关知识,也体会到了scrapy框架实现了数据的分布式爬取与存储强大功能。
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
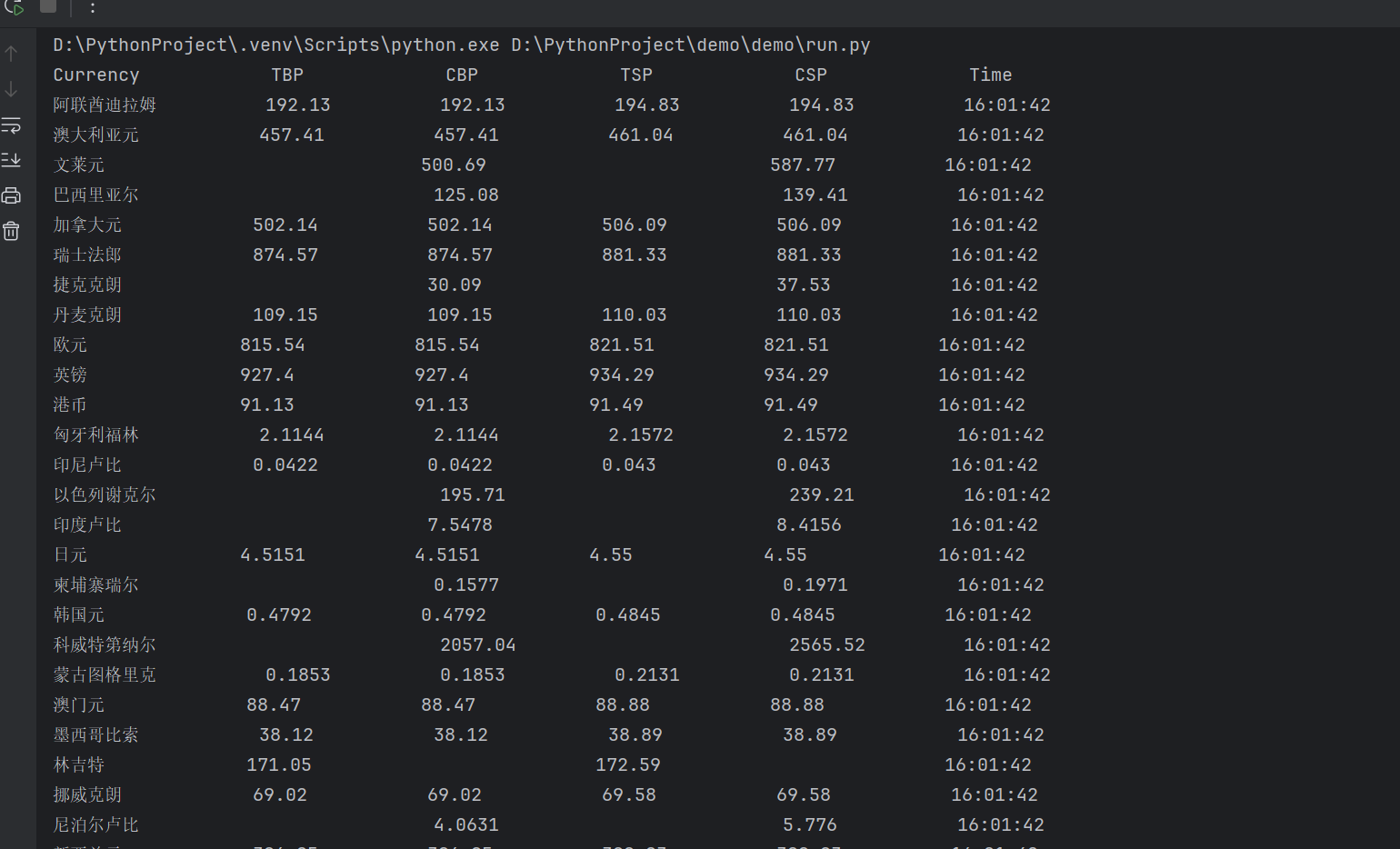
输出信息:
| Currency | TBP | CBP | TSP | CSP | Time |
|---|---|---|---|---|---|
| 阿联酋迪拉姆 | 198.58 | 192.31 | 199.98 | 206.59 | 11:27:14 |
Gitee文件夹链接:
mySprider.py:https://gitee.com/linyuars/2025_crawl_project/blob/master/作业3/3/1.py
middlewares.py: https://gitee.com/linyuars/2025_crawl_project/blob/master/作业3/3/2.py
items.py: https://gitee.com/linyuars/2025_crawl_project/blob/master/作业3/3/3.py
Pipelines.py: https://gitee.com/linyuars/2025_crawl_project/blob/master/作业3/3/4.py
settings.py: https://gitee.com/linyuars/2025_crawl_project/blob/master/作业3/3/5.py
1.核心代码:
这题的整体思路和上一题几乎一致,有重复的地方就不一一赘述了,这题我还是选择采用selenium结合scrapy来爬取信息,其中middlewares.py和setting.py文件的编写方法与上题一致,这里就不展示了。检查网页HTML源码的结构后发现每个货币的信息包含在align='left'的table标签下的tbody标签下的各个tr中,这里面要注意的是有的货币信息暂时是空的,我爬取不到对应的值时用''代替。
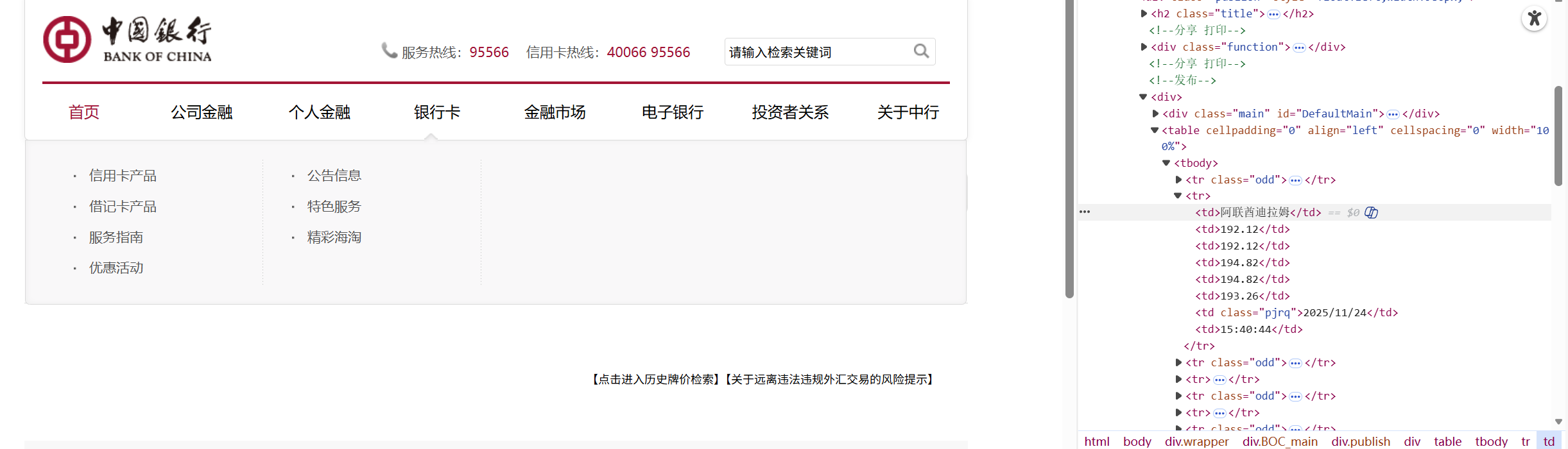
编写数据项目类,在items.py下编写如下代码:
import scrapy
#建立一个货币类,定义6个项目字段,对应要爬取的货币的不同信息
class BankItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency=scrapy.Field()
TBP=scrapy.Field()
CBP=scrapy.Field()
TSP=scrapy.Field()
CSP=scrapy.Field()
Time=scrapy.Field()
pass
编写spider.py文件:
import scrapy
from demo.items import BankItem
class MyScrapy(scrapy.Spider):
name="mySpider"
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self,response):
try:
data=response.body.decode()
selector=scrapy.Selector(text=data)#解码网站的html源码并建立selector对象
trs=selector.xpath("//table[@align='left']/tbody/tr")[1:]#这里跳过表头,直接爬取存储对应货币信息的tr标签
for tr in trs:
#爬取对应货币的信息并构成BankItem对象推送给相应的管道处理对象
item=BankItem()
item['Currency']=tr.xpath("./td[position()=1]/text()").extract_first()
if not item['Currency']:
item['Currency']=''
item['TBP'] = tr.xpath("./td[position()=2]/text()").extract_first()
if not item['TBP']:
