

Hadoop演进与Hadoop生态
1.了解对比Hadoop不同版本的特性,可以用图表的形式呈现。
DKhadoop发行版:有效的集成了整个HADOOP生态系统的全部组件,并深度优化,重新编译为一个完整的更高性能的大数据通用计算平台,实现了各部件的有机协调。因此DKH相比开源的大数据平台,在计算性能上有了高达5倍(最大)的性能提升。DKhadoop将复杂的大数据集群配置简化至三种节点(主节点、管理节点、计算节点),极大的简化了集群的管理运维,增强了集群的高可用性、高可维护性、高稳定性。
cloudera发行版:CDH是Cloudera的hadoop发行版,完全开源,比Apache hadoop在兼容性,安全性,稳定性上有增强。Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对hadoop的技术支持。
hortonworks发行版:Hortonworks 的主打产品是Hortonworks Data Platform (HDP),也同样是100%开源的产品,其版本特点:HDP包括稳定版本的Apache Hadoop的所有关键组件;安装方便,HDP包括一个现代化的,直观的用户界面的安装和配置工具。
MAPR发行版:mapR有免费和商业两个版本,免费版本在功能上有所减少。mapR版本不再需要单独的namenode机器,元数据分散在集群中,也类似数据默认存储三份。也不再需要用NAS来协助namenode做元数据备份,提供了机器使用率。
华为hadoop发行版:华为的hadoop版本基于自研的Hadoop HA平台,构建NameNode、JobTracker、HiveServer的HA功能,进程故障后系统自动Failover,无需人工干预,这个也是对hadoop的小修补,远不如mapR解决的彻底。
2.Hadoop生态的组成、每个组件的作用、组件之间的相互关系,以图例加文字描述呈现。
Hadoop生态圈
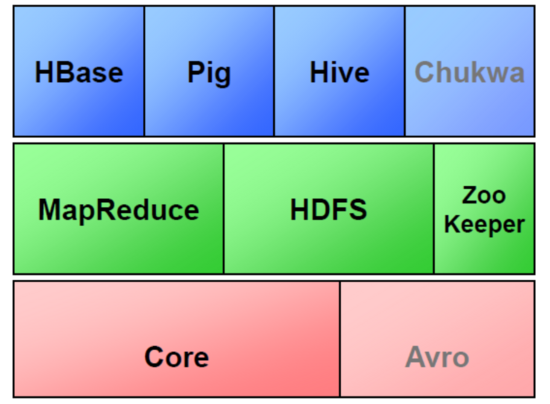
①HBase
Google Bigtable的开源实现
列式数据库
可集群化
可以使用shell、web、api等多种方式访问
适合高读写(insert)的场景
HQL查询语言
NoSQL的典型代表产品
②Hive
数据仓库工具。可以把Hadoop下的原始结构化数据变成Hive中的表
支持一种与SQL几乎完全相同的语言HiveQL。除了不支持更新、索引和事务,几乎SQL的其它特征都能支持
可以看成是从SQL到Map-Reduce的映射器
提供shell、JDBC/ODBC、Thrift、Web等接口
③Zookeeper
Google Chubby的开源实现
用于协调分布式系统上的各种服务。例如确认消息是否准确到达,防止单点失效,处理负载均衡等
应用场景:Hbase,实现Namenode自动切换
工作原理:领导者,跟随者以及选举过程
④Sqoop
用于在Hadoop和关系型数据库之间交换数据
通过JDBC接口连入关系型数据
⑤Chukwa
架构在Hadoop之上的数据采集与分析框架
主要进行日志采集和分析
通过安装在收集节点的“代理”采集最原始的日志数据
代理将数据发给收集器
收集器定时将数据写入Hadoop集群
指定定时启动的Map-Reduce作业队数据进行加工处理和分析
⑥Pig
Hadoop客户端
使用类似于SQL的面向数据流的语言Pig Latin
Pig Latin可以完成排序,过滤,求和,聚组,关联等操作,可以支持自定义函数
Pig自动把Pig Latin映射为Map-Reduce作业上传到集群运行,减少用户编写Java程序的苦恼
⑦Avro
数据序列化工具,由Hadoop的创始人Doug Cutting主持开发
用于支持大批量数据交换的应用。支持二进制序列化方式,可以便捷,快速地处理大量数据
动态语言友好,Avro提供的机制使动态语言可以方便地处理 Avro数据。
Thrift接口
⑧Cassandra
NoSQL,分布式的Key-Value型数据库,由Facebook贡献
与Hbase类似,也是借鉴Google Bigtable的思想体系
只有顺序写,没有随机写的设计,满足高负荷情形的性能需求
3.官网学习Hadoop的安装与使用,用文档的方式列出步骤与注意事项。
找到hadoop2.6版本 cdh5.14.2左右的就可以,找一个专门放压缩文件的文件夹开始解压
tar -zxf hadoop-2.6.0-cdh5.14.2.tar.gz
解压完后可以重命名便于记忆,在这里就叫hadoop260
mv hadoop-2.6.0-cdh5.14.2 hadoop260
接下来就是要开始配置环境变量:
hadoop260/etc/hadoop下都是hadoop的配置文件,在hadoop-env.sh找java环境变量,把路径改成你的jdk路径
vi hadoop-env.sh
配置core-site.xml,在里面配置4组
vi core-site.xml
设置副本个数,最少3个,这里因为是举例就设置成1个,也是在里面配置
vi hdfs-site.xml
拷贝一份mapred-site.xml.template配置文件到mapred-site.xml
更改mapred-site.xml中配置文件,同样在里面配置
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
配置resourcemanager站点名称和nodemanager 辅助节点管理
vi yarn-site.xml
配置hadoop的环境变量
vi /etc/profile
export HADOOP_HOME=/opt/hadoop260
export HADOOP_MAPRED_HOME=$ HADOOP_HOME
export HADOOP_COMMON_HOME=$ HADOOP_HOME
export HADOOP_HDFS_HOME=$ HADOOP_HOME
export YARN_HOME=$ HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$ HADOOP_HOME/lib/native
export PATH=$ PATH:$ HADOOP_HOME/sbin:$ HADOOP_HOME/bin
export HADOOP_INSTALL=$ HADOOP_HOME
激活配置文件
source /etc/profile
格式化格式化NameNode
hadoop namenode -format
启动
start-all.sh
这时会提示输入密码的情况,当正确输入密码的时候,可能需要多输入几次,去开启一个个进程
查看配置的文件是否生效,查看进程情况
当出现上图的5个进程时,表示启动成功,当然除了jps时,
去网站输入虚拟机的地址,端口号是50070,查看是否能显示网址
http://192.168.xx.xxx:50070
4.评估华为hadoop发行版本的特点与可用性。
华为在硬件上具有天然的优势,在网络、虚拟化、PC等方面都有很强的硬件实力。华为的Hadoop版本基于自主研发的Hadoop HA平台,具有构建NameNode、JobTracker、HiveServer的HA功能,进程故障后系统自动进行Failover,无须人工干预,这也是对Hadoop功能不足的小修补,远不如MapR解决得彻底。华为在Hadoop社区中的Contributor和Committer也是国内最多的,算是国内技术实力较强的公司。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号