
爬取新浪新闻国际新闻分享数排名
(一)、选题的背景
新浪新闻是新浪集团旗下的智能信息平台,致力于利用大数据和人工智能技术,为用户提供更丰富、场景化和个性化的内容阅读体验。新浪新闻与微博打通了双平台的内容、数据和账号体系,为用户提供全网资讯、热点要闻、深度精选、精彩视频、高清图集等精彩内容。
截至2021年8月,数据显示,新浪新闻MAU达到1.46亿,DAU突破8300万,实现连续22个季度的高速增长,稳居行业前三。
(二)、主题式网络爬虫设计方案(10 分)
1.主题式网络爬虫名称
爬取新浪新闻国际新闻分享数排名
2.主题式网络爬虫爬取的内容与数据特征分析
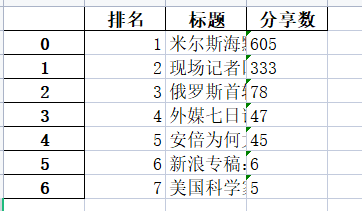
对国际新闻分享数排行榜进行爬取“排名”,“标题”,“分享数”
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
(三)、主题页面的结构特征分析(10 分)

2.Htmls 页面解析
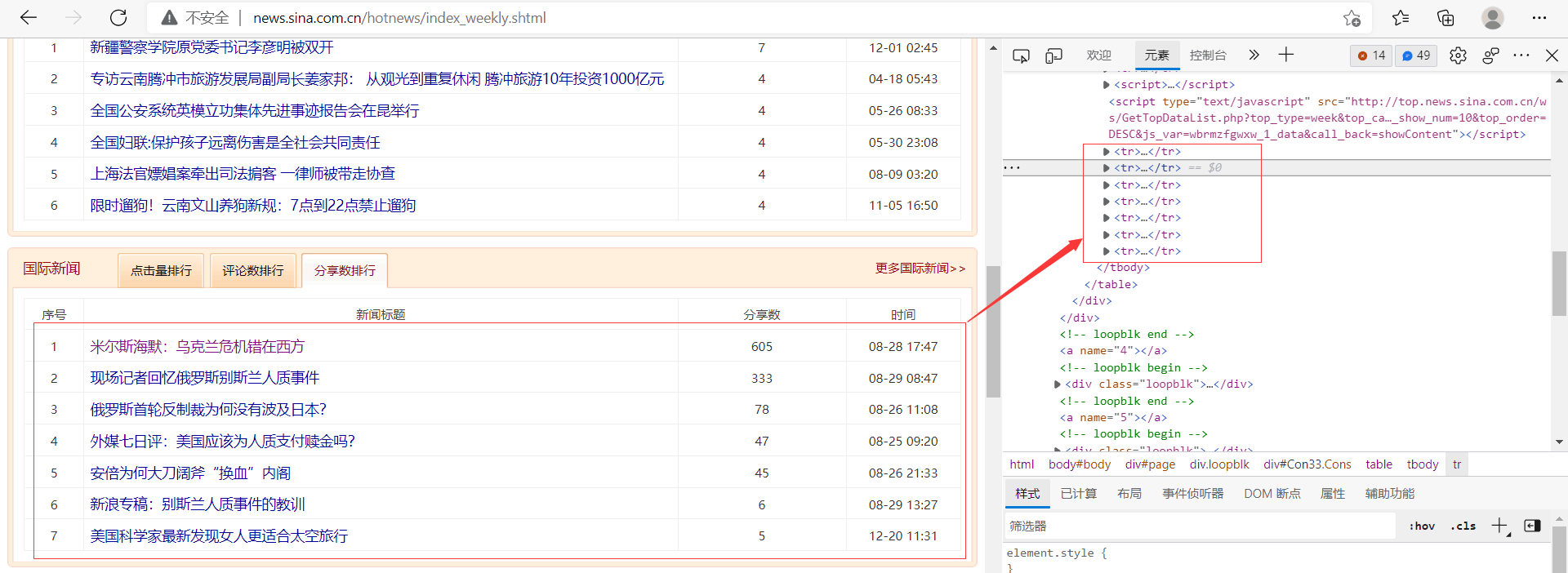

3.节点(标签)查找方法与遍历方
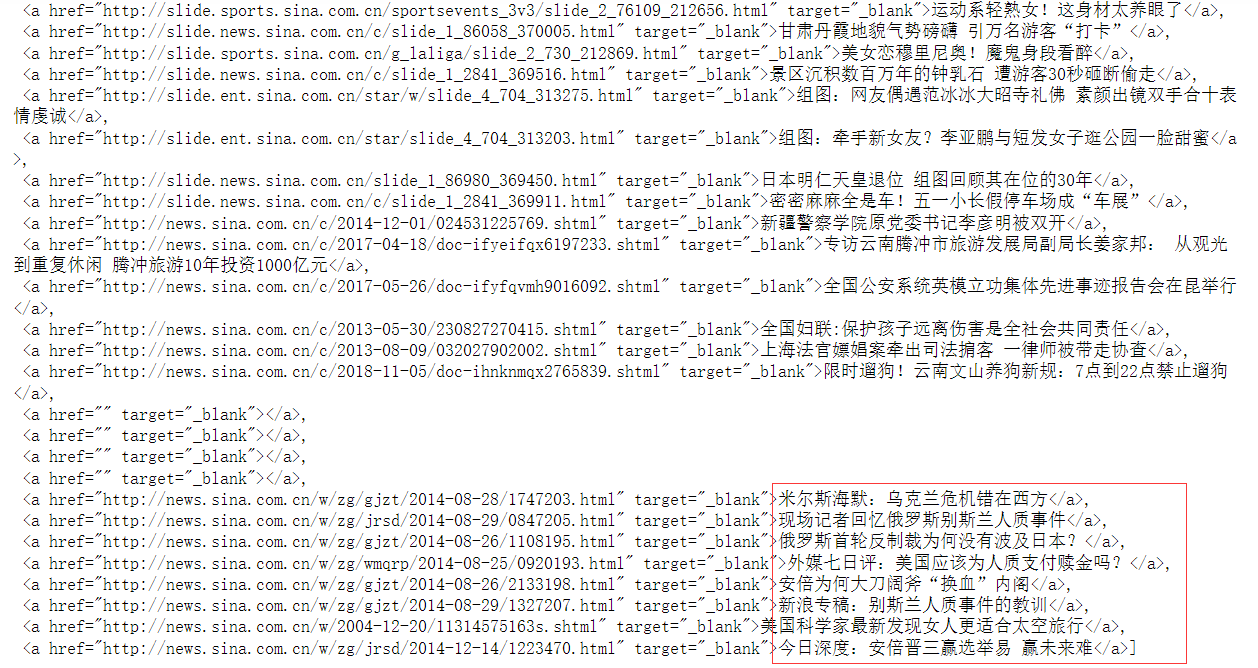
(必要时画出节点树结构)
(四)、网络爬虫程序设计(60 分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后
面提供输出结果的截图。
1.数据爬取与采集
1 #导入相关库 2 import requests 3 #引入pandas用于数据可视化 4 import pandas as pd 5 import numpy as np 6 import matplotlib.pyplot as plt 7 import matplotlib 8 import csv 9 import scipy as sp 10 import seaborn as sns 11 from sklearn.linear_model import LinearRegression 12 from bs4 import BeautifulSoup 13 from pandas import DataFrame 14 from scipy.optimize import leastsq 15 #搜索网址 16 url='http://news.sina.com.cn/hotnews/index_weekly.shtml' 17 #伪装爬虫 18 headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62'} 19 r = requests.get(url, headers=headers,timeout=10) 20 21 def getHTMLText(url,timeout = 30): 22 try: 23 #用requests抓取网页信息 24 r = requests.get(url, timeout = 30) 25 #可以让程序产生异常时停止程序 26 r.raise_for_status() 27 #设置编码标准 28 r.encoding = r.apparent_encoding 29 return r.text 30 except: 31 return '产生异常' 32 33 34 #统一编码 35 html=r.text 36 #html.parser表示用BeautifulSoup库解析网页 37 soup=BeautifulSoup(html,'html.parser') 38 #基于bs4库HTML的格式输出,让页面更友好的显示 39 print(soup.prettify())
