
数据采集与融合技术作业1
1.作业①:
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
输出信息:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| ... |
1.1作业代码和图片
import requests
from bs4 import BeautifulSoup//导入库
url='http://www.shanghairanking.cn/rankings/bcur/2020'
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0'}
response = requests.get(url,headers = headers)
response.encoding = "utf-8"
data = response.text//获取网页的html源码
soup=BeautifulSoup(data,'lxml')
rank=[]
name=[]
province=[]
stype=[]
grade=[]
rank_tags=soup.select('tr[data-v-389300f0] td[data-v-389300f0]:nth-child(1)')
for tag in rank_tags://获取各个大学的排名并存到相应的列表中
tags=tag.text.split('\n')
tag=tags[1].strip()
rank.append(tag)
name_tags=soup.select('tr[data-v-389300f0] span[class="name-cn"]')
for tag in name_tags://获取各个大学的名字并存到相应的列表中
tags=tag.text.split('\n')
tag=tags[0]
name.append(tag)
province_tags=soup.select('tr[data-v-389300f0] td[data-v-389300f0]:nth-child(3)')
for tag in province_tags://获取各个大学所在省市并存到相应的列表中
tags=tag.text.split('\n')
tag=tags[1].strip()
province.append(tag)
stype_tags=soup.select('tr[data-v-389300f0] td[data-v-389300f0]:nth-child(4)')
for tag in stype_tags://获取各个大学的类型并存到相应的列表中
tags=tag.text.split('\n')
tag=tags[1].strip()
stype.append(tag)
grade_tags=soup.select('tr[data-v-389300f0] td[data-v-389300f0]:nth-child(5)')
for tag in grade_tags://获取各个大学的得分并存到相应的列表中
tags=tag.text.split('\n')
tag=tags[1].strip()
grade.append(tag)
print('排名 学校名称 省市 学校类型 总分')//输出结果
for i in range(30):
print(f' {rank[i]} {name[i]} {province[i]} {stype[i]} {grade[i]}')

1.2 心得体会
通过本次实践,我对于用requests和BeautifulSoup库方法爬取网站信息有了更深的理解,也在一定程度上增强了我对于HTML的理解,也提高了我的编码实践能力,为后续要完成更加复杂的实践任务打下基础
2.作业②:
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | XXX |
| 2...... |
2.1作业代码和图片
import requests
import re
url = 'https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input&category_id=4003728&type=4003728&att=1000012%3A1873#J_tab'
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"
}
response = requests.get(url,headers = headers)
data = response.text
start=(re.search(r'<ul class="bigimg cloth_shoplist" id="component_38">.*</ul>',data)).start()
end=(re.search(r'<ul class="bigimg cloth_shoplist" id="component_38">.*</ul>',data)).end()
table=data[start:end] #截取含有需要内容的html源码
if table:
print("序号\t价格\t\t商品名称")
i=1
while re.search(r'<a title=" ', table)!=None:#每找到一组需要的书包名称和价格就将table缩短,去掉含有已经找到信息的源码
start = re.search(r'<a title=" ', table).end()
end = re.search(r' ddclick=', table).start()
name_bag = table[start:end - 1]#提取书包名称
start = re.search(r'<span class="price_n">', table).end()
end = re.search(r'</span>', table).start()
price_bag = table[start+5:end]#提取书包的价格
table = table[end:]
xin = re.search('</li>', table).end()
table = table[xin:]#去除包含已经找到信息的源码后的新的table
if price_bag and name_bag:#打印找到的书包的名称和价格
print("{}\t{}\t{}".format(i, price_bag, name_bag))
i += 1
else:
print("{}\t未找到商品价格或名称".format(i))
i += 1
except Exception as err:
print(err)

2.2 心得体会
通过本次实践任务,进一步加深了我对正则表达式操作符的理解,也让我掌握了更多re库的方法,懂得如何运用具体的正则表达式操作符爬取需要的信息,提高了个人的编程实践能力。
3.作业③:
要求:爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
输出信息:将自选网页内的所有JPEG、JPG或PNG格式图片件保存在一个文件夹中
3.1作业代码和图片
def downloadImage(ID,src,tExt):#下载相应图像到本地文件的函数
try:
imgName='download\\'+ID+'.'+tExt
urllib.request.urlretrieve(src,imgName)
except Exception as err:
print(err)
def initializeDownload():#对本地相应文件夹做初始化
if not os.path.exists('download'):
os.mkdir('download')
fs=os.listdir('download')
if fs:
for f in fs:
os.remove('download\\'+f)
def spider(url):#核心爬虫函数
global page,count,DB,threads
page=page+1
print('Page',page,url)
try:
req=urllib.request.Request(url,headers=headers)
resp=urllib.request.urlopen(req)
html=resp.read().decode()#获取网页源码
soup=BeautifulSoup(html,'lxml')
divs=soup.select("div[class='n_right fr'] div[class='img slow']")
for div in divs:
img=div.select_one('img')
src=''
tExt=''
if img:
src=urllib.request.urljoin(url,img['src'])#获取图片的url
p=src.rfind('.')
