机器学习-多项式回归+过拟合&欠拟合的处理
由一个案例引出
-
房地产估价数据集数据集(house.xlsx)
- 数据集信息:
- 房地产估值的市场历史数据集来自台湾新北市新店区。“房地产估价” 是一个回归问题。
-
属性信息:
-
输入如下:
- X1 =交易日期(例如,2013.250 = 2013年3月,2013.500 = 2013年6月,等等)
- X2 =房屋年龄(单位:年)
- X3 =到最近的捷运站的距离(单位:米) )
- X4 =步行生活圈中的便利店的数量(整数)
- X5 =地理坐标,纬度。(单位:度)
- X6 =地理坐标,经度。(单位:度)
-
输出结果如下:
- Y =单位面积的房价(10000新台币/ Ping,其中Ping是本地单位,1 Ping = 3.3米平方)
-
- 数据集信息:
from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split import pandas as pd from sklearn.metrics import mean_squared_error as MSE df = pd.read_excel('./datasets/house.xlsx') df = df.drop(labels='No',axis=1) df.head()

feature = df.loc[:,df.columns != 'Y house price of unit area'] target = df['Y house price of unit area'] x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2020) linner = LinearRegression() linner.fit(x_train,y_train) y_pred = linner.predict(x_test)
MSE(y_test,y_pred)
55.33406050090903
y_test.max(),y_test.min()
(63.2, 13.8)
linner.score(x_test,y_test)
0.6108181277767377
采用MES对数据做预测发现均方误差很大,模型评分很低
- 上述模型出现的问题:训练好的模型没有很好的拟合到原始的样本数据中标签和特征值之间的线性关系。
- 多项式回归可以处理上述案例出现的欠拟合问题
feature = df.loc[:,df.columns != 'Y house price of unit area'] target = df['Y house price of unit area'] #给原始特征增加高次项特征 from sklearn.preprocessing import PolynomialFeatures p = PolynomialFeatures(degree=2) d_2_feature = p.fit_transform(feature) x_train,x_test,y_train,y_test = train_test_split(d_2_feature,target,test_size=0.2,random_state=2020) linner = LinearRegression().fit(x_train,y_train) y_pred = linner.predict(x_test) MSE(y_test,y_pred) 30.830183307250028 linner.score(x_test,y_test) 0.7831616123616155
采用了多项式回归 发现均方误差小了 模型频分也高了
- 再试下3次项,看误差会不会更小
#给原始特征增加高次项特征 from sklearn.preprocessing import PolynomialFeatures p = PolynomialFeatures(degree=3) d_2_feature = p.fit_transform(feature) x_train,x_test,y_train,y_test = train_test_split(d_2_feature,target,test_size=0.2,random_state=2020) linner = LinearRegression().fit(x_train,y_train) y_pred = linner.predict(x_test) MSE(y_test,y_pred) 34.36996146905075
发现 均方误差相对2次项的误差大了 说明三次项不如二次项
- 问题:训练好的模型在训练集上表现的预测效果很好,但是在测试集上却有很大的问题和误差,why?