1 #爬取数据 2 #爬取排行 3 c=[] 4 for i in soup.find_all('td',class_='')[698:717:3]: 5 c.append(i.get_text().strip()) 6 7 print(c) 8 9 #爬取分享数 10 11 a=[] 12 for i in soup.find_all('td',class_='')[698:717:3]: 13 a.append(i.get_text().strip()) 14 15 print(a) 16 17 #爬取标题名 18 b=[] 19 for i in soup.find_all('a',class_='')[344:352]: 20 b.append(i.get_text().strip()) 21 22 print(b)
1 #将数据整理成表格 2 import pandas as pd 3 num=7 4 5 print('{:^5}\t{:^40}\t{:^20}'.format('排名', '标题', '分享数')) 6 7 lst=[] 8 for i in range(num): 9 print('{:^5}\t{:^40}\t{:^20}'.format(i+1, b[i], a[i])) 10 lst.append([i+1,b[i],a[i]]) 11 12 df = pd.DataFrame(lst,columns=['排名','标题','分享数']) 13 14 #将表格存入excel表中 15 rank = r'rank.xlsx' 16 df.to_excel(rank)

2.对数据进行清洗和处理
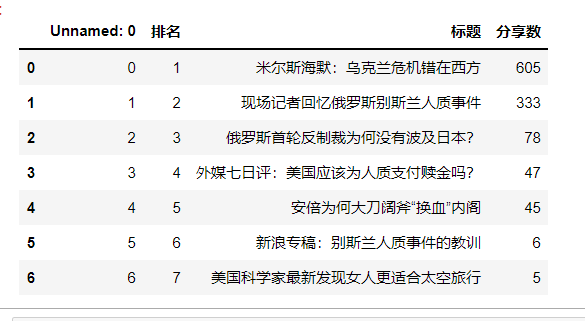
1 #读取excel表
2 df=pd.DataFrame(pd.read_excel('rank.xlsx'))
3 print(df)
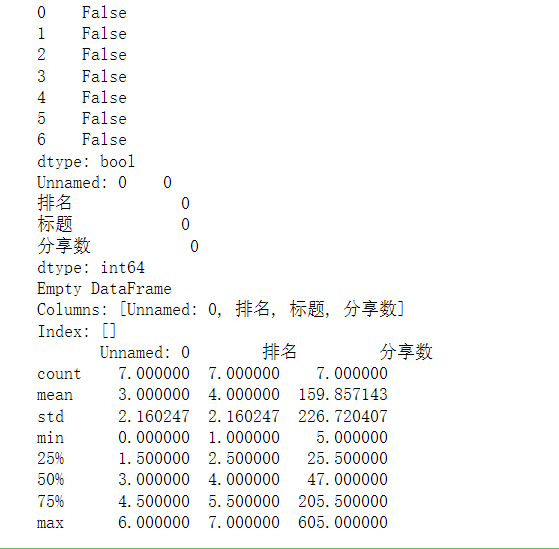
1 #数据清洗 2 3 #重复值确认 4 print(df.duplicated()) 5 6 #统计空值 7 print(df.isnull().sum()) #返回0则没有空值 8 9 #缺失值处理 10 print(df[df.isnull().values==True]) #返回无缺失值 11 12 #用describe()命令显示描述性统计指标 13 print(df.describe())
3.文本分析(可选):jieba 分词、wordcloud 的分词可视化
4.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图)
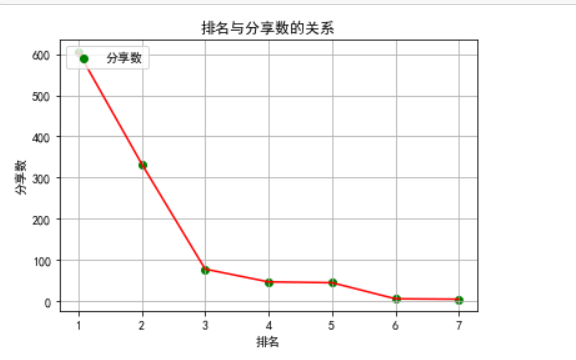
1 #绘制折线图 2 import numpy as np 3 import pandas as pd 4 import matplotlib.pyplot as plt 5 plt.rcParams['font.sans-serif'] = ['SimHei'] 6 # 用来正常显示中文标签 7 plt.rcParams['axes.unicode_minus'] = False 8 # 用来正常显示负号 9 plt.plot(df['排名'],df['分享数'],'r') 10 plt.scatter(df['排名'],df['分享数'],color="green",label='分享数') 11 plt.ylabel('分享数') 12 plt.xlabel('排名') 13 plt.title('排名与分享数的关系') 14 plt.grid() 15 plt.legend(loc=2) 16 plt.show()