if p>=0:
tExt=src[p+1:]
if tExt in ["jpg","png","jpeg"]:#判断是否为符合要求的图片
count=count+1
ID='%06d'%(count)
T=threading.Thread(target=downloadImage,args=[ID,src,tExt])#找到相应图片并进行开启一个线程进行下载
T.start()
threads.append(T)
nextUrl=''
links=soup.select("div[class='pb_sys_common pb_sys_normal pb_sys_style2'] span[class='p_next p_fun'] a")#找含有包含翻页信息的a标签
for link in links:
href=link['href']
nextUrl=urllib.request.urljoin(url,href)#得到下一页的url
if nextUrl:
spider(nextUrl)#进行下一页图像信息的爬取
except Exception as err:
print(err)
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0'}
initializeDownload()
threads=[]
page=0
count=0
spider(url='https://news.fzu.edu.cn/yxfd.htm')
for T in threads:
T.join()#循环等待子线程,确保子线程运行完毕后才结束程序
print('Total %d pages,%d items'%(page,count))
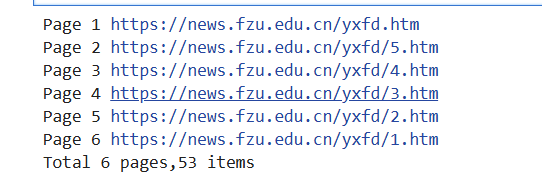
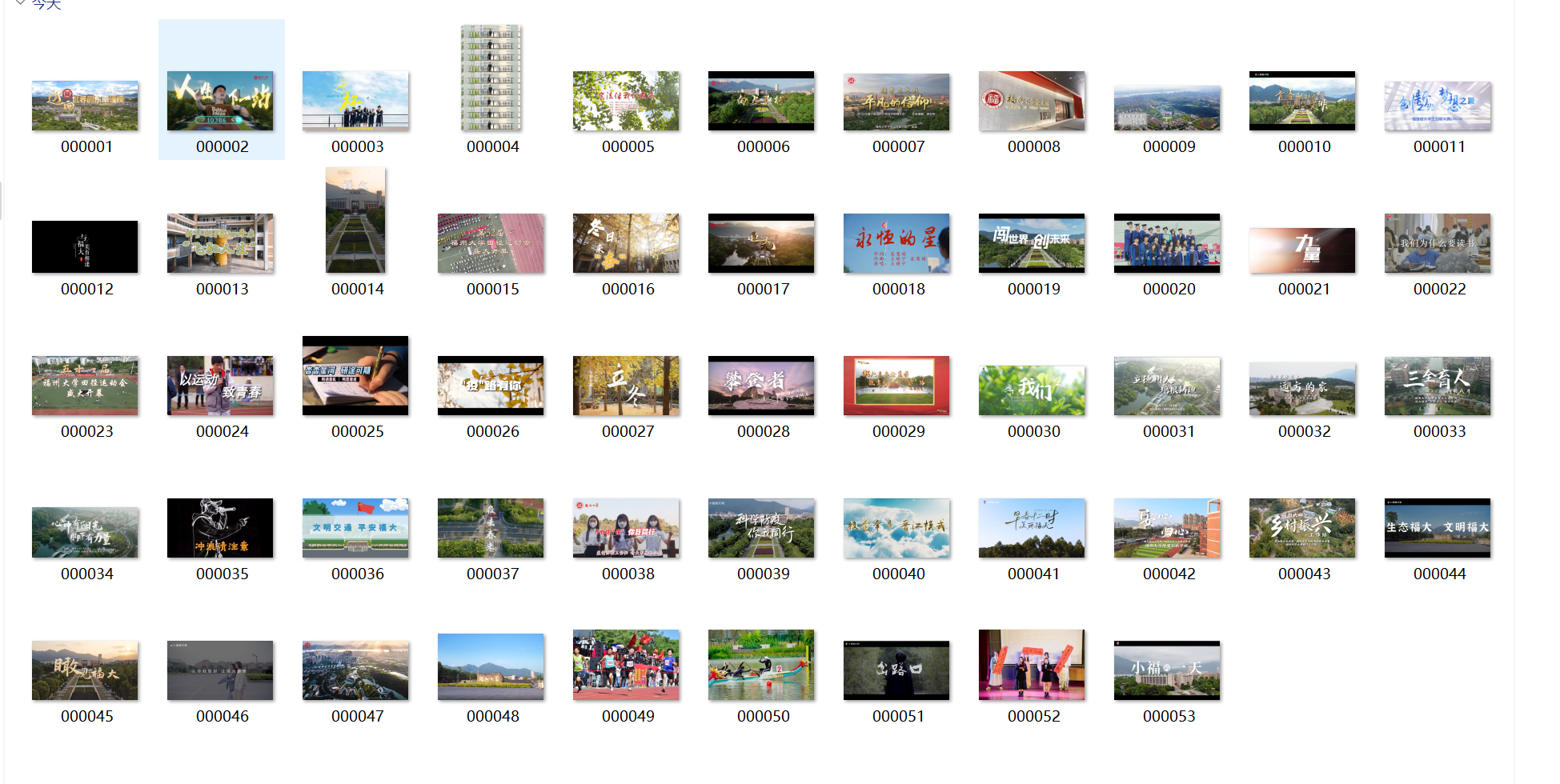
3.2 心得体会
通过本次实践任务,进一步加深了我对爬取网页信息实践过程的理解,也让我掌握了更多与爬虫相关库方法的使用,懂得如何运用相应的方法和步骤爬取并保存网站上的图片,也提高了个人的编程实践能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号