item['TBP']=''
item['CBP'] = tr.xpath("./td[position()=3]/text()").extract_first()
if not item['CBP']:
item['CBP']=''
item['TSP'] = tr.xpath("./td[position()=4]/text()").extract_first()
if not item['TSP']:
item['TSP']=''
item['CSP'] = tr.xpath("./td[position()=5]/text()").extract_first()
if not item['CSP']:
item['CSP']=''
item['Time'] = tr.xpath("./td[position()=8]/text()").extract_first()
if not item['Time']:
item['Time']=''
yield item
except Exception as err:
print(err)
编写管道处理类对象:
import sqlite3
class BankPipeline:
def open_spider(self,spider):#首先连接banks数据库并创建bank表存储股票的相关信息
self.con = sqlite3.connect("banks.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute(
"create table bank (Currency varchar(16),TBP varchar(16),CBP varchar(64),TSP varchar(32),CSP varchar(16),Time varchar(32))")
except:
self.cursor.execute("drop table if exists bank")
self.cursor.execute(
"create table bank (Currency varchar(16),TBP varchar(16),CBP varchar(64),TSP varchar(32),CSP varchar(16),Time varchar(32))")
def close_spider(self,spider):#在爬取结束后查询数据库中的信息并打印出来,最后关闭数据库
self.cursor.execute("select * from bank")
rows = self.cursor.fetchall()
print("%-20s%-16s%-16s%-16s%-16s%-16s" %('Currency','TBP','CBP','TSP','CSP','Time'))
for row in rows:
print("%-16s%-16s%-16s%-16s%-16s%-16s" %(row[0],row[1],row[2],row[3],row[4],row[5]))
self.con.commit()
self.con.close()
def process_item(self, item, spider):#对于每一个推送来的BankItem对象,提取其中的货币信息并将其插入到bank表的相应位置
try:
try:
self.cursor.execute("insert into bank (Currency,TBP,CBP,TSP,CSP,Time) values(?,?,?,?,?,?)",(item['Currency'],item['TBP'],item['CBP'],item['TSP'],item['CSP'],item['Time']))
except Exception as err:
print(err)
return item
最后修改一下scrapy的配置文件:
2.运行结果:
3.心得体会:
通过本次实践,我对于利用scrapy框架和mysql进行分布式数据爬取和数据存储有了更深的理解,也对于相关问题的解答流程更加熟悉,提高了个人编程解决实际爬虫相关问题的能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号