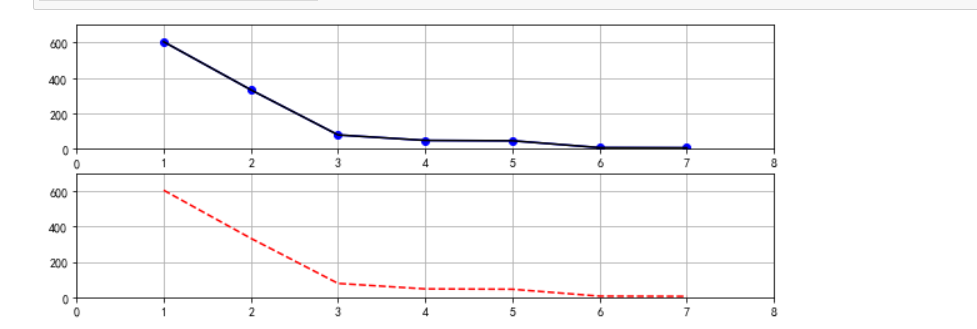
1 #绘制折线图 2 import numpy as np 3 import pandas as pd 4 import matplotlib.pyplot as plt 5 x=df['排名'] 6 y=df['分享数'] 7 plt.figure(figsize=[10,4]) 8 9 plt.subplot(2,1,1) 10 plt.plot(x,y,color='blue', marker='o') 11 plt.plot(x,y , color='black') 12 plt.axis((0, 8, 0,700)) 13 plt.grid() 14 15 plt.subplot(2,1,2) 16 plt.plot(x,y,'r--') 17 plt.axis((0, 8, 0,700)) 18 plt.grid() 19 plt.show()
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变
量之间的回归方程(一元或多元)。
1 #构建数据分析模型 2 3 import numpy as np 4 import pandas as pd 5 import sklearn 6 from sklearn import datasets 7 from sklearn.linear_model import LinearRegression 8 X = df[["排名"]] 9 predict_model = LinearRegression() 10 predict_model.fit(X, df[['分享数']]) 11 12 print("回归系数为{}".format(predict_model.coef_)) 13 print("回归方程截距:{}".format(predict_model.intercept_))

1 #选择排名和热度两个特征变量,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线 2 colnames=[" ","排名","分享数"] 3 df=pd.DataFrame(pd.read_excel('rank.xlsx')) 4 X = df.排名 5 Y = df.分享数 6 def A(): 7 plt.scatter(X,Y,color="blue",linewidth=2) 8 plt.title("分析图",color="blue") 9 plt.grid() 10 plt.show() 11 def B(): 12 plt.scatter(X,Y,color="green",linewidth=2) 13 plt.title("分析图",color="blue") 14 plt.grid() 15 plt.show() 16 def func(p,x): 17 a,b,c=p 18 return a*x*x+b*x+c 19 def error(p,x,y): 20 return func(p,x)-y 21 def main(): 22 plt.figure(figsize=(10,6)) 23 p0=[0,0,0] 24 Para = leastsq(error,p0,args=(X,Y)) 25 a,b,c=Para[0] 26 print("a=",a,"b=",b,"c=",c) 27 plt.scatter(X,Y,color="blue",linewidth=2) 28 x=np.linspace(0,20,20) 29 y=a*x*x+b*x+c 30 plt.plot(x,y,color="blue",linewidth=2,) 31 plt.title("分析图") 32 plt.grid() 33 plt.show() 34 print(A()) 35 print(B()) 36 print(main())