- 案例1:
- 现在有一组天鹅的特征数据然后对模型进行训练,然后模型学习到的内容是有翅膀,嘴巴长的就是天鹅。然后使用模型进行预测,该模型可能会将所有符合这两个特征的动物都预测为天鹅,则肯定会有误差的,因为鹦鹉,秃鹫都符合有翅膀和嘴巴长的特征。
- 原因:模型学习到的天鹅的特征太少了,导致区分标准太粗糙,不能准确的识别出天鹅。
- 现在有一组天鹅的特征数据然后对模型进行训练,然后模型学习到的内容是有翅膀,嘴巴长的就是天鹅。然后使用模型进行预测,该模型可能会将所有符合这两个特征的动物都预测为天鹅,则肯定会有误差的,因为鹦鹉,秃鹫都符合有翅膀和嘴巴长的特征。
- 案例2:
- 更新了样本的特征数据了,增加了一些特征,然后训练模型。模型这次学习到的内容是,有翅膀、嘴巴长、白色、体型像2、脖子长且有弯度的就是天鹅。然后开始使用模型进行预测,现在一组测试数据为鹦鹉,因为鹦鹉的体型小,脖子短不符合天鹅的特征,则预测结果为不是天鹅。然后又有一组特征为黑天鹅,结果因为颜色不是白色,预测成了黑天鹅。
- 原因:现在模型学习到的特征已经基本可以区分天鹅和其他动物了。但是学习到的特征中有一项是羽毛是白色,那么就会导致将黑天鹅无法识别出来。也就是机器学习到的特征太依赖或者太符合训练数据了。
- 更新了样本的特征数据了,增加了一些特征,然后训练模型。模型这次学习到的内容是,有翅膀、嘴巴长、白色、体型像2、脖子长且有弯度的就是天鹅。然后开始使用模型进行预测,现在一组测试数据为鹦鹉,因为鹦鹉的体型小,脖子短不符合天鹅的特征,则预测结果为不是天鹅。然后又有一组特征为黑天鹅,结果因为颜色不是白色,预测成了黑天鹅。
- 案例1:
- 欠拟合&&过拟合:
- 欠拟合:案例1中的场景就可以表示欠拟合(表现特征:在训练集和测试集中表现的都不好)
- 一个假设在训练数据上不能获得很好的拟合,但是在训练数据以外的数据集上也不能很好的拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
- 过拟合:案例2中的场景就可以表示过拟合(表现特征:在训练集表现不错,在测试集表现差)
- 一个假设在训练数据上能够获得比其他假设更好的拟合,但是在训练数据以外的数据集上却不能很好的拟合数据,此时认为这个假设出现了过拟合现象。(模型过于复杂)
- 欠拟合:案例1中的场景就可以表示欠拟合(表现特征:在训练集和测试集中表现的都不好)

- 欠拟合和过拟合的解决
- 欠拟合:
- 原因:模型学习到样本的特征太少
- 解决:增加样本的特征数量(多项式回归)
- 过拟合:
- 原因:原始特征过多,存在一些嘈杂特征。
- 解决:
- 进行特征选择,消除关联性大的特征(很难做)
- 正则化之岭回归(掌握)
- 欠拟合:
- 模型的复杂度--》回归出直线or曲线:
- 我们的回归模型最终回归出的一定是直线吗(y=wx+b)?有没有可能是曲线(非线性)呢(y=wx**2+b)?
- 我们都知道回归模型算法就是在寻找特征值和目标值之间存在的某种关系,那么这种关系越复杂则表示训练出的模型的复杂度越高,反之越低。
- 模型的复杂度是由特征和目标之间的关系导致的!特征和目标之间的关系不仅仅是线性关系!
- 我们的回归模型最终回归出的一定是直线吗(y=wx+b)?有没有可能是曲线(非线性)呢(y=wx**2+b)?
欠拟合的处理:多项式回归
- 为了解决欠拟合的情 经常要提高线性的次数(高次多项式)建立模型拟合曲线,次数过高会导致过拟合,次数不够会欠拟合。
- y = w*x + b 一次多项式函数
- y = w1x^2 + w2x + b 二次多项式函数
- y = w1x^3 + w2x^2 + w3*x + b 三次多项式函数
- 。。。
- 高次多项式函数的表示为曲线
- 相对于线性回归模型y=wx+b只能解决线性(回归出的为直线)问题,多项式回归能够解决非线性回归(回归出的为曲线)问题。
- 拿最简单的线性模型来说,其数学表达式可以表示为:y=wx+b,它表示的是一条直线,而多项式回归则可以表示成:y=w1x∧2+w2x+b,它表示的是二次曲线,
实际上,多项式回归可以看成特殊的线性模型
,即把x∧2看成一个特征,把x看成另一个特征,这样就可以表示成y=w1z+w2x+b,其中z=x∧2,这样多项式回归实际上就变成线性回归了。 - 其中的y=w1x∧2+w2x+b就是所谓的二次多项式:aX∧2+bX+c(a≠0).
