

Hadoop安装 与 HDFS体系结构
HDFS结构
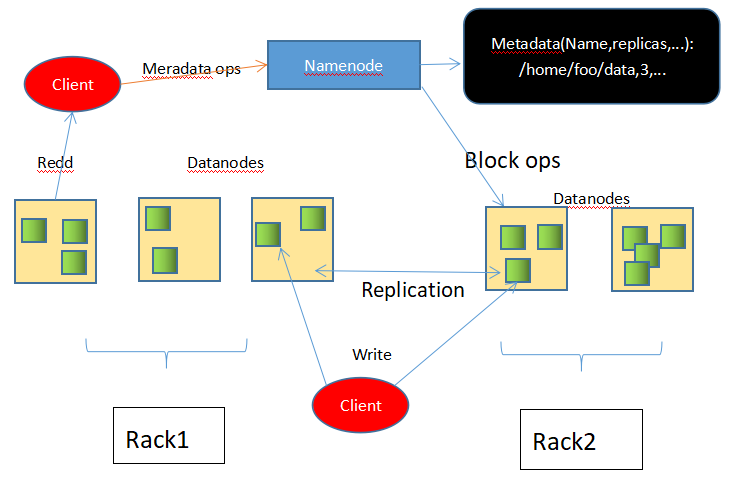
HDFS 采用Master/Slave的架构来存储数据,这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。一个HDFS集群是由一个NameNode和一定数目的DataNode组成的。NameNode是一个中心服务器,负责管理文件系统的名字空间 (Namespace )及客户端对文件的访问。集群中的DataNode一般是一个节点运行一个DataNode进程,负责管理它所在节点上的存储。
HDFS工作原理和流程
HDFS是一个文件系统,用于存储和管理文件,通过统一的命名空间(类似于本地文件系统的目录树)。HDFS是分布式的系统,服务器集群中各个节点都有自己的角色和职责。理解HDFS,需要注意以下几个概念:
1,HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数(
dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,之前的版本中是64M。
2,HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
3,目录结构及文件分块位置信息(元数据)的管理由namenode节点承担,namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的数据块信息(blockid及所在的datanode服务器)
4,文件的各个block的存储管理由datanode节点承担,datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication,默认是3)
5,Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量,HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行。
6,HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改。需要频繁的RPC交互,写入性能不好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号