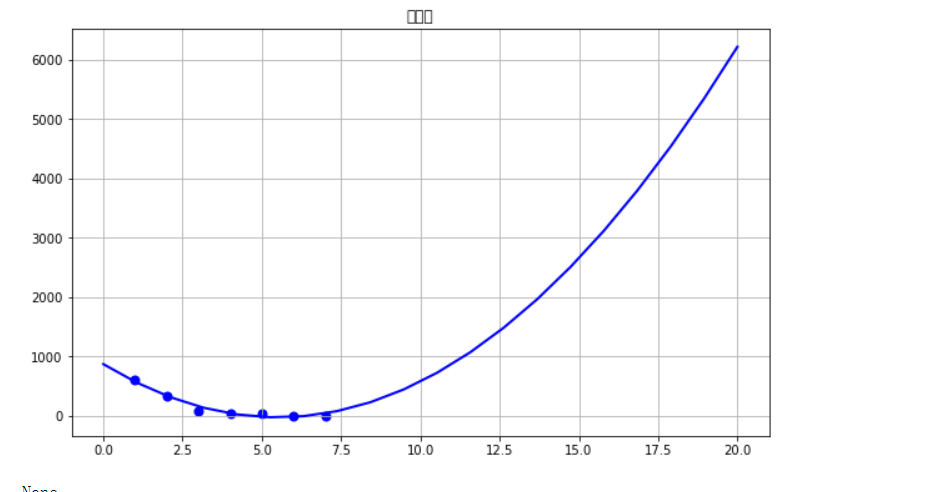
6.数据持久化
1 #数据持久化 2 3 rank = r'rank.xlsx' 4 df.to_excel(rank)
7.将以上各部分的代码汇总,附上完整程序代码
1 #导入相关库 2 import requests 3 #引入pandas用于数据可视化 4 import pandas as pd 5 import numpy as np 6 import matplotlib.pyplot as plt 7 import matplotlib 8 import csv 9 import scipy as sp 10 import seaborn as sns 11 from sklearn.linear_model import LinearRegression 12 from bs4 import BeautifulSoup 13 from pandas import DataFrame 14 from scipy.optimize import leastsq 15 #搜索网址 16 url='http://news.sina.com.cn/hotnews/index_weekly.shtml' 17 #伪装爬虫 18 headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62'} 19 r = requests.get(url, headers=headers,timeout=10) 20 21 def getHTMLText(url,timeout = 30): 22 try: 23 24 #用requests抓取网页信息 25 r = requests.get(url, timeout = 30) 26 #可以让程序产生异常时停止程序 27 r.raise_for_status() 28 #设置编码标准 29 30 r.encoding = r.apparent_encoding 31 return r.text 32 33 except: 34 35 return '产生异常' 36 37 38 #统一编码 39 40 html=r.text 41 #html.parser表示用BeautifulSoup库解析网页 42 soup=BeautifulSoup(html,'html.parser') 43 #基于bs4库HTML的格式输出,让页面更友好的显示 44 print(soup.prettify()) 45 46 47 #爬取数据 48 49 #爬取排行 50 c=[] 51 for i in soup.find_all('td',class_='')[698:717:3]: 52 c.append(i.get_text().strip()) 53 54 print(c) 55 56 #爬取分享数 57 58 a=[] 59 for i in soup.find_all('td',class_='')[698:717:3]: 60 a.append(i.get_text().strip()) 61 62 print(a) 63 64 #爬取标题名 65 66 b=[] 67 for i in soup.find_all('a',class_='')[344:352]: 68 b.append(i.get_text().strip()) 69 70 print(b) 71 72 #将数据整理成表格 73 74 import pandas as pd 75 num=7 76 77 