- 当然还可以将y=wx+b转为更高次的多项式。是否需要转成更高次的多项式取决于我们想要拟合样本的程度了,更高次的多项式可以更好的拟合我们的样本数据,但是也不是一定的,很可能会造成过拟合。
示例
- 下面模拟 根据蛋糕的直径大小 预测蛋糕价格
from sklearn.linear_model import LinearRegression import numpy as np import matplotlib.pyplot as plt # 样本的训练数据,特征和目标值 x_train = [[6], [8], [10], [14], [18]] #大小 y_train = [[7], [9], [13], [17.5], [18]]#价格 linner = LinearRegression() linner.fit(x_train,y_train) y_pred = linner.predict(x_train) plt.scatter(x_train,y_train) plt.plot(x_train,y_pred) plt.xlabel('size_x') plt.ylabel('price_y')
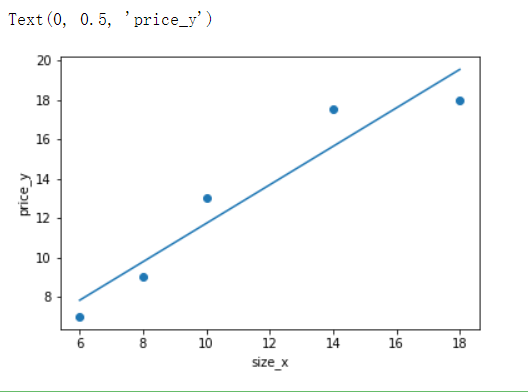
建立二次多项式线性回归模型进行预测
- 根据二次多项式公式可知,需要给原始特征添加更高次的特征数据x^2.
- y=w1x∧2+w2x+b
- 如何给样本添加高次的特征数据呢?
- 使用sklearn.preprocessing.PolynomialFeatures来进行更高次特征的构造
- 它是使用多项式的方法来进行的,如果有a,b两个特征,那么它的2次多项式为(1,a,b,a^2,ab, b^2)
- PolynomialFeatures有三个参数
- degree:控制多项式的度
- interaction_only: 默认为False,如果指定为True,上面的二次项中没有a^2和b^2。
- include_bias:默认为True。如果为False的话,那么就不会有上面的1那一项
- 使用sklearn.preprocessing.PolynomialFeatures来进行更高次特征的构造
#工具类的基本使用 from sklearn.preprocessing import PolynomialFeatures p = PolynomialFeatures(degree=2) p.fit_transform([[3,5]]) array([[ 1., 3., 5., 9., 15., 25.]]) #如果训练效果差了 可以试着去掉1 #建立2次多项式线性回归模型进行预测 p = PolynomialFeatures(degree=2) d_2_train = p.fit_transform(x_train) linner = LinearRegression().fit(d_2_train,y_train) y_pred = linner.predict(d_2_train) plt.scatter(x_train,y_train) plt.plot(x_train,y_pred) plt.xlabel('size_x') plt.ylabel('price_y')
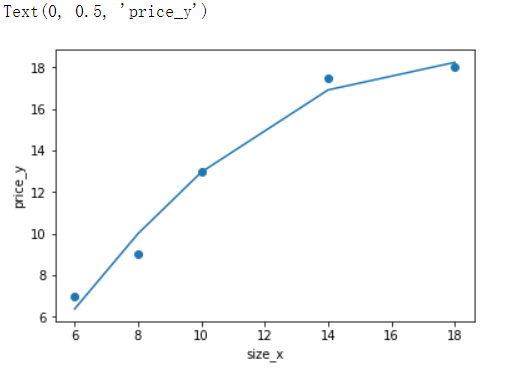
#建立3次多项式线性回归模型进行预测
p = PolynomialFeatures(degree=3)
d_3_train = p.fit_transform(x_train)
linner = LinearRegression().fit(d_3_train,y_train)
y_pred = linner.predict(d_3_train)
plt.scatter(x_train,y_train)
plt.plot(x_train,y_pred)
plt.xlabel('size_x')