print('{:^5}\t{:^40}\t{:^20}'.format('排名', '标题', '分享数')) 78 79 lst=[] 80 for i in range(num): 81 print('{:^5}\t{:^40}\t{:^20}'.format(i+1, b[i], a[i])) 82 lst.append([i+1,b[i],a[i]]) 83 84 df = pd.DataFrame(lst,columns=['排名','标题','分享数']) 85 86 #将表格存入excel表中 87 88 rank = r'rank.xlsx' 89 df.to_excel(rank) 90 91 #读取excel表 92 93 df=pd.DataFrame(pd.read_excel('rank.xlsx')) 94 print(df) 95 96 #数据清洗 97 98 #重复值确认 99 100 print(df.duplicated()) 101 102 #统计空值 103 104 print(df.isnull().sum()) #返回0则没有空值 105 106 ##缺失值处理 107 108 print(df[df.isnull().values==True]) #返回无缺失值 109 110 ##用describe()命令显示描述性统计指标 111 print(df.describe()) 112 113 #绘制折线图 114 115 import numpy as np 116 import pandas as pd 117 import matplotlib.pyplot as plt 118 plt.rcParams['font.sans-serif'] = ['SimHei'] 119 120 # 用来正常显示中文标签 121 122 plt.rcParams['axes.unicode_minus'] = False 123 124 # 用来正常显示负号 125 126 plt.plot(df['排名'],df['分享数'],'r') 127 plt.scatter(df['排名'],df['分享数'],color="green",label='分享数') 128 plt.ylabel('分享数') 129 plt.xlabel('排名') 130 plt.title('排名与分享数的关系') 131 plt.grid() 132 plt.legend(loc=2) 133 plt.show() 134 135 #绘制折线图 136 137 import numpy as np 138 import pandas as pd 139 import matplotlib.pyplot as plt 140 x=df['排名'] 141 y=df['分享数'] 142 plt.figure(figsize=[10,4]) 143 144 plt.subplot(2,1,1) 145 plt.plot(x,y,color='blue', marker='o') 146 plt.plot(x,y , color='black') 147 plt.axis((0, 8, 0,700)) 148 plt.grid() 149 150 plt.subplot(2,1,2) 151 plt.plot(x,y,'r--') 152 plt.axis((0, 8, 0,700)) 153 plt.grid() 154 plt.show() 155 156 #构建数据分析模型 157 158 import numpy as np 159 import pandas as pd 160 import sklearn 161 from sklearn import datasets 162 from sklearn.linear_model import LinearRegression 163 X = df[["排名"]] 164 predict_model = LinearRegression() 165 predict_model.fit(X, df[['分享数']]) 166 167 print("回归系数为{}".format(predict_model.coef_)) 168 print("回归方程截距:{}".format(predict_model.intercept_)) 169 170 #选择排名和热度两个特征变量,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线 171 colnames=[" ","排名","分享数"] 172 df=pd.DataFrame(pd.read_excel('rank.xlsx')) 173 X = df.排名 174 Y = df.分享数 175 def A(): 176 plt.scatter(X,Y,color="blue",linewidth=2) 177 plt.title("分析图",color="blue") 178 plt.grid() 179 plt.show() 180 def B(): 181 plt.scatter(X,Y,color="green",linewidth=2) 182 plt.title("分析图",color="blue") 183 plt.grid() 184 plt.show() 185 def func(p,x): 186 a,b,c=p 187 return a*x*x+b*x+c 188 def error(p,x,y): 189 return func(p,x)-y 190 def main(): 191 plt.figure(figsize=(10,6)) 192 p0=[0,0,0] 193 Para = leastsq(error,p0,args=(X,Y)) 194 a,b,c=Para[0] 195 print("a=",a,"b=",b,"c=",c) 196 plt.scatter(X,Y,color="blue",linewidth=2) 197 x=np.linspace(0,20,20) 198 y=a*x*x+b*x+c 199 plt.plot(x,y,color="blue",linewidth=2,) 200 plt.title("分析图") 201 plt.grid() 202 plt.show() 203 print(A()) 204 print(B()) 205 print(main()) 206 207 #数据持久化 208 209 rank = r'rank.xlsx' 210 df.to_excel(rank)
(五)、总结(10 分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
通过对数据的分析,我们可以得到新浪新闻网在国际新闻的关注上差别会很大,然而并没有达到预期目标,并不知道为什么会有如此大的差异。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
在完成此次设计的途中可谓是九九八十一难,无论是网站爬取,图表制作还是数据分析,都出现过大大小小的问题。例如在寻找要爬取的网站时,曾因为无法找到相关信息,出现乱码等,不得不反反复复更换十来个网站进行爬取。在设计过程中,我收获到了如何编写爬虫程序,如何把网页想要爬取的内容提取出来,怎么画出自己想要的图像。改进的地方可能是编写代码经验不足吧,写代码的时候比较吃力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号