plt.ylabel('price_y')
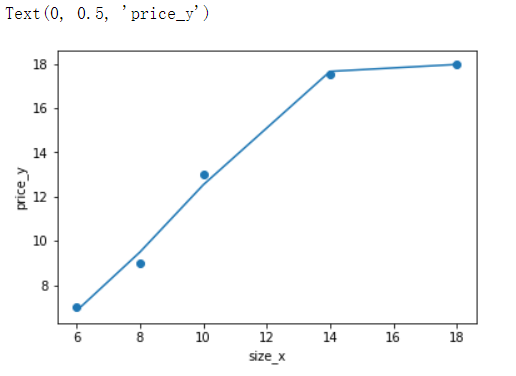
过拟合处理:正则化
- 将过拟合的曲线的凹凸幅度减少就可以将过拟合曲线趋近于拟合曲线了。那么过拟合曲线的凹凸肯定是由y=wx**2+x**3+x**4中的高次项导致的,那么正则化就可以通过不断的尝试发现高次项的特征然后这些特征的权重w调小到0,则高次项的特征没有了,那么凹凸幅度就减少了,就越趋近于拟合曲线了!
- 可以使得高次项的w权重减小,趋近于0.
- LinnerRegression是没有办法进行正则化的,所以该算法模型容易出现过拟合,并且无法解决。
- L2正则化:
- 使用带有正则化算法的回归模型(Ridge岭回归)处理过拟合的问题。
Ridge岭回归:具备L2正则化的线性回归模型
- API:from sklearn.linear_model import Ridge
- Ridge(alpha=1.0):
- alpha:正则化的力度,力度越大,则表示高次项的权重w越接近于0,导致过拟合曲线的凹凸幅度越小。
- 取值:0-1小数或者1-10整数
- coef_:回归系数
- alpha:正则化的力度,力度越大,则表示高次项的权重w越接近于0,导致过拟合曲线的凹凸幅度越小。
使用岭回归可以通过控制正则化力度参数alpha降低高次项特征的权重
岭回归的优点:
- 获取的回归系数更符合实际更可靠
- 在病态数据(异常值多的数据)偏多的研究中有更大的存在意义
from sklearn.linear_model import Ridge from sklearn.linear_model import LinearRegression import numpy as np import matplotlib.pyplot as plt from sklearn.preprocessing import PolynomialFeatures # 样本的训练数据,特征和目标值 x_train = [[6], [8], [10], [14], [18]] #大小 y_train = [[7], [9], [13], [17.5], [18]]#价格 # 在原有特征上增加3次方特征 p = PolynomialFeatures(degree=3) d_3_train = p.fit_transform(x_train) linear = LinearRegression().fit(d_3_train,y_train) # 原本线性回归权重系数 linear.coef_ array([[ 0. , -1.42626096, 0.31320489, -0.01103344]]) # 使用L2正则化力度调整权重系数 # 参数alpha正则化力度 ridge = Ridge(alpha=0.5) ridge.fit(d_3_train,y_train) ridge.coef_ # 调整后权重系数,明显将高权重的变低了 array([[ 0. , -0.14579637, 0.19991159, -0.00792083]])
模型的保存和加载
- from sklearn.externals import joblib (推荐使用,但是高版本anaconda可能不支持)
- joblib.dump(model,'xxx.m'):保存
- joblib.load('xxx.m'):加载
- import pickle
- with open('./123.pkl','wb') as fp:
- pickle.dump(linner,fp)
- with open('./123.pkl','rb') as fp:
- linner = pickle.load(fp)
- with open('./123.pkl','wb') as fp:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号